
文章目录
ETL
ETL(Extract-Transform-Load,即数据抽取、转换、转载),对于企业或行业应用来说,我们经常会遇到各种数据的处理,转换,迁移,所以了解并掌握一种ETL工具的使用,必不可少。
市面上常用的ETL工具有很多,比如Sqoop,DataX,Kettle,Talend等,作为一个大数据工程师,我们最好要掌握其中的两到三种。
一、Kettle
Kettle是一款国外开源的ETL工具,用纯Java语言编写,可以在Windows、Linux、UNIX上运行,数据抽取高效稳定。它支持图形化的GUI设计界面,而且可以以工作流的形式流转,在数据抽取、质量检测、数据清洗、数据转换、数据过滤等方面有着比较稳定的表现。此外,Kettle中有两种脚本文件——转换和作业,转换完成针对数据的基础转换,作业则完成整个工作流的控制。
Kettle中有两种脚本文件,transformation和job,transformation完成针对数据的基础转换,job则完成整个工作流的控制。
Kettle的特点:开源免费,可维护性好,便于调试,开发简单。
核心组件
Spoon.bat/spoon.sh:是一个图形化界面,可以让我们的图形化的方式转换和作业(Windows选择Spoon.bat;Linux选择Spoon.sh)
Pan.bat/pan.sh:利用Pan可以用命令行的形式执行由Spoon编辑的转换和作业
Kitchen.bat/kitchen.sh:利用Kitchen可以使用命令行调用由Spoon编辑好的job
Carte.bat/Carte.sh:Carte是一个轻量级的Web容器,用于建立专用、远程的ETL Server
二、安装和运行Kettle
Kettle是基于Java开发的,因此需要Java环境,也就是要先安装JDK工具包。
下载Kettle,解压到任意目录。
启动Kettle。安装完成之后,双击spoon.bat批处理程序即可启动Kettle。
kettle启动界面。
根据数据库,将数据库的驱动jar包放到xxxx\pdi-ce-7.1.0.0-12\data-integration\lib目录下,重启spoon即可。
三、Kettle使用
配置资源库与数据库
重新双击spoon.bat,运行Kettle工具。
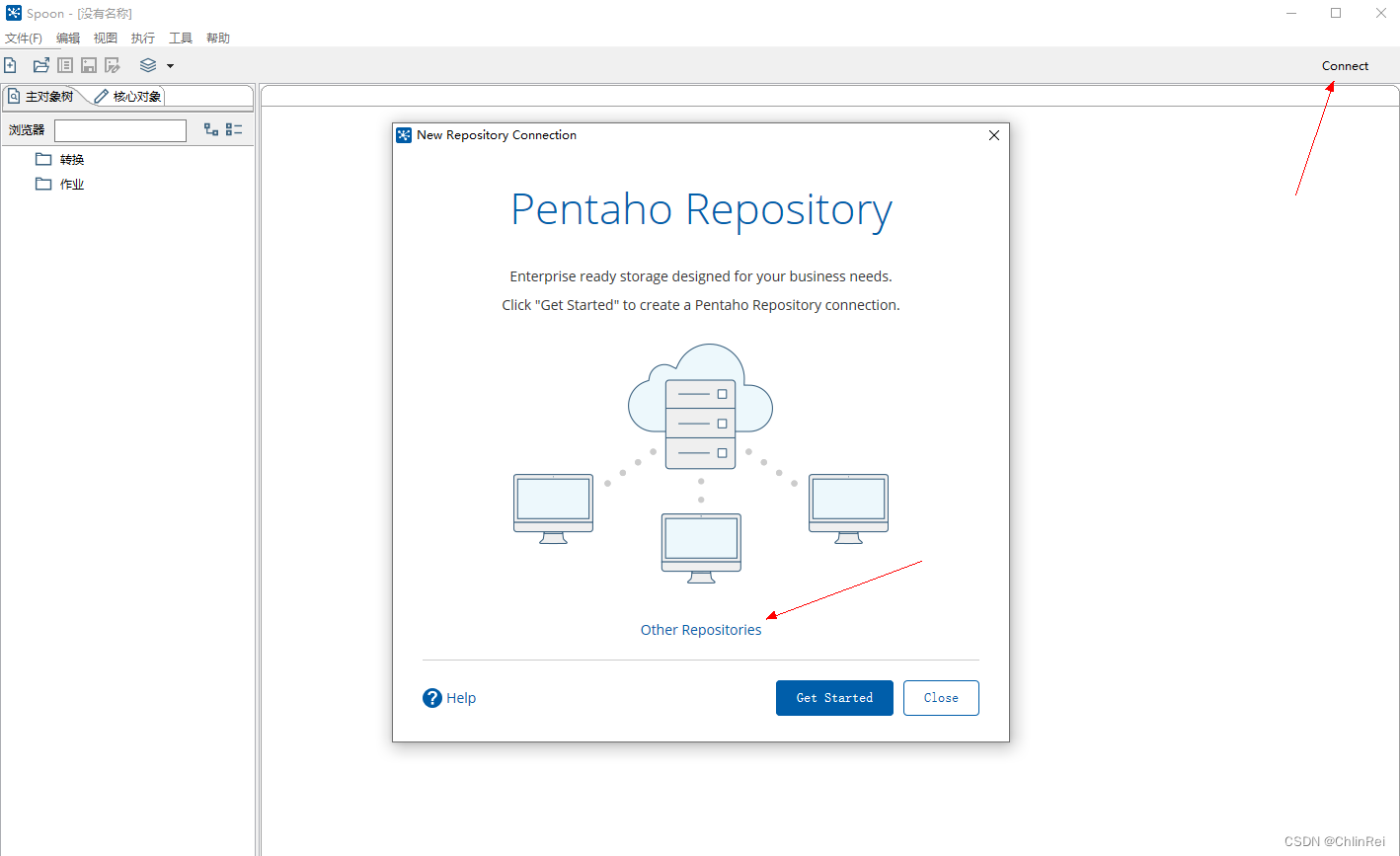
点击右上角
connect
标志,点击
Other Repositories
。如下图:
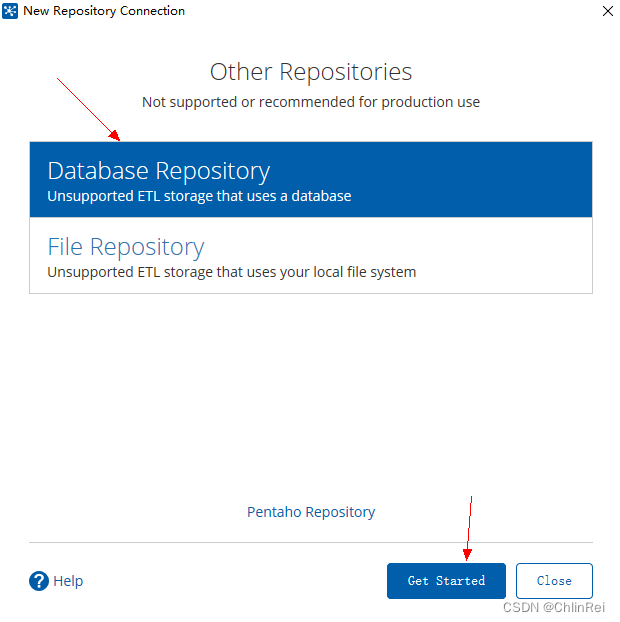
在弹窗中选择
Database Repository
选项,点击
Get Started
。
输入资源库名称(自定义),点击
Database Connection
创建数据库连接。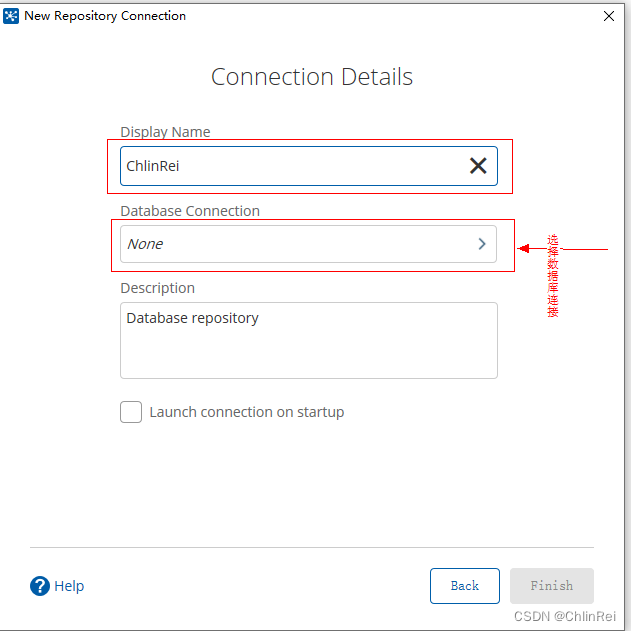
点击创建新的数据库连接,根据需求选择连接方式,默认选一般;数据库连接名称(自定义);连接类型,什么数据库就选择什么;连接方式,默认选第一个;最后再将数据库连接信息,信息填好后,点击
测试
,连接成功后点击确定即可。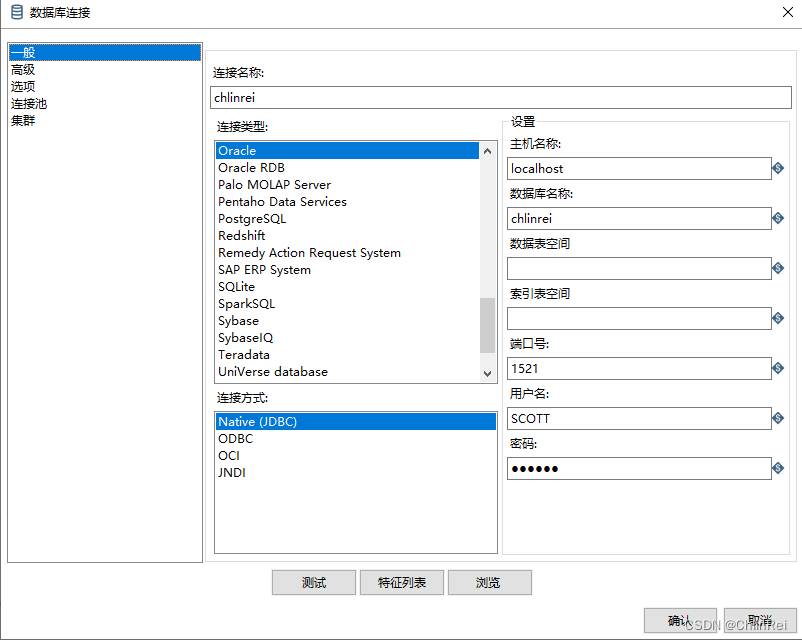
数据库连接成功,在database Connection中即可选择刚才建立的数据源。点击Finish,选择
Conncect Now
,进入登录页面,默认是admin用户,密码也是admin。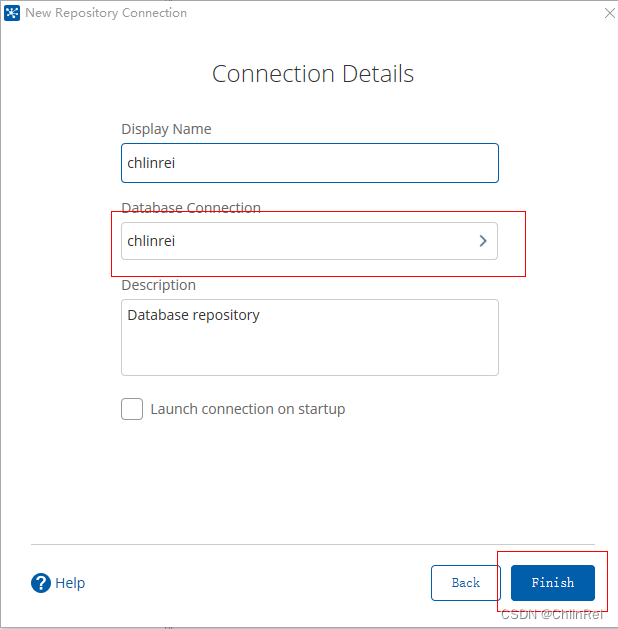
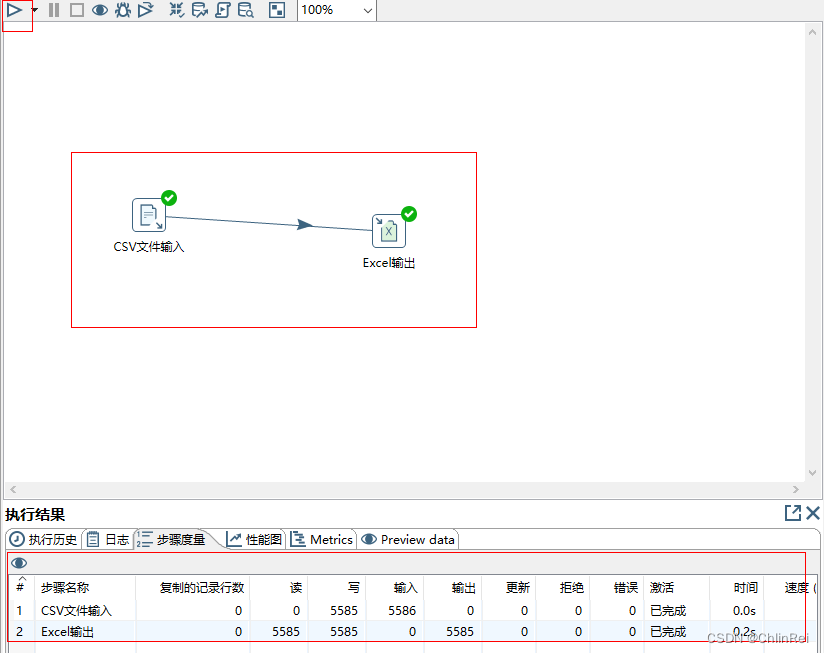
将CSV文件转换为Excel,选择CSV文件输入、Excel输出拖入操作面板,连接后点击左上角
三角
运行。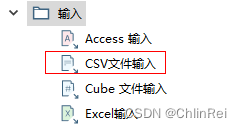
四、Kettle核心概念
可视化
Kettle可以被归类为可视化编程语言,因为kettle可以使图形化的方式定义复杂的ETL程序和工作流。
可视化编程一直是kettle里的核心概念,它可以让你快速构建复杂的ETL作业和减低维护工作kettle里的代码就是转换和作业。
转换
转换负责数据的输入、转换、校验和输出等工作。kettle中使用转换完成数据ETL全部工作。转换由多个步骤组成,如文本文件输入,过滤输出行,执行SQL脚本等。各个步骤使用跳(Hop)(连接箭头)来链接。跳定义了一个数据流通道,即数据由一个步骤流跳向下一个步骤。在kettle中数据的最小单位是数据行(row),数据流中流动其实是缓存的行集(RowSet)
步骤
步骤(控件)是转换里的基本的组成部分,‘CSV文件输入’和‘Excel输出’。
一个步骤有几个关键特性:
步骤需要有一个名字,这个名字在同一个转换范围内唯一
每个步骤都会读、写数据行(唯一例外是“生成记录”步骤,该步骤只写数据)
步骤将数据写到与之相连的一个或多个输出跳(hop)再传送到跳的另一端的步骤。
大多数的步骤都可以有多个输出跳。一个步骤的数据发送可以被设置为分发和复制,分发是目标步骤轮流接收记录,复制是所有的记录被同时发送到所有的目标步骤。
跳
跳就是步骤之间带箭头的连线,跳定义了步骤之间的数据通路
跳实际上时两个步骤之间的被称为行集的数据行缓存,行集的大小可以在转换的设置里定义。当行集满了,向行集写数据的步骤将停止写入,直到行集里又有了空间。当行集空了,丛行集读取数据的步骤停止读取,直到行集又有可读的数据行。
版权归原作者 ChlinRei 所有, 如有侵权,请联系我们删除。