
一、HDFS是什么
Hadoop Distributed File System 的缩写,即Hadoop 分布式文件系统
二、HDFS抽象认识
我们打开windows中一个文件的详细信息,看看平时我们用的文件系统是什么样的
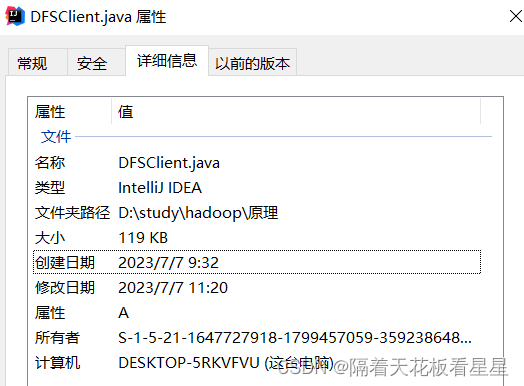
这份文件的详细信息中有文件名称、文件类型、文件夹路径、大小、日期、所有者、计算机归属
因为这是我的个人电脑,所以计算机一栏显示的是这台电脑
那么分布式文件系统是不是就应该显示多台机器中的某一台机器呢?
答案是的
我们按着想象画下我们现在心目中的分布式文件系统是什么样的
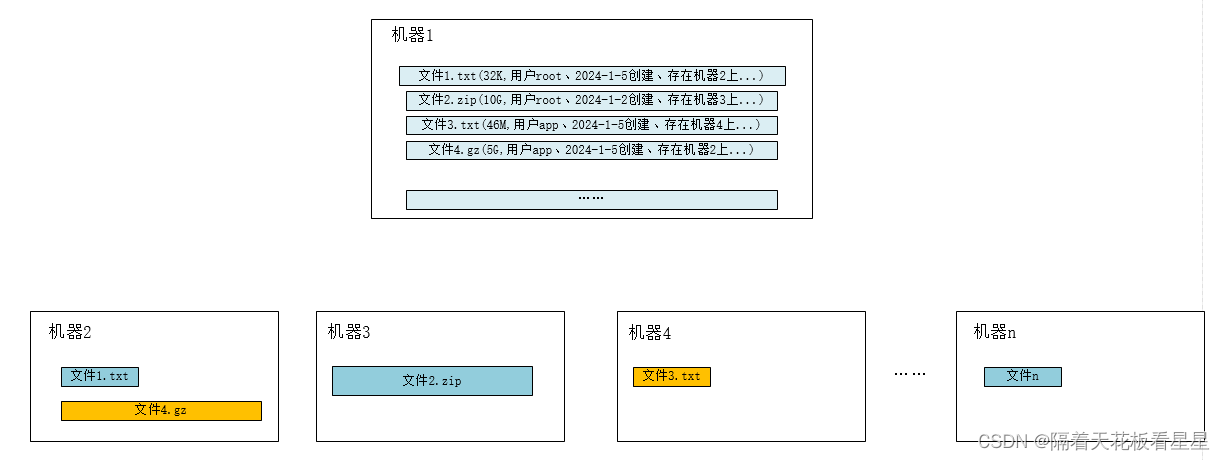
接下来我们去官方网站上验证下我们的想象
三、HDFS官方学习
1、架构描述
下面我们看看 HDFS官方网站上是怎么描述的
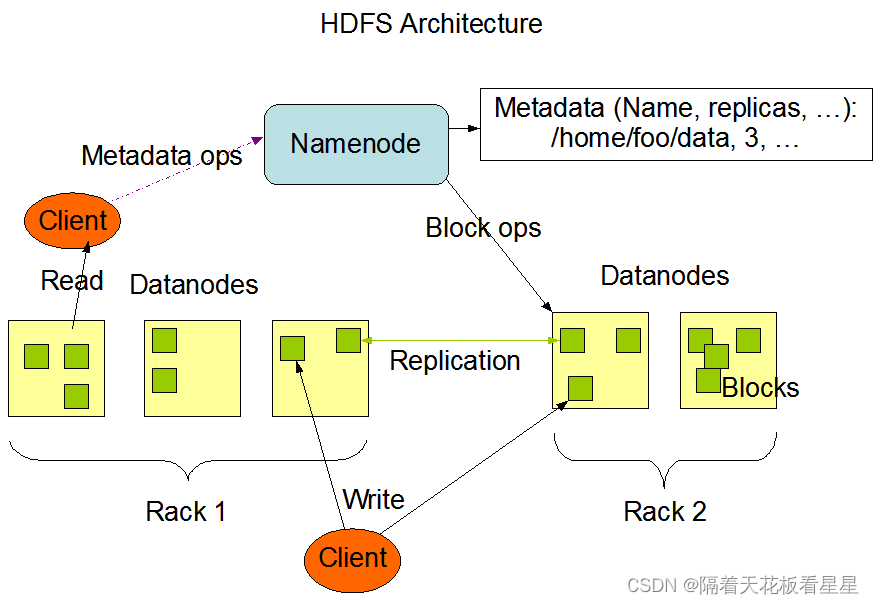
HDFS是主/从架构,有一个NameNode(主)和多个DataNode(从)组成,通常是一个节点一个DataNode。
NameNode负责维护文件系统命名空间,如打开、关闭和重命名文件和目录和文件数据块到某个DataNode的映射。
DataNode负责提供来自文件系统客户端的读写请求,和来自NameNode的指示执行块创建、删除和复制。
NameNode会定期从集群中的每个数据节点接收一个心跳信号和一个块报告。接收到心跳信号意味着DataNode工作正常。块报告包含DataNode上所有块的列表。
2、块描述及放置策略
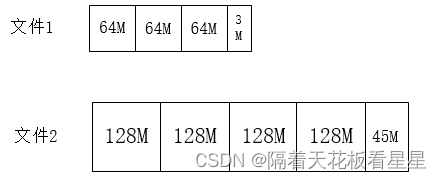
HDFS将每个文件存储为一个块序列,每个文件都可以配置块大小和副本数。文件中除最后一个块外的所有块都是相同的大小。文件在HDFS中就是这样的:
默认情况下每个块会存放三份来实现容错,下面是官方的描述图:
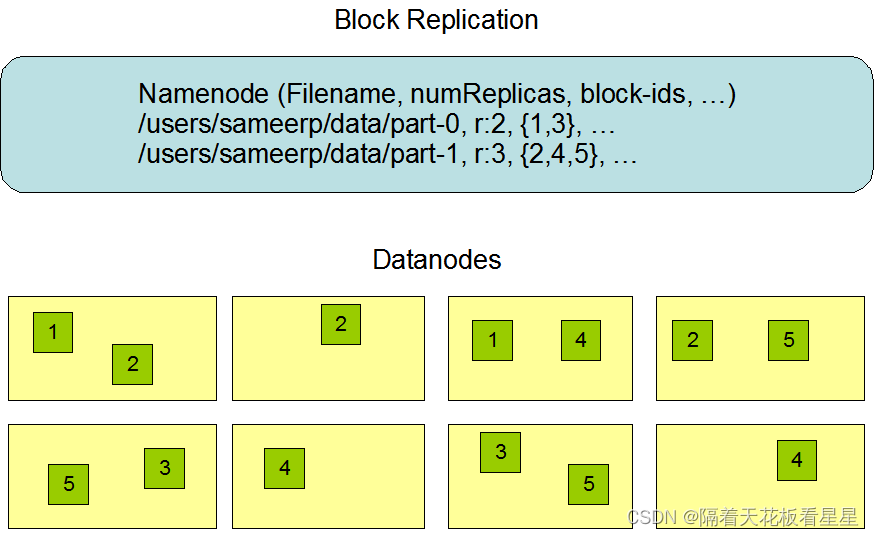
副本的放置对HDFS的可靠性和性能至关重要,需要考虑可靠性、可用性和网络带宽利用率。通常情况下,同一机架中机器之间的网络带宽大于不同机架中机器间的网络带宽。以默认副本数3为例,为了满足可靠性,需要放置到不同机架上,为了降低网络带宽消耗应尽可能的放在一个机架上,因此第一个块会放在本机上(如果写入程序位于DataNode节点放本机,如果不是就放同机架随机节点上),第二个块放不同机架的节点上,第三个块放同机架的不同节点上。此策略可减少机架间写入流量,这通常会提高写入性能。
如果副本数>3,则随机确定第4个和以下副本的位置,同时将每个机架的复制副本数量保持在上限以下,基本上为(副本数-1)/机架+2)。
3、NameNode中元数据的持久化
HDFS命名空间由NameNode存储,NameNode使用一个名为EditLog的事务日志来持久记录文件系统元数据发生的每一次更改。例如,在HDFS中创建一个新文件会导致NameNode在EditLog中插入一条记录来指示这一点。类似地,更改文件的副本数也会导致将新记录插入到EditLog中。NameNode使用其本机文件系统中的文件来存储EditLog。
整个文件系统命名空间,包括块到文件的映射和文件系统属性,都存储在一个名为FsImage的文件中。FsImage也作为文件存储在NameNode的本地文件系统中。
NameNode将整个文件系统命名空间和文件块映射的映像保存在内存中。当NameNode启动时,或者检查点由可配置的阈值触发时,它从磁盘读取FsImage和EditLog,将EditLog中的所有事务应用于FsImage的内存表示,并将此新版本刷新到磁盘上的新FsImage。然后,它可以截断旧的EditLog,开始新的EditLog记录,因为它的事务已应用于持久FsImage。这个过程被称为检查点。检查点的目的是通过获取文件系统元数据的快照并将其保存到FsImage来确保HDFS对文件系统元数据具有一致的视图。
检查点可以在以秒为单位的给定时间间隔(dfs.namenode.checkpoint.eperiod)触发,也可以在累积了给定数量的文件系统事务(dfs.name node.cacheckpoint.txns)之后触发。如果同时设置了这两个属性,则要达到的第一个阈值将触发检查点。
DataNode对HDFS文件一无所知,它只负责存储每个文件中的块。当DataNode启动时,它会扫描其本地文件系统,生成与每个本地文件对应的所有HDFS数据块的列表,并将此报告发送到NameNode。该报告称为区块报告。
4、HDFS的访问方式
HDFS允许以文件和目录的形式组织用户数据。它提供了一个名为FSshell的命令行接口,允许用户与HDFS中的数据进行交互。这个命令集的语法类似于用户已经熟悉的其他shell
比如:
创建目录:hadoop fs -mkdir /test
删除目录:hadoop fs -rm -r /test
查看文件:hadoop fs -cat /test/test.txt
查看文件大小: hadoop fs -du -h /test
对于HDFS管理员可以使用DFSAdmin命令集
将集群置于安全模式:hdfs dfsadmin -safemode enter
生成数据节点列表:hdfs dfsadmin -report
重新部署或停用数据节点:hdfs dfsadmin -refreshNodes
此外HDFS还可以通过多种不同的方式从应用程序访问。在本机中,HDFS为应用程序提供了一个FileSystem Java API以供使用。还可以使用HTTP浏览器和来浏览HDFS实例的文件。
5、HDFS空间回收
如果启用了垃圾桶配置,HDFS中执行文件删除操作时会将其移动到垃圾目录(每个用户在/user/<username>/.trash下都有自己的垃圾目录)。只要文件仍在垃圾中,就可以快速恢复。最近删除的大多数文件都会移动到当前垃圾桶目录(/user/<username>/.trash/current),在可配置的时间间隔内,HDFS会为当前垃圾桶中的文件创建检查点(在/user/<username>/.trash/<date>下),并在旧检查点过期时删除这些检查点。文件的删除会导致与该文件相关联的块被释放,只是时间会延迟些。示例如下:
hadoop fs -rm -r /test
Moved: hdfs://localhost:8020/test to trash at: hdfs://localhost:8020/user/root/.Trash/Current
windows中我们按Shift+delete可以永久删除文件,跳过垃圾桶,HDFS删除时如果加上skipTrash选项也会跳过垃圾桶直接将文件删除
hadoop fs -rm -r -skipTrash /test
Deleted /test
当降低文件的副本数时,NameNode会选择可以删除的多余副本,在下一次DataNode心跳时将此信息传输到DataNode,DataNode删除相应的块。
hadoop fs -setrep -w -R 1 /test
版权归原作者 隔着天花板看星星 所有, 如有侵权,请联系我们删除。