
一、前言
随着大数据技术的飞速发展,实时处理能力变得越来越重要。在众多实时处理框架中,Apache Flink以其强大的流处理能力和丰富的功能集,受到了广泛关注和应用。在实时业务日益增长的趋势下,这促使我们深入探索Flink的内核,以更好地保障Flink任务的维护。本次分享将重点介绍得物在Flink内核方面的探索与实践,探讨如何通过深度优化和定制,实现更加高效和稳定的数据处理能力。
二、读者收益
通过阅读本次分享,读者将获得以下收益:
- 深入理解Flink内核:了解Flink的核心架构和关键组件,掌握Flink内核的运行机制。
- 优化实践:学习得物在Flink优化方面的实战经验,包括如何通过参数调优和内核定制,提升系统性能。
- 问题解决方案:掌握处理Flink常见问题的方法和技巧,提高在实际项目中应对复杂场景的能力。
- 实时处理案例:通过实际案例,了解如何在复杂业务场景中应用Flink,实现高效的实时数据处理。
- 最佳实践:获得得物在Flink应用中的最佳实践建议,帮助在实际项目中少走弯路,提高开发效率。
无论你是刚接触Flink的初学者,还是有一定经验的开发者,相信通过本次分享,都能有所收获,进一步提升在实时数据处理方面的能力。
三、自研特性
自研调度器
Apache Flink是一个开源的流处理框架,调度器是其重要的一部分。
在调度器上,我们新增了一款集合社区各款调度器优点的DwScheduler。
SchedulerNG (interface)
|
+-- SchedulerBase (implements SchedulerNG)
|
+-- DefaultScheduler (extends SchedulerBase 默认资源调度器)
|
+-- AdaptiveBatchScheduler (extends DefaultScheduler 自适应批调度器)
|
+-- SpeculativeScheduler (extends AdaptiveBatchScheduler 预测执行调度器)
|
|
+-- DwScheduler (extends DefaultScheduler 自研调度器)
|
+-- AdaptiveScheduler (implements SchedulerNG 自适应调度器)
- 在流任务生产环境中目前现有的调度并不很理想,在生产中我们常常遇到一些问题,例如:- 任务JobGraph与资源调度没有直接的联系,难于变化和修改;- 不能以TaskManager维度均衡分配所有task到所有slot上;- 1.18以前没有直接动态扩缩容的接口、1.18以后也没有整体算子同时扩缩容的能力;- 流任务调度器没有可以迁移task/Tm的迁移计算节点的能力。
- DwScheduler整合了社区调度器的各项优点,并提供了很多适应我们生产情况的特性:- 建立了JobGraph与资源之间的直接联系,用JSON可修改和表示流图信息和资源并进行调度;- 能够均衡调度所有task到所有TaskManager上;- 支持动态扩缩容各个算子,并且热更新资源规格的能力;- 支持热迁移task/Tm的能力。
下面主要从上述的这四个特性上来重点讲解我们的成果。
简化资源调度
背景:常规通过配置任务的高级参数进行提交任务,不利于资源的拓展,以及用户想设置多个SlotSharingGroup也无法通用地实现。
SQL/DataStream任务都可通过我们的Flink编译器Generator编译完成后生成一个流图资源信息JSON。
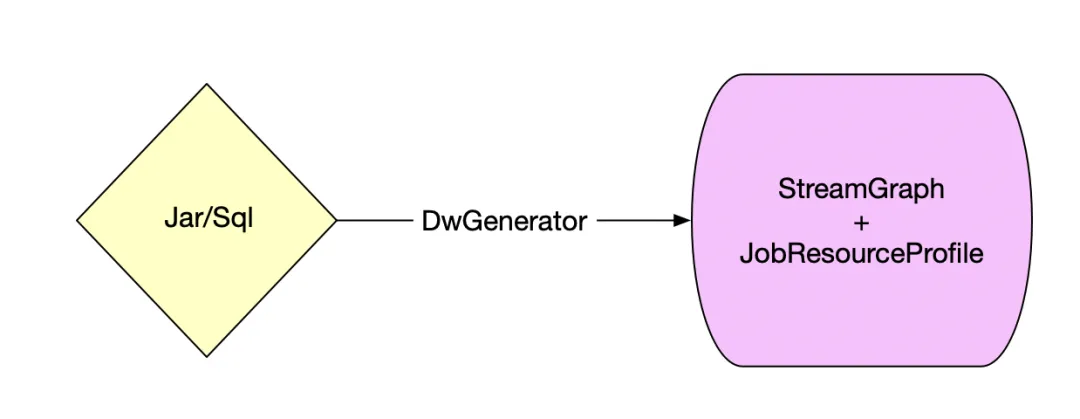
- 调度器支持通过JobResourceProfile JSON信息来进行资源申请。- JobResourceProfile的信息用户可自由编辑,同样我们也提供了便捷的UI给用户操作算子和流图的以及资源的配置。- 我们支持配置算子的并行度、最大并行度、SlotSharingGroup,以及资源的CPU、MEM、堆外内存部分我们也做了合理的管理让用户只需要配置一个比例,自动化设置资源的堆外各项参数降低OOM的风险,简化了用户对资源配置的操作难度。
- 支持接收新的资源资源JobResourceProfile JSON重新调度任务,支持同时扩缩容多个Operator算子的并行度。- 在JobManager里我们提供了接收资源变更的Handler;- DwScheduler可以接收多元化的Service发起过来的资源变更请求;- 并且它提供了六个回调接口,不同的Service可以通过实现它来执行不同的逻辑。
default void preRequestResource() {}
default void postRequestResource(Throwable throwable) {}
default void preRestart() {}
default void postRestart() {}
default void preDeploy() {}
default void postDeploy(Throwable throwable) {}
Flink支持通过资源JobResourceProfile+JobGraph流图提交任务,JM支持动态接收新的JobResourceProfile更新任务资源,可以按标签申请不同的资源机型。
均衡调度Task
背景:Flink的task分配是基于slot维度进行全局调度的,即使配置了cluster.evenly-spread-out-slots 也同样会有在Tm维度上的task分配不均衡的问题。
使用自研调度器的情况下,能够使用JobResourceProfile提前计算出每个TaskManager应该分配多少task,在此基础上我们实现了自己的DwSlotSharingStrategy,可以有效的按TaskManager来分配task个数,而不仅仅是在slot层面做到资源的均衡。
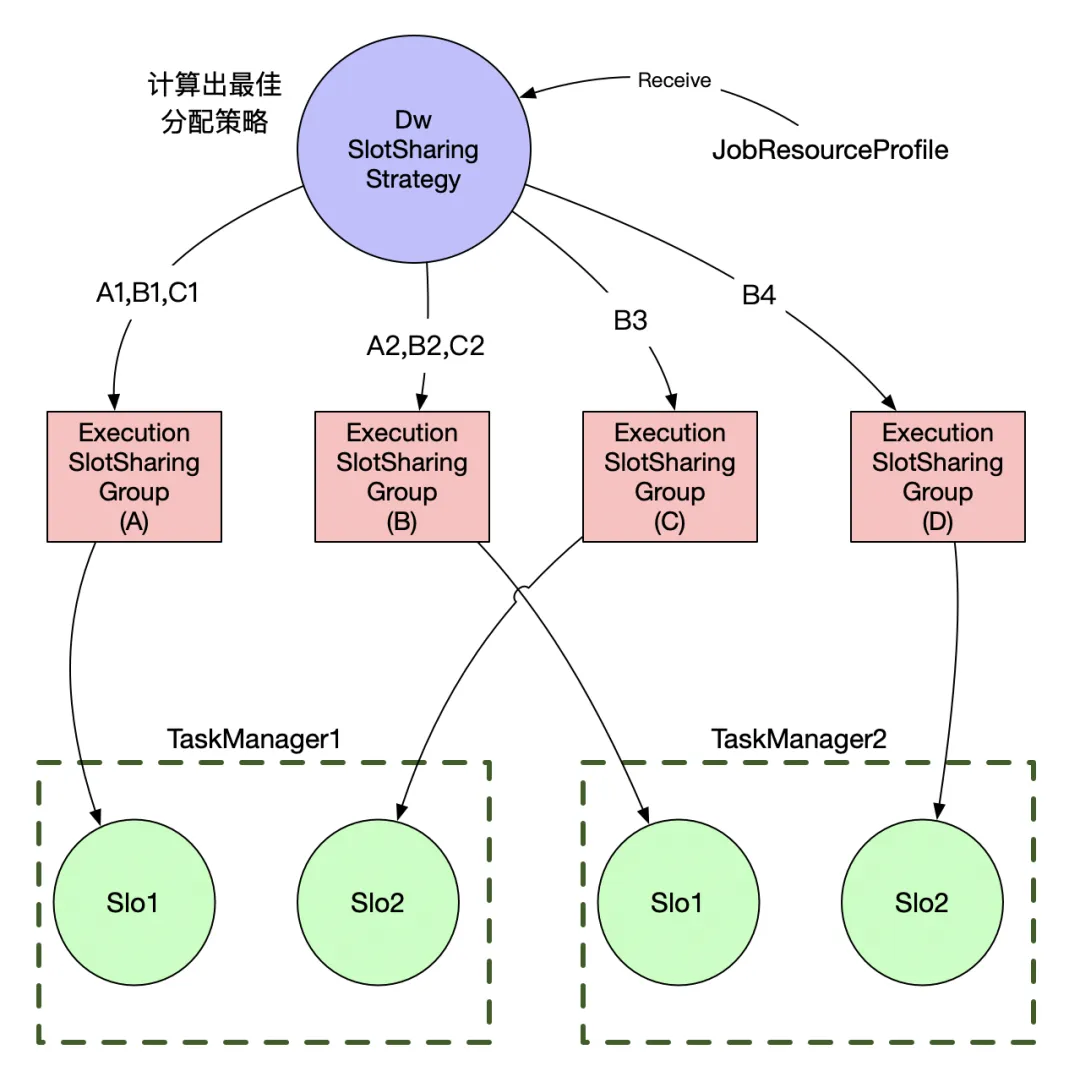
在同一个任务使用原生社区调度器和使用我们自研调度器,我们得出了一些数据效果,从Tm维度来看CPU使用均衡了许多。
从CPU使用率上来看,明显均衡了很多,减少了不均衡分配带来的性能瓶颈问题。
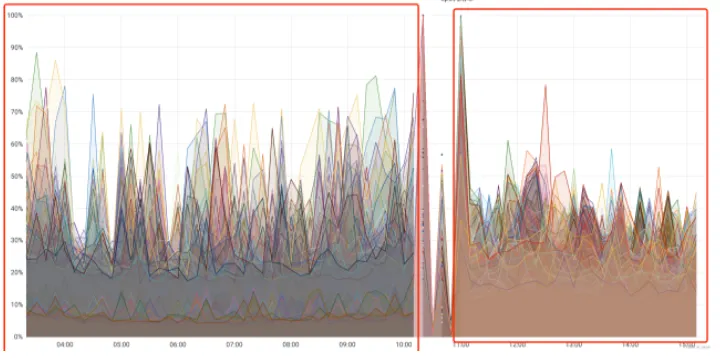
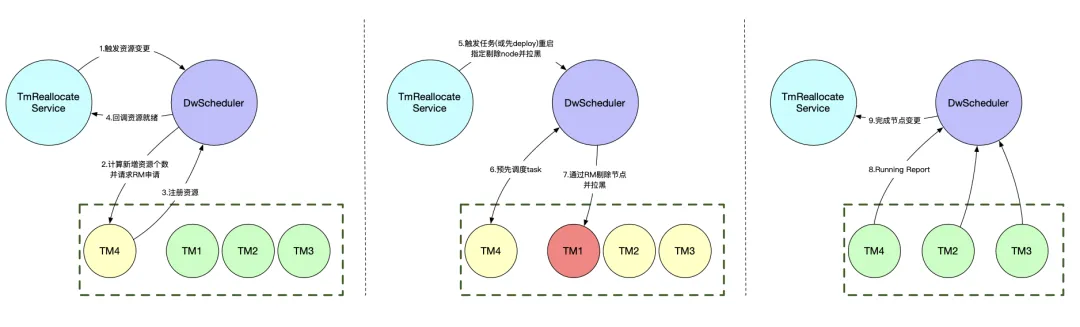
TaskManager热迁移
背景:在日常生产运维中,经常有需要迁移热点机器或故障机器的底层场景,Flink缺乏这部分的热迁移能力。
- 自研Scheduler为我们解决了这一问题,我们支持了热迁移TaskManager- 同样使用DwScheduler提供的六个回调接口以及触发资源变更的请求来完成Tm的热迁移- 热迁移的Service只需要对应地实现下它的功能,不必关心调度的流程
从投入生产迁移Tm资源的断流耗时情况来看,几乎能做到断流1~5s内的快速迁移:
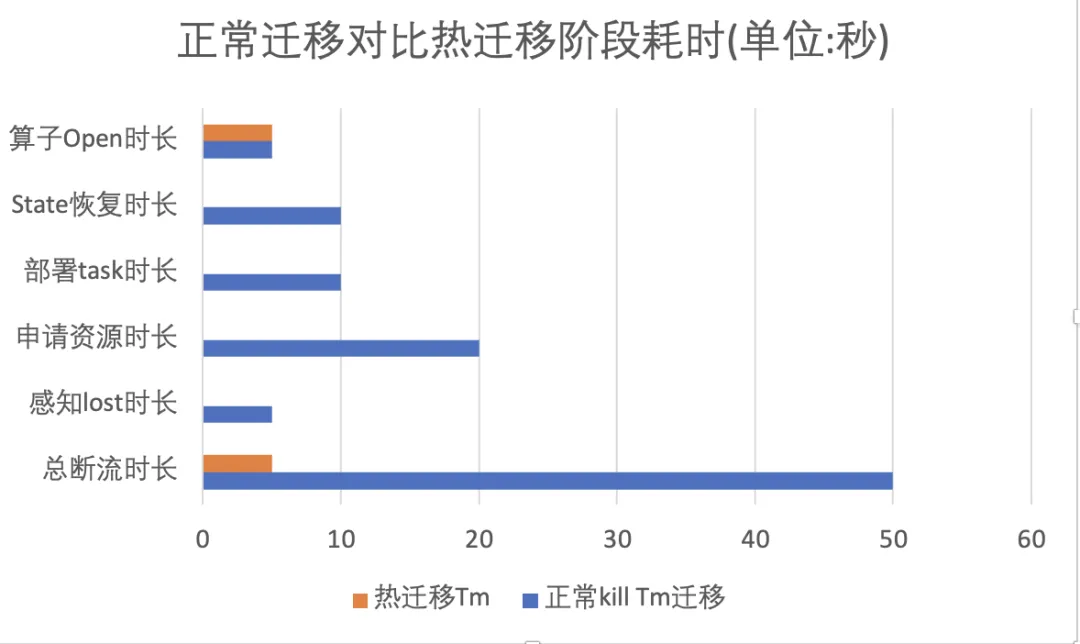
TmRestart重启策略
背景:Flink社区只提供了FullRestart、RegionRestart,往往在生产环境中我们经常会遇到各种不可抗力Cancel用户的代码会超时或堆外有泄漏的情况。
- 为解决这一问题,我们在Restart层面增加了一种TmRestart策略:- 我们将Tm Pod的主进程修改为常驻Shell,可以在Cancel超过一定时间能快速退出进程进行重启,也可以根据JM请求的重启参数直接触发TmRestart;- 修改Pod的主进程我们需要解决一些问题如:信号量传递给子进程、进程返回码的协调与重新拉起;- 另外我们也通过Shell主进程对Tm进程的IO探活、Process D监控等等;- 在重启过程中会对zk有一定的重连,我们改造了这部分代码,尝试无法链接上一次的JM地址失败后才会去访问zk获取最新的leader地址。
- 同时我们也可以调整重新拉起的Tm进程的JVM参数- 在特殊场景通过对Tm退出的异常原因进行分析,列如k8s判定是OOM或是容器等待内存回收的延时分布次数过高,判断重新拉起的Tm是否应该进行JVM参数适当调整。
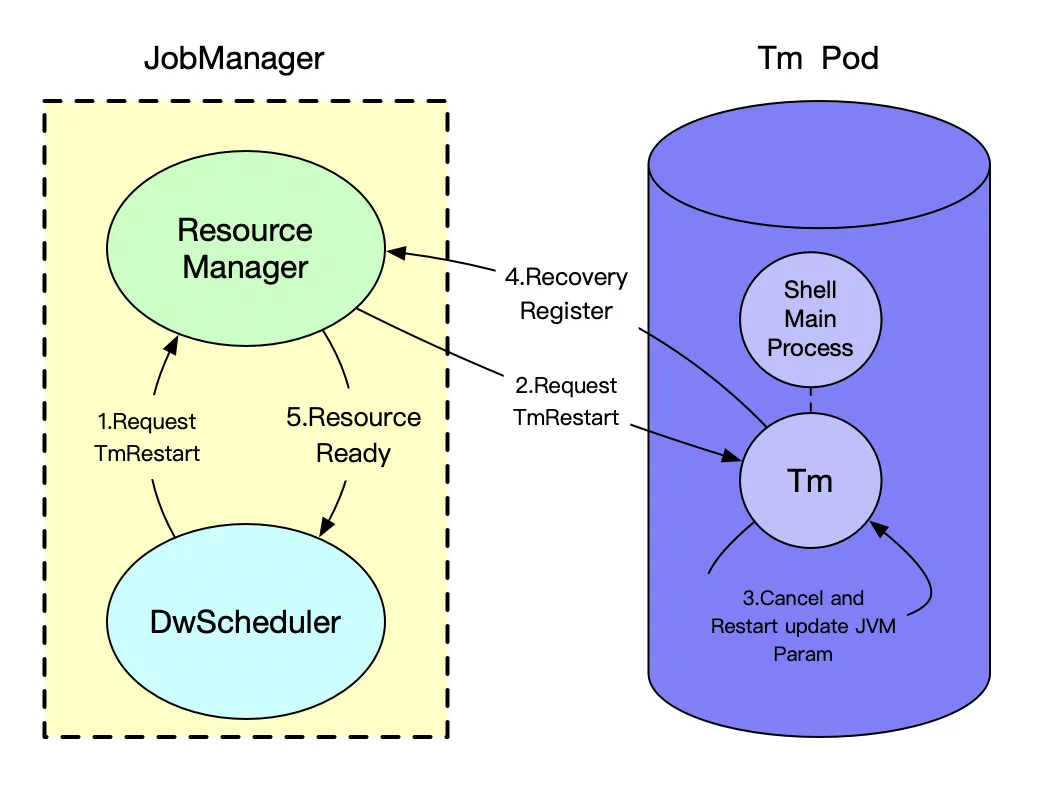
TmRestart重启,可根据任务异常情况、作业配置等按需重启Tm进程,支持修改JVM的参数。
四、总结
本文主要介绍了以下内容:
- Flink调度器的基本生产优化和改造。
- 重建Flink资源模型和支持热迁移等功能的特性介绍。
- Flink的Task分配策略优化和重启逻辑新特性TmRestart。
*文 / 天然卷
本文属得物技术原创,更多精彩文章请看:得物技术
未经得物技术许可严禁转载,否则依法追究法律责任!
版权归原作者 得物技术 所有, 如有侵权,请联系我们删除。