
📋 个人简介
- 💖 作者简介:大家好,我是阿牛,全栈领域优质创作者。😜
- 📝 博主的个人网站:阿牛的博客小屋🔥
- 🎉 支持我:点赞👍+收藏⭐️+留言📝
- 📣 系列专栏:python网络爬虫🍁
- 💬格言:要成为光,因为有怕黑的人!🔥

目录
前言
因为我做的项目需要一些疫情数据,因此在这里总结一下数据获取以及将其保存到数据库,对网络爬虫学习者还是有帮助的。
需求分析
我们需要获取的内容是某新闻报告官网的这个国内疫情数据,包含总体数据以及各省市数据以及每天的数据及变化!
目标网站如下:https://news.qq.com/zt2020/page/feiyan.htm#/
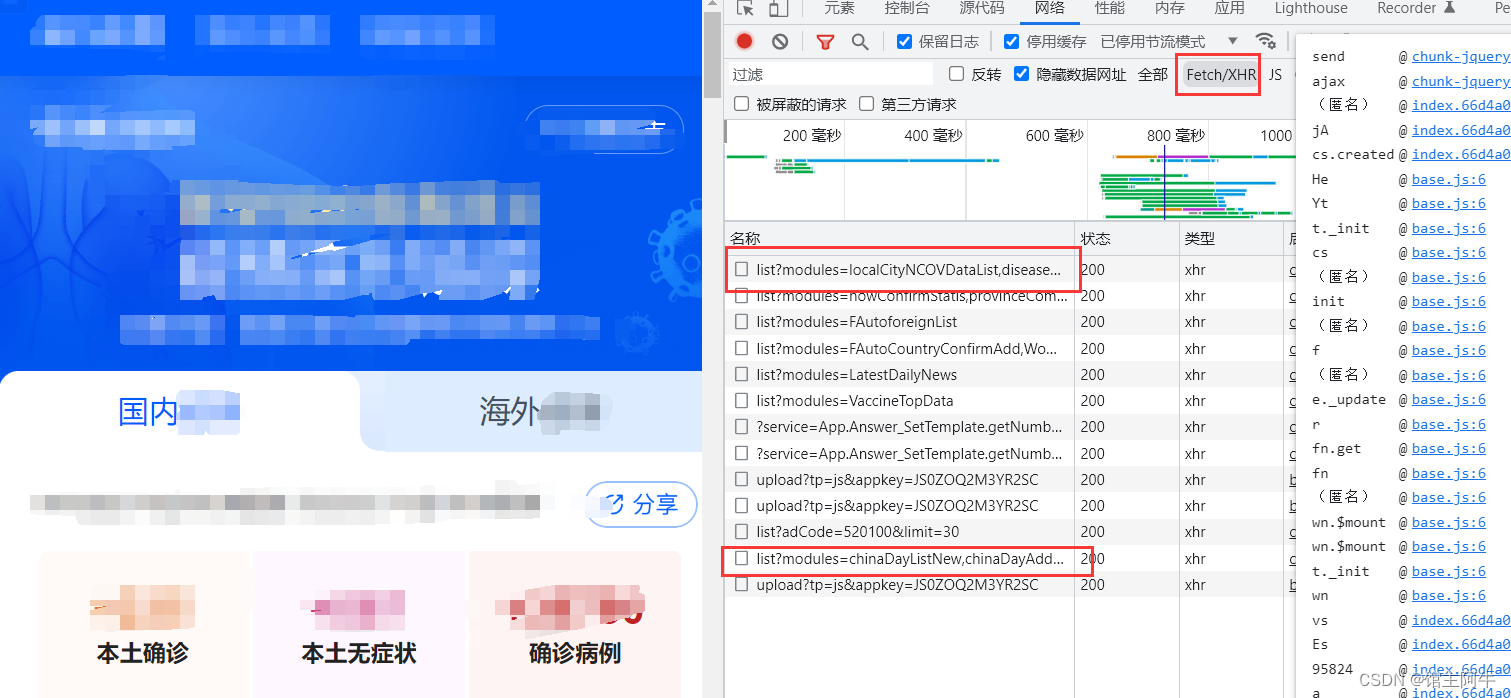
如图:要获取的api有两个,第一个链接是各省市的详情数据,第二个是近30天的历史数据。
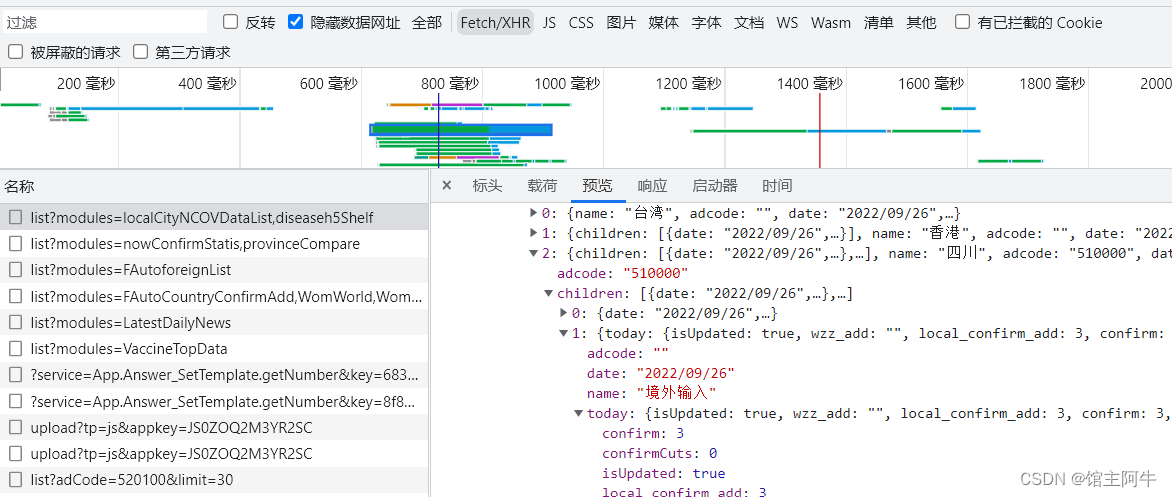
如图,数据是树状的,需要我们看好一层层提取,可借助json格式化工具!
最后将其保存到mysql数据库!
项目技术
爬虫-获取数据
pymysql - 连接数据库
mysql - 保存数据
数据库设计
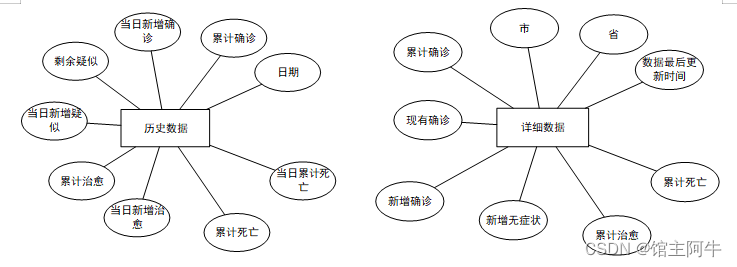
ER图
建表sql
详细数据表
CREATETABLE`details`(`id`intNOTNULLAUTO_INCREMENT,`update_time`datetimeDEFAULTNULLCOMMENT'数据最后更新时间',`province`varchar(50)DEFAULTNULLCOMMENT'省',`city`varchar(50)DEFAULTNULLCOMMENT'市',`confirm`intDEFAULTNULLCOMMENT'累计确诊',`now_confirm`intDEFAULTNULLCOMMENT'现有确诊',`confirm_add`intDEFAULTNULLCOMMENT'新增确诊',`wzz_add`intDEFAULTNULLCOMMENT'新增无症状',`heal`intDEFAULTNULLCOMMENT'累计治愈',`dead`intDEFAULTNULLCOMMENT'累计死亡',PRIMARYKEY(`id`))ENGINE=InnoDBAUTO_INCREMENT=528DEFAULTCHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
历史数据表
CREATETABLE`history`(`ds`datetimeNOTNULLCOMMENT'日期',`confirm`intDEFAULTNULLCOMMENT'累计确诊',`confirm_add`intDEFAULTNULLCOMMENT'当日新增确诊',`local_confirm`intDEFAULTNULLCOMMENT'现有本土确诊',`local_confirm_add`intDEFAULTNULLCOMMENT'本土当日新增确诊',`local_no_infect`intDEFAULTNULLCOMMENT'现有本土无症状',`local_no_infect_add`intDEFAULTNULLCOMMENT'本土当日新增无症状',`heal`intDEFAULTNULLCOMMENT'累计治愈',`heal_add`intDEFAULTNULLCOMMENT'当日新增治愈',`dead`intDEFAULTNULLCOMMENT'累计死亡',`dead_add`intDEFAULTNULLCOMMENT'当日新增死亡',PRIMARYKEY(`ds`)USINGBTREE)ENGINE=InnoDBDEFAULTCHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
pymysql连接数据库
# mysql建立连接defget_con():# 建立连接
con = pymysql.connect(host="127.0.0.1",
user="root",
password="",
db="",
charset="utf8")# 创建游标
cursor = con.cursor()return con, cursor
# mysql关闭连接defclose_con(con, cursor):if cursor:
cursor.close()if con:
con.close()
password和db请配置成你的!
爬虫设计
爬虫需要模块
- requests
- json
- random
因为需要多次爬取,因此我搭建了ip代理池和ua池
# ip代理池
ips =[{"HTTP":"175.42.129.105"},{"HTTP":"121.232.148.97"},{"HTTP":"121.232.148.72"}]
proxy = random.choice(ips)# headers池
headers =[{'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36'},{'user-agent':"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2227.0 Safari/537.36"},{'user-agent':"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:22.0) Gecko/20130328 Firefox/22.0"}]
header = random.choice(headers)
爬取数据本身没有难度,数据提取比较费劲,请借助json格式化工具看清楚!
代码与展示
import traceback
import requests
import json
import time
import random
import pymysql
# ip代理池
ips =[{"HTTP":"175.42.129.105"},{"HTTP":"121.232.148.97"},{"HTTP":"121.232.148.72"}]
proxy = random.choice(ips)# headers池
headers =[{'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36'},{'user-agent':"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2227.0 Safari/537.36"},{'user-agent':"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:22.0) Gecko/20130328 Firefox/22.0"}]
header = random.choice(headers)# 返回历史数据和当日详细数据defget_tencent_data():# 当日详情数据的url
url1 ="https://api.inews.qq.com/newsqa/v1/query/inner/publish/modules/list?modules=localCityNCOVDataList,diseaseh5Shelf"# 历史数据的url
url2 ="https://api.inews.qq.com/newsqa/v1/query/inner/publish/modules/list?modules=chinaDayListNew,chinaDayAddListNew&limit=30"
r1 = requests.get(url=url1, headers=header,proxies=proxy).text
r2 = requests.get(url=url2, headers=header,proxies=proxy).text
# json字符串转字典
data_all1 = json.loads(r1)['data']['diseaseh5Shelf']
data_all2 = json.loads(r2)['data']# 历史数据
history ={}for i in data_all2["chinaDayListNew"]:# 时间
ds = i["y"]+'.'+ i["date"]
tup = time.strptime(ds,"%Y.%m.%d")# 匹配时间 结果是时间元祖
ds = time.strftime("%Y-%m-%d", tup)# 改变时间输入格式,不然插入数据库会报错,数据库是datatime格式
confirm = i["confirm"]
local_confirm = i["localConfirm"]
local_no_infect = i["noInfectH5"]
heal = i["heal"]
dead = i["dead"]
history[ds]={"confirm": confirm,"local_confirm": local_confirm,"local_no_infect": local_no_infect ,"heal": heal,"dead": dead}for i in data_all2["chinaDayAddListNew"]:
ds = i["y"]+'.'+ i["date"]
tup = time.strptime(ds,"%Y.%m.%d")# 匹配时间
ds = time.strftime("%Y-%m-%d", tup)# 改变时间输入格式,不然插入数据库会报错,数据库是datatime格式
confirm_add = i["confirm"]
local_confirm_add = i["localConfirmadd"]
local_no_infect_add = i["localinfectionadd"]
heal_add = i["heal"]
dead_add = i["dead"]
history[ds].update({"confirm_add": confirm_add,"local_confirm_add": local_confirm_add,"local_no_infect_add":local_no_infect_add,"heal_add": heal_add,"dead_add": dead_add})# 当日详细数据
details =[]
update_time = data_all1["lastUpdateTime"]
data_country = data_all1["areaTree"][0]
data_province = data_country["children"]# 中国各省for pro_infos in data_province:
province = pro_infos["name"]# 省名for city_infos in pro_infos["children"]:
city = city_infos["name"]# 累计确珍人数
confirm = city_infos["total"]["confirm"]# 现有确诊人数
now_confime = city_infos["total"]["nowConfirm"]# 新增确诊人数
confirm_add = city_infos["today"]["confirm"]# 新增无症状
wzz_add = city_infos["today"]["wzz_add"]if wzz_add =='':
wzz_add =0else:
wzz_add =int(wzz_add)# 累计治愈人数
heal = city_infos["total"]["heal"]# 累计死亡人数
dead = city_infos["total"]["dead"]
details.append([update_time, province, city, confirm, now_confime, confirm_add,wzz_add, heal, dead])return history, details
# mysql建立连接defget_con():# 建立连接
con = pymysql.connect(host="127.0.0.1",
user="root",
password="",
db="",
charset="utf8")# 创建游标
cursor = con.cursor()return con, cursor
# mysql关闭连接defclose_con(con, cursor):if cursor:
cursor.close()if con:
con.close()# 插入及更新每日details数据defupdate_details():
cursor =None
con =Nonetry:
lis = get_tencent_data()[1]# 0是历史数据,1是当日详细数据
con, cursor = get_con()
sql ="insert into details (update_time,province,city,confirm,now_confirm,confirm_add,wzz_add,heal,dead) values (%s,%s,%s,%s,%s,%s,%s,%s,%s)"
sql_query ="select update_time from details order by id desc limit 1"# 执行sql语句
cursor.execute(sql_query)
query_data = cursor.fetchone()# 判断表中是否有数据以及对比当前最大时间是否相同# query_data[0] 中时间数据类型是datetime.datetime,li[0][0] 中时间数据类型是strif query_data ==Noneorstr(query_data[0])!= lis[0][0]:print(f"{time.asctime()} 开始更新数据")for item in lis:
cursor.execute(sql, item)
con.commit()#提交事务print(f"{time.asctime()} 更新到最新数据")else:print(f"{time.asctime()} 已是最新数据!")except:#traceback模块不仅可以返回错误,还可以返回错误的具体位置
traceback.print_exc()finally:
close_con(con, cursor)#插入及更新更新历史数据defupdate_history():
cursor =None
con =Nonetry:
dic = get_tencent_data()[0]#0代表历史数据字典print(f"{time.asctime()} 开始更新历史数据")
con,cursor = get_con()
sql ="insert into history values (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)"
sql_query ="select confirm from history where ds=%s"for k,v in dic.items():# 判断最新时间的数据是否在数据表中,不在更新数据ifnot cursor.execute(sql_query,k):
cursor.execute(sql,[k, v.get("confirm"), v.get("confirm_add"), v.get("local_confirm"),
v.get("local_confirm_add"), v.get("local_no_infect"), v.get("local_no_infect_add"),
v.get("heal"), v.get("heal_add"),
v.get("dead"), v.get("dead_add")])
con.commit()print(f"{time.asctime()} 历史数据更新完毕")except:
traceback.print_exc()finally:
close_con(con,cursor)if __name__ =="__main__":# print(get_tencent_data())# 插入、更新每日details数据
update_details()# 插入、更新历史数据
update_history()
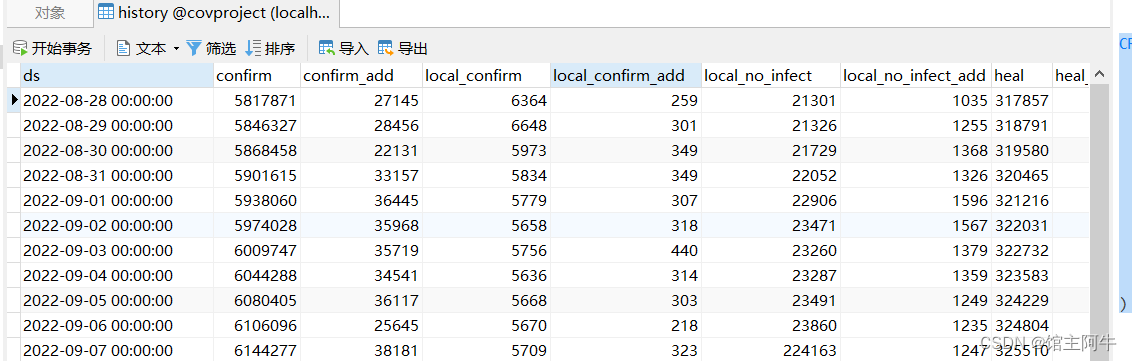
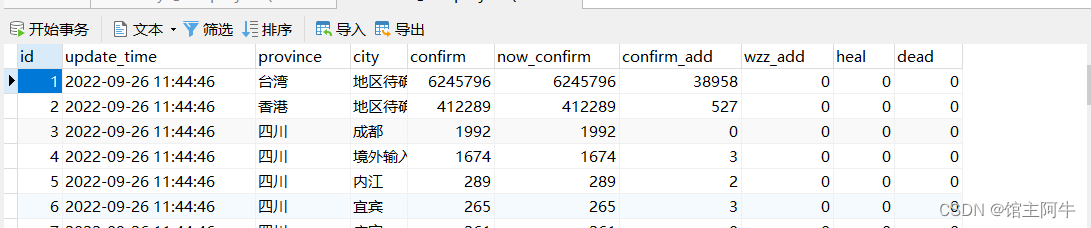
代码执行说明
先在mysql数据库中执行sql语句建表,然后修改代码中的数据库配置,然后运行代码即可!
结语
之所以做这个是因为我的项目需要数据!
正好我最近做的项目完工了,已开源。
项目地址:https://gitee.com/aniu-666/project
项目拿走不谢,还请给个star💖
本文转载自: https://blog.csdn.net/qq_57421630/article/details/127057505
版权归原作者 馆主阿牛 所有, 如有侵权,请联系我们删除。
版权归原作者 馆主阿牛 所有, 如有侵权,请联系我们删除。