
一、前言
上一章学习了ES的索引相关操作,那么这一章就轮到映射,了解映射操作最重要的点就是去学习ES的数据类型。那么本章我们会了解到映射的创建、查看和修改操作,然后详细介绍ES中的基本数据类型和复杂的数据类型,并且会对常用的类型和用法进行示范,最后介绍映射的常用参数和动态映射的使用。
我们知道在使用数据之前,需要构建数据的组织结构。这种组织结构在关系型数据库中叫作表结构,在ES中叫作映射。作为无模式搜索引擎,ES可以在数据写入时猜测数据类型,从而自动创建映射。但有时ES创建的映射中的数据类型和目标类型可能不一致。当需要严格控制数据类型时,还是需要用户手动创建映射。
二、映射操作
2,1、查看映射
在ES中查看文档映射的请求类型是GET,其请求形式如下:
GET /${index_name}/_mapping
上面的index_name就是搜索名称。例如查看索引hotel的mappings,请求的DSL如下:
GET /hotel/_mapping
请求的返回结果如下:
{"hotel":{"mappings":{"properties":{"city":{"type":"keyword"#定义city字段类型为keyword},
"price":{"type":"double"#定义price字段类型为double},
"title":{"type":"text"#定义title字段类型为text}}}}}
通过返回信息可见,查看索引hotel的mappings时,返回的信息和建立该索引时的信息是一致的。
2.2、扩展映射
可能有的读者看到标题会有疑问:映射不能修改吗?为什么叫扩展呢?答案是:映射中的字段类型是不可以修改的,但是字段可以扩展。最常见的扩展方式是增加字段和为object(对象)类型的数据新增属性。下面的DSL示例为扩展hotel索引,并增加tag字段
POST /hotel/_mapping
{"properties":{"tag":{"type":"keyword"#索引中新增字段tag,类型为keyword}}}
查看索引hotel的mappings,返回结果如下:
{"hotel":{"mappings":{"properties":{"city":{"type":"keyword"},
"price":{"type":"double"},
"tag":{"type":"keyword"},
"title":{"type":"text"}}}}}
又返回结果可知,tag字段已经被添加到索引hotel中。
2.3、基本的数据类型
2.3.1.keyword类型
keyword类型是不进行切分的字符串类型。这里的"不进行切分"指的是:在索引时,对keyword类型的数据不进行切分,直接构建倒排索引;在搜索时,对该类型的查询字符串不进行切分后的部分匹配。keyword类型数据一般用于对文档的过滤、排序和聚合.
在现实场景中,keyword经典用于描述姓名、产品类型、用户ID、URL和状态码等。keyword类型数据一般用于比较字符串是否相等,不对数据进行部分匹配,因此一般查询这种类型的数据时使用term查询。
例如,我们的hotel索引中有一个city字段类型是keyword,我们查询它的数据,请求的DSL如下:
GET /hotel/_search
{"query":{"term":{"city":{"value":"成都"}}}}
返回的信息结果如下: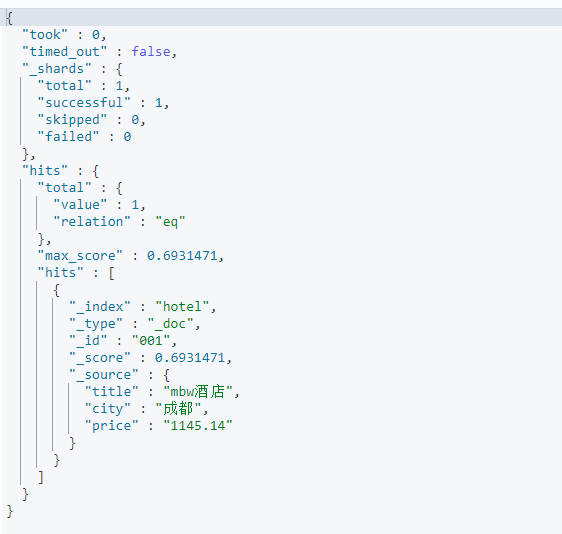
由搜索结果可以看出,使用term进行全字符串匹配“成都”可以搜索到命中文档。下面的DSL使用match搜索城市中带有“成”的记录:
GET /hotel/_search
{"query":{"match":{"city":"成"}}}
返回结果如下: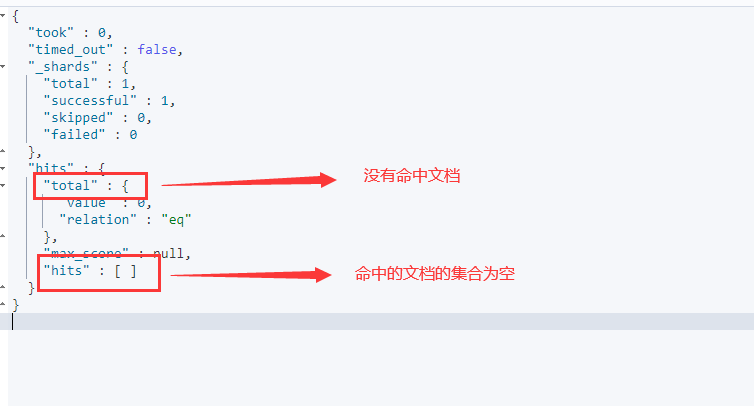
由搜索结果可见,对keyword类型使用match搜索进行部分匹配是不会命中文档的。印证keyword是不进行切分的字符串类型。
2.3.2、text类型
text类型是可进行切分的字符串类型。这里的“可切分”指的是:在索引时,可按照相应的切词算法对文本内容进行切分,然后构建倒排索引;在搜索时,对该类型的查询字符串按照用户的切词算法进行切分,然后对切分后的部分匹配打分。
例如,一个酒店搜索项目,我们希望可以根据酒店名称即title字段进行模糊匹配,因此可以设定title字段为text类型,那之前我们创建hotel索引的时候就已经创建好了text类型的title字段,这里不做赘述。
现在往hotel类型写入一条数据:
POST /hotel/_doc/004
{"title":"爱情公寓",
"city":"成都市天府一街",
"price":"1145.14"}
下面先按照普通的term搜索,观察能否搜索到刚刚写入的文档,请求的DSL如下:
GET /hotel/_search
{"query":{"term":{"title":{"value":"爱情公寓"}}}}
ES返回结果如下: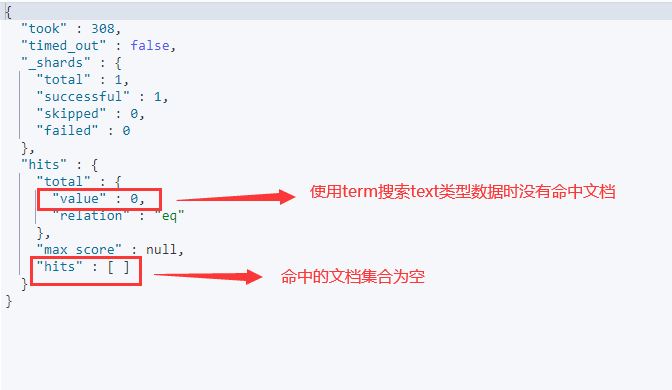
根据返回结果,上面的请求并没有搜索到文档。term搜索用于搜索值和文档对应的字段是否完全相等,而对于text类型的数据,在建立索引时ES已经进行了切分并建立了倒排索引,关于这个切分后文会详细介绍。因此使用term没有搜索到的数据。一般情况下,搜索text类型的数据时应使用match搜索。关于match搜索的具体使用,后面的章节会详细介绍,本节仅进行简单的使用:
GET /hotel/_search
{"query":{"match":{"city":"成都"}}}
ES返回结果如下:
当然有时也会出现text类型好像切分了”但又没切分“的情况,这个先看下面例子,等后面学习分词算法会详细解释,例如我增加如下数据:
POST /hotel/_doc/003
{"title":"爱情公寓",
"city":"成都市天府一街",
"price":"1145.14"}
POST /hotel/_doc/004
{"title":"爱情公寓",
"city":"成都市天府二街",
"price":"1145.14"}
这个时候match我拿成都去搜:
GET /hotel/_search
{"query":{"match":{"city":"成都"}}}
按理说应该能搜出新增的,but: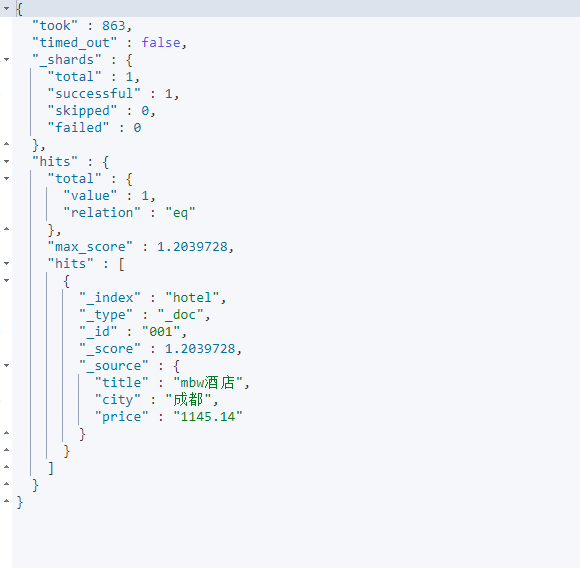
然后你会发现你用成都市,天府这样的词去搜仍然搜不出,只有把全程输入搜索,才可以搜得到,类似keyword类型不切分的性质,所以这一点需要大家注意下,分词算法不一定每次都能成功生效。示例如下:
GET /hotel/_search
{"query":{"match":{"city":"成都市天府一街"}}}
这样才能成功搜索出:
2.3.3、数值类型
ES支持的数值类型有long、integer、short、byte、double、float、half_float、scaled_float和unsigned_long等。各类型所表达的数值范围可以参考官方文档,网址为https://www.elastic.co/guide/cn/elasticsearch/guide/current/foreword_id.html.**为节约存储空间并提升搜索和索引的效率,在实际应用中,在满足需求的情况下应尽可能选择范围小的数据类型**。比如,年龄字段的取值最大值不会超过200,因此选择byte类型即可。数值类型的数据也可用于对文档进行过滤、排序和聚合。
以酒店搜索为例,酒店的索引除了包含酒店名称和城市之外,还需要定义价格、星级和评论数等,创建索引的DSL如下:
POST /hotel/_mapping
{"properties":{"name":{"type":"text"},
"city":{"type":"keyword"},
"price":{"type":"double"},
"star":{#定义星级字段,类型为byte"type":"byte"},
"comment_count":{#定义评论数字段,类型为integer"type":"integer"}}}
对于数值型数据,一般使用term搜索或者范围搜索。例如,搜索价格为350~400(包含350和400)元的酒店,搜索的DSL如下:
GET /hotel_1/_search
{"query":{"range":{"comment_info.good_comment":{"gte":50,
"lte":200}}}}
2.3.4、布尔类型
布尔类型使用boolean定义,用于业务中的二值表示,如商品是否售罄,房屋是否已租,酒店房间是否满房等。**写入或者查询该类型的数据时,其值可以使用true和false,或者使用字符串形式的"true"和"false"**。下面的DSL定义索引中"是否满房"的字段为布尔类型:
POST /hotel/_mapping
{"properties":{"full_room":{"type":"boolean"}}}
对于布尔类型,一般使用term搜索,例如下面的DSL将查询满房的酒店:
GET /hotel/_search
{"query":{"term":{"full_room":{"value":true}}}}
2.3.5、日期类型
在ES中,日期类型的名称为date.ES中存储的日期是标准的UTC格式。下面定义索引hotel,该索引有一个create_time字段,现在把它定义成date类型。定义date类型请求的DSL如下:
POST /hotel/_mapping
{"properties":{"create_time":{"type":"date"}}}
一般使用如下形式表示日期类型数据:
- 格式化的日期字符串
- 毫秒级的长整型,表示从1970年1月1日0点到现在的毫秒数
- 秒级别的整型,表示从1970年1月1日0点到现在的秒数。
日期类型的默认格式为strict_date_time||epoch_millis.其中,strict_date_optional_time的含义是严格的时间类型,支持yyyy-MM-dd、yyyyMMdd、yyyyMMddHHmmss、yyyy-MM-ddTHH:mm:ss、yyyy-MM-ddTHH:mm:ss.SSS和yyyy-MM-ddTHH:mm:ss.SSSZ等格式,epoch_millis的含义是从1970年1月1日0点到现在的毫秒数。
下面写入索引的文档中有一个create_time字段是日期格式的字符串,请求的DSL如下:
POST /hotel/_doc/006
{"name":"miss酒店1",
"city":"成都",
"price":"1145.14",
"create_time":"20230117"}
搜索日期型数据时,一般使用ranges查询。例如,搜索创建日期为2015年的酒店,请求的DSL如下:
GET /hotel/_search
{"query":{"range":{"create_time":{"gte":20221220,
"lte":20230120}}}}
日期类型默认不支持yyyy-MM-dd HH:mm:ss格式,如果经常使用这种格式,可以在索引的mapping中设置日期字段的format属性为自定义格式。下面的示例将设置新增的update_time字段的格式为yyyy-MM-dd HH:mm:ss(因为create_time已经建立,无法在修改其格式,只能通过扩展字段的方式设定其格式为自定义格式)
POST /hotel/_mapping
{"properties":{"update_time":{"type":"date",
"format":"yyyy-MM-dd HH:mm:ss"}}}
ps:如果使用这样的自定义格式,从另一方面来说也定死了该格式,只能使用指定日期类型数据放入索引。此时如果再写入不符合刚刚定义格式的日期数据,便会报如下错误: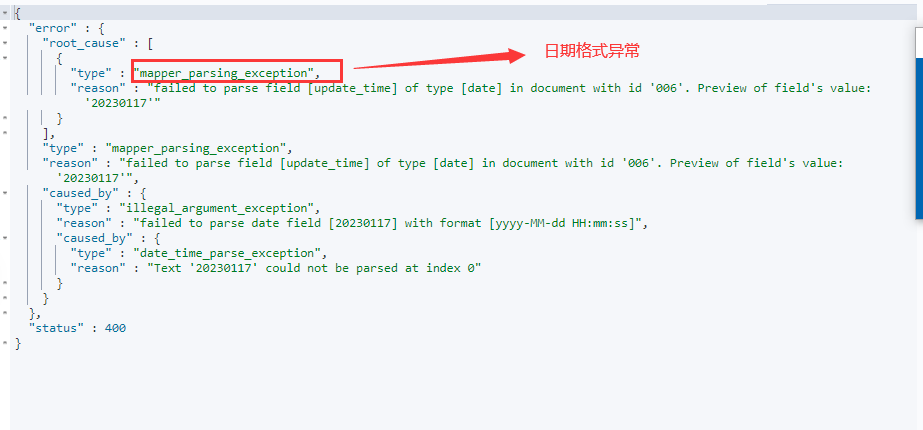
根据错误信息可知,错误的原因是写入的数据格式和定义的数据格式不同。此时需要写入的格式为yyy-MM-dd HH:mm:ss的文档,请求的DSL如下:
POST /hotel/_doc/007
{"name":"miss酒店1",
"city":"成都",
"price":"1145.14",
"update_time":"2023-01-17 11:57:30"}
发现添加成功。
2.4、复杂的数据类型
2.4.1、数组类型
ES数组没有定义方式,其使用方式是开箱即用的,即无须事先证明,在写入时把数据用中括号[]括起来,由ES对该字段完成定义。
当然。如果事先已经定义了字段类型,在写数据时以数组形式写入,ES也会将该类型转为数组。例如,我们之前在hotel索引定义了city字段。我们可以查看下hotel的索引映射结构: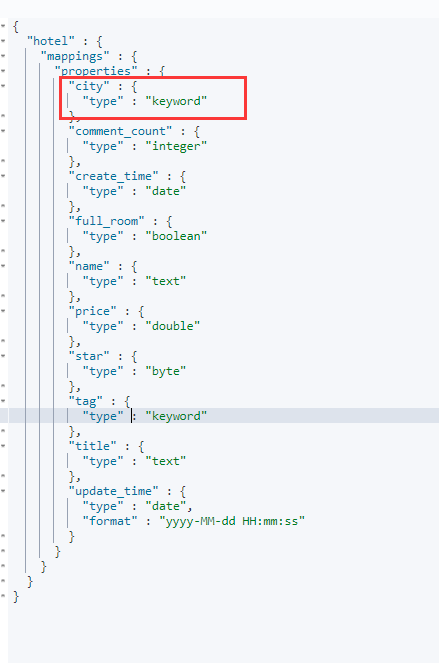
通过返回的mapping信息来看,city字段与普通的keyword类型字段没什么区别,现在写入一条数据:
POST /hotel/_doc/008
{"name":"miss酒店1",
"city":["成都","上海"], #写入字符串数组数据"price":"1145.14"}
查看一下写入的数据,ES返回的信息如下: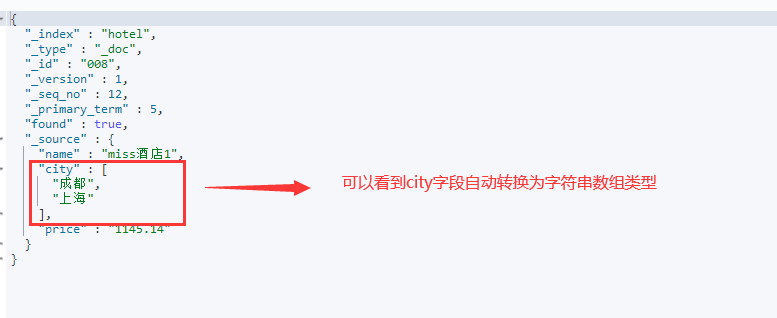
但是你去查看索引映射,city仍然是keyword类型,所以让我来比喻的话,大家可以将其想象成List<>尖括号中的泛型,类似List<keyword> 。
通过以上信息可以看到,写入的数据的city字段已经是数组类型了。那么,数组类型的数据如何搜索呢?
数组类型的字段适用于元素类型的搜索方式,也就是说,数组元素适用于什么搜索,数组字段就适用于什么搜索。例如数组元素类型是keyword,该类型适用于term搜索,则city字段也可以用于term搜索,搜索的DSL如下:
GET /hotel/_search
{"query":{"term":{"city":{"value":"上海"}}}}
ES中的空数组可以作为missing field,即没有值的字段,下面的DSL将插入一条city为空的数组:
POST /hotel/_doc/009
{"name":"miss酒店1",
"city":[], #写入空数组"price":"1145.14"}
该文档数据如下: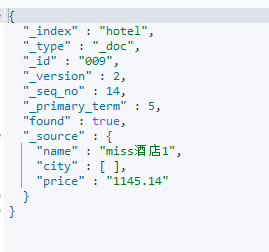
2.4.2、对象类型
在实际业务中,一个文档需要包含其他内部对象。例如,在酒店搜索需求中,用户希望酒店信息中包含评论数据。评论数据分为好评数量和差评数量。为了支持这种业务,在ES中可以使用对象类型。和数组类型一样,对象类型也不用事先定义,在写入文档的时候ES会自动识别并转换为对象类型。
如下,在hotel索引中添加一条记录,请求的DSL如下:
POST /hotel/_doc/010
{"name":"miss酒店1",
"city":"厦门",
"price":"1145.14",
"comment_info":{"good_comment":200,
"bad_comment":70
}}
执行已上DSL后,索引hotel增加了一个字段comment_info,它有两个属性,分别是good_comment和bad_comment,二者的类型都是long。下面查看mapping进行验证:
{"hotel":{"mappings":{"properties":{"city":{"type":"keyword"},
"comment_count":{"type":"integer"},
"comment_info":{#评论数据"properties":{"bad_comment":{#好评数据,类型为long"type":"long"},
"good_comment":{#差评数据,类型为long"type":"long"}}},
"create_time":{"type":"date"},
"full_room":{"type":"boolean"},
"name":{"type":"text"},
"price":{"type":"double"},
"star":{"type":"byte"},
"tag":{"type":"keyword"},
"title":{"type":"text"},
"update_time":{"type":"date",
"format":"yyyy-MM-dd HH:mm:ss"}}}}}
根据对象类型中的属性进行搜索,可以直接用"."操作符进行指向。例如,搜索Hotel索引中好评数大于100的文档,请求的DSL如下:
GET /hotel/_search
{"query":{"range":{"comment_info.properties.good_comment":{"gte":100}}}}
返回结果如下: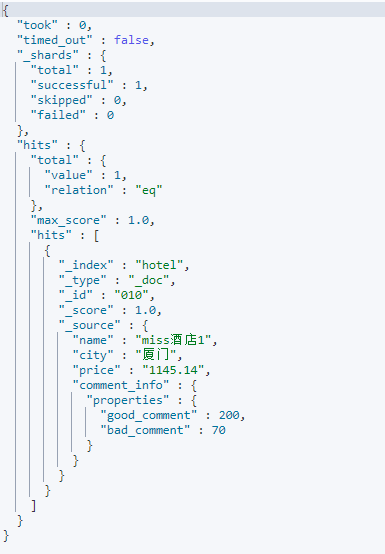
当然,对象内部还可以包含对象。例如,评论信息字段comment_info可以增加前3条好评数据,请求的DSL如下:
POST /hotel/_doc/012
{"name":"miss酒店1",
"city":"厦门",
"price":"1145.14",
"comment_info":{"good_comment":200,
"bad_comment":70,
"top2_good_comment":{"top1":{"content":"very good",
"score":87
},
"top2":{"content":"good",
"score":90
}}}}
以上请求,对文档的comment_info字段增加了前2条评论的内容和评分数据.
2.4.3、地理类型
在移动互联网时代,用户借助移动设备产生的消费也越来越多。例如,用户需要根据某个地理位置来搜索酒店,此时可以把酒店的经纬度数据设置为地理数据类型。该类型的定义需要在mapping中指定目标字段的数据类型为geo_point类型,也就意味着需要事先定义,示例如下:
POST /hotel/_mapping
{"properties":{"location":{"type":"geo_point"#定义字段location,类型为geo_point}}}
其中,location字段定义为地理类型,现在向索引中写入一条酒店文档,DSL如下:
POST /hotel/_doc/013
{"name":"miss酒店1",
"city":"上海",
"price":"1145.14",
"location":{"lat":40.012134,
"lon":116.497553}}
2.5、动态映射
当字段没有定义时,ES可以根据写入的数据自动定义该字段的类型,这种机制叫作动态映射。其实,在前面的章节中我们已经用到了ES的动态映射机制。在介绍数组类型和对象类型时提到,这两种类型都不需要用户提前定义,ES将根据写入的数据自动创建mapping中对应的字段并指定类型。对于基本类型,如果字段没有定义,ES在将数据存储到索引时会进行自动映射,如下表所示为自动映射时的JSON类型和索引数据类型的对应关系。
JSON类型索引类型null不新增字段true或falsebooleanintegerlongobjectobject(对象)array根据数组中的第一个非空值进行判断stringdate、double、long、text,根据数据形式进行判断
在一般情况下,如果使用基本类型数据,最好先把数据类型定义好,因为ES的动态映射生成的字段类型
可能会与用户的预期有差别。例如,写入数据时,由于ES对于未定义的字段没有类型约束,如果同一字段的数据形式不同(有的是字符型,有的是数值型),则ES动态映射生成的字段类型和用户的预期可能会有偏差。提前定义好数据类型并将索引创建语句纳入SVN或者Git管理范围是良好的编程习惯,同时还能增强项目代码的连贯性和可读性。
下面来演示一下动态映射出现偏差的场合,创建空的索引hotel_5
PUT /hotel_5
直接在该索引下添加数据,注意price我们虽然用字符串包装,但是我们希望它的类型是double
POST /hotel_5/_doc/001
{"name":"miss酒店1",
"city":"厦门",
"price":"1145.14"}
此时查看hotel_5的索引映射: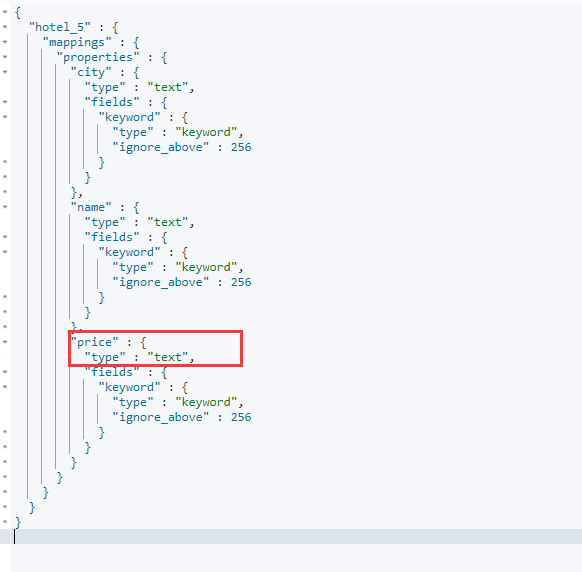
发现它赋予price的类型是text,并非我们希望的double类型。所以基本类型大家尽量提前定义,大家可能会比较感兴趣为什么这个映射的字段type已经定义了text,但是下面还有一个field类型,还将其定义为keyword类型,这个就是后面会提到的多字段。
2.6、多字段
针对同一个字段,有时需要不同的数据类型,这通常表现在为了不同的目的以不同的方式索引相同的字段。例如,在订单搜索系统中,既希望能够按照用户姓名进行搜索,又希望按照姓氏进行排列,可以在mapping定义中将姓名字段先后定义为text类型和keyword类型,其中,keyword类型的字段叫作子字段,这样ES在建立索引时会将姓名字段建立两份索引,即text类型的索引和keyword类型的索引。订单搜索索引的定义如下:
PUT /hotel_order
{"mappings":{"properties":{"username":{"type":"text",
"fields":{"username_keyword":{"type":"keyword"}}}}}}
可以看出,正常定义username字段后,使用fields定义其子字段的定义方式和普通字段的定义方式相同。
为方便演示,批量写入如下数据,我们会用到/bulk批量导入命令,注意/bulk批量导入文档不能有换行符
POST /_bulk
{"index":{"_index":"hotel_order","_id":"001"}}{"username":"Mike JorDan"}{"index":{"_index":"hotel_oder","_id":"002"}}{"username":"Tom JorDan"}{"index":{"_index":"hotel_order","_id":"003"}}{"username":"Kobi JorDan"}
可以在普通搜索中使用user_name字段,比如我们通过其text类型的搜索以及通过keyword类型对用户名全称进行升序排序,DSL如下:
GET /hotel_order/_search
{"query":{"match":{"username":"JorDan"}},
"sort":[{"username.username_keyword":{"order":"asc"}}]}
搜素结果如下: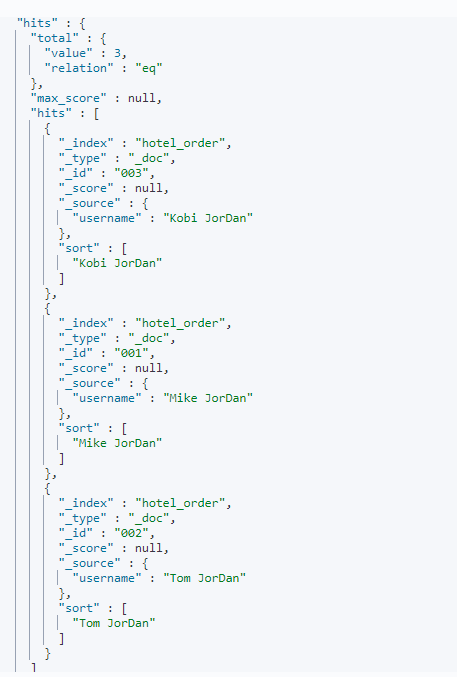
根据以上结果可知,搜索Jordan之后,添加的4个文档都命中并且排序时是按照用户姓名的全程进行排序的。
版权归原作者 雨~旋律 所有, 如有侵权,请联系我们删除。