
在 4 月 18 日,Meta在官网上公布了旗下最新大模型Llama 3。目前,Llama 3已经开放了80亿(8B)和700亿(70B)两个小参数版本,上下文窗口为8k,据称,通过使用更高质量的训练数据和指令微调,Llama 3接受了超过 15 万亿个标记数据的训练——比 Llama 2 模型使用的训练数据集大七倍,其中包含四倍于 Llama 2 的代码数据,支持 8K 的上下文长度,是 Llama 2 的两倍。

现在,Meta 的 Llama 3 模型已在 Amazon Bedrock 中正式可用,本篇文章将浅要分析Llama 3模型特点,然后在Amazon Bedrock上使用Meta Llama 3 模型进行实践。
一、关于 Llama 3
在人工智能领域,性能的提升往往意味着技术的巨大进步,Llama 3的推出,正是这种进步的一个生动例证。与它的前身Llama 2相比,Llama 3在性能上实现了“重大飞跃”,这不仅仅是一个简单的比较,而是在多个维度上的全面超越。
Meta公司在Llama 3的训练程序上做出了显著改进,这些改进直接反映在了模型的性能上。错误拒绝率的降低意味着模型更加可靠,对齐度的提升则表明模型对输入数据的理解更加深入,而响应多样性的增加则为模型的应用提供了更广阔的空间。这些改进共同作用,使得Llama 3在推理、代码生成和指令跟踪等关键能力上都有了显著提高,极大地增强了模型的可操控性。
在具体的参数数量上,Llama 3 8B和Llama 3 70B在两个定制的24,000个GPU集群上的训练,不仅展示了Meta在硬件资源上的雄厚实力,也体现了其在软件优化上的深厚功底。这样的训练规模,使得Llama 3成为了当今性能最好的生成人工智能模型之一。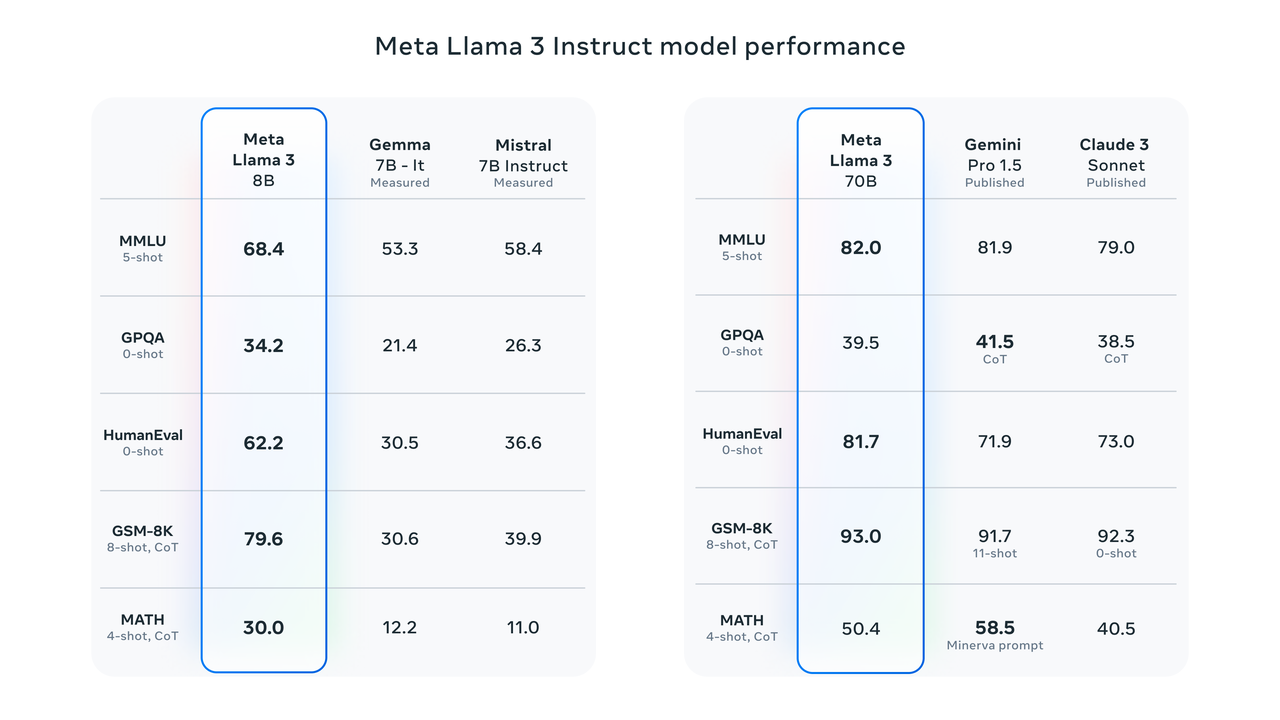
将视角转向人工智能基准测试,Llama 3的表现同样令人瞩目。Llama 3 8B在至少九个基准测试中超越了其他开放模型,如Mistral 7B和Google的Gemma 7B,这一成就充分证明了其卓越的性能;Llama 3 70B虽然未能超越Anthropic性能最高的机型Claude 3 Opus,但在MMLU、HumanEval和GSM-8K等五个基准测试上,它的得分却高于Claude 3系列中第二弱的模型Claude 3 Sonnet。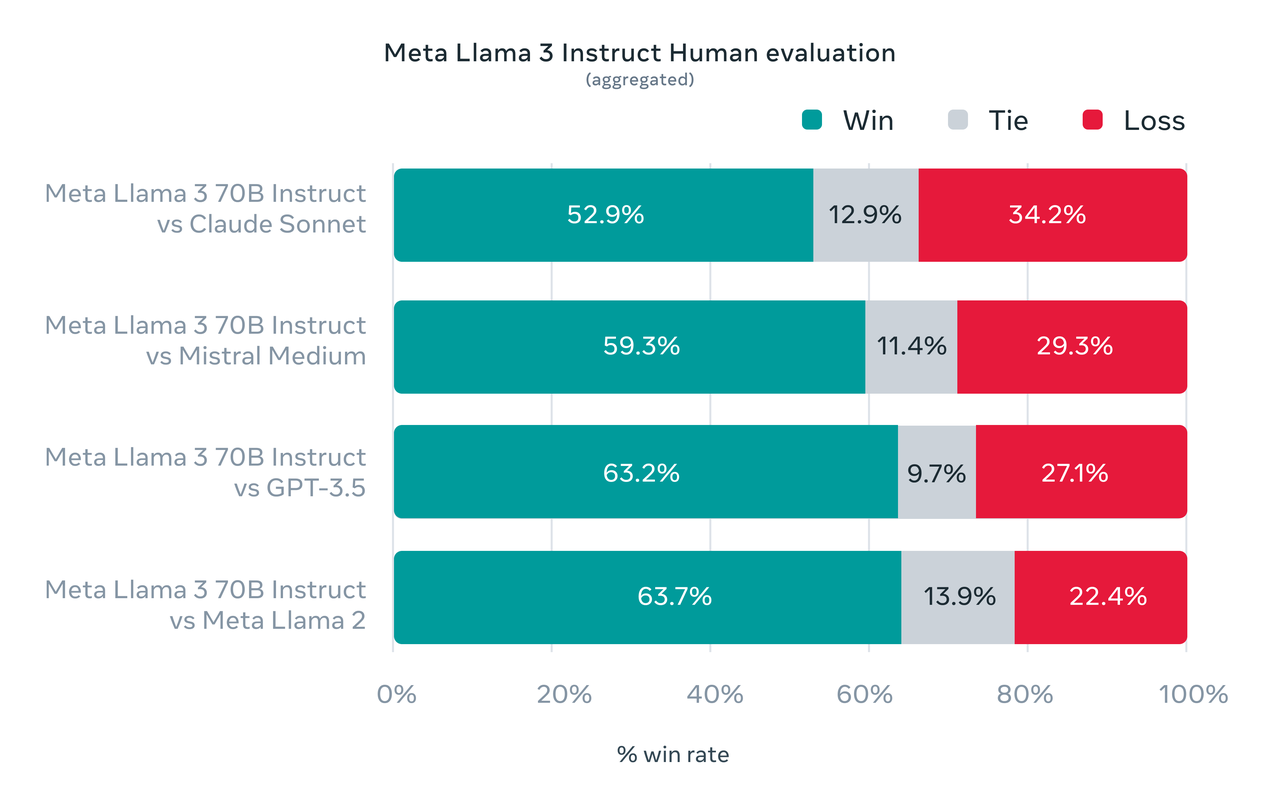
从两个模型的特点来说:
- Llama 3 8B 适合有限的计算能力和资源以及边缘设备。该模型擅长文本摘要、文本分类、情感分析和语言翻译。
- Llama 3 70B 适合内容创作、对话式AI、语言理解、研发和企业应用。该模型擅长文本摘要和准确性、文本分类和细微差别、情感分析和细微推理、语言建模、对话系统、代码生成和遵循指令。
此外,Meta 目前也正在训练参数超过 400B 的其他 Llama 3 模型。这些 400B 模型将具有新的能力,包括多模态、多语言支持和更长的上下文窗口。
二、Amazon Bedrock + Llama3 实践
现在,Meta 的 Llama 3 模型已在 Amazon Bedrock 中正式可用。
Amazon Bedrock 是一项完全托管的服务,通过单个 API 提供来自 AI21 Labs、Anthropic、Cohere、Meta、Stability AI 和 Amazon 等领先人工智能公司的高性能基础模型(FM),以及通过安全性、隐私性和负责任的 AI 构建生成式人工智能应用程序所需的一系列广泛功能。
Amazon Bedrock 提供易于使用的开发者体验,借助 Amazon Bedrock 知识库,可以安全地将基础模型连接到数据来源,以便在托管服务中增强检索,从而扩展基础模型已有功能,使其更了解特定领域和组织,越用越好,才是王道。
要使用Llama 3 8B和Llama 3 70B模型,我们首先需要进入Amazon Bedrock控制台,下滑左侧导航栏,找到模型访问权限,点击然后在右侧找到Llama 3 8B和Llama 3 70B,初次使用会显示可请求状态。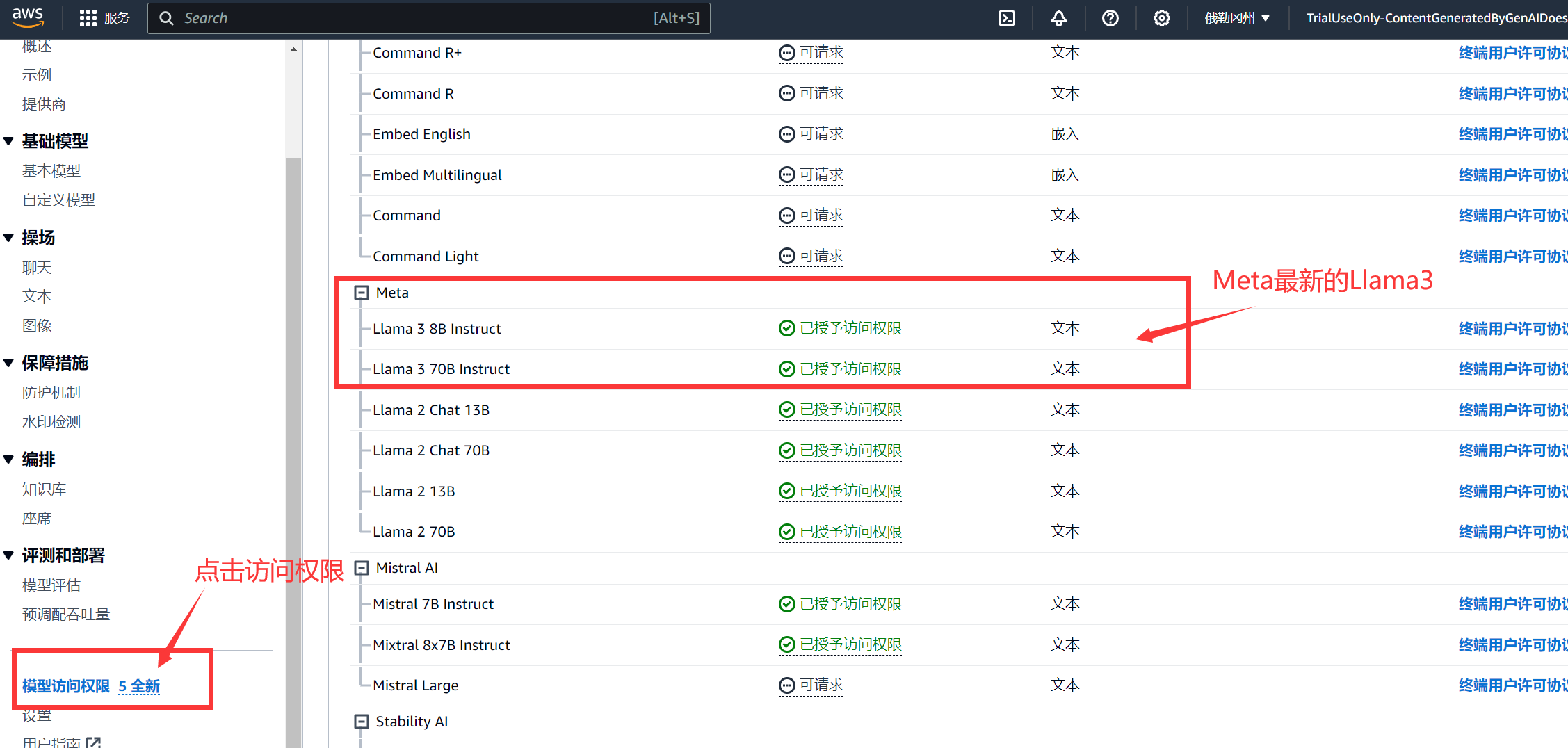
如果显示为“可请求”,则翻到上面,点击管理模型访问权限,然后勾选刚刚的Llama3模型,翻到底部提交更改即可。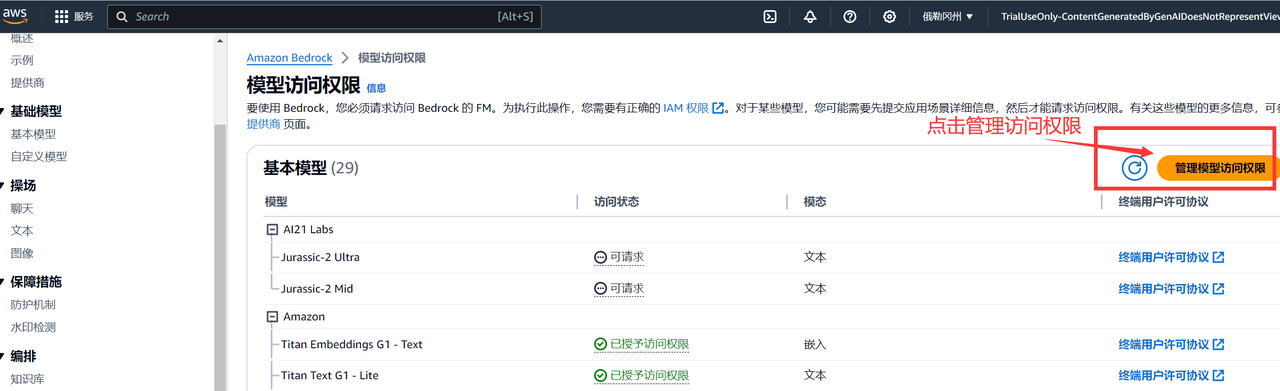
下面在 Amazon Bedrock 控制台中测试 Meta Llama 3 模型。首先在左侧菜单窗格中选择操场下的文本或聊天。然后选择选择模型,并将类别设置为 Meta,将模型设置为 Llama 8B Instruct 或 Llama 3 70B Instruct。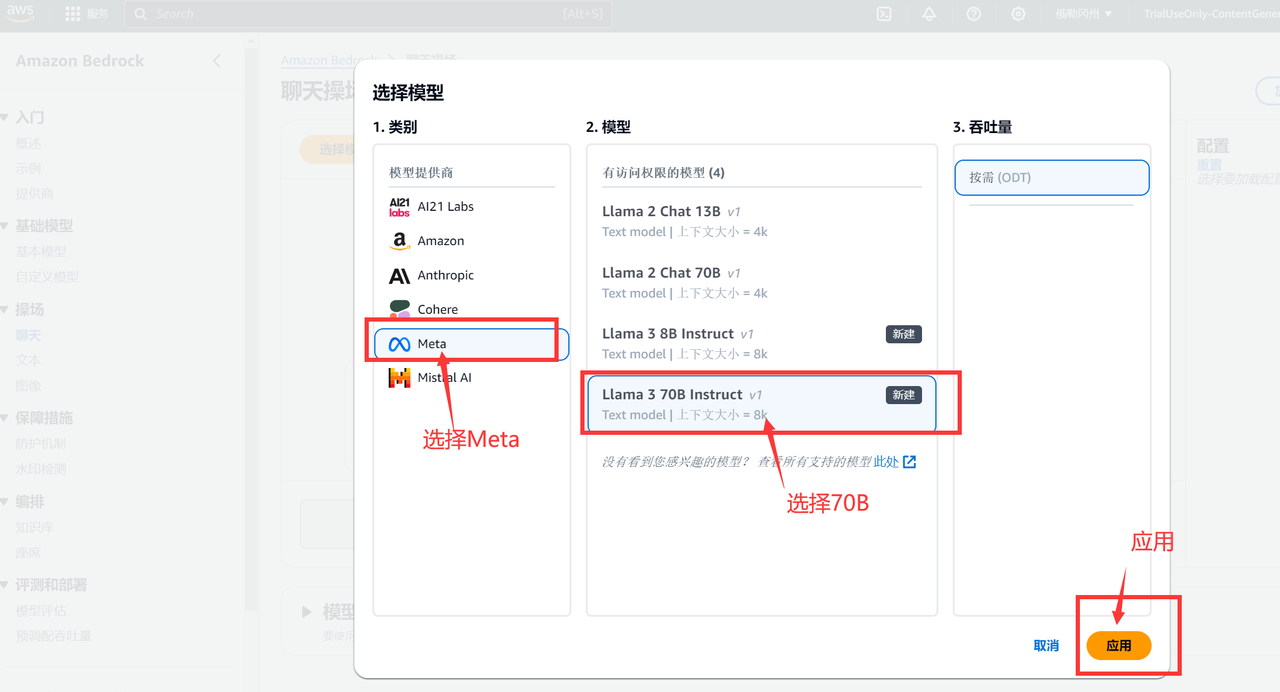
进入后可以看到Llama 3 为我们提供了多项配置: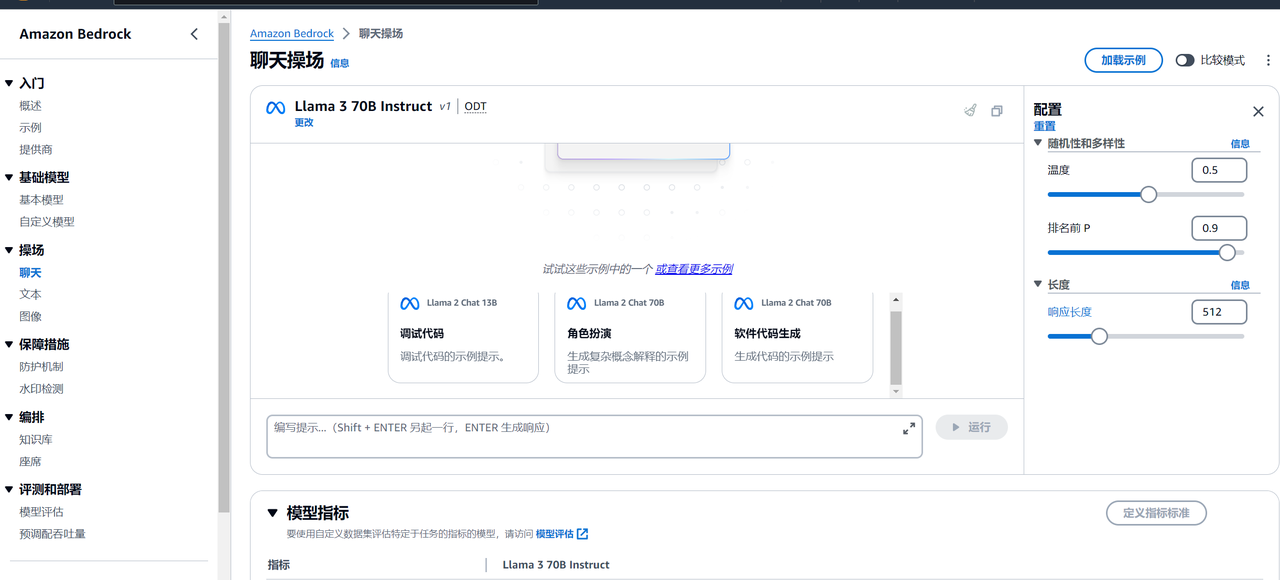
其中温度是一个控制生成文本多样性的参数,较高的温度值,如1.0,会产生更随机的输出,而较低的温度值,如0.1,会使模型更倾向于选择最可能的单词。排名前P也称Top-p,是一种考虑模型输出的全局策略,它决定了更好地探索可能的输出序列,从而产生更多样化的输出。具体来说,Top-p 策略首先按照每个词的预测概率对它们进行排序,然后根据这些词的顺序逐个选择下一个输出,直到累计概率达到 p。Top-p 可以更好地探索可能的输出序列,从而产生更多样化的输出。响应长度是生成文本的最大长度限制,超过这个长度的文本将被截断或停止生成。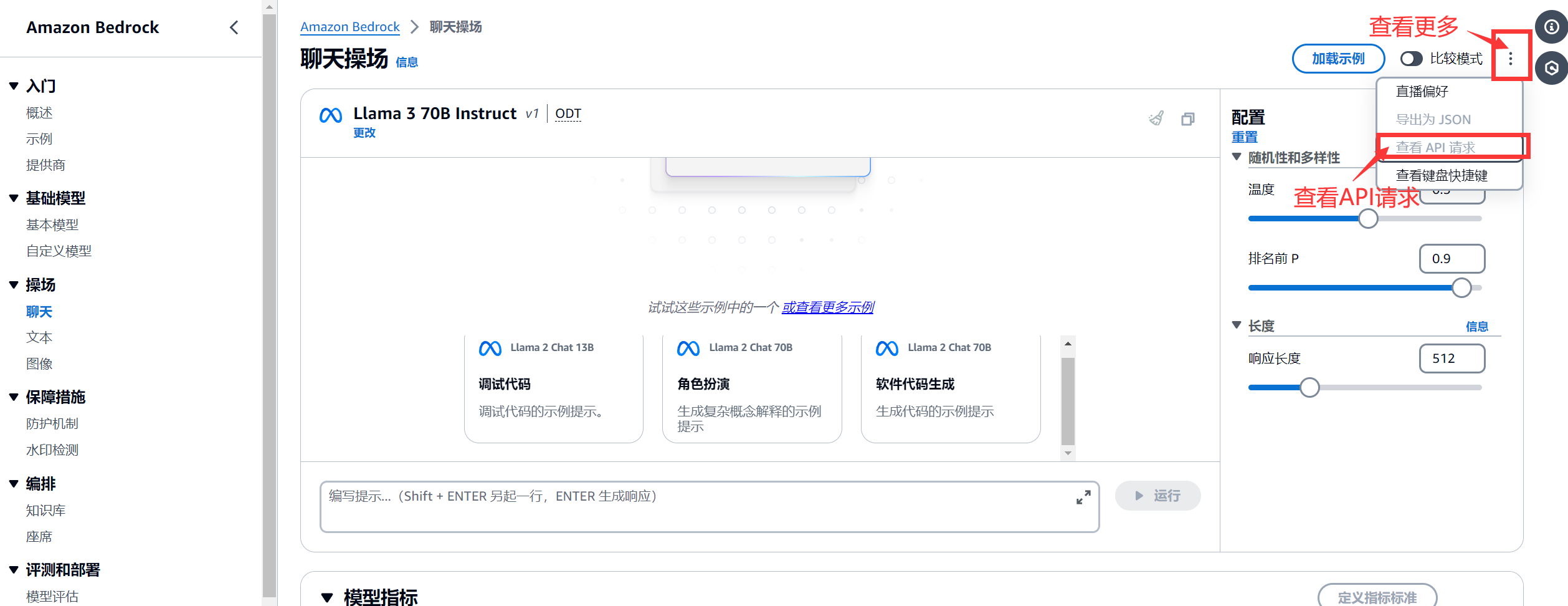
另外,通过选择查看 API 请求,还可以使用亚马逊云科技命令行界面 (Amazon CLI) 和 Amazon SDK 中的代码示例来访问该模型。您可以使用诸如 meta.llama3-8b-instruct-v1 或 meta.llama3-70b-instruct-v1 这样的模型 ID。这是一个 Amazon CLI 命令样本。
$ aws bedrock - runtime invoke - model\--model - id meta.llama3 - 8 b - instruct - v1: 0\--body "{\"prompt\":\"Simply put, the theory of relativity states that\\n the laws of physics are the same everywhere in the universe, and that the passage of time and the length of objects can vary depending on their speed and position in a gravitational field \",\"max_gen_len\":512,\"temperature\":0.5,\"top_p\":0.9}"\--cli - binary - format raw - in-base64 - out\--region us - east - 1\ invoke - model - output.txt
并且,可以使用 Amazon Bedrock + Amazon SDK 用各种编程语言构建您的应用程序。
definvoke_llama3(self, prompt):try: body ={"prompt": prompt,"temperature":0.5,"top_p":0.9,"max_gen_len":512,}
response = self.bedrock_runtime_client.invoke_model(modelId ="meta.llama3-8b-instruct-v1:0", body = json.dumps(body))
response_body = json.loads(response["body"].read()) completion = response_body["generation"]return completion
except ClientError: logger.error("Couldn't invoke Llama 3")raise
以下是部分效果: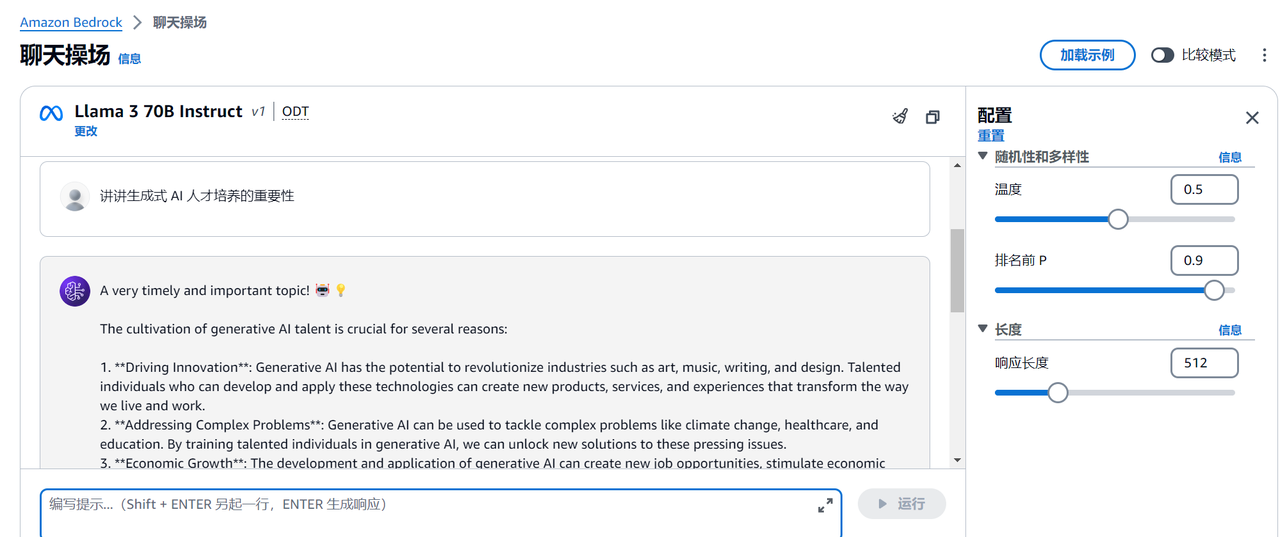
以上只是初步实践,在今年即将召开的2024亚马逊云科技峰会上,将有更为深入的生成式AI应用构建实践,其将聚焦如何借助Amazon Bedrock服务,结合企业业务应用场景,简化模型选择,模型定制和集成应用。使用一站式的Bedrock服务,用户可以通过单个 API 体验20多个业界领先的基础模型(包括Claude3),利用私有数据通过RAG、微调以及提示词工程进行模型定制,快速部署模型到生成式AI应用程序中,推动业务创新,抢占赛道新机遇。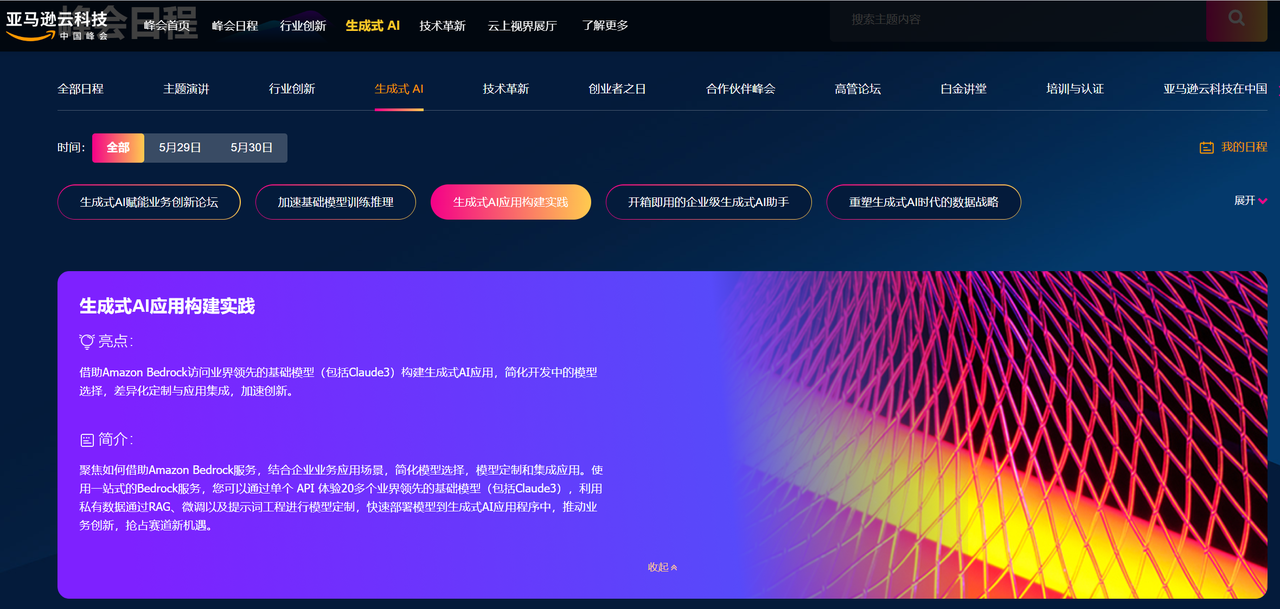
三、2024亚马逊云科技峰会
亚马逊云科技中国峰会将于2024年5月29日至30日在上海世博中心盛大举办,作为一年一度的科技盛会,这次峰会将再次为我们带来云计算领域的最新动态和前沿技术。在这里,每一位参会者将有机会深入了解云计算如何推动行业发展,以及生成式AI等前沿技术的落地实践。

除了基于Amazon Bedrock构建生成式AI应用实践外,大会还将带来自亚马逊云科技全球高管携手云计算行业领军人物围绕生成式AI的重磅发布、分享多个创新场景与客户案例,探讨生成式AI如何重构客户体验、聚焦基础模型训练与推理的基础服务、最新发布的,开箱即用的Amazon Q服务以及多个行业创新范例等等主题。
点击参会链接,一起报名,享受这场科技盛会吧!
最后
💖 个人简介:博客专家,人工智能优质创作者,2022年博客之星人工智能领域TOP2,COC武汉城市开发者社区主理人、2023中国开发者影响力年度优秀主理人
📝 个人主页:中杯可乐多加冰
🎉 支持我:点赞👍+收藏⭐️+留言📝
点击下方公众号,加入采苓AI研习社,回复“白皮书”获取“中国大模型发展白皮书.pdf”,回复“产业报告”获取“AIGC深度产业报告 ”。
版权归原作者 中杯可乐多加冰 所有, 如有侵权,请联系我们删除。