
1.如何保证kafka高可用
系统引入的外部依赖越多,越容易挂掉。本来你就是 A 系统调用 BCD 三个系统的接口就好了,ABCD 四个系统还好好的,没啥问题,但加个 MQ 进来,万一 MQ 挂了,整套系统就崩溃了
Kafka 0.8 以前,是没有 HA 机制的,就是任何一个 broker 宕机了,那个 broker 上的 partition 就废了,没法写也没法读,没有什么高可用性可言。
比如说,我们假设创建了一个 topic,指定其 partition 数量是 3 个,分别在三台机器上。但是,如果第二台机器宕机了,会导致这个 topic 的 1/3 的数据就丢了,因此这个是做不到高可用的。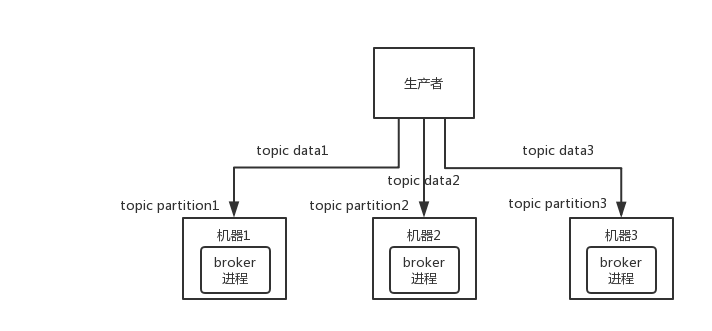
Kafka 0.8 以后,提供了 HA 机制,就是 replica(复制品) 副本机制。每个 partition 的数据都会同步到其它机器上,形成自己的多个 replica 副本。所有 replica 会选举一个 leader 出来,那么生产和消费都跟这个 leader 打交道,然后其他 replica 就是 follower。
写的时候,leader 会负责把数据同步到所有 follower 上去,读的时候就直接读 leader 上的数据即可。为什么只能读写 leader?因为要是你可以随意读写每个 follower,那么就要注意数据一致性的问题,系统复杂度太高,很容易出问题。Kafka 会均匀地将一个 partition 的所有 replica 分布在不同的机器上,这样才可以提高容错性。
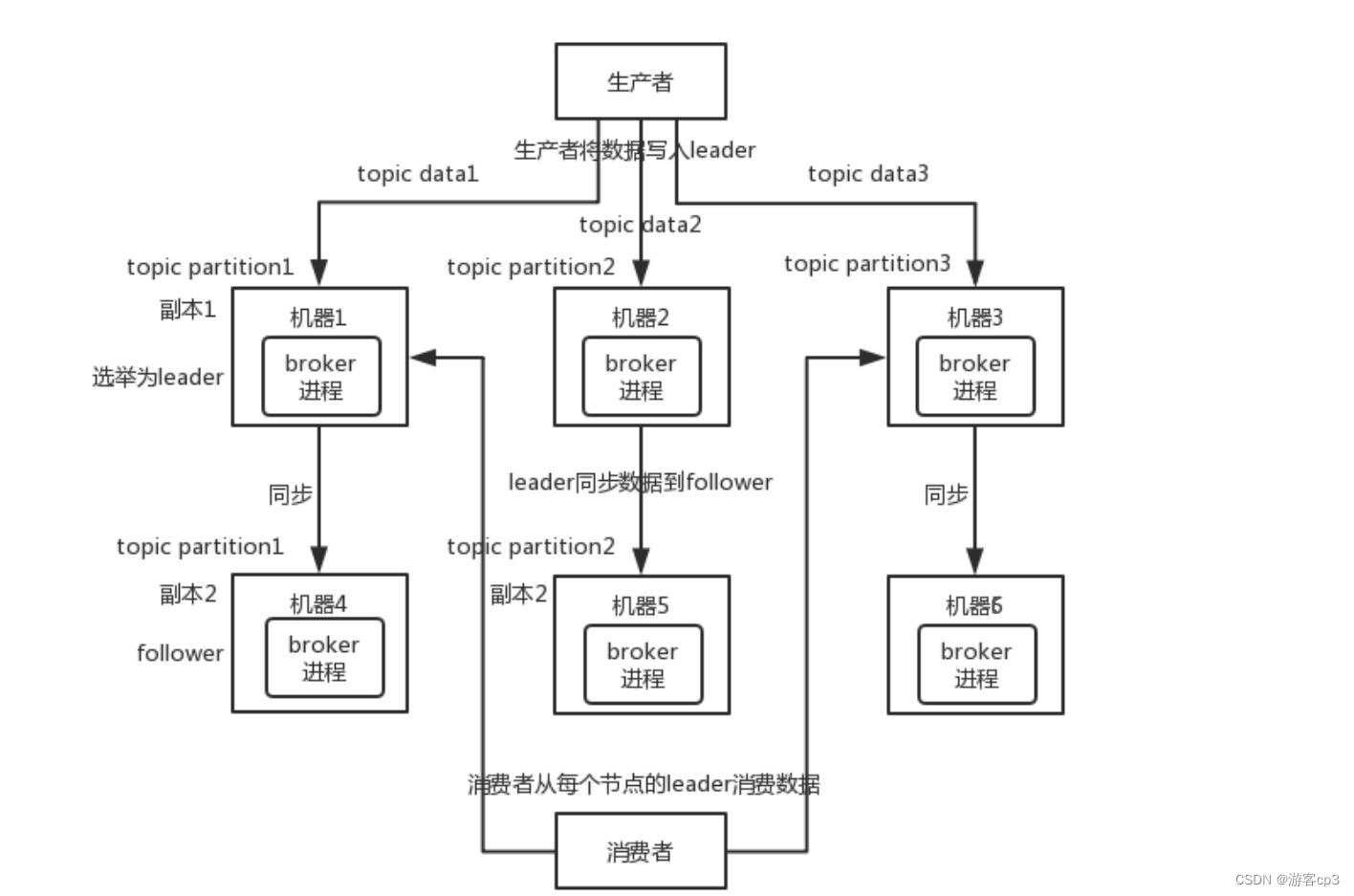
这么搞,就有所谓的高可用性了,因为如果某个 broker 宕机了,没事儿,那个 broker 上面的 partition 在其他机器上都有副本的。如果这个宕机的 broker 上面有某个 partition 的 leader,那么此时会从 follower 中重新选举一个新的 leader 出来,大家继续读写那个新的 leader 即可。这就有所谓的高可用性了。
写数据的时候,生产者就写 leader,然后 leader 将数据落地写本地磁盘,接着其他 follower 自己主动从 leader 来 pull 数据。一旦所有 follower 同步好数据了,就会发送 ack 给 leader,leader 收到所有 follower 的 ack 之后,就会返回写成功的消息给生产者。(保证一致性)
消费数据的时候,只会从 leader 去读,但是只有当一个消息已经被所有 follower 都同步成功返回 ack 的时候,这个消息才会被消费者读到。
如何选举leader?
- Kafka启动时,会在所有的broker中选举出一个controller,但只有一个竞争成功,其他的broker会注册该节点的监视器,一旦Controller所在broker崩溃,其他的broker会重新注册为Controller
- Controller为所有Topic的所有Partition指定Leader及Follower
- controller读取到当前分区的ISR,只要有Replica还幸存,任意选这个Replica作为leader
什么是ISR?
1、AR(Assigned Replicas)一个partition的所有副本(就是replica,不区分leader或follower)
2、ISR(In-Sync Replicas)能够和 leader 保持同步的 follower + leader本身 组成的集合。
3、OSR(Out-Sync Replicas)不能和 leader 保持同步的 follower 集合
4、公式:AR = ISR + OSR
Kafka对外依然可以声称是完全同步,但是承诺是对AR中的所有replica完全同步了吗?并没有。Kafka只保证对ISR集合中的所有副本保证完全同步。
ISR的机制就保证了,处于ISR内部的follower都是可以和leader进行同步的,一旦出现故障或延迟,就会被踢出ISR。
什么情况ISR中的replica会被踢出或返回ISR?
依据replica.lag.time.max.ms来判断,即follower在过去的replica.lag.time.max.ms时间内,已经追赶上leader一次了(和leader同步完同样的内容)。没同步完就被提出ISR
replica重新追上了leader,就会回到ISR中。
follower为什么会同步慢了
1、follower副本进程卡住,在一段时间内根本没有想leader副本发起同步请求,比如频繁的Full GC。
2、follower副本进程同步过慢,在一段时间内都无法追赶上leader副本,比如IO开销过大。
3、通过工具增加了副本因子,那么新增加的副本在赶上leader副本之前也都是处于失效状态的。
4、如果一个follower副本由于某些原因(比如宕机)而下线,之后又上线,在追赶上leader副本之前也是出于失效状态。
2.如何保证消息的顺序性?
什么是顺序性:以咱们系统为例,就是同一订单,生产者按放款-》还款的顺序将数据同步到kafka,消费者也要按照放款-》还款的顺序消费。
step one: 把同一订单的数据放到同一个Partition,然后再想办法。
比如说我们建了一个 topic,有三个 partition。生产者如何确定在发送消息的时候指定要发送到哪个Partition。详情看ProducerRecord类
我们需要将 producer 发送的数据封装成一个 ProducerRecord 对象。
(1)指明 partition 的情况下,直接将指明的值直接作为 partiton 值;
(2)没有指明 partition 值但有 key 的情况下,将 key 的 hash 值与 topic 的 partition数进行取余得到 partition 值;
(3)既没有 partition 值又没有 key 值的情况下,第一次调用时随机生成一个整数(后面每次调用在这个整数上自增),将这个值与 topic 可用的 partition 总数取余得到 partition值,也就是轮询。
比如说我们指定了某个订单 id 作为 key,那么这个订单相关的数据,一定会被分发到同一个 partition 中去,而且这个 partition 中的数据一定是有顺序的。
消费者从 partition 中取出来数据的时候,也一定是有顺序的。到这里,顺序还没有错乱。接着,我们在消费者里可能会搞多个线程来并发处理消息。因为如果消费者是单线程消费处理,而处理比较耗时的话,比如处理一条消息耗时几十 ms,那么 1 秒钟只能处理几十条消息,这吞吐量太低了。而多个线程并发跑的话,顺序可能就乱掉了。
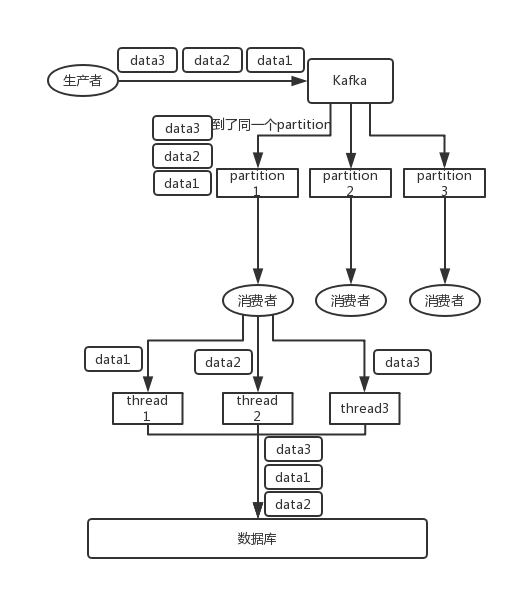
step two :数据在同一个partition中怎么按序消费
- 一个 topic,一个 partition,一个 consumer,内部单线程消费,单线程吞吐量太低,一般不会用这个。
- 写 N 个内存 queue,具有相同 key 的数据都到同一个内存 queue;然后对于 N 个线程,每个线程分别消费一个内存 queue 即可,这样就能保证顺序性。
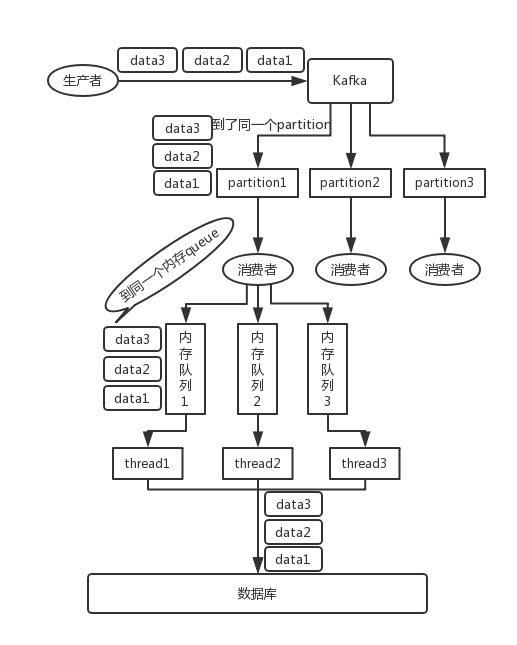
假如此时data1消费失败了,会导致data2、data3阻塞,可以先将data1放入一个暂存表,日后修复bug后继续消费。
3.如何保证消息消费的幂等性
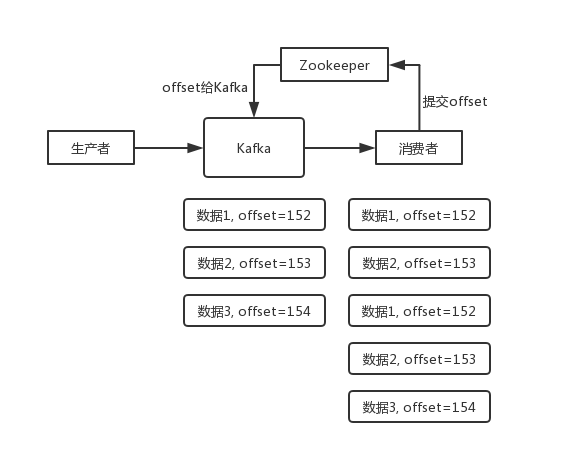
数据 1/2/3 依次进入 Kafka,Kafka 会给这三条数据每条分配一个 offset,代表这条数据的序号,我们就假设分配的 offset 依次是 152/153/154。消费者从 Kafka 去消费的时候,也是按照这个顺序去消费。假如当消费者消费了
offset=153
的这条数据,刚准备去提交 offset 到 Zookeeper,此时消费者进程被重启了。那么此时消费过的数据 1/2 的 offset 并没有提交,Kafka 也就不知道你已经消费了
offset=153
这条数据。那么重启之后,消费者会找 Kafka 说,你给我接着把上次我消费到的那个地方后面的数据继续给我传递过来。由于之前的 offset 没有提交成功,那么数据 1/2 会再次传过来,如果此时消费者没有去重的话,那么就会导致重复消费。
p.s. 新版的 Kafka 已经将 offset 的存储从 Zookeeper 转移至 Kafka brokers,并使用内部位移主题
__consumer_offsets
进行存储。
其得结合业务来思考,有几个思路可参考:
- 比如你拿个数据要写库,你先根据主键查一下,如果这数据都有了,你就别插入了,update 一下。
- 比如你是写 Redis,那没问题了,反正每次都是 set,key-value天然幂等。
- 比如稍微复杂一点的场景,你需要让生产者发送每条数据的时候,里面加一个全局唯一的 id,类似source_id ,然后你这里消费到了之后,先根据source_id 去比如 Redis 里查一下,之前消费过吗?如果没有消费过,你就处理,然后source_id 写 Redis。如果消费过了,那你就别处理了,保证别重复处理相同的消息即可。
- 比如基于数据库的唯一键来保证重复数据不会重复插入多条。因为有唯一键约束了,重复数据插入只会报错,不会导致数据库中出现脏数据。
版权归原作者 游客cp3 所有, 如有侵权,请联系我们删除。