

欢迎来到爱书不爱输的程序猿的博客, 本博客致力于知识分享,与更多的人进行学习交流
本文收录于SQL应知应会专栏,本专栏主要用于记录对于数据库的一些学习,有基础也有进阶,有MySQL也有Oracle

分区表 • MySQL版
一、分区表
1.非分区表
CREATETABLEIFNOTEXISTS student
(id INT, name VARCHAR(50), age INT, address VARCHAR(100));
或
CREATETABLEIFNOTEXISTS`student`(`id`INT,`name`VARCHAR(50),`age`INT,`address`VARCHAR(100));
- 注意: 数据库名、表名、字段名反勾号` 是系统导出DDL语句自带格式,也可以不写。
2.分区表
2.1 概念
分区是一种表的设计模式,通俗地讲表分区是将一大表,根据条件分割成若干个小表。
但是对于应用程序来讲,分区的表和没有分区的表是一样的。
换句话来讲,分区对于应用是透明的,只是数据库对于数据的重新整理。
MySQL在创建表的时候可以通过使用
PARTITION BY
子句定义每个分区存放的数据。在执行查询的时候,优化器根据分区定义过滤那些没有我们需要的数据的分区,这样查询就可以无需扫描所有分区,只需要查找包含需要数据的分区即可。
分区的另一个目的是将数据按照一个较粗的粒度分别存放在不同的表中。这样做可以将相关的数据存放在一起,另外,当我们想要一次批量删除整个分区的数据也会变得很方便(可以单独
truncate分区
)
delete 要记录日志,如果开启事务的话,可以进行回滚,一行一行的删除,效率慢
truncate 直接删除底层的数据页,MySQL的物理结构底层是数据页
2.2 MySQL数据库表分区
2.2.1 InnoDB 逻辑存储结构
- InnoDB存储引擎的逻辑存储结构和Oracle大致相同,所有数据都被逻辑地存放在一个空间中,我们称之为表空间(tablespace。表空间又由段(segment)、区(extent)、页(page) 组成。
- **页在一些文档中有时也称为块(block)**,1 extent = 64 pages
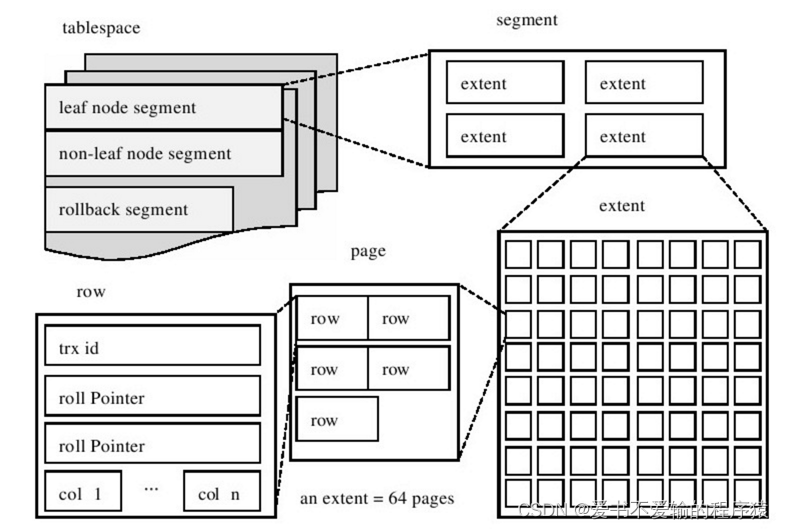
2.2.2 段(segment)
表空间是由各个段组成的,常见的段有数据段、索引段、回滚段等。
- 对于回滚段,进行delete后可以回滚数据,所以delete既占空间也耗时间,truncate相当于直接将页格式化了(不要再讲truncate是讲表删除后又重建了一个,不太恰当)
- InnoDB存储引擎表是索引组织的(index organized),因此数据即索引,索引即数据。那么数据段即为B+树的页节点(上图的leaf node segment),索引段即为B+树的非索引节点(上图的non-leaf node segment)。
- 与Oracle不同的是,InnoDB存储引擎对于段的管理是由引擎本身完成,这和Oracle的自动段空间管理(ASSM)类似,没有手动段空间管理(MSSM)的方式,这从一定程度上简化了DBA的管理。
- 需要注意的是,并不是每个对象都有段。因此更准确地说,表空间是由分散的页和段组成。
2.2.3 区(extent)
区是由64个连续的页组成的,每个页大小为16KB,即每个区的大小为1MB。对于大的数据段,InnoDB存储引擎最多每次可以申请4个区,以此来保证数据的顺序性能。
在我们启用了参数innodb_file_per_talbe后,创建的表默认大小是96KB。
区是64个连续的页,那创建的表的大小至少是1MB才对啊?其实这是因为在每个段开始时,先有32个页大小的碎片页(fragment page)来存放数据,当这些页使用完之后才是64个连续页的申请。这样做得目的是,对于一些小表或者undo类的段,可以开始申请较小的空间,节约磁盘开销
2.2.4 页(page)
页就是上图的page区域,也可以叫块。
页是InnoDB磁盘管理的最小单位。默认大小为16KB,可以通过参数innodb_page_size来设置
常见的页类型有:数据页,undo页,系统页,事务数据页,插入缓冲位图页,插入暖冲空闲列表页,未压缩的二进制大对象页,压缩的二进制大对象页等。
2.3 MySQL数据库分区的由来
- 传统不分区数据库痛点 mysql数据库中的数据是以文件的形式存在磁盘上的,默认放在/mysql/data下面(可以通过my.cnf中的datadir来查看),一张表主要对应着三个文件,一个是frm存放表结构的,一个是myd存放表数据的,一个是myi存表索引的。(这是myisam引攀,如果是innodb,则是frm和ibd文件,索引和数据在一起)
2.4 为什么对表进行分区?
为了改善大型表以及具有各种访问模式的表的可伸缩性,可管理性和提高数据库效率。
2.4.1 表分区要解决的问题
当表非常大,或者表中有大量的历史记录,而“热数据“却位于表的末尾。如日志系统、新闻…此时就可以考虑分区表。(热数据就是经常使用的数据)
【注:此处也可以使用分表,但是会增加业务的复杂性】
2.4.2 表分区有如下优点:
- 与单个磁盘或文件系统分区相比,可以存储更多的数据
- 对于那些已经失去保存意义的数据,通常可以通过删除与那些数据有关的分区,很容易地删除那些数据。 - 相反地,在某些情况下,添加新数据的过程又可以通过为那些新数据专门增加一个新的分区,来很方便地实现。- 同样的,你可以很快的通过删除分区来移除旧数据,还可以优化、检查、修复个别分区
- 一些查询可以得到极大的优化。可以把一些归类的数据放在一个分区中,可以减少服务器检查数据的数量加快查询。 - 这主要是借助于满足一个给定WHERE语句的数据可以只保存在一个或多个分区内,这样在查找时就不用查找其他剩余的分区。
PS:因为分区可以在创建了分区表后进行修改,所以在第一次配置分区方案时还不曾这么做时,可以重新组织数据,来提高那些常用查询的效率。
- 涉及到例如SUM()和COUNT()这样聚合函数的查询,可以很容易地进行并行处理。 - 通过“并行”,这意味着该查询可以在每个分区上同时进行,最终结果只需通过总计所有分区得到的结果。
这种查询的一个简单例子如
SELECT salesperson_id,COUNT(orders)as order_total FROM sales GROUPBY salesperson_id
- 通过跨多个磁盘来分散数据查询,来获得更大的查询吞吐量
2.5 MySQL的分区形式
2.5.1 水平分区(HorizontalPartitioning)
- 这种形式的分区是对根据表的行进行分区,通过这样的方式不同分组里面的物理列分割的数据集得以组合,从而进行个体分别(单分区)或集体分别(1个或多个分区)
- 所有在表中定义的列在每个数据集中都能找到,所以表的特性依然得以保持
- 水平分区一定要通过某个属性列来分别,常见的有年份、日期
2.5.2 垂直分区(VerticalPartitioning)
- 这种分区方式一般来说是通过对表的垂直划分来减少目标表的宽度,是某些特定的列被划分到特定的分区,每个分区都包含了其中的列所对应的所有行
2.6 MySQL分区的类型
- 根据所使用的不同分区规则可以分成几大分区类型

- MySql默认是支持表分区的,可以通过语句查询是否开启表分区功能:
show plugins
2.6.1 range分区:范围表分区,按照一定的范围值来确定每个分区包含的数据
- 语法如下:
partition by range(id) partition p0 values less than() - 示例:
createtableuser(id int(11)notnull,name varchar(32)notnull)-- 正常的创建语句partitionby range(id)-- 根据表字段id来创建分区 <--分区的定义(-- 分区实例 -->partition p0 values less than(10),-- 第一个分区p0,范围~-9partition p1 values less than(20),-- 第二个分区p1,范围10-19partition p2 values less than(30),-- 第三个分区p2,范围20-29partition p3 values less than maxvalue -- 第四个分区p3,范围30-~)-- 需要注意的是分区字段“id”的取值范围等于分区取值范围
maxvalue只是可以这么做,但是实际情况不可能把后面的所有数据都放在同一个分区,如果进行删除的话,那就是直接将后面的所有数据都删除了,不符合业务逻辑- range分区,一般用于生产运维、比较固化的调度场景,很少进行补数据的操作,如果涉及到补数据 - 根据上面的分区,假设要把范围15-19的放在一个新的分区,这就需要用到其他的手段,如重组分区
recognation,如果是Oracle的话,还需要进行split,对分区进行一个分割- 以后想补旧的数据的时候,假设对第一个分区进行再分割,很不方便,之后会用存储过程进行存取数据的操作,存储过程的变量定义都是写死的,很难去增加一个范围分区(往后增加可以,比如上面的maxvalue,但是不能往前增加,比如上面的第一个分区的前面)

版权归原作者 爱书不爱输的程序猿 所有, 如有侵权,请联系我们删除。