
前提:在虚拟机中安装好Hadoop
参考文章:HDFS编程实践(Hadoop3.1.3)_厦大数据库实验室博客 (xmu.edu.cn)
实验要求
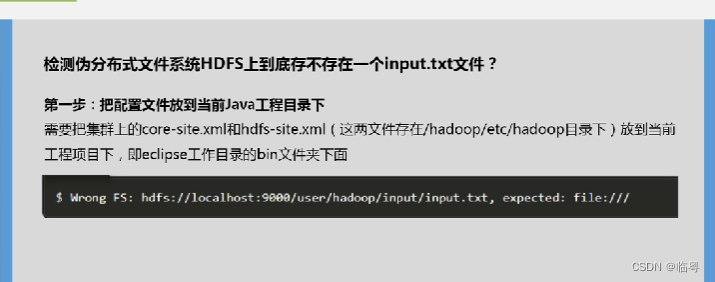
编写shell与Java代码检验分布式系统HDFS上是否存在一个input.txt,并对代码进行详细注释,通过流程图阐述数据查找过程。
实验步骤
1. **做好前提准备**
** ①启动Hadoop**
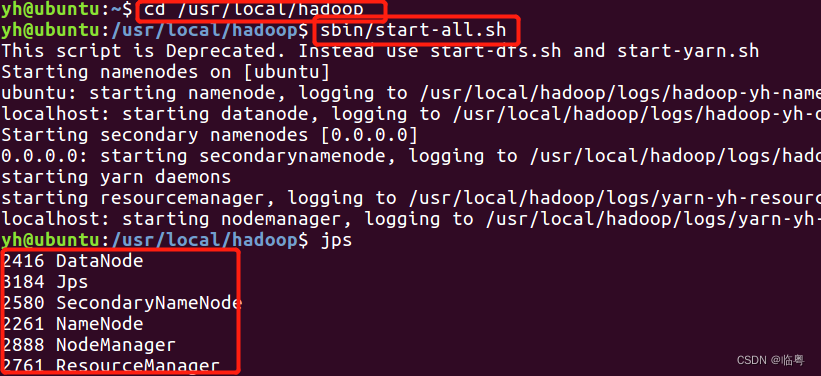
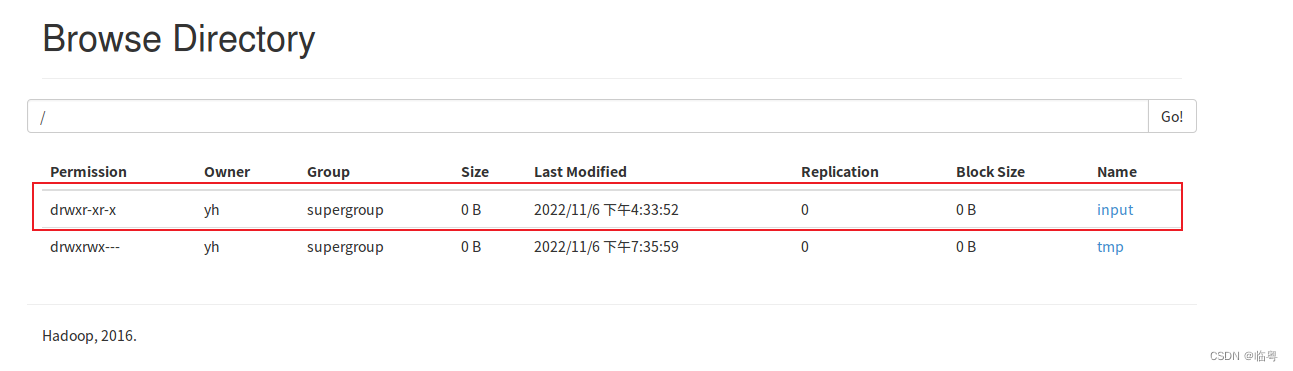
**②使用Hadoop内的hdfs创建文件夹用于存储文件,可以实现对照**
** 使用的命令为:./bin/hdfs/dfs -mkdir /input**

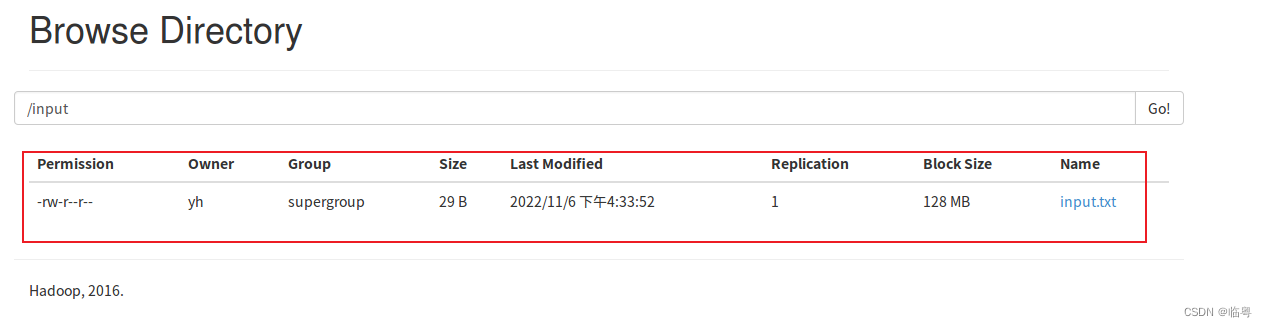
** ③上传本地文件到hdfs中**
** 使用的命令为:./bin/hdfs dfs -put /usr/local/hadoop/input/txt /input**



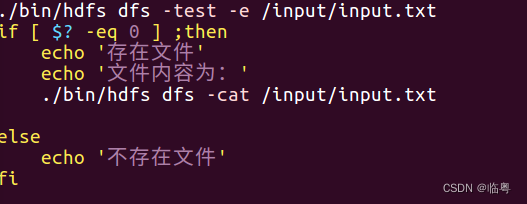
** 2. 使用shell编程实现判断文件是否存在,如存在就输出文件的内容。**
** ①命令行直接实现**
./bin/hdfs dfs -test -e /input/input.txt
echo $?
**如果输出为 0 代表文件存在;如果输出为1,代表文件不存在。**

** ②通过shell编程实现文字版的输出**
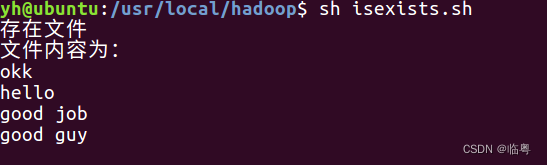
** 3. 使用java代码判断文件是否存在,如存在就输出文件的内容。**
import java.io.BufferedReader;//java读取文件的相关包
import java.io.InputStreamReader;
//导入相关包
import org.apache.hadoop.conf.Configuration;//这个包是专门管理配置文件的
//这个包中包含了hadoop中所有关于文件管理的类,所有的都是继承它
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;//可以读取url路径
import org.apache.hadoop.fs.FSDataInputStream;
//FileSystem对象中的open()方法返回的是FSDataInputStream对象,这个类是继承了java.io.DataInputStream接口的一个特殊类
//支持随机访问,可以从流中的任意位置读取数据
public class Hdfs {
public static void main(String[] args){
try{
String fileName = "/input/input.txt";//文件的路径
//加载配置项
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.43.100:8020");//文件系统的路径(这个需要看自己在配置core-site.xml时使用的路径)
//DistributedFileSystem是在HDFS客户端的节点上,负责与HDFS集群进行交互,如在NameNode上读写元数据,在DataNode节点上读写数据等
conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");
//创建文件系统实例
FileSystem fs = FileSystem.get(conf);
//判断文件是否存在
if(fs.exists(new Path(fileName))){
//如果文件存在就打印输出
System.out.println("文件存在");
//打印输出文本内容
Path file = new Path(fileName);
FSDataInputStream getIt = fs.open(file);
//缓冲区读取,避免了乱码现象
BufferedReader d = new BufferedReader(new InputStreamReader(getIt));
String line = null;
System.out.println("文件的内容为:");
while((line = d.readLine()) != null) {
System.out.println(line);
}
d.close(); //关闭文件
}else{
System.out.println("文件不存在");
}
//如果报错的话,就打印输出错误信息
}catch (Exception e){
e.printStackTrace();
}
}
}
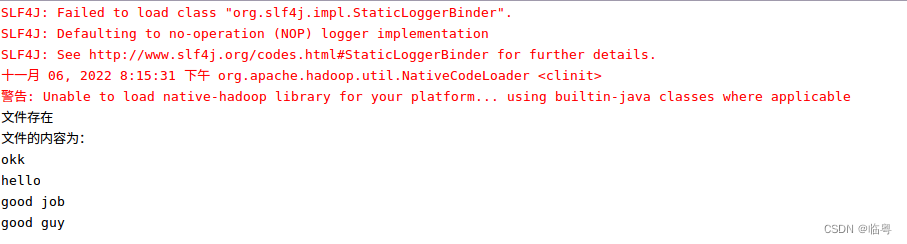
结果输出
小贴士
- 在Ubuntu中安装eclipse
教程:打开底部的软件安装软件-->搜索eclipse-->安装
- 创建Java project
将Hadoop相关的库导入
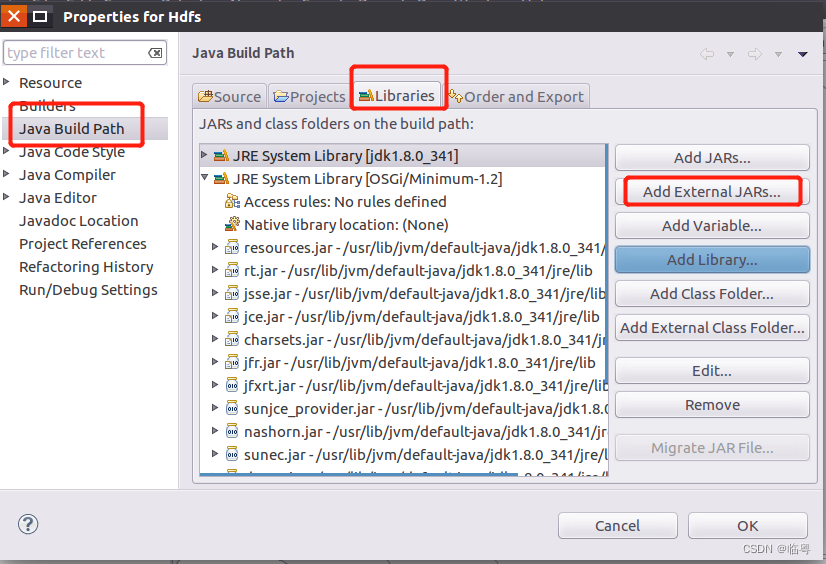
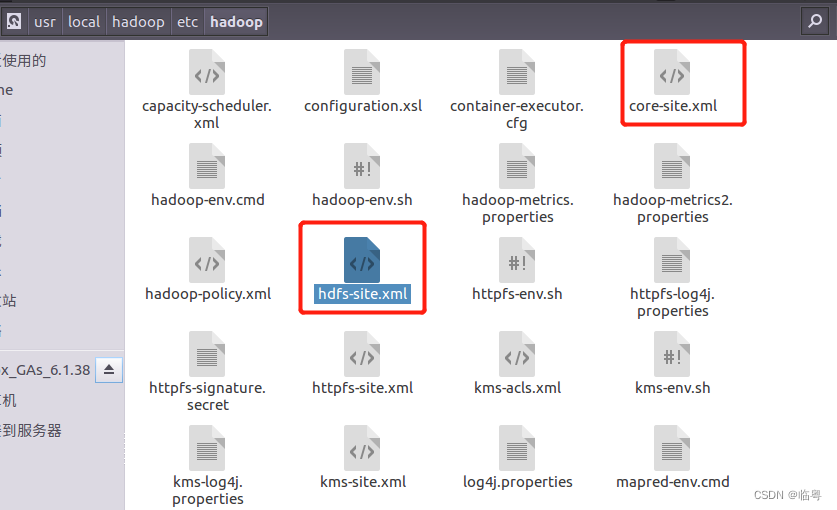
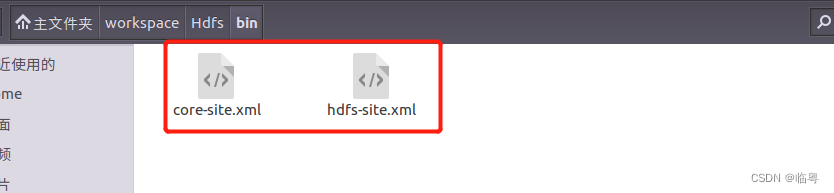
- 将Hadoop配置文件中的core-site.xml以及hdfs-site.xml复制到创建好的java project的bin目录下(要不然会报错的)
实验中遇到的问题及解决方法
- 实验中导包问题
在实验的过程中,按照林子雨老师的教程,只是把那几个Hadoop包导入进去就OK的,但是在实际中,还需要导入其他的库,其他库分别分布在Hadoop其他目录下,需要自己找一下。
(可能是我在安装Hadoop的时候放乱了)
贴一些因为jar包没导入而报的错

贴一些解决方法(其他库分别分布在Hadoop其他目录下,需要自己找一下)
Exception in thread “main” java.lang.NoClassDefFoundError: com/google/common/base/Preconditions_五道口纳什的博客-CSDN博客
org.apache.hadoop.util.PlatformName_鱿鱼ing的博客-CSDN博客
- 上传文件提示失败
 这是因为DataNode节点没有启动成功
这是因为DataNode节点没有启动成功
可以看另外一篇文章的文末
大数据技术原理与应用-实验一-Hadoop的安装与使用_临粤的博客-CSDN博客
- Caused by: java.net.ConnectException: 网络不可达 (connect failed)
解决方法:看java代码中连接hdfs的链接是否跟配置core-site.xml中hdfs的路径一致。我们在配置hdfs-site.xml时,里面可能填写的是IP地址+8020,但是在Java代码中我们填写了localhost+9000,两者不一致,导致连接不上。
实验参考厦门大学老师的hdfs编程教程
如果有什么错漏的地方,请各位大佬指教[抱拳]
版权归原作者 遮望眼 所有, 如有侵权,请联系我们删除。