
1.1 KNN****的主要研究内容
(1)分类器的基本原理及算法内容
(2)利用现有的公开数据集(鸢尾花)实现分类器分类
(3)利用某种评价标准对分类结果进行分析评判
1.2****分类的定义
分类(Classification)是数据挖掘领域中的一种重要的技术,它是从一组已知的训练样本中发现分类模型,并且使用这个分类模型来预测待分类样本。建立一个有效的分类算法模型最终将待分类的样本进行处理是非常有必要的。
目前常用的分类算法主要有:朴素贝叶斯分类算法(Naive Bayes)、支持向量机分类算法(Support Vector Machines)、KNN 算法(k-Nearest Neighbors)、神经网络算法(NNet)以及决策树(DecisionTree)等等。
1.3 KNN****算法简介
何谓K近邻算法,即K-Nearest Neighbor algorithm,简称KNN算法,单从名字来猜想,可以简单粗暴的认为是:分析一个人时,我们不妨观察和他最亲密的几个人。同理的,在判定一个未知事物时,可以观察离它最近的几个样本,这就是KNN(k最近邻)的方法。简单来说,KNN可以看成:有那么一堆你已经知道分类的数据,然后当一个新数据进入的时候,就开始跟训练数据里的每个点求距离,然后挑出离这个数据最近的K个点,看看这K个点属于什么类型,然后用少数服从多数的原则,给新数据归类。
**1.4 **算法思想

如图所示,有两类不同的样本数据,分别用蓝色的小正方形和红色的小三角形表示,而图正中间的那个绿色的圆所标示的数据则是待分类的数据。
如果K=3,绿色圆点的最近的3个邻居是2个红色小三角形和1个蓝色小正方形,少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于红色的三角形一类。
如果K=5,绿色圆点的最近的5个邻居是2个红色三角形和3个蓝色的正方形,还是少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于蓝色的正方形一类。
**1.5 **算法步骤
①初始化距离为最大值;
②计算未知样本和每个训练样本的距离dist;
③得到目前K个最临近样本中的最大距离maxdist;
④如果dist小于maxdist,则将该训练样本作为K-最近邻样本;
⑤重复步骤2、3、4.直到所有未知样本和所有训练样本的距离都算完;
⑥统计K-最近邻样本中每个类标号出现的次数;
⑦选择出现频率最大的类标作为未知样本的类标号。
*1.6 算法三个基本要素:K*值的选择、距离度量、决策规则
(1)K值的选择
k值通常是采用交叉检验来确定(以k=1为基准),交叉验证(将样本数据按照一定比例,拆分出训练用的数据和验证用的数据,比如6:4拆分出部分训练数据和验证数据),从选取一个较小的K值开始,不断增加K的值,然后计算验证集合的方差,最终找到一个比较合适的K值。
增大k的时候,一般错误率会先降低,因为有周围更多的样本可以借鉴了,分类效果会变好。但注意,当K值更大的时候,错误率会更高。这也很好理解,比如说你一共就35个样本,当你K增大到30的时候,KNN基本上就没意义了。
所以选择K点的时候可以选择一个较大的临界K点,当它继续增大或减小的时候,错误率都会上升。
(2)****距离度量
除此之外,还有另外一个因素,就是距离的计算。距离越近应该意味着这两个点属于一个分类的可能性越大。距离的计算有多种方法,比如欧式距离,曼哈顿距离等等,不同距离度量方式会影响最近的K个样本点的选取,从而对结果造成影响,在实际分析中,一般都采用的是欧式距离。



(3)决策规则
• k=1距离更近的近邻决定最终的分类
• k大于1 根据少数服从多数的投票法则(majority-voting),让未知实例归类为K个最邻近样本中最多数的类别
•投票决定:少数服从多数,近邻中哪个类别的点最多就分为该类。
•加权投票法:根据距离的远近,对近邻的投票进行加权,距离越近则权重越大(权重为距离平方的倒数)
1.7 KNN****的优缺点
✦ 优点:
①简单,易于理解,易于实现,⽆需参数估计,⽆需训练
②精度高,对异常值不敏感(个别噪⾳数据对结果的影响不是很⼤)
③适合对稀有事件进行分类
④特别适合于多分类问题(multi-modal,对象具有多个类别标签),KNN要比SVM表现要好
✦ 缺点:
①计算量大,尤其是特征数非常多的时候
②样本不平衡的时候,对稀有类别的预测准确率低
③KD树,球树之类的模型建⽴需要⼤量的内存
④是慵懒散学习⽅法,基本上不学习,导致预测时速度⽐起逻辑回归之类的算法慢
⑤相比决策树模型,KNN模型的可解释性不强,无法给出决策树那样的规则1.9** KNN算法带来的问题**
应用KNN算法来进行预测的时候,经常会遇到很多现实问题。包括:维度灾害问题、近邻索引问题、近邻大小问题、计算效率问题、归纳偏置问题
1.8 KNN****算法应用面或者场景
·预测某人是否喜欢推荐电影(Netflix)
·模式识别,特别是光学字符识别
·数据库,如基于内容的图像检索
·编码理论(最大似然编码);数据压缩(MPEG-2标准)
·向导系统;DNA测序;
·剽窃侦查;拼写检查,建议正确拼写
·相似比分算法,用来推断运动员的职业表现
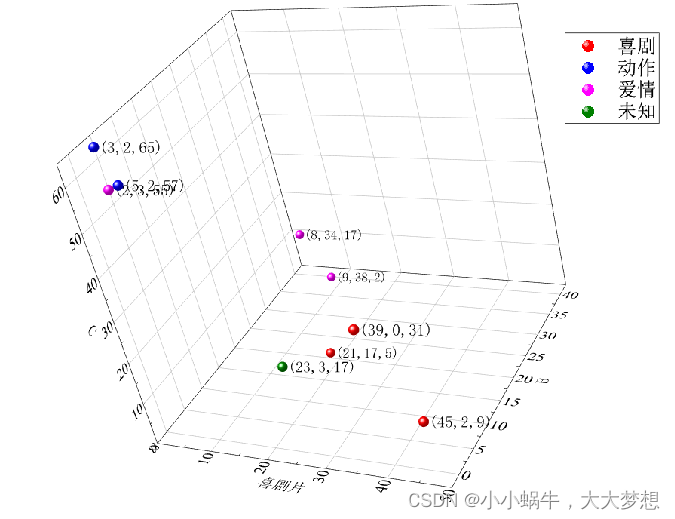
**1.9 **举例
假设们现在有几部电影:

计算公式:
分布图:
版权归原作者 小小蜗牛,大大梦想 所有, 如有侵权,请联系我们删除。