
一、搭建伪分布式本次实验环境:
1、一台centos7 64位
2、主机名位master
3、ip 地址:192.168.20.11
4、本次实验需要的安装包
二、 伪分布式搭建前的准备
1.关闭防火墙:systemctl stop firewalld
2.修改主机名,添加主机映射:
hostnamectl set-hostname master
vi /etc/hosts
192.168.20.11 master
ping master查看是否成功

三、安装jdk:
cd /opt
tar -zxvf jdk-8u152-linux-x64.tar.gz
mv jdk1.8.0_152/ jdk

vi /etc/profile
在最后加上
export JAVA_HOME=/opt/jdk #这里是opt目录
export PATH=:$PATH:$JAVA_HOME/bin

source /etc/profile使环境变量生效
验证是否安装成功
验证:
java -version
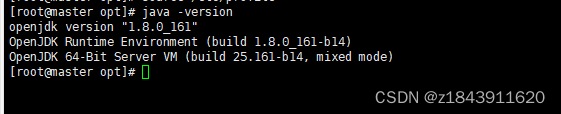
四、搭建hadoop伪分布式
cd /opt
tar -zxvf hadoop-2.7.1.tar.gz
cd /opt/hadoop/etc/hadoop/
修改 hadoop-env.sh
在最后加上export JAVA_HOME=/opt/jdk
修改 core-site.xml
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/opt/hadoop/tmp</value> </property> <property> <name>fs.trash.interval</name> <value>1440</value> </property> </configuration> 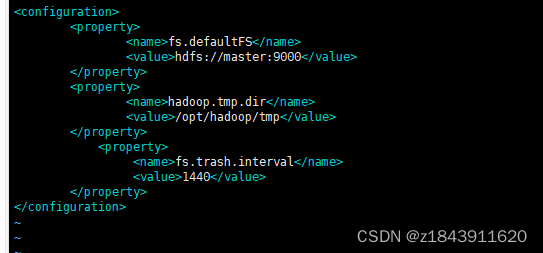修改 hdfs-site.xml 将dfs.replication设置为1
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> </configuration>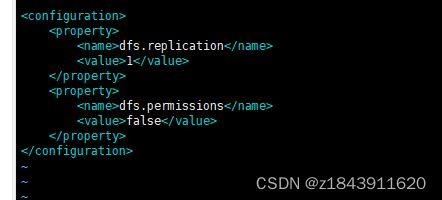
修改文件yarn-site.xml
<configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>master</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property> </configuration>
修改 mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>master:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>master:19888</value> </property> </configuration> 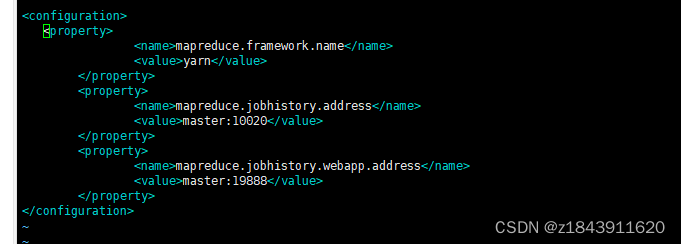修改环境变量
Vim /etc/profile
export JAVA_HOME=/opt/jdk
export HADOOP_HOME=/opt/hadoop
export PATH=:$PATH:$JAVA_HOME/bin
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin

使环境变量生效
source /etc/profile
初始化hadoop集群
hadoop namenode -format
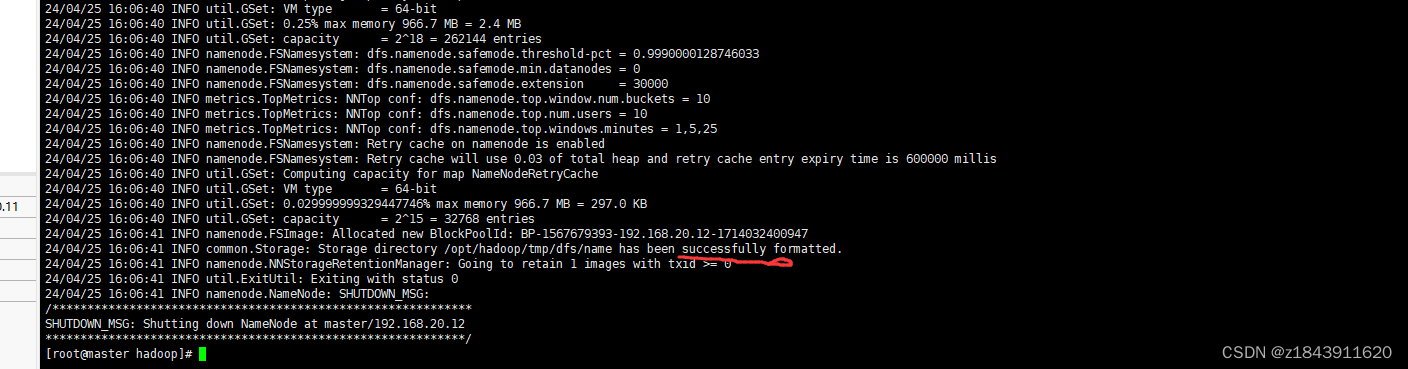
初始化成功
到 hadoop 的sbin目录启动hadoop
cd /opt/hadoop/sbin/
./start-all.sh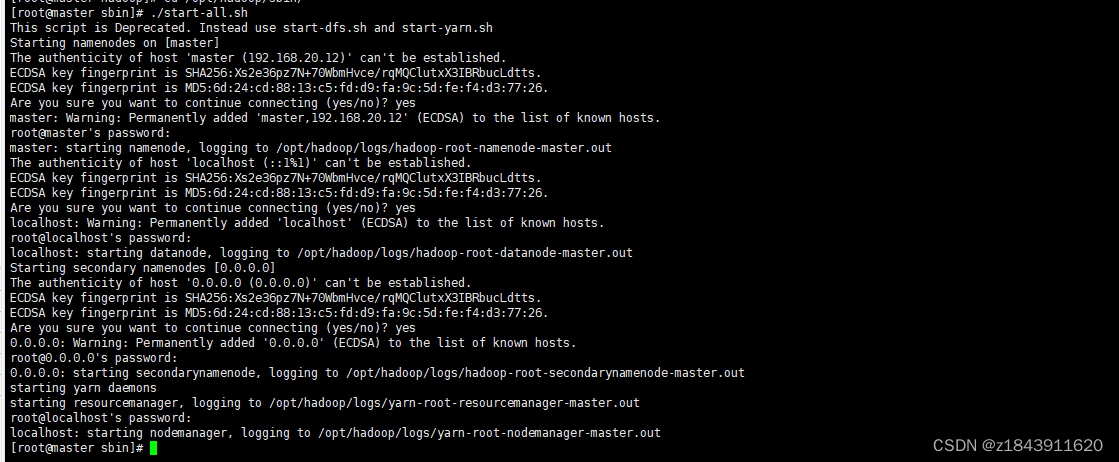
验证
jps

出现以上java节点 Hadoop伪分布式就搭建成功了
验证hdfs:可以登录浏览器地址:192.168.20.11:50070 (ip地址是master的地址)
看到下面页面证明 hdfs装好了
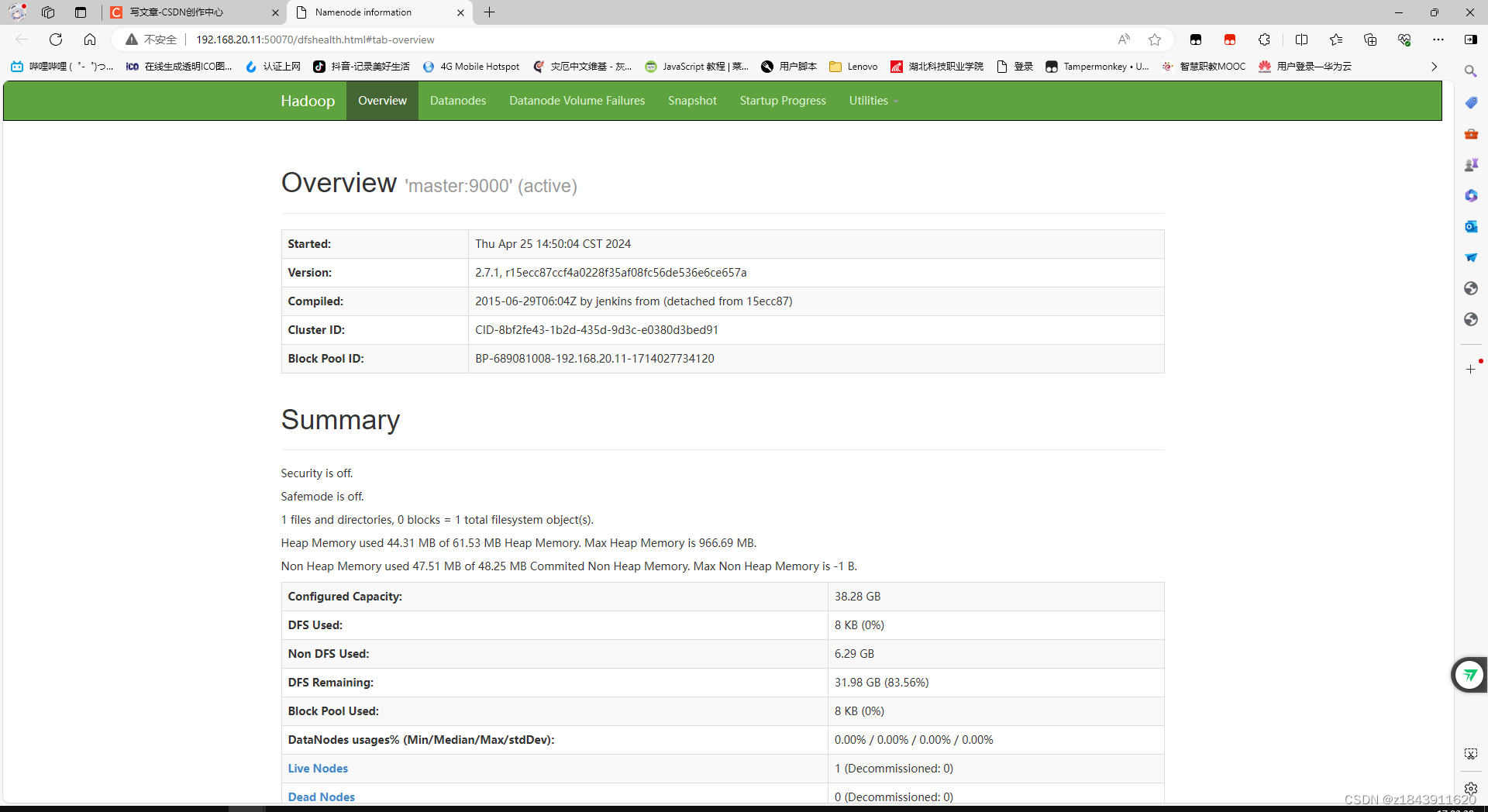
验证yarn

五、安装spark
cd /opt
tar -zxvf spark-2.0.0-bin-hadoop2.6.tgz
mv spark-2.0.0-bin-hadoop2.6 spark
cd /opt/spark/conf/
cp spark-env.sh.template spark-env.sh
vi spark-env.sh
在文件末尾加上
export JAVA_HOME=/opt/jdk
export HADOOP_HOME=/opt/hdaoop
export HADOOP_CONF_DIR=/opt/hadoop/etc/hadoop
export SPARK_MASTER_IP=master
export SPARK_LOCAL_IP=master

切换到spark安装目录的/sbin目录下启动spark集群
cd /opt/spark/sbin/
./start-all.sh

浏览器输入192.168.20.11:8080如果出现下面界面代表成功
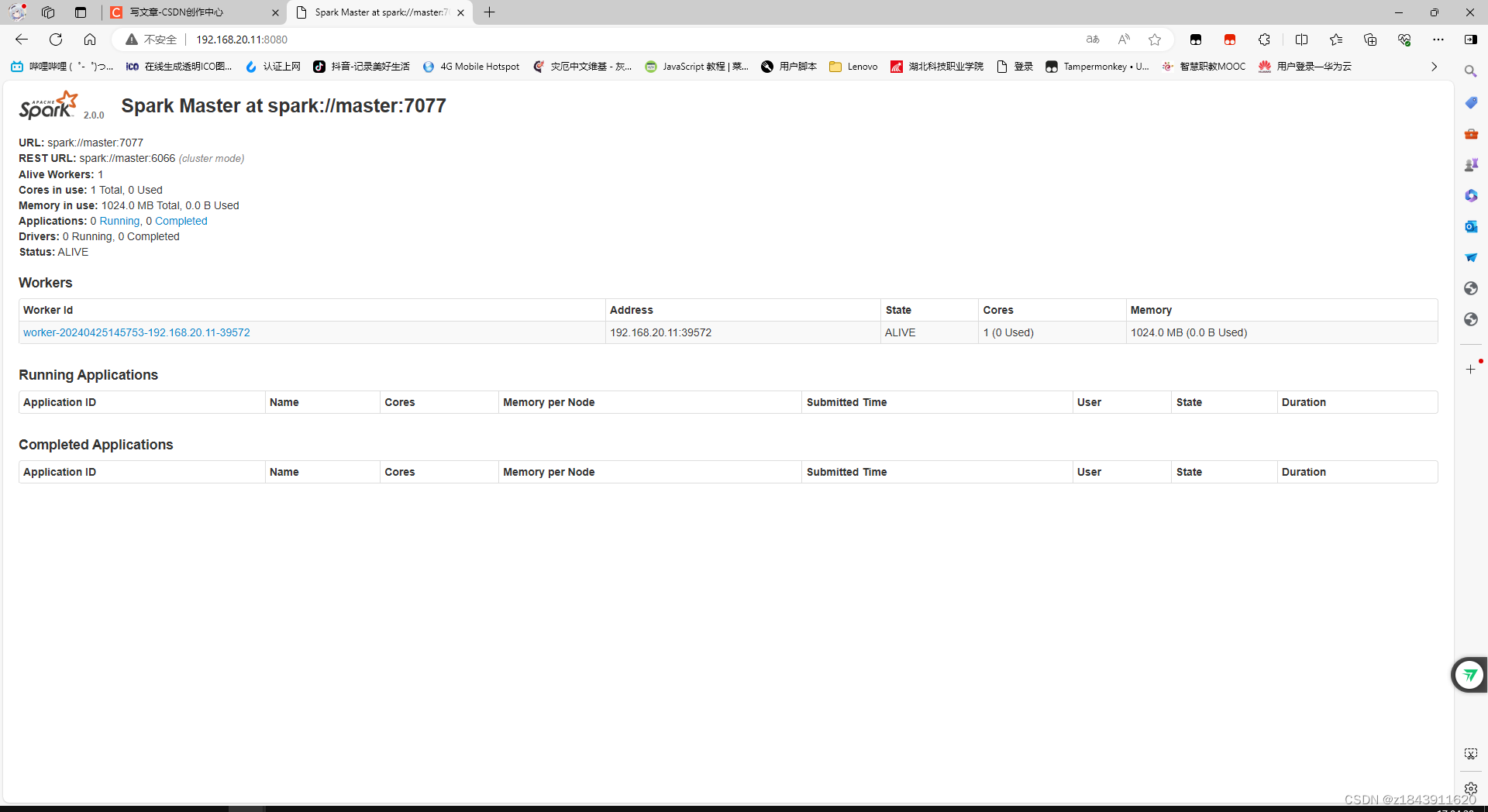
cd /opt/spark/bin
spark-shell
如果进入以下界面代表成功
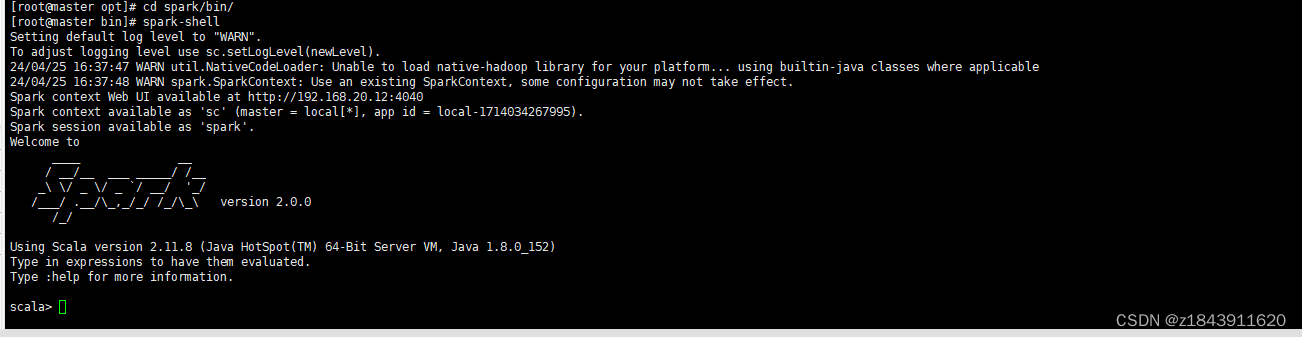
六、安装scala:
cd /opt
tar -zxvf scala-2.11.8.tgz
mv scala-2.11.8 scala
修改环境变量
Vim /etc/profile
export SCALA_HOME=/opt/scala
export PATH=$PATH:$SCALA_HOME/bin
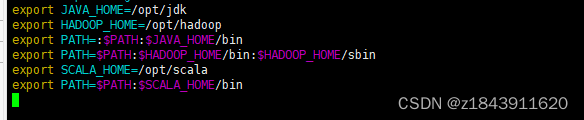
使环境变量生效
source /etc/profile
输入scala
进入以下界面代表成功

版权归原作者 z1843911620 所有, 如有侵权,请联系我们删除。