
(零)本文简介
Paimon多流拼接/合并性能优化;
为解决离线T+1多流拼接数据时效性、Flink实时状态太大任务稳定性问题,这里基于数据湖工具Apache Paimon进行**近实时**的多流拼接。
使用Flink+Paimon基于**ParmaryKey Table**(**PartialUpdate**)进行多流拼接的时候,跑一段时间有时会遇到**周期性背压、checkpoint时间过长**等情况,本文通过剖析源码逻辑、修改源码,在一定程度上解决了这个问题。
note:下文对源码的修改可能需要了解一点paimon的实现原理比如:LSM Tree(level DB);
可参考:LSM树详解 - 知乎
LSM(Log-Structured Merge Tree)_lsm tree_一介草民kk的博客-CSDN博客
Apache Paimon基础 、多流拼接方法 及 与Hudi 的对比 可参考前面文章:
新一代数据湖存储技术Apache Paimon入门Demo_Leonardo_KY的博客-CSDN博客
基于数据湖的多流拼接方案-HUDI概念篇_Leonardo_KY的博客-CSDN博客
意外收获:
本文通过修改源码还意外解决了【跨分区关联率偏低】的问题(详见下文)。
(一)背景
这里使用 Flink 1.14 + Apache Paimon 0.5 snapshot 进行多流拼接(前端埋点流 + 服务端埋点流);
当前情况是一天一个分区,一个分区100个bucket;就会出现如下情况:分区/bucket中的数据越来越多,到达下午或者傍晚的时候就会出现 paimon 作业周期性背压(因为*mergeTree中维护的数据越来越多,tree越来越大*),checkpoint时间也会比较长;于是决定将mergeTree中的**过期数据删除**,即让其不进入tree中,减少计算量;
这里的“**过期**”按需自定义,比如调研发现99.9%的数据都可以使用3个小时之内的数据拼接上,那就根据时间戳与当前时间戳(假设没有很严重的消费积压)相比,时间差超过3小时的数据就将其丢弃;
具体细节涉及到(这里先将结论给出):
- data文件创建后是否还会修改?(不会)2. 根据时间排序的data数据文件是增量还是全量?(几个最新文件加起来就是全量)3. 应该根据dataFile的创建/修改时间判断过期 还是 通过具体每个record字段值的时间戳判断过期?(通过record)
(二)探索梳理过程
1、首先观察hdfs文件之后发现,dataFile只保留最近一个小时的文件,超过一小时的文件就会被删除,这里应该对应参数 partition.expiration-check-interval = 1h,由此可知data文件不是增量的【下文compact只有几个文件再次加强验证】(那么就不能通过dataFile的最新修改时间判断文件过期将数据过滤);
2、观察flink log发现,每次compaction都只读几个文件,如下所示:

每次其实只读取一个level0的file,再加上几个level5的file(level5这里file就是之前的全部数据,包含多个流的),最后将compact之后的文件再命名为新的名字写到level5;
随着分区数据量的增多,参与compact的file也会越来越多(这也是会导致tree偏大,出现周期性背压的原因);
另外,dataFile命名呈现如下规律:
level5的第二个文件总是跟第一个中间隔一个(这个跟改源码没有关系,只是适合观察规律);

到晚间的时候参与compact的file更多了:

3、观察每次level5生成的dataFile(理论上level5的dataFile会越来越大/多,当单个文件大小超过**128M *(1+rate)**时,会生成新文件);
所有level5的文件大小加起来会越来越大,即永远是呈增长趋势;
如下每一层的总大小在不断增大,同时当文件到一定程度之后,每层2个文件变成3个文件;

4、【以上3点均为原始实现思路,从这里开始改造】思考:既然已知每个bucket中只要最新的几个dataFile就包含了全部的data数据(dataFile不是增量的),那么就不能通过文件最新修改时间来判断数据是否过期,只能从最新的几个dataFile的每条记录来进行判断了,即原本每次参与合并的record是从这个partition+bucket建立开始的全部数据,那么是否可以通过修改源码判断每条record是否过期,从而不参与mergeTree,在compact完成之后也不会再次写入新的dataFile(如果还是写进来,每次读进tree时都需要判断是否过期,是否进入tree)?【答案当然是可以的!】
(三)源码改造
1、首先说明一下,在源码中有这么一段
// IntervalPartition.partition()
public List<List<SortedRun>> partition() {
List<List<SortedRun>> result = new ArrayList<>();
List<DataFileMeta> section = new ArrayList<>();
BinaryRow bound = null;
for (DataFileMeta meta : files) {
if (!section.isEmpty() && keyComparator.compare(meta.minKey(), bound) > 0) {
// larger than current right bound, conclude current section and create a new one
result.add(partition(section));
section.clear();
bound = null;
}
section.add(meta);
if (bound == null || keyComparator.compare(meta.maxKey(), bound) > 0) {
// update right bound
bound = meta.maxKey();
}
}
if (!section.isEmpty()) {
// conclude last section
result.add(partition(section));
}
return result;
}
此处为了将文件排序、再将有overlap的放在一个list里边,一但产生gap(即没有overlap),那么就创建新的list,最终将这些 list 再放到List>中:
示意图如下:

2、后续通过一些处理变成 List> 的格式,这里的KeyValue就包含我们想要去操纵的record!
源码是这样的:
public <T> RecordReader<T> mergeSort(
List<ReaderSupplier<KeyValue>> lazyReaders,
Comparator<InternalRow> keyComparator,
MergeFunctionWrapper<T> mergeFunction)
throws IOException {
if (ioManager != null && lazyReaders.size() > spillThreshold) {
return spillMergeSort(lazyReaders, keyComparator, mergeFunction);
}
List<RecordReader<KeyValue>> readers = new ArrayList<>(lazyReaders.size());
for (ReaderSupplier<KeyValue> supplier : lazyReaders) {
try {
readers.add(supplier.get());
} catch (IOException e) {
// if one of the readers creating failed, we need to close them all.
readers.forEach(IOUtils::closeQuietly);
throw e;
}
}
return SortMergeReader.createSortMergeReader(
readers, keyComparator, mergeFunction, sortEngine);
}
这里的return就会创建sortMergeReader了,我们可以在将数据传入这里之前,先进行过滤(通过判断每一条record是否超过过期时间),修改如下:
public <T> RecordReader<T> mergeSort(
List<ReaderSupplier<KeyValue>> lazyReaders,
Comparator<InternalRow> keyComparator,
MergeFunctionWrapper<T> mergeFunction)
throws IOException {
if (ioManager != null && lazyReaders.size() > spillThreshold) {
return spillMergeSort(lazyReaders, keyComparator, mergeFunction);
}
List<RecordReader<KeyValue>> readers = new ArrayList<>(lazyReaders.size());
for (ReaderSupplier<KeyValue> supplier : lazyReaders) {
try {
// 过滤掉过期数据
RecordReader<KeyValue> filterSupplier =
supplier.get()
.filter(
(KeyValue keyValue) ->
isNotExpiredRecord(
keyValue.value(), expireTimeMillis));
readers.add(filterSupplier);
} catch (IOException e) {
// if one of the readers creating failed, we need to close them all.
readers.forEach(IOUtils::closeQuietly);
throw e;
}
}
return SortMergeReader.createSortMergeReader(
readers,
keyComparator,
mergeFunction,
sortEngine,
keyType.getFieldTypes(),
valueType.getFieldTypes());
}
// 判断这条数据是否过期
public boolean isNotExpiredRecord(InternalRow row, long expireTimeMillis) {
if (expireTimeMillis <= 0) {
return true;
}
// 只要有一个字段不为空,且大于0,且过期时间大于expireTimeMillis,就判断为过期
for (Integer pos : expireFieldsPosSet) {
if ((!row.isNullAt(pos))
&& row.getLong(pos) > 0
&& (System.currentTimeMillis() - row.getLong(pos)) > expireTimeMillis) {
return false;
}
}
return true;
}
与此同时,将相关参数暴露出来,可以在建表时进行自定义配置:
public static final ConfigOption<Integer> RECORDS_EXPIRED_HOUR =
key("record.expired-hour")
.intType()
.defaultValue(-1)
.withDescription(
"Records in streams WON'T be offered into MergeTree when they are expired."
+ " (Inorder to avoid too large MergeTree; -1 means never expired). ");
public static final ConfigOption<String> RECORDS_EXPIRED_FIELDS =
key("record.expired-fields")
.stringType()
.noDefaultValue()
.withDescription(
"Records in streams WON'T be offered into MergeTree when they are judged as [expired] according to these fields."
+ "If you specify multiple fields, delimiter is ','.");
使用方法:
val createPaimonJoinTable = (
s"CREATE TABLE IF NOT EXISTS ${paimonTable}(\n"
+ " uuid STRING,\n"
+ " metaid STRING,\n"
+ " cid STRING,\n"
+ " area STRING,\n"
+ " ts1 bigint,\n"
+ " ts2 bigint,\n"
+ " d STRING, \n"
+ " PRIMARY KEY (d, uuid) NOT ENFORCED \n"
+ ") PARTITIONED BY (d) \n"
+ " WITH (\n" +
" 'merge-engine' = 'partial-update',\n" +
" 'changelog-producer' = 'full-compaction', \n" +
" 'file.format' = 'orc', \n" +
s" 'sink.managed.writer-buffer-memory' = '${sinkWriterBuffer}', \n" +
s" 'full-compaction.delta-commits' = '${fullCompactionCommits}', \n" +
s" 'scan.mode' = '${scanMode}', \n" +
s" 'bucket' = '${bucketNum}', \n" +
s" 'sink.parallelism' = '${sinkTaskNum}', \n" +
s" 'record.expired-hour' = '3' , \n" + // user defined para
" 'record.expired-fileds' = '4,5' , \n" + // user defined para
" 'sequence.field' = 'ts1' \n" +
")"
)
tableEnv.executeSql(createPaimonJoinTable)
(四)修改效果
1、JOB状态
运行到晚上20点尚未出现背压:

checkpoint时间也没有过长(如果不剔除过期数据,到这个时间cp时长应该在3分钟左右):

生产到Kafka的消息也没有严重的断流或者锯齿现象:

还是有可能出现exception如下(但对数据量没有任何影响):


2、Level5的dataFile总大小
上边只是现象,最终还是要数据说话。
修改源码之后,观察dataFile,理论上每一层的size总大小可能会出现减小的情况 (因为过期数据就不会再写入到 level5 新的data文件中了)
如下图:levelSize diff(下一次level总size - 上一次level总size),确实出现了**“有正有负”**的情况,于是验证源码修改生效(即每次进行compact只会读取近 n 个小时的数据进行合并)!

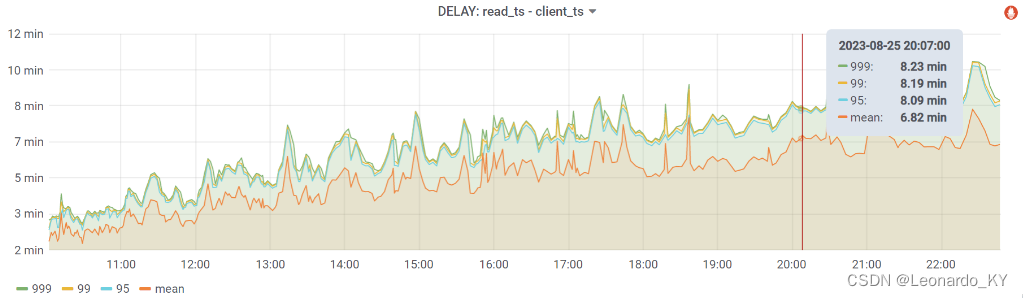
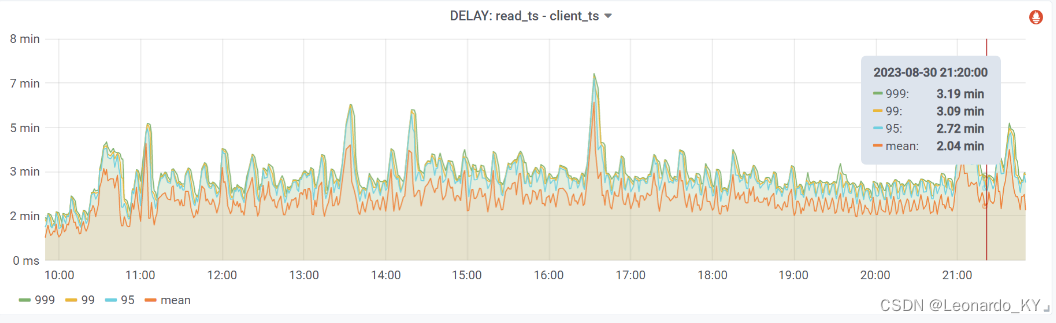
3、数据延迟
有意思的是,当我们修改源码(将过期的数据丢弃)之后,数据延迟也变小了。
数据延迟计算方法:paimon处理完将数据写到kafka队列的时间戳 - 前端埋点被触发被服务器接收到的时间戳;
修改前:
修改后:
4、关联率
意外收获:
经过上述过程改造源码,还可以解决“**跨分区关联率偏低**”的问题!!!
既然是多个流相关联,那么就必然存在一个关联率的问题(一定会有部分数据因为埋点上报缺失/延迟导致关联不上)。于是就会存在如下问题:如果数据***按“天”进行分区***,那么在跨分区时刻也就必然会存在更多的数据关联不上(因为两个流的时间不是完全同步的,一条流可能落到前一天分区,另一条流可能落在第二天分区;数据不在同一个分区,就不会进入同一个mergeTree,也就关联不上)。
那么修改了源码之后是如何解决上述问题的呢?
如前文所述,我们修改源码的目的是“使参与compact的数据不会持续增加”,于是修改代码使部分数据过期,最终**level5(LSM tree的最深一层)**的数据总量不持续增加。那么,既然数据不会持续增加,我们就可以将所有的数据全部放在一个分区中(或者理解为不设分区,一直在一个hdfs路径下;此时只有一开始跑的时候前一少部分数据关联率偏低,后边会维持在一个稳定水平),也就没有过跨分区一说了。
(五)未来展望:异步Compact
官方提供的paimon源码,里边的compaction是 sync 模式的,我尝试改成过 async 的,但是时不时会出现很少量的数据丢失(感觉可能是因为同一时刻有多个compact任务在进行),后续有机会可以再继续尝试一下。
版权归原作者 Leonardo_KY 所有, 如有侵权,请联系我们删除。