
一、说明
1.1、前言
背景:使用selenium,获取招工平台岗位要求与待遇信息出现报错
环境:windows 10家庭版
语言:python 3
模块:selenium
出现的问题:
selenium.common.exceptions.StaleElementReferenceException: Message: The element reference: element is not attached to the page document
意思是说节点陈旧,使用当前节点找不到信息,是否刷新啥的。
1.2、报错信息
完整报错信息如下:
selenium.common.exceptions.StaleElementReferenceException: Message: The element reference of
is stale; either the element is no longer attached to the DOM, it is not in the current frame context, or the document has been refreshed
Stacktrace:
RemoteError@chrome://remote/content/shared/RemoteError.sys.mjs:8:8
WebDriverError@chrome://remote/content/shared/webdriver/Errors.sys.mjs:182:5
StaleElementReferenceError@chrome://remote/content/shared/webdriver/Errors.sys.mjs:463:5
element.resolveElement@chrome://remote/content/marionette/element.sys.mjs:674:11
evaluate.fromJSON@chrome://remote/content/marionette/evaluate.sys.mjs:255:31
evaluate.fromJSON@chrome://remote/content/marionette/evaluate.sys.mjs:263:29
evaluate.fromJSON@chrome://remote/content/marionette/evaluate.sys.mjs:263:29
receiveMessage@chrome://remote/content/marionette/actors/MarionetteCommandsChild.sys.mjs:74:341.3、报错代码
driver = Firefox() # 创建一个浏览器对象 driver.get("页面url") # 访问网页 # 访问页面后,出现登录或注册弹窗,影响下一步,所以要把弹窗关掉 # 右键检查,选项页面元素,直接复制xpath路径 driver.implicitly_wait(8) # driver.switch_to.window(driver.window_handles[-1]) one_el = driver.find_element(By.XPATH, '//*[@id="cboxClose"]') # 定位标签位置,一般是打叉的位置 one_el.click() # 点击该位置,点击打叉也就是关闭弹窗 time.sleep(3) # 在文本框输入内容,先定位,在输入值,敲回车或者点击搜索 driver.find_element(By.XPATH, '//*[@id="search_input"]').send_keys("python", Keys.ENTER) all_li = driver.find_elements(By.XPATH, '/html/body/div/div[2]/div/div[2]/div[3]/div/div[1]/div') for li in all_li: job_name = li.find_element(By.XPATH, './div/div/div/a').text job_time = li.find_element(By.XPATH, './div/div/div/span').text job_price = li.find_element(By.XPATH, './div/div/div[2]/span').text print(job_name, job_time, job_price)二、解决
2.1、搜索引擎解决
1)首先是使用了搜索引擎进行问题的查找,大概明白了出现这个报错是什么原因(后面会讲),感谢热心网友分享;
2)尝试使用大部分网友分享的办法:使用try,except结构来进行页面的刷新,但是发现报的是一样的错误(此时已经加了延时)
这个办法在我这行不通。。。
2.2、最终解决
输入搜索内容后,进行延迟,确保页面内容可以完整出现,然后在进行刷新(关键是这个,这个刷新使节点更新了),在延迟,使内容完全加载,此时在进行节点与内容的获取。
代码如下:
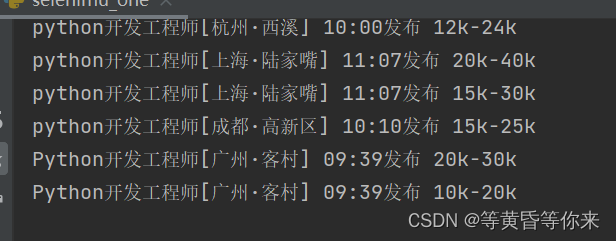
driver = Firefox() # 创建一个浏览器对象 driver.get("页面url") # 访问网页 # 访问页面后,出现登录或注册弹窗,影响下一步,所以要把弹窗关掉 # 右键检查,选项页面元素,直接复制xpath路径 driver.implicitly_wait(8) # driver.switch_to.window(driver.window_handles[-1]) one_el = driver.find_element(By.XPATH, '//*[@id="cboxClose"]') # 定位标签位置,一般是打叉的位置 one_el.click() # 点击该位置,点击打叉也就是关闭弹窗 time.sleep(3) # 在文本框输入内容,先定位,在输入值,敲回车或者点击搜索 driver.find_element(By.XPATH, '//*[@id="search_input"]').send_keys("python", Keys.ENTER) time.sleep(3) # 等待内容加载完成 driver.refresh() # 刷新页面,使节点刷新 time.sleep(3) # 等待页面加载完成,此时的节点才是正确的 all_li = driver.find_elements(By.XPATH, '/html/body/div/div[2]/div/div[2]/div[3]/div/div[1]/div') # a = 1 for li in all_li: job_name = li.find_element(By.XPATH, './div/div/div/a').text job_time = li.find_element(By.XPATH, './div/div/div/span').text job_price = li.find_element(By.XPATH, './div/div/div[2]/span').text print(job_name, job_time, job_price)结果如下图1:
图1
程序能跑了,我不用跑了。
本文转载自: https://blog.csdn.net/qq_57663276/article/details/128495490
版权归原作者 等黄昏等你来 所有, 如有侵权,请联系我们删除。
版权归原作者 等黄昏等你来 所有, 如有侵权,请联系我们删除。