
一、benchmark的使用
1.一个简单的例子
go mod init test 创建项目test,创建目录bench/fib
创建fib.go
package fib
func fib(n int) int {
if n == 0 || n == 1 {
return n
}
return fib(n-1) + fib(n-2)
}
创建fib_test.go
package fib
import (
"testing"
)
func BenchmarkFib(b *testing.B) {
for i := 0; i < b.N; i++ {
fib(30)
}
}
go 不管是单元测试还是基准测试,测试函数都应该写在以_test.go 为结尾的文件中。
go 单元测试函数以Test开头,函数参数为*testing.T
go 基准测试函数以Bench开头,函数参数为*testing.B
2.运行用例
如何运行测试用例呢?
运行单元测试:go test -run=xxx,其中xxx为正则表达式,用来匹配单元测试函数的函数名。
运行基准测试:go test -bench=xxx,其中xxx为正则表达式,用来匹配基准测试函数的函数名。
上述命令只能运行当前目录中的测试用例,如果想运行其他目录的测试用例呢?
go test -bench=. test/bench/fib ,指定目标包在项目中的绝对路径。
go test -bench=. ./fib , 运行当前目录下的子目录fib中的测试。
go test -bench=. ./... , 运行当前目录下的所有的package中的测试。

对-bench=加上正则表达式:
go test -bench=^BenchmarkFib ./fib

3.benchmark 是如何工作的
benchmark用例的参数为b testing.B, b.N 表示要测试的内容运行的次数,这个次数对于每个用例都不同。那么这个次数变化规律是什么呢?b.N从1开始,如果内容在1s内运行结束,那么b.N会增加,测试会再次执行。b.N 的值大概以 1, 2, 3, 5, 10, 20, 30, 50, 100 这样的序列递增,越到后面,增加得越快。
修改测试的内容,让运行时间>1s
func BenchmarkFib(b *testing.B) {
for i := 0; i < b.N; i++ {
time.Sleep(time.Second)
fib(30)
}
}

可以看到,只执行了1次。
benchmarkFib-12 的-12的意思是 GOMAXPROCS数,即cpu核数,可以使用-cpu来指定cpu核数,-cpu=2,3 表示分别使用GOMAXPROCS=2 和GOMAXPROCS=3 进行测试。

可以看到测试用例运行了两轮,分别以单核和12核,但我们的测试结果没有发生变化,因为我们的测试内容本身是单核的,与多核无缘。
4.提升准确度
对于性能测试来说,提升测试精度的一个重要手段是提升测试时间和测试次数。我们可以是用-benchtime 和 -count 来达到目的。
benchmark 默认的benchtime是1s,我们指定2s,可以看到执行次数也提升了约1倍。

我们还能直接指定b.N ,即 -benchtime=30x 表示30次

那么count就是测试的轮数了,-count=2 测试两轮。

5.内存分配情况
前面的测试结果中,只能看见执行的次数和一次执行的时间,没有任何与内存相关的信息。加入 -benchmem 就可以看到。

因为fib函数使用的空间全在栈上,不需要进行内存分配。
下面测试切片的内存分配。创建目录 bench/cap
cap.go
// 一次性分配空间
func generateWithCap(n int) []int {
rand.Seed(time.Now().UnixNano())
nums := make([]int, 0, n)
for i := 0; i < n; i++ {
nums = append(nums, rand.Int())
}
return nums
}
// 多次分配空间
func generate(n int) []int {
rand.Seed(time.Now().UnixNano())
nums := make([]int, 0)
for i := 0; i < n; i++ {
nums = append(nums, rand.Int())
}
return nums
}
cap_test.go
package cap
import "testing"
func BenchmarkGenerateWithCap(b *testing.B) {
for n := 0; n < b.N; n++ {
generateWithCap(1000000)
}
}
func BenchmarkGenerate(b *testing.B) {
for n := 0; n < b.N; n++ {
generate(1000000)
}
}
测试结果:

可以看到:
一次性分配内存的切片赋值函数比多次分配内存的切片赋值函数消耗内存更少。
一次性分配内存的切片赋值函数运行时间更少,因为内存分配需要耗时间。
6.测试不同的输入
不同函数的复杂度不同,O(1)、O(n)、O(lgn)等,利用 benchmark 验证复杂度一个简单的方式,是构造不同的输入,对刚才的generate函数构建不同的输入可以达到这个目的。
cap_test.go
func benchmarkGenerate(n int, b *testing.B) {
for i := 0; i < b.N; i++ {
generate(n)
}
}
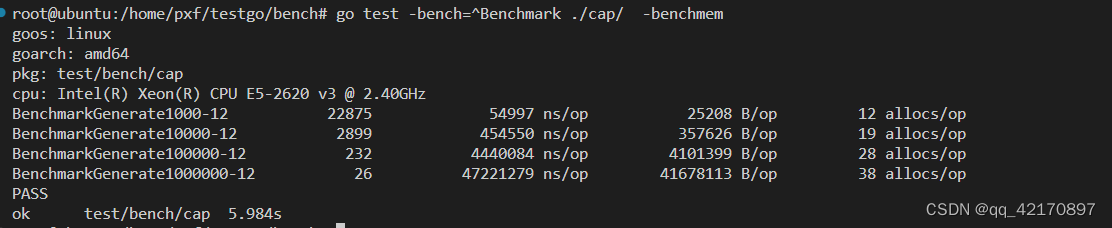
func BenchmarkGenerate1000(b *testing.B) { benchmarkGenerate(1000, b) }
func BenchmarkGenerate10000(b *testing.B) { benchmarkGenerate(10000, b) }
func BenchmarkGenerate100000(b *testing.B) { benchmarkGenerate(100000, b) }
func BenchmarkGenerate1000000(b *testing.B) { benchmarkGenerate(1000000, b) }
随着输入按10倍的速度增长,运行时间也按10倍在增长,则函数的复杂度是线性的,即O(n).
二、benchmark的注意事项
1.ResetTimer
如果在正式执行测试前需要进行准备工作,那么在准备工作完成后,可以使用b.ResetTimer() 函数来重置计数器。
使用sleep模拟耗时的准备工作。
fib_test.go
func BenchmarkFib(b *testing.B) {
time.Sleep(time.Second)
for i := 0; i < b.N; i++ {
fib(30)
}
}

每次执行fib(30)高达1s多,显然不对。
使用b.ResetTimer()
fib_test.go
func BenchmarkFib(b *testing.B) {
time.Sleep(time.Second)
b.ResetTimer()
for i := 0; i < b.N; i++ {
fib(30)
}
}

我们将耗时的准备工作排除在测试之外,每次调用fib(30)花费 6ms = 0.006s
2.StopTimer & StartTimer
如果在每一次函数前后都需要准备工作和清理工作,那么就需要StopTimer + StartTimer 函数了。
例:
sort_test.go
// 一次性分配空间
func generateWithCap(n int) []int {
rand.Seed(time.Now().UnixNano())
nums := make([]int, 0, n)
for i := 0; i < n; i++ {
nums = append(nums, rand.Int())
}
return nums
}
//冒泡排序
func bubbleSort(nums []int) {
for i := 0; i < len(nums); i++ {
for j := 1; j < len(nums)-i; j++ {
if nums[j] < nums[j-1] {
nums[j], nums[j-1] = nums[j-1], nums[j]
}
}
}
}
func BenchmarkBubbleSort(b *testing.B) {
for n := 0; n < b.N; n++ {
//暂停计时
b.StopTimer()
nums := generateWithCap(10000)
//继续计时
b.StartTimer()
bubbleSort(nums)
}
}

显然我们只测试到排序的性能,没有将内存分配的时间花费算入结果。
每次排序需花费120ms的时间。
版权归原作者 pakano 所有, 如有侵权,请联系我们删除。