
注:参考文档:
SQL之用户行为路径分析--HQL面试题46【拼多多面试题】_路径分析 sql-CSDN博客文章浏览阅读2k次,点赞6次,收藏19次。目录0 问题描述1 数据分析2 小结0 问题描述已知用户行为表 tracking_log, 大概字段有:(user_id 用户编号, op_id 操作编号, op_time 操作时间)要求:(1)统计每天符合以下条件的用户数:A操作之后是B操作,AB操作必须相邻。 (2)统计用户行为序列为A-B-D的用户数其中:A-B之间可以有任何其他浏览记录(如C,E等),B-D之间除了C记录可以有任何其他浏览记录(如A,E等)1 数据分析(1)数据生成......_路径分析 sqlhttps://blog.csdn.net/godlovedaniel/article/details/119856344
0 问题描述
有一张用户行为表 tracking_log,包括字段:user_id 用户编号, op_id 操作编号, op_time 操作时间。2个需求:
- 统计每天符合以下条件的用户数:A操作之后是B操作,AB操作必须相邻;
- 统计用户行为序列为A-B-D的用户数; 其中 A-B之间可以有任何其他浏览记录(如C,E等),B-D之间除了C记录可以有任何其他浏览记录(如A,E等)
1 数据准备
create table tracking_log(
user_id int ,
op_id string,
op_time string
)row format delimited fields terminated by '\t';
insert overwrite table tracking_log values
(1, 'A', '2020-1-1 12:01:03'),
(2, 'A', '2020-1-1 12:01:04'),
(3, 'A', '2020-1-1 12:01:05'),
(1, 'B', '2020-1-1 12:03:03'),
(1, 'A', '2020-1-1 12:04:03'),
(1, 'C', '2020-1-1 12:06:03'),
(1, 'D', '2020-1-1 12:11:03'),
(2, 'A', '2020-1-1 12:07:04'),
(3, 'C', '2020-1-1 12:02:05'),
(2, 'C', '2020-1-1 12:09:03'),
(2, 'A', '2020-1-1 12:10:03'),
(4, 'A', '2020-1-1 12:01:03'),
(4, 'C', '2020-1-1 12:11:05'),
(4, 'D', '2020-1-1 12:15:05'),
(1, 'A', '2020-1-2 12:01:03'),
(2, 'A', '2020-1-2 12:01:04'),
(3, 'A', '2020-1-2 12:01:05'),
(1, 'B', '2020-1-2 12:03:03'),
(1, 'A', '2020-1-2 12:04:03'),
(1, 'C', '2020-1-2 12:06:03'),
(2, 'A', '2020-1-2 12:07:04'),
(3, 'B', '2020-1-2 12:08:05'),
(3, 'E', '2020-1-2 12:09:05'),
(3, 'D', '2020-1-2 12:11:05'),
(2, 'C', '2020-1-2 12:09:03'),
(4, 'E', '2020-1-2 12:05:03'),
(4, 'B', '2020-1-2 12:06:03'),
(4, 'E', '2020-1-2 12:07:03'),
(2, 'A', '2020-1-2 12:10:03');
2 数据分析
需求一:统计每天符合以下条件的用户数:A操作之后是B操作,AB操作必须相邻;
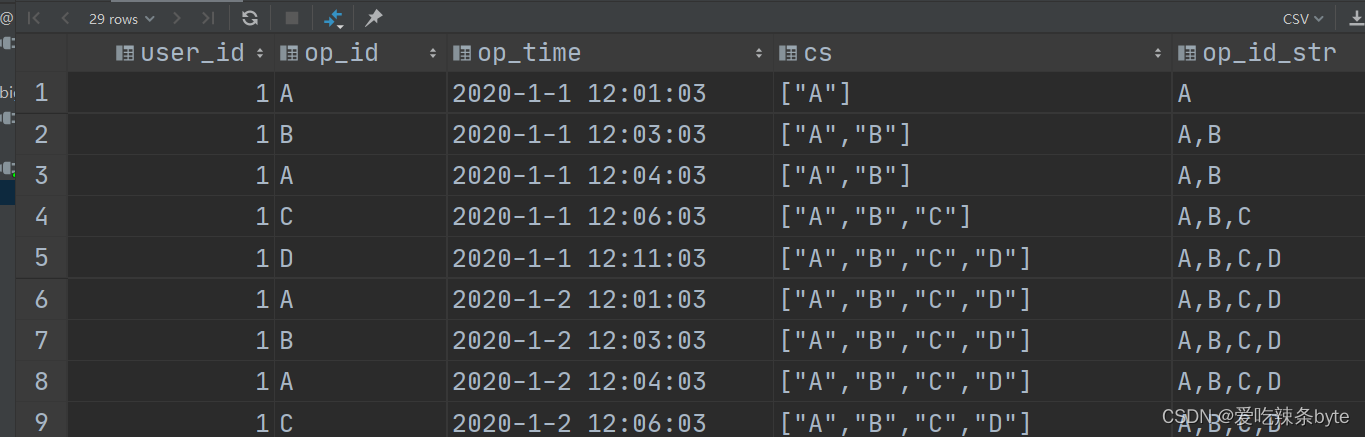
**step1: **将路径分析转换成字符串序列分析,采用函数concat_ws(',', collect_set())
select
user_id,
op_id,
op_time,
collect_set(op_id) over (partition by user_id order by op_time) cs,
--用户行为轨迹
--collect_set 及collect_list属于高级的聚合窗口函数,当over()中有order by,但是省略窗口子句时候,窗口计算范围:orws between unbounded preceding and current row
concat_ws(',', collect_set(op_id) over (partition by user_id order by op_time)) as op_id_str
from tracking_log
order by user_id, op_time
上述代码涉及到的函数:
collect_list : 收集并形成list集合,结果不去重 (高级聚合函数)
- 语法:collect_list(col)
- 返回值:array
- 说明:在hive中是把一个key的多个信息收集起来合成一个,不去重
- 举例:select avg(score) from table;
collect_set:收集并形成set集合,结果去重(高级聚合函数)
- 语法:collect_set(col)
- 返回值:array
- 说明:在hive中是把一个key的多个信息收集起来,去重
- 举例:select avg(score) from table;
concat_ws(带分隔符的字符串连接函数)
- 语法:concat_ws(string SEP, string A ,string B.......)
- 返回值:string
- 说明:返回输入字符串连接后的结果,SEP表示各个字符串的分隔符
- 举例:select concat_ws('|','ad','cv','op') ;---> ad|cv|op
step2: 利用函数 locate()判断序列 A,B 是否在字符串op_id_str 中存在,存在则返回该位置的索引,where locate('A,B', op_id_str) >0
select
date_format(op_time, 'yyyy-MM-dd') as dt,
count(distinct user_id) cnt
from (select
user_id,
op_id,
op_time,
collect_set(op_id) over (partition by user_id order by op_time) cs,
--用户行为轨迹
concat_ws(',', collect_set(op_id) over (partition by user_id order by op_time)) as op_id_str
from tracking_log
order by user_id, op_time) t
where locate('A,B', op_id_str) >0
group by date_format(op_time, 'yyyy-MM-dd')
上述代码涉及到的函数:
locate:第一次出现的位置
语法: locate( string substr, string str [, int pos] )
返回值: int
说明:查找字符串substr第一次出现的位置
举例:select locate('ad','aadbedfaad'); ---> 2
select locate('A,B','A,B,C,D'); ---> 1

需求二:需要匹配A-B-D的路径,但A,B之间可以有任何其他浏览记录,B-D之间除了C记录可以有任何其他浏览记录,所以使用字符串的正则匹配,like来求解。代码片段: where op_id_str like '%A%B%D' and op_id_str not like '%A%B%C%D'
select
date_format(op_time, 'yyyy-MM-dd') as dt,
count(distinct user_id) as cnt
from (select
user_id,
op_id,
op_time,
collect_set(op_id) over (partition by user_id order by op_time) cs,
--用户行为轨迹
concat_ws(',', collect_set(op_id) over (partition by user_id order by op_time)) as op_id_str
from tracking_log
order by user_id, op_time) t
where op_id_str like '%A%B%D' and op_id_str not like '%A%B%C%D'
group by date_format(op_time, 'yyyy-MM-dd');

3 小结
上述案例阐述用户行为路径的解决方法,主要思路是将用户路径转换为字符串序列进行分析,并利用like方法进行路径的模糊匹配。(字符”%”表示任意数量的字符。)
**Hive的like正则表达式见:**Hive正则表达式-CSDN博客文章浏览阅读382次,点赞13次,收藏5次。Hive正则表达式https://blog.csdn.net/SHWAITME/article/details/136094446?spm=1001.2014.3001.5502
版权归原作者 爱吃辣条byte 所有, 如有侵权,请联系我们删除。