
废话不多说,先来说一下我的配置。
移动工作站:
- 内存:256GB
- cpu:两块,每块为10核20线程,总共20核40线程
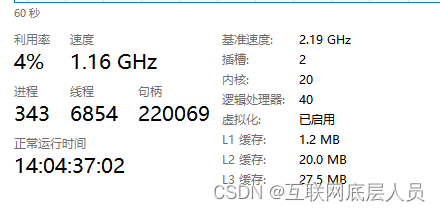
上述的逻辑处理器,可以理解为线程的意思。
首先说一下集群配置:
7个节点, 内存为16GB,处理器核数分配分别为
1核 8线程1核 8线程1核 4线程1核 4线程1核 4线程1核 4线程1核 4线程
需要说明的是,不要将本机所有的线程都分配掉,不然会造成cpu软死锁!!!!
说一下job任务的规模,文件大小为70GB,复制2份,用Mapreduce框架,在上述分配下在整个job任务过程中,没有发生sockettimeout和cpu lockup 异常。
但是如果在这里将节点的核数设置为2核,总线程不变时候,会发生卡死,陷入长时间等待的问题,当总线程继续增加时,虚拟机的cpu使用率出现异常情况,负载很高,但是个别节点出现如下情况。
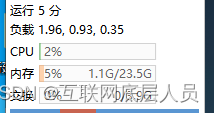
cpu和内存使用率都不高,但是某些节点却完全宕机,这说明cpu在分配资源时候不合理,因为我们知道如果虚拟机的总资源大于本机资源,那么本机cpu会采用轮询的方式来分配给cpu,在这时候那么sockettimeout和 cpu lockup就很容易发生,因为通道的开始和结束,和任务的开启和结束需要cpu的参与,但是当某台节点发生cpu软死锁时候,资源得不到释放,那么后面应该得到资源的节点就会开始等待,直到过了60000ms之后发生socketimeout,当然你也可以将socket的时间设置的更大,但是始终是治标不治本。最重要的是MR是以进程进行,那么资源抢占一定是非常常见的。

我们可以发现,上图中基本上每几秒就会进行IO操作,然后时间到了54分时候,仍然没有动静。
很明显这时候cpu是在为新的job开启通道和即将完成job的任务进行处理,然而这次处理却进行了4分钟之久,其实并行化的量大也是一个原因,如果这时候cpu资源分配不合理,那么某些节点就会发生软死锁。

虽然IO操作中间过程中不需要CPU的参与,但是大量的job并行化时,cpu的负担仍然很重,如果采用的是轮询制度,那么就很容易发生错误。
所以集群总节点的资源一定<本机资源
另外在yarn集群配置上,请保留一个虚拟核,否则也会造成虚拟机很卡顿

以上是8线程的2个主节点所分配给yarn的,保留了两个。
结论:若本机有2个cpu的,请尽量只分配1个cpu,虚拟机总线程<本机总线程,yarn调度中心请不要分配虚拟机所有的核心数。
版权归原作者 互联网底层人员 所有, 如有侵权,请联系我们删除。