
声明:
1. 本文针对的是一个知识的梳理,自行整理以及方便记忆
2. 若有错误不当之处, 请指出
一、hive的定义与理解
首先,hive是一个构建于hadoop集群之上的数据仓库应用。那么,得先了解一下什么是数据仓库?数据仓库是一个数据集合,用于支持管理决策。简单来说就是为了分析数据而设计的仓库。
那么hive就好理解了,hive是一个翻译器,不具备计算能力,存储能力,是一个构建于hadoop集群之上的系统,用于存储和处理数据。而它将得到的数据映射到一张数据表,然后存储在hafs之上。
hive提供了自己的SQL语句,即HQL,现在来看看和sql的不同之处,和SQL很多相似的地方,免去了学习一门新语言的时间,(对于我这种摆烂的还是挺好的)。
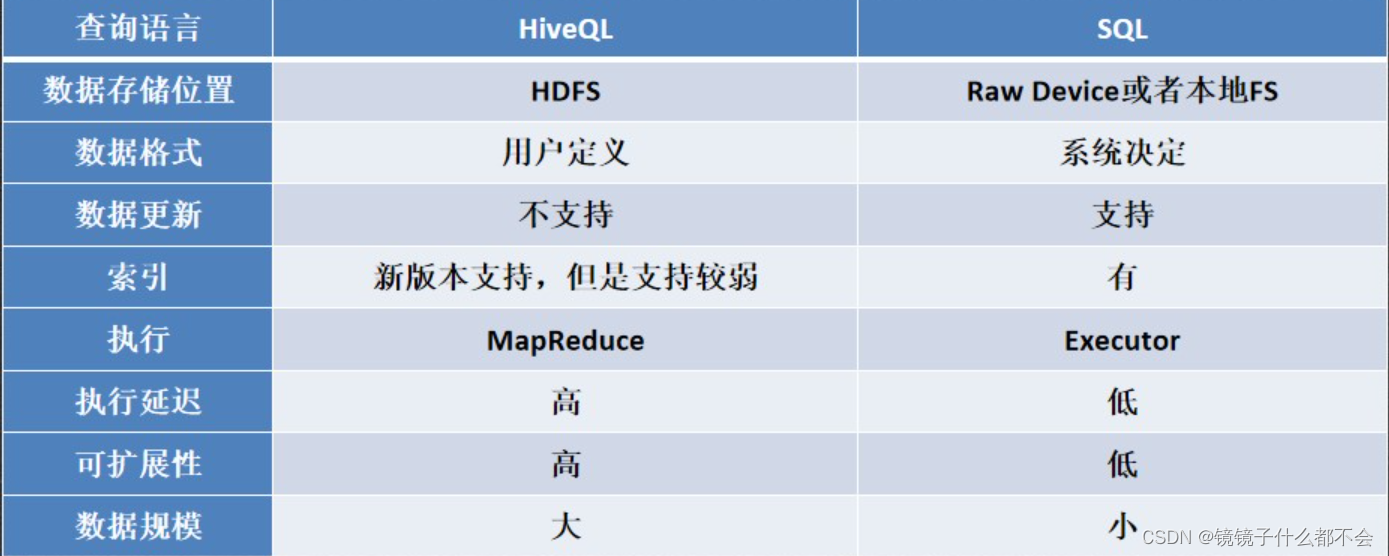
二、系统架构
如图所示,hive的的系统架构为这个,一般为以下几步:
1.用户建表,给入sql语句
2.Metastore(元数据)记录对应的路径。
3.映射表的关系返回给用户
4.通过接口连接hive,通过cli发布HQL
5.hive解析查询制订逻辑查询计划
6.转换成MapReduce作业
7.在Hadoop上执行MapReduce
运行机制

三、基本操作
DDL操作(数据定义语言)包括:Create、Alter、Show、Drop等。
(1)create database- 创建新数据库

查看仓库DB的信息和路径

(2)alter database - 修改数据库
(3)drop database - 删除数据库

(4)create table - 创建新表
先查看表,已存在cat这个表

.创建一个名为cat的内部表,有两个字段为cat_id和cat_name,字符类型为string。
create table cat(cat_id string,cat_name string);
创建一个外部表,表名为cat2,有两个字段为cat_id和cat_name,字符类型为string
create external table if not exists cat2(cat_id string,cat_name string);

(5)alter table - 变更(改变)数据库表
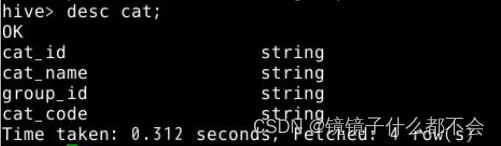
修改cat表的表结构。对cat表添加两个字段group_id和cat_code
alter table cat add columns(group_id string,cat_code string);
可以用desc cat查看
(6)drop table - 删除表
(7)create index - 创建索引(搜索键)
(8)drop index - 删除索引
(9)show table - 查看表
DML操作(数据操作语言)包括:Load 、Insert、Update、Delete、Merge。
(1)load data - 加载数据
①insert into - 插入数据
②insert overwrite - 覆盖数据(insert ... values从Hive 0.14开始可用。)
(2)update table - 更新表(update在Hive 0.14开始可用,并且只能在支持ACID的表上执行)
(3)delete from table where id = 1; - 删除表中ID等于1的数据(delete在Hive 0.14开始可用,并且只能在支持ACID的表上执行)
(4)merge - 合并(MERGE在Hive 2.2开始可用,并且只能在支持ACID的表上执行)
Hive中数据的导入导出
以下介绍四种常见的数据导入方式:
1.从本地文件系统中导入数据到Hive表。
首先,在Hive中创建一个cat_group表,包含group_id和group_name两个字段,字符类型为string,以“\t”为分隔符,并查看结果。
- create table cat_group(group_id string,group_name string) row format delimited fields terminated by '\t' stored as textfile;
- show tables;
[row format delimited]关键字,是用来设置创建的表在加载数据的时候,支持的列分隔符。
[stored as textfile]关键字,是用来设置加载数据的数据类型,默认是TEXTFILE,如果文件数据是纯文本,就是使用 [stored as textfile],然后从本地直接拷贝到HDFS上,Hive直接可以识别数据。

通过select语句查看cat_group表中是否成功导入数据,由于数据量大,使用limit关键字限制输出10条记录。
- select * from cat_group limit 10; 2.将HDFS上的数据导入到Hive中。首先,另外开启一个操作窗口,在HDFS上创建/myhive2目录。

- 然后,将本地/data/hive2/下的cat_group表上传到HDFS的/myhive2上,并查看是否创建成功。
- 将cat_group1表中的数据导入到cat_group2表中。
- insert overwrite table cat_group2 select * from cat_group1; (insert overwrite 会覆盖数据)
分区表
分区表实际上就是对应一个** HDFS 文件系统**上的独立的文件夹,该文件夹下是该分区所 有的数据文件。Hive 中的分区就是分目录,把一个大的数据集根据业务需要分割成小的数据集。在查询时通过 WHERE 子句中的表达式选择查询所需要的指定的分区,这样的查询效率会提高很多
创建表分区,在Hive中创建一个分区表goods,包含goods_id和goods_status两个字段,字符类型为string,分区为cat_id,字符类型为string,以“\t“为分隔符。(partition by 用来定义分区 )
- create table goods(goods_id string,goods_status string) partitioned by (cat_id string) row format delimited fields terminated by '\t';
向分区表插入数据,将本地/data/hive2下的表goods中数据,插入到分区表goods中。
首先,在Hive中创建一个非分区表goods_1表,用于存储本地/data/hive2下的表goods中数据。
- create table goods_1(goods_id string,goods_status string,cat_id string) row format delimited fields terminated by '\t';
- 导表操作 将本地/data/hive2下的表goods中数据导入到Hive中的goods_1表中load data local inpath '/data/hive2/goods' into table goods
同理,再将表goods_1中的数据导入到分区表goods中 ** insert into table **goods **partition**(cat_id='52052') select goods_id,goods_status from goods_1 where cat_id='52052';- 查看表goods中的分区 show partitions goods;

- 分桶是将数据集分解成更容易管理的若干部分的另一个技术。桶为表提供了额外的结构,Hive在处理某些查询时利用这个结构,能够有效地提高查询效率。 分区针对的是数据的存储路径;分桶针对的是数据文件。
- 创建桶创建一个名为goods_t的表,包含两个字段goods_id和goods_status,字符类型都为string,按cat_id string做分区,按goods_status列聚类和goods_id列排序,划分成两个桶,clustered by用来指定划分通分桶用的列和要划分桶的个数create table goods_t(goods_id string,goods_status string) partitioned by (cat_id string) ** clustered by**(goods_status) sorted by (goods_id)** into 2 buckets**;
- 用insert子句将其他表中的数据加载到分桶表 insert overwite table good1 select * from goods_t; (每个桶对于MapReduce的输出文件分区,一个作业产生)1. 导入数据的语法 (1)load data [local] inpath 'filepath' [overwrite] into table tablename [partition(partcol=val1,partcol2=cal2...)] local的意思是导入linux的本地的数据,若是从hdfs上导入就不用加 filepath指的是数据的路径 overwrite指定覆盖表之前的数据 partition分区表的意思 (2)单表查询导入数据 insert [overwrite|into] table 表1 [partition (part1=val1,part2=val2) ] select字段1,字段2,字段3 from 表2;2.

版权归原作者 镜镜子什么都不会 所有, 如有侵权,请联系我们删除。