
01 ClickHouse集群安装部署
1.1 安装部署Zookeeper
1.安装模式
Zookeeper安装模式有三种:
单机模式:Zookeeper只运行在一台服务器上,适合测试环境。
伪集群模式:一台物理机上运行多个Zookeeper 实例,适合测试环境。
分布式集群模式:Zookeeper运行于一个集群中,适合生产环境。
2.集群规划
(1)主机规划
Zookeeper最小集群是3节点集群,生产环境中100节点以下集群3个Zookeeper节点就够用,500节点以下集群5节点就够用。
Hadoop3-01
Hadoop3-02
Hadoop3-03
Zookeeper
是
是
是
(2)软件规划
JDK使用工作中常用的较新版本jdk1.8(java10最新)。
软件
版本
位数
Jdk
1.8
64
Centos
7
64
Zookeeper
zookeeper-3.5.6
稳定版本
(3)用户规划
大数据平台集群软件统一在hadoop用户下安装。
节点名称
用户组
用户
Hadoop3-01
Hadoop
Hadoop
Hadoop3-02
Hadoop
Hadoop
Hadoop3-03
Hadoop
Hadoop
(4)目录规划
为了方便统一管理,提前规划好软件目录、脚本目录和数据目录。
名称
路径
所有软件目录
/home/hadoop/app
脚本目录
/home/hadoop/tools
数据目录
/home/hadoop/data
3.JDK安装
Zookeeper是由Java编写,运行在JVM,所以需要提前安装JDK运行环境。
(1)下载JDK
可以到官网下载对应版本的jdk,这里选择安装jdk1.8版本,并上传至/home/hadoop/app目录下。
(2)解压JDK
通过tar -zxvf命令对jdk安装包进行解压即可。

(3)创建软连接
为了方便版本的更换和学习使用,可以创建jdk软连接指向jdk真实安装路径。可以使用如下命令:ln -s jdk1.8.0_51 jdk

(4)配置环境变量
1)修改/etc/profile文件
如果你的计算机仅仅作为开发使用时推荐使用这种方法,因为所有用户的shell都有权使用这些环境变量,可能会给系统带来安全性问题。这里是针对所有的用户的,所有的shell。
vi /etc/profileJAVA_HOME=/home/hadoop/app/jdkCLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jarPATH=$JAVA_HOME/bin:/home/hadoop/tools:$PATHexport JAVA_HOME CLASSPATH PATH
2)修改.bashrc文件
这种方法更为安全,它可以把使用这些环境变量的权限控制到用户级别,这里是针对某一个特定的用户,如果你需要给某个用户权限使用这些环境变量,你只需要修改其个人用户主目录下的.bashrc文件就可以了。
vi ~/.bashrcJAVA_HOME=/home/hadoop/app/jdkCLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jarPATH=$JAVA_HOME/bin:/home/hadoop/tools:$PATHexport JAVA_HOME CLASSPATH PATH
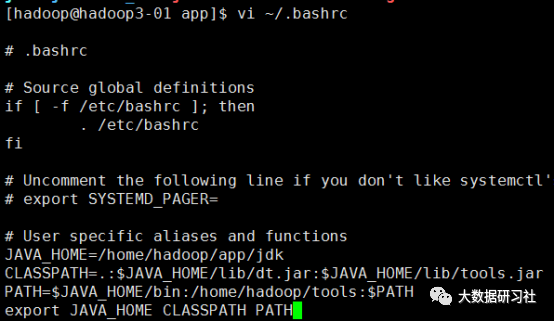
(5)source使配置文件生效
通过source ~/.bashrc命令使得刚刚配置的环境变量生效。
(6)检查JDK是否安装成功
通过命令:java –version查看jdk版本,如果能查看到当前jdk版本,说明jdk安装成功

(7)JDK安装包同步到其他节点
通过脚本命令:deploy.sh jdk1.8.0_51 /home/hadoop/app/ slave将jdk安装包同步到其他节点,然后重复3.3~3.6步骤完成各个节点的jdk安装。

4.ZK安装
(1)下载Zookeeper
Apache Zookeeper核心版本下载地址:
http://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/
Apache Zookeeper所有版本下载地址:
https://archive.apache.org/dist/zookeeper/

注意:第一个是Zookeeper安装包,第二个是Zookeeper源码包。如果选择源码包安装会报如下错误:
Error: Could not find or load main class org.apache.zookeeper.server.quorum.QuorumPeerMain
(2)解压Zookeeper
通过tar -zxvf命令对Zookeeper安装包进行解压即可。

(3)创建软连接
为了方便版本的更换和学习使用,可以创建zookeeper软连接指向zookeeper真实安装路径。可以使用如下命令:ln -s zookeeper-xxx zookeeper

(4)修改zoo.cfg配置文件
The number of milliseconds of each tick
#这个时间是作为Zookeeper服务器之间或客户端与服务器之间维持心跳的时间间隔
tickTime=2000
The number of ticks that the initial
synchronization phase can take
#配置 Zookeeper 接受客户端初始化连接时最长能忍受多少个心跳时间间隔数。
initLimit=10# The number of ticks that can pass between # sending a request and getting an acknowledgement#Leader 与 Follower 之间发送消息,请求和应答时间长度syncLimit=5# the directory where the snapshot is stored.# do not use /tmp for storage, /tmp here is just # example sakes.
#数据目录需要提前创建
dataDir=/home/hadoop/data/zookeeper/zkdata
#日志目录需要提前创建
dataLogDir=/home/hadoop/data/zookeeper/zkdatalog# the port at which the clients will connect
#访问端口号
clientPort=2181# the maximum number of client connections.# increase this if you need to handle more clients#maxClientCnxns=60## Be sure to read the maintenance section of the # administrator guide before turning on autopurge.## http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance## The number of snapshots to retain in dataDir#autopurge.snapRetainCount=3# Purge task interval in hours# Set to "0" to disable auto purge feature#autopurge.purgeInterval=1
#server.每个节点服务编号=服务器ip地址:集群通信端口:选举端口
server.1=hadoop3-01:2888:3888
server.2=hadoop3-02:2888:3888
server.3=hadoop3-03:2888:3888
5.zk安装目录同步到其他节点
将Zookeeper安装目录整体分发到其他节点
deploy.sh apache-zookeeper-3.5.6 /home/hadoop/app/ slave

并分别创建软连接
ln -s apache-zookeeper-3.5.6 zookeeper

6.创建规划的目录
runRemoteCmd.sh "mkdir -p /home/hadoop/data/
zookeeper/zkdata" all

runRemoteCmd.sh "mkdir -p /home/hadoop/data/
zookeeper/zkdatalog" all

7.修改每个节点服务编号
分别到各个节点,进入/home/hadoop/data/zookeeper/
zkdata目录,创建文件myid,里面的内容分别填充为:1、2、3

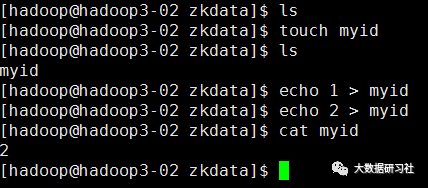

8.测试运行
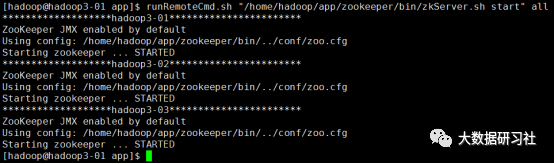
启动Zookeeper
runRemoteCmd.sh "/home/hadoop/app/zookeeper/bin/zkServer.sh start" all
查看Zookeeper进程
runRemoteCmd.sh "jps" all

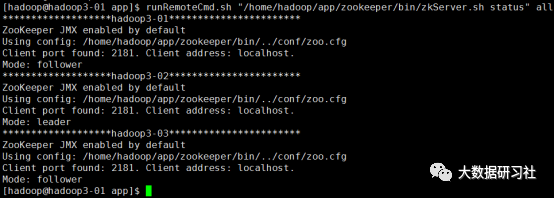
查看Zookeeper状态
runRemoteCmd.sh "/home/hadoop/app/zookeeper/bin/zkServer.sh status" all
1.2 ClickHouse集群部署
1.ClickHouse其它节点准备
其他节点按照ClickHouse单节点先安装部署完毕。
2.ClickHouse集群配置
(1)配置metrika.xml
以hadoop3-1节点为例,在metrika.xml文件中,添加如下配置:
vi /etc/clickhouse-server/config.d/metrika.xml<yandex><!--ClickHouse相关配置--><clickhouse_remote_servers><cluster_2shards_0replicas><shard><replica><host>hadoop3-1</host><port>9000</port></replica></shard><shard><replica><host>hadoop3-2</host><port>9000</port></replica></shard></cluster_2shards_0replicas></clickhouse_remote_servers><!--zookeeper相关配置--><zookeeper-servers><node index="1"><host>hadoop3-1</host><port>2181</port></node><node index="2"><host>hadoop3-2</host><port>2181</port></node><node index="3"><host>hadoop3-3</host><port>2181</port></node></zookeeper-servers><macros><replica>hadoop3-1</replica></macros><networks><ip>::/0</ip></networks></yandex>
(2)配置config.xml
在全局配置config.xml中使用<include_from>标签引入刚才定义的配置:
vi /etc/clickhouse-server/config.xml<include_from>/etc/clickhouse-server/config.d/metrika.xml</include_from>
#引用Zookeeper配置的定义
<zookeeper incl="zookeeper-servers" optional="false" />
#打开注释,让其他节点访问当前节点ClickHouse
<listen_host>::</listen_host>
(3)集群其他节点重复上面配置
在其他节点依次增加metrika.xml配置文件,并修改全局配置config.xml。在config.xml文件中,每个节点需要修改自己的宏定义,以hadoop3-2节点为例
<macros><replica>hadoop3-2</replica>
</macros>3.启动ClickHouse集群
(1)启动Zookeeper集群
runRemoteCmd.sh "/home/hadoop/app/zookeeper/bin/zkServer.sh start" all
(2)启动ClickHouse集群
基于默认配置启动ClickHouse
sudo /etc/init.d/clickhouse-server start
(3)验证ClickHouse集群
在每个节点启动clickhouse客户端,分别查询集群信息。
如果能查看到集群配置的分片和副本信息等信息,说明clickhouse的集群部署完全成功。

在ClickHouse系统表中,提供了一张Zookeeper代理表,可以使用SQL访问Zookeeper内的数据。
#查询Zookeeper根目录
select * from system.zookeeper where path = '/'
#查询ClickHouse目录
select * from system.zookeeper where path = '/clickhouse'
版权归原作者 大数据研习社 所有, 如有侵权,请联系我们删除。