
目标
基于大语言模型的 Chat 应用,是一种利用自然语言处理技术来进行对话交互的智能应用。
大语言模型通过大量数据的学习和训练,能够理解自然语言表达的语义,具备智能对话的能力。当用户向 Chat 应用提出问题时,Chat 应用就会利用其学习到的知识和自然语言处理技术来理解用户的意图,然后推理生成相应的答案。
我们的目标是使用 React.js 开发一个通用的 Chat 应 用程序,提供对话 Web 界面,调用 ChatGLM3 项目的 OpenAI 兼容接口,编译并部署到 Nginx。
功能概要
(1)Chat 交互界面
该应用使用 Chat 对话模式的界面,接收用户的输入内容,并将其显示到聊天记录中。大语言模型返回的结果会回写到聊天记录中。用户与大模型交流的文本用左右位置或图标进行区分。
(2)流式接口
这是指 OpenAI 兼容的流式调用方式,最早由 ChatGPT 使用,目前已成为大语言模型 Chat 应用事实上的接口标准。流式访问是一种服务端逐步推送数据、客户端逐步接收结果并显示的方法,适用于处理大量数据或长时间运行的任务。
(3)多轮会话
多轮对话是指模型把当前的问题及上文的问答情况整合到一起,形成关于问题的上下文描述。由于在多轮会话中输入的 token 较长,问题的上下文描述得比较清楚,相关语境也构建得相对完整,所以相比于单轮对话,多轮会话生成的答案更为合理。
其缺点在于随着对话轮数的增加,输入的 token 越来越长,会影响大语言模型的运算效率。所以在具体实现 Chat 应用时,要对历史对话记录进行一定的限制,以防止输入 token 过长导致模型的生成性能下降。
(4)打字效果
ChatGPT 采用了模拟打字的视觉效果实现行文本的逐步生成,既保证用户能在第一时间获取生成的部分文本信息,不会觉得等待时间很长,也减少了大模型一次性生成长文本导致算力过载的情况。因此,这次所开发的应用也采用了此技术来显示文本的生成过程。
打字效果的实现基于 SSE 服务端推送技术。SSE 是一种 HTML5 技术,允许服务器向客户端推送数据,而不需要客户端主动请求。它能在服务端有新消息时,将消息实时推送到前 端,从而实现动态打字的聊天效果。
系统架构
Chat 应用是一个 B/S 结构的应用。服务端由大语言模型的 OpenAI API 服务提供,客户端使用 React.js 编写,部署于 Nginx。客户端通过浏览器访问页面,在浏览器中执行 JavaScript 代码,以将用户的输入发送至服务端,渲染页面显示服务端返回的结果。其架构图见图 1。
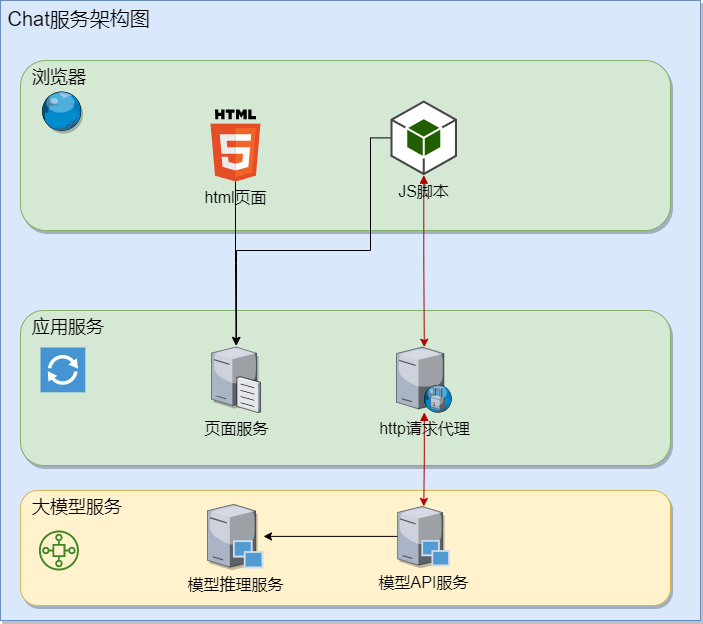
图 1 Chat 应用架构图
(1)大模型服务层
模型推理服务由大语言模型的代码完成,如在 ChatGLM3-6B 模型的 modeling_chatglm.py 文件中,stream_chat 函数实现了流式推理。模型 API 服务则由 ChatGLM3 项目源码中的openai_api_demo/api_server.py 提供。
(2)应用服务层
在开发环境下由 npm 模拟一个本地应用服务,承担页面下载和请求代理的职责。而在正式运行环境中,这两个职责是由 Nginx 的页面部署服务和代理转发功能来完成的。Nginx 在配置上还要支持 SSE 推流模式。
(3)客户端浏览器层
通过运行在浏览器中的 HTML5 和 JavaScript 代码来与应用服务层交互。JavaScript 发出的 HTTP/HTTPS 请求经应用服务层转发到模型 API 服务。
运行原理
- 浏览器负责展现页面,调用 OpenAI 兼容接口来获取生成内容。
- Nginx 提供页面内容以及代理调用 OpenAI 兼容接口。
- 页面请求和接口调用在一个域名或
IP:端口内,这样可以避免跨域问题。跨域问题是指在 Web 开发中,当一个网站的客户端(前端)需要调用服务端(后端)的 API 时,请求的 URL 与页面的 URL 来自不同的域名,导致安全风险,而被浏览器拦截。 - openai_api.py 用于装载模型,提供 API 服务。
开发
(1)Node.js 安装
React.js 程序的开发调试要在 Node.js 环境下进行。从 https://nodejs.org/ 中下载并安装 Node.js,然后在命令行运行
node -v
命令来测试它是否安装成功。
(2)chat-app 新建
1)新建应用新建一个名为 chat-app 的 React.js 应用,命令如下。
npm install -g create-react-app
create-react-app chat-app
cd chat-app
2)安装组件chat-app 用到两个第三方组件,一个是作为 Chat 界面的 ChatUI 框架,另一个是调用模型 API 服务的 Node.js 组件—openai-node。
npm i --save @chatui/core
npm i --save openai
源代码
实现 Chat 页面和业务逻辑的代码在 src/app.js 中。它只有 61 行代码,下面完整展示出来。
import './App.css';
import React from 'react';
import '@chatui/core/es/styles/index.less';
import Chat, { Bubble, useMessages } from '@chatui/core';
import '@chatui/core/dist/index.css';
import OpenAI from 'openai';
const openai = new OpenAI({
apiKey: 'EMPTY', dangerouslyAllowBrowser: true,
baseURL: "http://server-llm-dev:8000/v1"
});
var message_history = [];
function App() {
const { messages, appendMsg, setTyping, updateMsg } = useMessages([]);
async function chat_stream(prompt, _msgId) {
message_history.push({ role: 'user', content: prompt });
const stream = openai.beta.chat.completions.stream({
model: 'ChatGLM3-6B',
messages: message_history,
stream: true,
});
var snapshot = "";
for await (const chunk of stream) {
snapshot = snapshot + chunk.choices[0]?.delta?.content || '';
updateMsg(_msgId, {
type: "text",
content: { text: snapshot.trim() }
});
}
message_history.push({ "role": "assistant", "content": snapshot });
}
function handleSend(type, val) {
if (type === 'text' && val.trim()) {
appendMsg({
type: 'text',
content: { text: val },
position: 'right',
});
const msgID = new Date().getTime();
setTyping(true);
appendMsg({
_id: msgID,
type: 'text',
content: { text: '' },
});
chat_stream(val, msgID);
}
}
function renderMessageContent(msg) {
const { content } = msg;
return <Bubble content={content.text} />;
}
return (
<Chat
navbar={{ title: 'chat-app' }}
messages={messages}
renderMessageContent={renderMessageContent}
onSend={handleSend}
/>
);
}
export default App;
测试
(1)启动大模型 API 服务
安装 ChatGLM3-6B 模型。API 服务则由 ChatGLM3 代码库的 openai_api_demo/api_server.py 提供。在这个文件中,/v1/embeddings 接口依赖一个较小文本向量模型 BAAI/bge-large-zh-v1.5。虽然本次开发应用程序中不会用到它,但为了保证程序能正常运行,建议先下载这个模型。
cd ChatGLM3
conda activate ChatGLM3
wget https://aliendao.cn/model_download.py
python model_download.py --e --repo_id BAAI/bge-large-zh-v1.5 \
--token YPY8KHDQ2NAHQ2SG
设定模型及文本向量模型文件所在位置,启动 API 服务,监听 8000 端口。
MODEL_PATH=./dataroot/models/THUDM/chatglm3-6b \
EMBEDDING_PATH=./dataroot/models/BAAI/bge-large-zh-v1.5 \
python openai_api_demo/api_server.py
(2)测试 chat-app
客户端程序目录下运行
npm start
命令,以启动客户端的开发环境服务。在浏览器中打开
http://localhost:3000
,运行结果如图 2 所示。
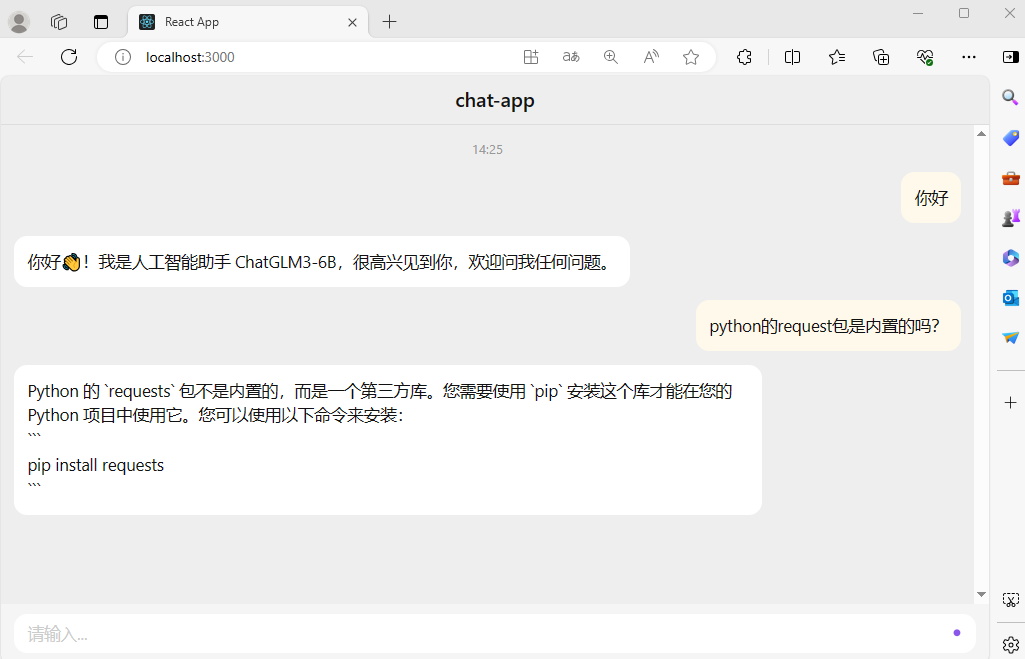
图 2 chat-app 运行
运行发现,在 chat-app 应用中,用户可以进行流式人机对话。该应用同时支持多轮对话,也实现了打字的视觉效果。
也就是说,该应用达到了原先设定的目标。
(3)界面美化
chat-app 是一个通用的 Chat 应用客户端,通过改变程序中的
apiKey
和
baseURL
参数,可以连接任意一个兼容 OpenAI 接口的大语言模型推理服务,当然包括在正确设置
apiKey
的情况下连接 OpenAI 的服务。
此时,chat-app 的界面还需要进一步美化。比如,将输入框从一行变为多行以便于输入。
- 需要在 app.js 文件的同级目录下建一个 chatui-theme.css 文件,内容如下。
.ChatFooter .Composer-input {
background: white;
max-height: 160px;
border: 1px solid darkgray;
min-height: 80px;
height: auto;
}
- 在 app.js 文件中的第 6 行代码
import OpenAI from ’openai’;后增加一行 命令,如下所示。
import './chatui-theme.css';
- 重新用
npm start命令运行程序,就可以看到输入框变成多行了。
应用发布
在程序开发调试过程中,应用依赖于 Node.js,并以“ npm start”的方式运行。
对此,可以通过编译过程,将 React.js 程序编译成脱离 Node.js 的 HTML5 和 JavaScript 文件,部署到 Nginx 等应用服务器中运行。
(1)编译
运行以下命令编译源代码,将编译结果存放在 build 目录下。
npm run build
(2)发布
将 build 目录下的所有文件复制到 Nginx 的 html 目录下即可完成部署。
如果是 Windows操作系统,则 html 在 Nginx 的目录下;如果是 Linux 操作系统,其目录则可能是/usr/local/share/nginx/html 或 /usr/local/nginx/html。
(3)运行
首次运行 Nginx 时,在 Windows 上直接运行 nginx.exe,在 Linux 上则要运行
sudo nginx
命令。
如果 Nginx 已运行,那么配置文件会发生改变,需要重启。可以执行以下命令。
sudo nginx -s reload
对于该命令,在 Windows 或 Linux 上的形式几乎是一样的,区别在于因为涉及权限问题,对于 Linux 系统,需要在命令前加
sudo
。
(4)应用升级
借助浏览器的缓存机制可以减少页面、JavaScript 代码的下载量。因为它会对相同请求 URL 的 HTML5 页面、JavaScript 代码进行缓存。然而,每次执行
npm build
命令产生的文件名是固定的,这样即使代码有调整,且 Nginx 的 html 目录下的文件已更新,但由于 URL 未发生变化,浏览器仍会从缓存中加载旧版本。
为了解决这个问题,可修改 package.json 中的
version
参数值,提高版本号,以编译出不同的文件名。这样浏览器会由于 URL发生变化而忽略缓存,加载文件的最新版本。
(5)SSE 配置
启动 Nginx 服务后,就可以使用诸如
http://127.0.0.1
这样不带端口的 URL 访问页面,但是可能会存在跨域问题。因为页面对应 Nginx 所在计算机的 80 端口,JavaScript 调用的是 API 服务器的 8000 端口,两者的 IP 和端口是不一样的。
如果 API 服务端不处理跨域问题的话,chat-app 调 API 服务就会报跨域错误。解决的方法是在 Nginx 的 80 端口上配置一个 API 服务的路径代理。因为要支持 SSE,这个代理配置要与一般的路径代理有一定的区别。
举例来说,在 baseURL 为
http://server-llm-dev:8000/v1
的情况下,在 Nginx 的 conf/nginx.conf 中的 server 模块下增加一个
location
,如下所示。
location /v1 {
proxy_http_version 1.1;
proxy_set_header Connection "";
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header Host $host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
# SSE 连接时的超时时间
proxy_read_timeout 86400s;
# 取消缓冲
proxy_buffering off;
# 关闭代理缓存
proxy_cache off;
# 禁用分块传输编码
chunked_transfer_encoding off;
# 反向代理到 SSE 应用的地址和端口
proxy_pass http://server-llm-dev:8000/v1;
}
重启 Nginx,将 app.js 中的 baseURL 由
http://server-llm-dev:8000/v1
更改为
http://127.0.0.1/ v1
。
重新编译部署后,即可发现跨域问题得以解决。
文章来源:IT阅读排行榜
本文摘编自《大模型项目实战:多领域智能应用开发》,高强文 著,机械工业出版社出版,经出版方授权发布,转载请标明文章来源。
▼
延伸阅读

《大模型项目实战:多领域智能应用开发》
高强文 著
从模型理解到高级应用开发真正解决实操问题
10大场景案例覆盖主流开发需求
内容简介:
本书系统地讲解了大语言模型的实战应用过程,涵盖基础知识、常见操作和应用开发3个方面,帮助大语言模型的使用者、应用开发者循序渐进地掌握大模型的原理、操作以及多个场景下的应用开发技能。
上拉下滑查看目录 ↓
前 言
基础篇
第1章 大语言模型的基础知识 3
1.1 大语言模型概述 4
1.1.1 基本情况 4
1.1.2 发展历史 4
1.1.3 发展现状 6
1.1.4 发展趋势 7
1.2 基本原理 7
1.2.1 Transformer架构 8
1.2.2 编码器与解码器 8
1.2.3 自注意力机制 9
1.3 应用开发技术 11
1.3.1 Python 11
1.3.2 React.js 11
1.4 训练方法 12
1.4.1 FFT 12
1.4.2 RLHF 13
1.4.3 P-Tuning 13
1.4.4 LoRA 13
1.5 常见现象 13
1.5.1 幻觉 14
1.5.2 灾难性遗忘 14
1.5.3 涌现 14
1.5.4 价值对齐 15
第2章 大语言模型应用架构 16
2.1 整体架构 16
2.2 基础设施 17
2.2.1 硬件部分 17
2.2.2 操作系统 18
2.3 基础软件 18
2.3.1 CUDA 18
2.3.2 PyTorch 18
2.3.3 Anaconda 19
2.3.4 Nginx 19
2.4 应用软件 20
2.4.1 大语言模型文件 20
2.4.2 Transformers库 20
2.4.3 服务程序 20
2.4.4 API 21
2.4.5 客户端程序 21
第3章 大语言模型应用的工作模式 22
3.1 硬件部署 22
3.2 应用软件部署 23
3.3 运行模式 24
3.3.1 模型API服务的工作模式 24
3.3.2 模型API服务的运行过程 25
3.3.3 前后端交互方法 26
3.3.4 前端实现 27
操作篇
第4章 应用环境搭建 31
4.1 基础设施 31
4.1.1 服务器要求 31
4.1.2 操作系统准备 31
4.1.3 推理卡安装 32
4.2 基础软件安装 32
4.2.1 Linux 32
4.2.2 Windows 40
4.3 其他软件安装 41
4.3.1 Nginx 41
4.3.2 Git 42
第5章 大语言模型安装 43
5.1 ChatGLM安装 43
5.1.1 ChatGLM3模型介绍 43
5.1.2 ChatGLM3-6B安装 44
5.1.3 编程验证 45
5.2 Qwen-VL安装 47
5.2.1 Qwen模型介绍 47
5.2.2 Qwen-VL-Chat-Int4安装 47
5.2.3 编程验证 49
5.3 LLaMA2安装 50
5.3.1 LLaMA2模型介绍 50
5.3.2 Llama-2-7b-chat安装 51
5.3.3 运行验证 51
5.4 Gemma安装 54
5.4.1 Gemma模型介绍 54
5.4.2 Gemma-2B安装 55
5.4.3 编程验证 55
5.5 Whisper安装 57
5.5.1 Whisper-large-v3介绍 57
5.5.2 Whisper-large-v3安装 57
5.5.3 编程验证 58
第6章 大语言模型微调 60
6.1 ChatGLM微调 60
6.1.1 微调方法介绍 61
6.1.2 微调环境准备 61
6.1.3 语料准备 62
6.1.4 模型下载 65
6.1.5 微调过程 65
6.1.6 微调模型测试 67
6.2 LLaMA2微调 68
6.2.1 微调方法介绍 68
6.2.2 微调环境准备 69
6.2.3 语料准备 70
6.2.4 模型下载 71
6.2.5 微调过程 71
6.2.6 PEFT微调模型测试 73
6.2.7 模型合并 74
6.2.8 合并后模型测试 74
6.3 Gemma微调 74
6.3.1 微调方法介绍 74
6.3.2 微调环境准备 75
6.3.3 模型下载 75
6.3.4 微调程序开发 75
6.3.5 语料文件下载 77
6.3.6 微调与测试过程 78
第7章 大语言模型量化 79
7.1 量化介绍 79
7.2 llama.cpp量化过程 80
7.2.1 llama.cpp编译 80
7.2.2 模型GGUF格式转换 81
7.2.3 模型下载 81
7.2.4 量化过程 81
7.2.5 量化模型测试 82
7.2.6 Web方式运行 82
7.3 gemma.cpp量化过程 83
7.3.1 gemma.cpp源码下载 83
7.3.2 gemma.cpp编译 83
7.3.3 量化模型下载 84
7.3.4 推理 84
第8章 多模态模型应用 86
8.1 Stable Diffusion介绍 86
8.2 Stable Diffusion部署 87
8.2.1 代码获取 87
8.2.2 Python虚拟环境准备 87
8.2.3 依赖库安装 87
8.2.4 模型下载 88
8.2.5 服务运行 88
8.3 Stable Diffusion应用 88
8.3.1 文生图应用 89
8.3.2 图生图应用 90
开发篇
第9章 Chat应用 94
9.1 目标 94
9.2 原理 94
9.2.1 功能概要 94
9.2.2 系统架构 95
9.2.3 运行原理 96
9.3 开发过程 96
9.3.1 Node.js安装 96
9.3.2 chat-app新建 96
9.3.3 源代码 97
9.3.4 测试 98
9.3.5 应用发布 99
第10章 辅助编程应用 102
10.1 目标 103
10.2 原理 103
10.2.1 功能概要 103
10.2.2 系统架构 103
10.2.3 运行原理 104
10.3 开发过程 104
10.3.1 开发环境准备 104
10.3.2 测试模型准备 105
10.3.3 API服务实现 106
10.3.4 测试 110
第11章 VS Code插件 112
11.1 目标 112
11.2 原理 112
11.2.1 功能概要 112
11.2.2 系统架构 113
11.2.3 运行原理 114
11.3 开发过程 114
11.3.1 环境准备与项目创建 115
11.3.2 插件开发 115
11.3.3 插件发布 118
第12章 检索增强生成应用 121
12.1 目标 121
12.2 原理 122
12.2.1 功能概要 122
12.2.2 系统架构 123
12.2.3 运行原理 124
12.3 开发过程 125
12.3.1 大语言模型安装 125
12.3.2 依赖库安装 125
12.3.3 向量化模型下载 126
12.3.4 源代码 126
12.3.5 测试 128
第13章 PDF翻译应用 130
13.1 目标 130
13.2 原理 130
13.2.1 功能概要 130
13.2.2 系统架构 131
13.2.3 运行原理 131
13.3 开发过程 135
13.3.1 大语言模型安装 135
13.3.2 依赖环境安装 135
13.3.3 下载英译中模型 135
13.3.4 源代码 136
13.3.5 测试 138
第14章 智能代理应用 140
14.1 目标 140
14.2 原理 141
14.2.1 AI Agent 141
14.2.2 AutoGen 141
14.3 开发过程 143
14.3.1 大语言模型安装 143
14.3.2 Docker安装 144
14.3.3 虚拟环境准备 145
14.3.4 运行环境验证 145
14.3.5 多代理会话应用开发 146
第15章 语音模型应用 149
15.1 目标 149
15.2 原理 149
15.2.1 功能概要 149
15.2.2 系统架构 150
15.2.3 运行原理 151
15.3 开发过程 152
15.3.1 运行环境安装 152
15.3.2 模型下载 153
15.3.3 Demo运行 153
15.3.4 服务端开发 154
15.3.5 客户端开发 160
15.3.6 测试 163
第16章 数字人应用 166
16.1 目标 166
16.2 原理 167
16.2.1 功能概要 167
16.2.2 系统架构 167
16.2.3 运行原理 168
16.3 开发过程 169
16.3.1 环境准备 169
16.3.2 源代码 173
16.3.3 测试 177
第17章 提示词生成应用:从零训练模型 179
17.1 目标 179
17.2 原理 180
17.2.1 GPT-2 180
17.2.2 训练流程与应用架构 181
17.2.3 训练方法与运行原理 182
17.3 开发与训练过程 185
17.3.1 语料整理 186
17.3.2 训练 188
17.3.3 推理与服务 196
17.3.4 测试 202
第18章 AI小镇应用 204
18.1 目标 204
18.2 原理 205
18.2.1 功能概要 205
18.2.2 系统架构 206
18.2.3 运行原理 207
18.3 开发过程 209
18.3.1 大语言模型安装 210
18.3.2 开发环境搭建 210
18.3.3 地图制作 210
18.3.4 app.js 211
18.3.5 BootScene.js 213
18.3.6 GameScene.js 213
18.3.7 ChatUtils.js 218
18.3.8 测试 219

- 本文来源:原创,图片来源:原创
- 责任编辑:王莹,部门领导:宁姗
- 发布人:白钰
购买链接:点击购买
版权归原作者 The-Venus 所有, 如有侵权,请联系我们删除。