
一、创建静态分区表(SP static )
1.启动集群
2.进入hive
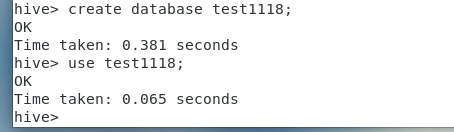
3.创建test1118数据库并使用
4.创建 t1 表
create table t1(
c1 string,
c2 string
);

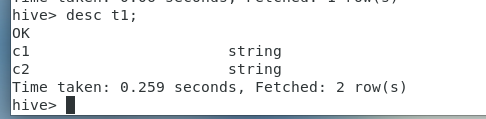
5.查看表结构:
6.创建t2表
create table t2(
c1 string
) partitioned by ( c2 string ) row format delimited fields terminated by ',';
partitioned by ( c2 string ) # 创建分区 c1跟c2都是字段,但是创建的时候不能写在t2里面,只能写在分区里面(同时select查询的时候,c2的字段也要写在最后面)

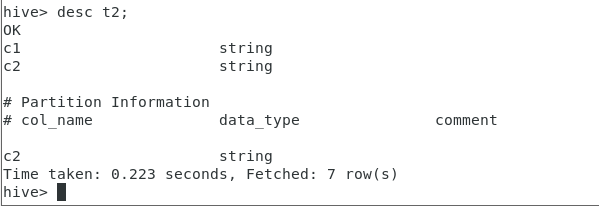
7.查看表结构:
8.上传数据到 t2 表的 c2 分区
要加载数据到分区表,只需在原来的加载数据的语句上增加partition关键字,同时指定分区的字段值即可。
注意:当你退出过hive后,再次进入hive,不要忘记使用了哪个database,我这里使用的是test1118数据库
load data inpath '/lyh/bbb.txt' into table t2 partition (c2='a');

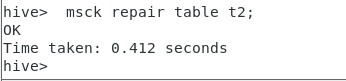
9.需要进行修复,输入以下命令
msck repair table t2;
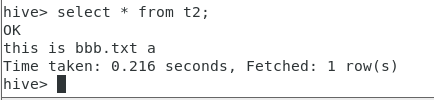
10.查看内容
select * from t2;
11.添加分区b
先确保集群上有a.txt这个文件退出hive
hdfs dfs -mkdir /user/hive/warehouse/test1118.db/t2/b

hdfs dfs -put /a.txt /user/hive/warehouse/test1118.db/t2/b

进入hive 后使用命令
use test1118;
load data inpath '/lyh/a.txt' into table t2 partition(c2='b');

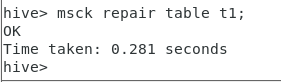
但是这个时候是查看不了的,需要进行修复,输入以下命令
msck repair table t1;
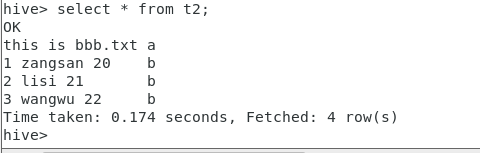
现在修复后可以进行查看
select * from t2;
层次一次建好 分区可以逐个添加
create table t3 (
id int,
name string
)partitioned by (year string,month string)
row format delimited fields terminated by ',';

load data inpath '/lyh/a.txt' into table t3 partition (year='2022',month='11');

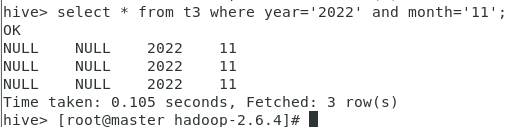
select * from t3 where year='2022';

select * from t3 where year='2022' and month='11';
hdfs dfs -mkdir /user/hive/warehouse/test1118.db/t3/year
hdfs dfs -mkdir /user/hive/warehouse/test1118.db/t3/year/month
hdfs dfs -mkdir -p /user/hive/warehouse/test1118.db/t3/2023
这里的-p和linux意义不同
退出hive
hdfs dfs -mkdir -p /user/hive/warehouse/test1118.db/t3/2023/11
hdfs dfs -put /a.txt /user/hive/warehouse/test1118.db/t3/2023/11
进入hive,然后输入 use dest1118;
msck repair table t3;
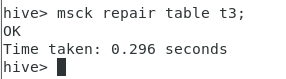
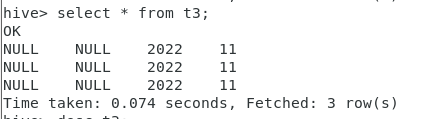
select * from t3;

添加分区
alter table t3 add if not exists partition(year='2023',month='11');


退出hive
hdfs dfs -mv /d.txt /user/hive/warehouse/test1118.db/t3
进入hive,use test1118;
select * from t3;
二、创建动态分区表(DP dynamic)
开启动态分区
set hive.exec.dynamic.partition=true

...=false 关闭
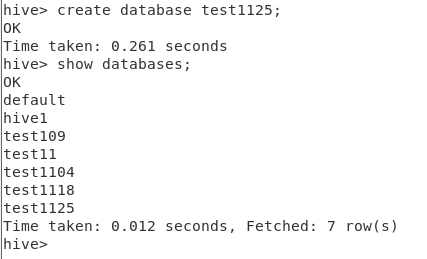
create database test1125;
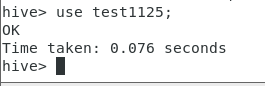
use test1125;
create table t1(
c1 string
) partitioned by(c2 string)
row format delimited fields terminated by ',';
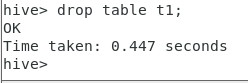
删除表
drop table t1;
create table t2(
id int,
name string
) partitioned by(year string,month string)
row format delimited fields terminated by ',';
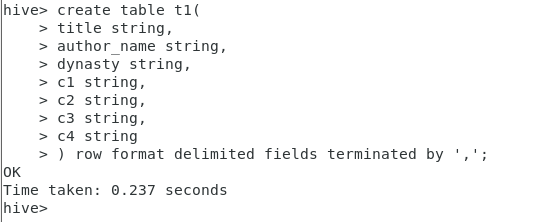
create table t1(
title string,
author_name string,
dynasty string,
c1 string,
c2 string,
c3 string,
c4 string
) row format delimited fields terminated by ',';
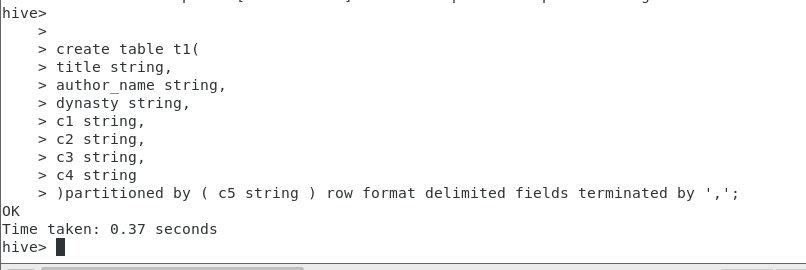
create table t1(
title string,
author_name string,
dynasty string,
c1 string,
c2 string,
c3 string,
c4 string
)partitioned by ( c5 string ) row format delimited fields terminated by ',';
创建一个a.txt文本,内容为
秋夜寄丘二十二员外,韦应物,唐代,怀君属秋夜,散步咏凉天,空山松子落,幽人应未眠

上传到集群
hdfs dfs -put a.txt /lyh

导入文本到 t1 表里
use test1125;
load data inpath '/lyh/a.txt' into table t1 partition(c5='a');

select * from t1;

/***
* ,%%%%%%%%,
* ,%%/\%%%%/\%%
* ,%%%\c "" J/%%%
* %. %%%%/ o o \%%%
* `%%. %%%% _ |%%%
* `%% `%%%%(__Y__)%%'
* // ;%%%%`\-/%%%'
* (( / `%%%%%%%'
* \\ .' |
* \\ / \ | |
* \\/ ) | |
* \ /_ | |__
* (___________))))))) 攻城湿
*/
标签:
hive
本文转载自: https://blog.csdn.net/weixin_64420247/article/details/129789633
版权归原作者 鸷鸟之不群 所有, 如有侵权,请联系我们删除。
版权归原作者 鸷鸟之不群 所有, 如有侵权,请联系我们删除。