
什么是分布式锁
在分布式架构中,Java的锁无法管理多个实例,因此需要有一个类似于统一管理锁的架构模式,即分布式锁。
目前比较常见的分布式锁实现方案有以下几种:
- 基于数据库乐观锁,如MySQL(增加字段版本标识version控制实现)
- 基于缓存,如Redis
- 基于Zookeeper、etcd等(ZooKeeper机制规定:同一个目录下只能有一个唯一的文件名,借助ZooKeeper的临时节点实现)
例如两个订单服务,对要更新数据库的数据,如果能获取到相应的锁才能进行后续操作。

分布式锁的几种实现方式
基于MySQL实现分布式锁
当我们想要获得锁时,可以插入一条数据;当需要释放锁的时,可以删除这条数据
CREATETABLE`database_lock`(`id`BIGINTNOTNULLAUTO_INCREMENT,`resource`intNOTNULLCOMMENT'锁定的资源',`description`varchar(1024)NOTNULLDEFAULT""COMMENT'描述',PRIMARYKEY(`id`),UNIQUEKEY`uiq_idx_resource`(`resource`))ENGINE=InnoDBDEFAULTCHARSET=utf8mb4 COMMENT='数据库分布式锁表';
在表database_lock中,resource字段做了唯一性约束,这样如果有多个请求同时提交到数据库的话,数据库可以保证只有一个操作可以成功(其它的会报错:ERROR 1062 (23000): Duplicate entry ‘1’ for key ‘uiq_idx_resource’),那么那么我们就可以认为操作成功的那个请求获得了锁。
基于Redis实现分布式锁
简单实现
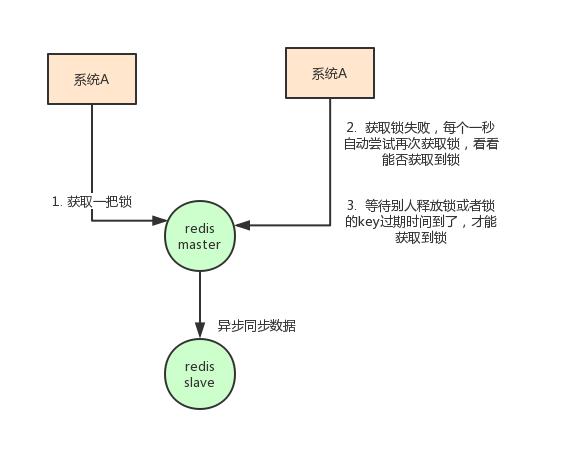
使用Redis做分布式锁的思路大概是这样的:在redis中设置一个值表示加了锁,然后释放锁的时候就把这个key删除。
Redis的缺点与改进
Redis的缺点
使用redis做分布式锁的缺点在于:如果采用单机部署模式,会存在单点问题,只要redis故障了,加锁就不行了。
采用master-slave模式,加锁的时候只对一个节点加锁,即便通过sentinel做了高可用,但是如果master节点故障了,发生主从切换,此时就会有可能出现锁丢失的问题。
RedLock算法
基于以上的考虑,其实redis的作者也考虑到这个问题,他提出了一个RedLock的算法,这个算法的意思大概是这样的:
假设redis的部署模式是redis cluster,总共有5个master节点,通过以下步骤获取一把锁:
- 获取当前时间戳,单位是毫秒
- 轮流尝试在每个master节点上创建锁,过期时间设置较短,一般就几十毫秒
- 尝试在大多数节点上建立一个锁,比如5个节点就要求是3个节点(n / 2 +1)
- 客户端计算建立好锁的时间,如果建立锁的时间小于超时时间,就算建立成功了
- 要是锁建立失败了,那么就依次删除这个锁
- 只要别人建立了一把分布式锁,你就得不断轮询去尝试获取锁
但是这样的这种算法还是颇具争议的,可能还会存在不少的问题,无法保证加锁的过程一定正确。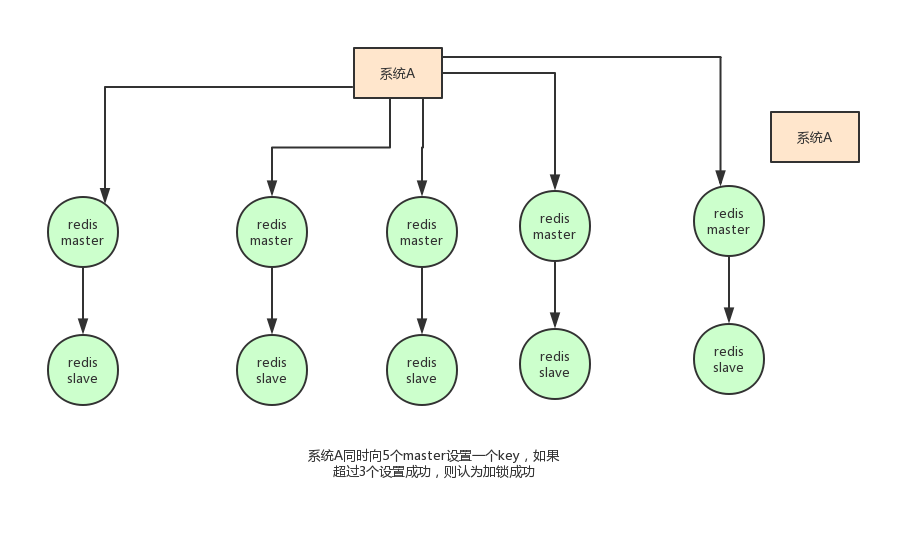
使用Redission
实现Redis的分布式锁,除了自己基于redis client原生api来实现之外,还可以使用开源框架:Redission
Redisson是一个企业级的开源Redis Client,也提供了分布式锁的支持,比较推荐使用,它帮我们考虑了很多细节
- redisson的“看门狗”逻辑保证了没有死锁发生:redisson中有一个watchdog的概念,翻译过来就是看门狗,它会在你获取锁之后,每隔10秒帮你把key的超时时间设为30s,这样的话,就算一直持有锁也不会出现key过期了,其他线程获取到锁的问题了。
- redisson所有指令都通过lua脚本执行,redis支持lua脚本原子性执行
- 提供了对redlock算法的支持

基于Zookeeper实现分布式锁
Zookeeper特性
zookeeper有一些特性使得原生支持分布式锁:
- 有序节点:假如当前有一个父节点为/lock,我们可以在这个父节点下面创建子节点。
- 临时节点:客户端可以建立一个临时节点,在会话结束或者会话超时后,zookeeper会自动删除该节点。
- 事件监听:在读取数据时,我们可以同时对节点设置事件监听,当节点数据或结构变化时,zookeeper会通知客户端。当前zookeeper有如下四种事件: - 节点创建- 节点删除- 节点数据修改- 子节点变更
简单实现
基于以上的一些zk的特性,我们很容易得出使用zk实现分布式锁的落地方案:
- 使用zk的临时节点和有序节点,每个线程获取锁就是在zk创建一个临时有序的节点,比如在/lock/目录下。
- 创建节点成功后,获取/lock目录下的所有临时节点,再判断当前线程创建的节点是否是所有的节点的序号最小的节点
- 如果当前线程创建的节点是所有节点序号最小的节点,则认为获取锁成功。
- 如果当前线程创建的节点不是所有节点序号最小的节点,则对节点序号的前一个节点添加一个事件监听。
- 比如当前线程获取到的节点序号为/lock/003,然后所有的节点列表为[/lock/001,/lock/002,/lock/003],则对/lock/002这个节点添加一个事件监听器。
- 如果锁释放了,会唤醒下一个序号的节点,然后重新执行第3步,判断是否自己的节点序号是最小。
- 比如/lock/001释放了,/lock/002监听到时间,此时节点集合为[/lock/002,/lock/003],则/lock/002为最小序号节点,获取到锁。

使用Curator实现
Curator是一个zookeeper的开源客户端,也提供了分布式锁的实现,底层原理和上面分析的是差不多的

两种方案的优缺点比较
关于Redis
redis分布式锁,其实需要自己不断去尝试获取锁,比较消耗性能。
即便使用redlock算法来实现,在某些复杂场景下,也无法保证其实现100%没有问题,关于redlock的讨论可以看How to do distributed locking
但是另一方面使用redis实现分布式锁在很多企业中非常常见,而且大部分情况下都不会遇到所谓的“极端复杂场景”
所以使用redis作为分布式锁也不失为一种好的方案,最重要的一点是redis的性能很高,可以支撑高并发的获取、释放锁操作。
关于Zookeeper
zookeeper天生设计定位就是分布式协调,强一致性。锁的模型健壮、简单易用、适合做分布式锁。
如果获取不到锁,只需要添加一个监听器就可以了,不用一直轮询,性能消耗较小。
但是zk也有其缺点:如果有较多的客户端频繁的申请加锁、释放锁,对于zk集群的压力会比较大。
版权归原作者 笼中小夜莺 所有, 如有侵权,请联系我们删除。