
一、引言
随着数据量的不断增长,传统的数据处理方式已经无法满足现代企业和组织的需求。Hadoop作为一个开源的分布式计算框架,为大数据处理提供了强大的支持。本文将对Hadoop进行详细介绍,包括其基本概念、核心组件、应用场景以及安装配置等方面。
二、Hadoop概述
Hadoop是一个由Apache基金会所开发的分布式系统基础架构,主要解决的是海量数据的存储和计算问题。Hadoop具有高效、可靠、可扩展和容错性强的特点,使得它成为大数据处理领域的核心框架之一。
Hadoop主要由HDFS(Hadoop Distributed File System)和MapReduce两部分组成。HDFS负责数据的存储,而MapReduce则负责数据的计算。Hadoop通过分布式存储和分布式计算,实现了对海量数据的快速处理和分析。
三、Hadoop核心组件
- HDFS(Hadoop Distributed File System)
HDFS是Hadoop的核心组件之一,它是一个高度容错性的分布式文件系统,能够处理超大数据集。HDFS将数据存储在多个节点上,并通过复制数据来提高数据的可靠性和可用性。HDFS还提供了数据块的概念,将数据分成多个块进行存储,以便进行并行处理。
理解概念图:
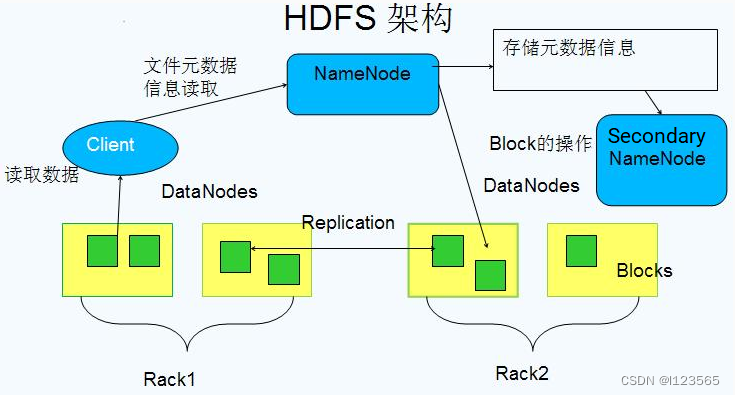
** ** 2**. MapReduce**
MapReduce是Hadoop的另一个核心组件,它是一个编程模型,用于处理和分析大规模数据集。MapReduce将复杂的计算任务拆分成两个简单的函数:Map和Reduce。Map函数对输入数据进行处理并生成中间结果,Reduce函数则对中间结果进行汇总并输出最终结果。MapReduce通过分布式计算,实现了对海量数据的快速处理和分析。
四、Hadoop应用场景
Hadoop广泛应用于各种大数据处理场景,包括但不限于以下方面:
- 日志分析:Hadoop可以处理和分析海量的日志数据,帮助企业了解用户行为、系统性能等信息。
- 搜索引擎:Hadoop可以用于构建搜索引擎的索引和查询系统,实现对海量网页的快速检索。
- 推荐系统:Hadoop可以处理用户的行为数据,为用户提供个性化的推荐服务。
- 金融分析:Hadoop可以用于处理和分析金融数据,如股票交易数据、信贷数据等,为金融机构提供决策支持。
- 科学计算:Hadoop可以处理和分析大规模的科学数据,如气象数据、天文数据等,为科学研究提供支持。
五、Hadoop安装配置
Hadoop的安装配置相对复杂,需要一定的Linux基础和编程能力。以下是一个简化的Hadoop安装配置流程:
- 准备环境:安装Linux操作系统(如Ubuntu、CentOS等),并配置好Java环境。 Java环境是使用hadoop的必要条件,hadoop是基于java的,所以要有java的jdk,如果你不确定自己电脑里面(这里指的是Linux系统)是否有Java环境,可以用一条命令来确认:
java -version如果有的话,会出现一下情况: 如果没有的话需要先行安装(记得是Linux系统的),这里不多展开。
如果没有的话需要先行安装(记得是Linux系统的),这里不多展开。 - 下载Hadoop:从Apache官网下载Hadoop的发行版,并解压到合适的目录。 官网链接:Hadoop 中文网 这是hadoop的中文官网,可以在里面找到自己想要的版本。Hadoop 中文网由于使用的远程连接工具有所不同,到肯定有把文件从Windows上传到Linux的功能,使用cd命令进入文件所在路径,再解压安装,
- 命令:tar -xzvf hadoop-3.1.3.tar.gz -C /usr/local
tar -xzvf hadoop-3.1.3.tar.gz -C /usr/localf: 指文件名(file),tar命令后面会跟随要处理的文件名 hadoop-3.1.3.tar.gz: 要解压的文件的名称(注意看清你的版本号) -C: 指更改目录(change directory),在解压前首先切换到指定的目录。 /opt: 要切换到的目录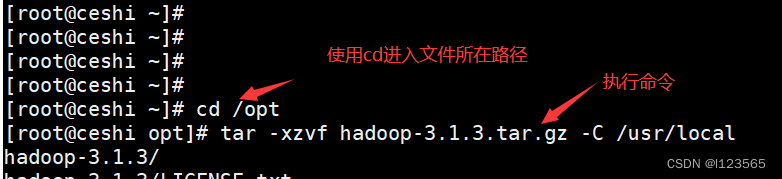 执行命令之后,他就会开始解压文件。
执行命令之后,他就会开始解压文件。 - 配置Hadoop:修改Hadoop的配置文件(如core-site.xml、hdfs-site.xml、yarn-site.xml等),设置HDFS和MapReduce的相关参数。 环境变量设置:
#HADOOP_HOMEexport HADOOP_HOME=/usr/local/hadoop-3.1.3export PATH=$PATH:$HADOOP_HOME/binexport PATH=$PATH:$HADOOP_HOME/sbin配置好环境之后,就可以检测是否安装成功,使用以下命令:hadoop version成功如下: 这样就可以了,其实hadoop主要还是集群,开启集群需要多台电脑(一般是可以是虚拟机多开)。
这样就可以了,其实hadoop主要还是集群,开启集群需要多台电脑(一般是可以是虚拟机多开)。
六、总结
Hadoop作为大数据处理的核心框架之一,具有高效、可靠、可扩展和容错性强的特点。它广泛应用于各种大数据处理场景,为企业和组织提供了强大的数据处理能力。然而,Hadoop的安装配置相对复杂,需要一定的技术基础。因此,对于初学者来说,建议先了解Hadoop的基本原理和核心概念,再逐步深入学习和实践。
版权归原作者 l123565 所有, 如有侵权,请联系我们删除。