
购物信息分析基于spark
本案例中三个文案例中需要处理的文件为 order_goods.txt、products.txt 以及 orders.txt 三个文件,三个文件的说明如下
order_goods.txt

products.txt
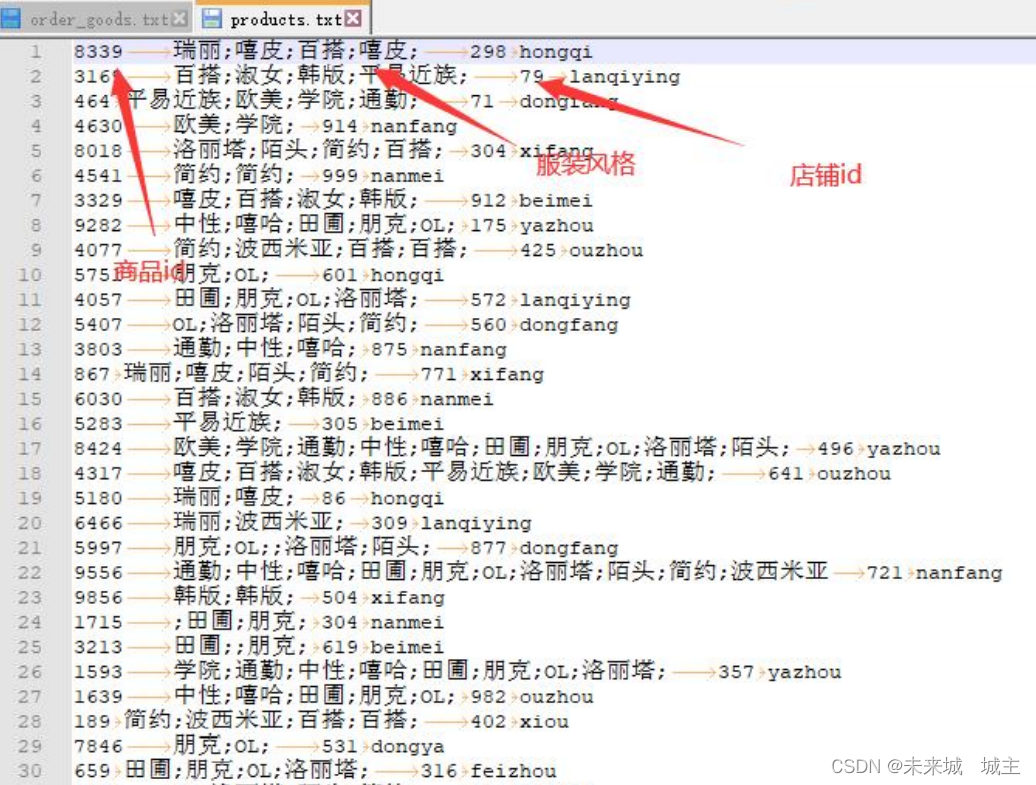
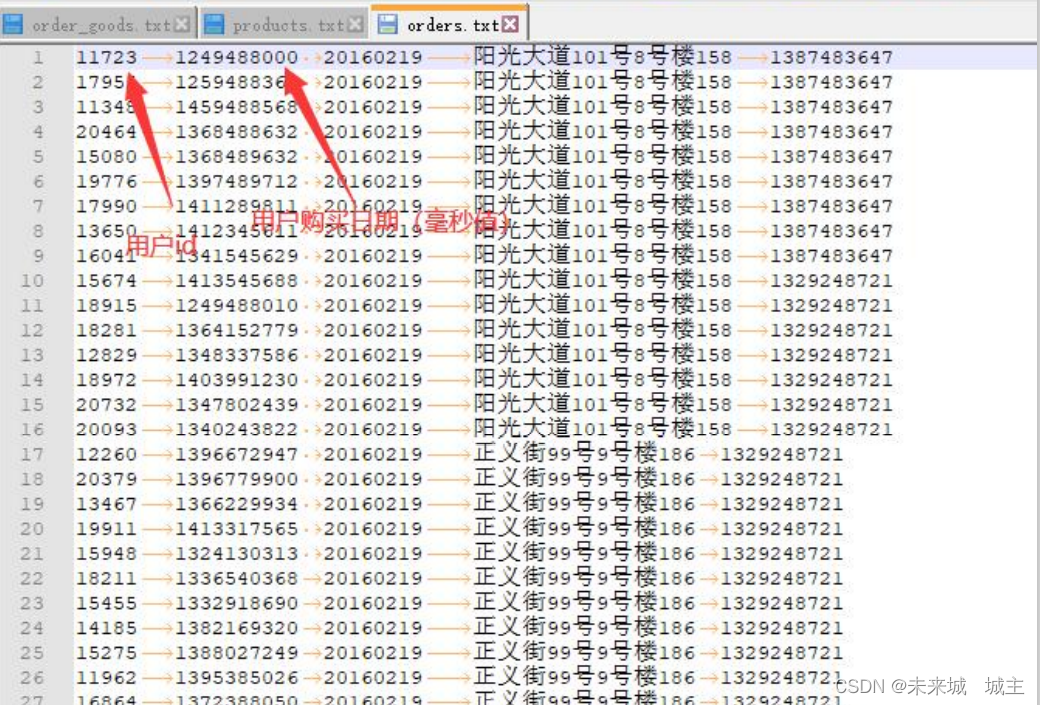
orders.txt
一、本实训项目针对实验数据主要完成了哪些处理?
1数据清洗
1.1需求描述 数据清洗--DataClear
1)order_goods.txt 中缺少元素的
- products.txt 中缺少元素的
1.2 解题思路 案例中需要处理的文件为 order_goods.txt、products.txt,读取每个文件并按行处理,使 用 filter 函数过滤行中个字段是否为空字符串,如为空字符串则丢掉。
2商户画像
2.1 需求描述 计算店铺画像,既合并商户的所有不同服装的风格
2.2 解题思路
a. 读取文件并切分
b. 重新排列数据,商户 id 为 key,以服装风格为值重新排列
c. 按照商户 id分组并合并服装风格并且去重
3计算店铺订单数
3.1 需求描述 计算每个商铺的总订单数
3.2 解题思路
a. 以商品 id 作为关联,将 order_goods 和 product 进行 join 操作,操作结果形成单商品 对应多((用户 id,商品风格),店铺 id))结构, 格式为(商品 id,((用户 id,商品风 格),店铺 id)));
b. 取出店铺 id 计算数量
4计算用户(卖家)画像
4.1 需求描述 通过买家购买的服装,计算买家穿衣风格画像
4.2. 解题思路
a.读取 order_goods 和 products,以商品 id 为 key 进行 join 操作,生成数据结构为(商 品 id,(用户 id,服装风格))
b. 取出(用户 id,服装风格)进行 groupByKey(或 reduceByKey,建议 reduceByKey)操作, 将用户购买服装风格进行连接,
c. 去除掉结果数据中重复的风格
5消费习惯
5.1 需求描述 取每个 uid 下订单最多的那一天,并判断是周末还是工作日(即提取用户是喜欢在周末购物 还是工作日购物特征)
5.2 解题思路
a.读取 orders.txt,根据毫秒值计算星期几
b.按照整条记录分组,也就是将用户名和周 X 整个作为分组条件
c.分组后,t._2 默认是 CompactBuffer 类型,将其转换为 List 然后计算其元素数量,就是 这个用户在周 X
二、Hadoop+Spark集群环境的搭建步骤有哪些?*(只介绍完全分布式集群环境的搭建)*
1.安装虚拟机
2设置网络
3主机名和ip映射
4上传安装包并解压安装
5设置环境变量
6启动hadoop
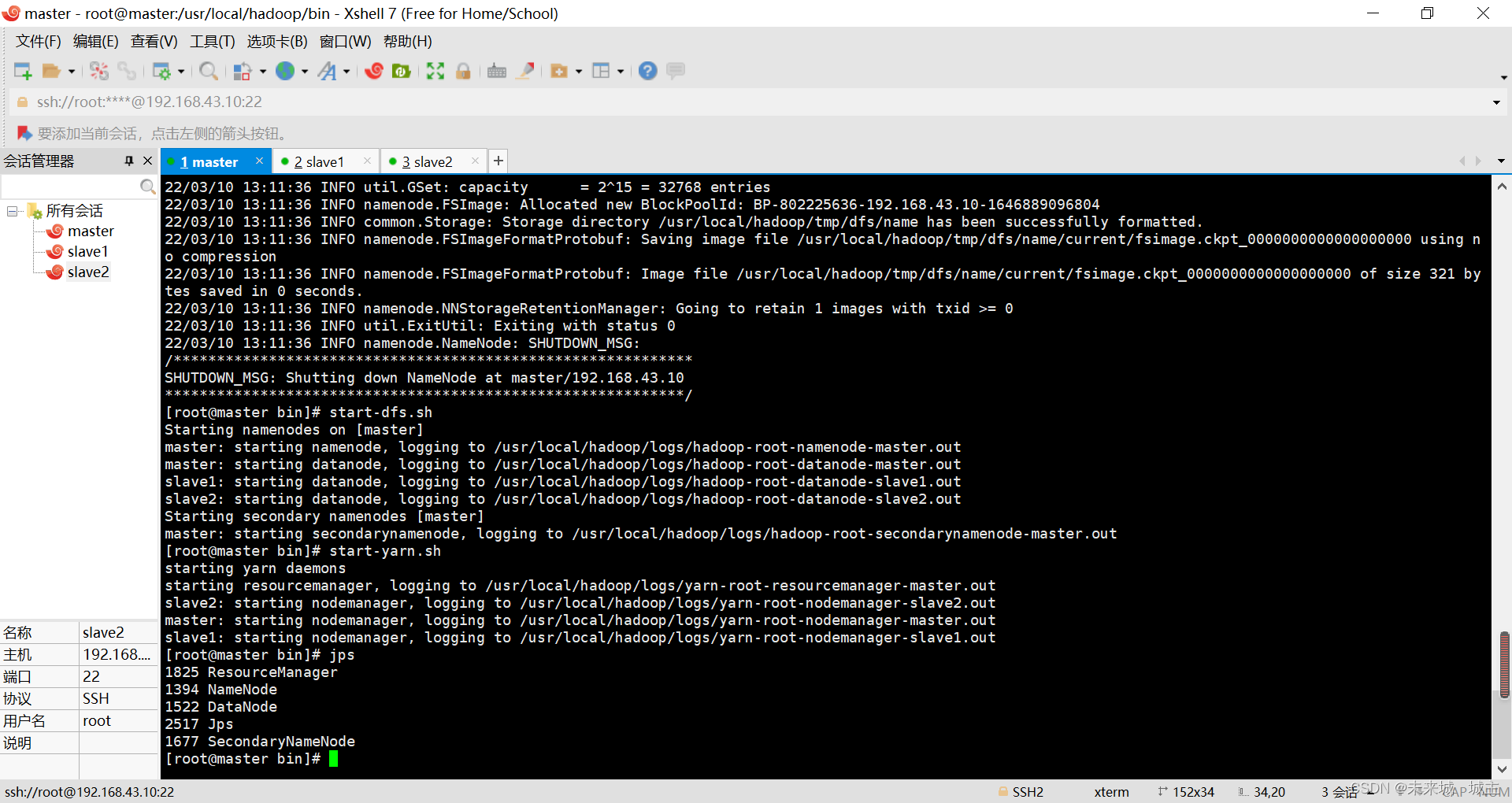
7使用jps 显示进程 Hadoop的hdfs和yarn成功启动
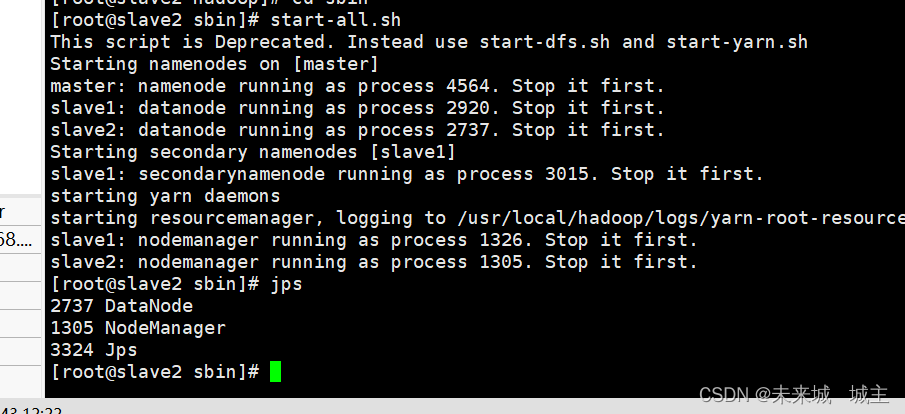
8上传spark安装包并且安装 spark本地模式安装完毕
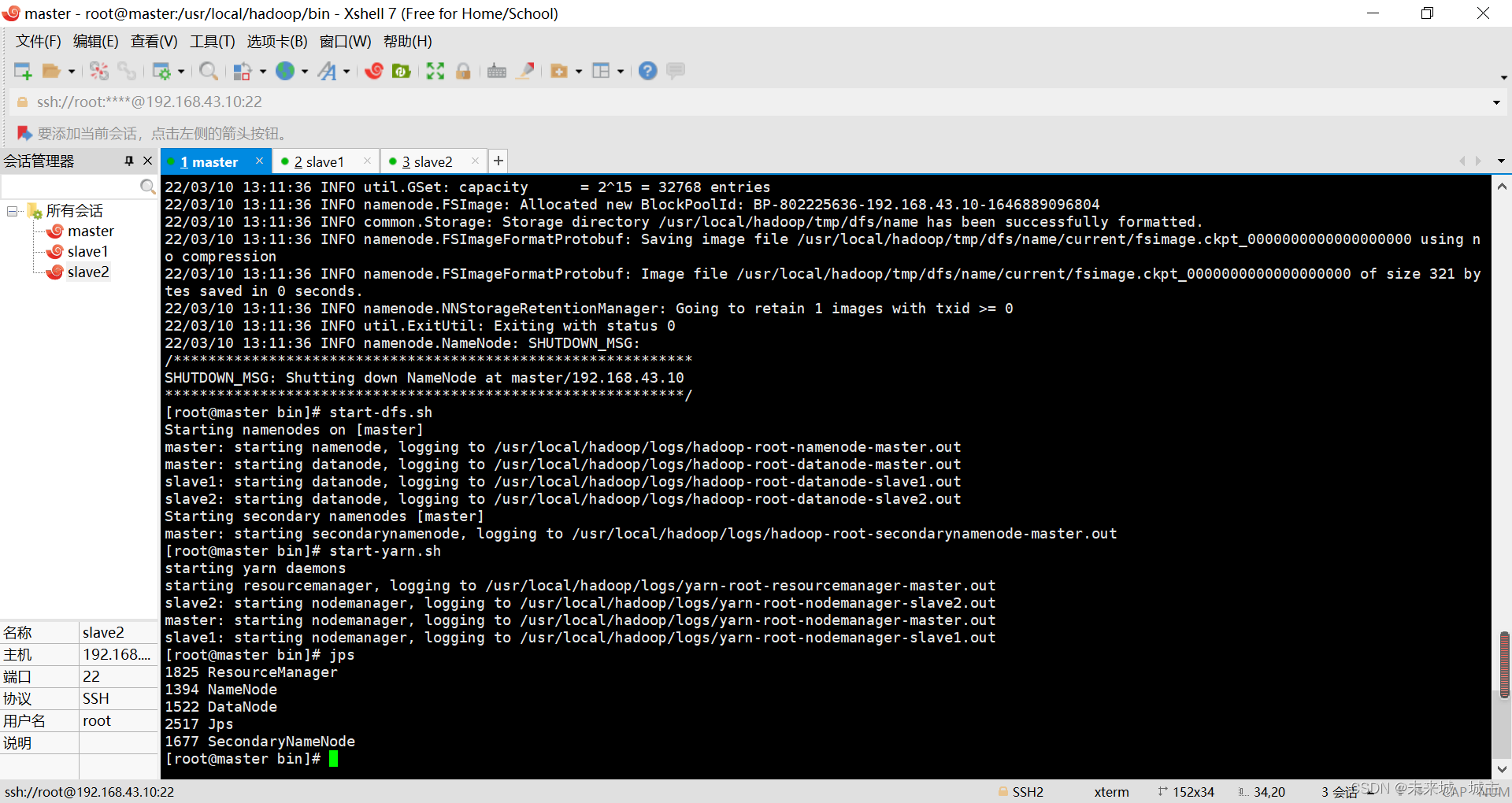
三、本人在搭建Hadoop+Spark完全分布式集群过程中出现了哪些问题?如何解决的?
1.经常直接关闭虚拟机损坏了hdfs文件,导致进入安全模式
删除所有hdfs受损文件或者强制退出安全模式
2.清理电脑内存时,不小心删除了镜像文件,导致虚拟机全部崩溃
重新下载镜像文件,并且重置网络设置
3.Hdfs的从节点中有一个datanode不启动
关闭集群删除从节点所有日志和文件,主节点重新格式化hdfs,启动集群
4.集群中的hdfs datanode节点容易崩溃
重置了网络,改用手机热点,比以前稳点了许多
四、描述数据清理过程过程,最终要得到的数据中是对原数据做了哪些处理?
1读取文件中的数据构建RDD,然后把其中的每个数据按照\t进行分割构成数组,然后遍历数组中的数据如果有空数据就不写入RDD,数据齐全写入RDD
两个数据清洗类似,就不做过多介绍。
代码如下
import org.apache.spark.{SparkConf, SparkContext}
object DataClean {
def main(args: Array[String]): Unit = {
//第一步 数据清洗 order_goods.txt、products.txt 买家和卖家信息
val Conf = new SparkConf().setMaster("local").setAppName("DataClean")
val sc = new SparkContext(Conf)
val data1 = sc.textFile("data/products.txt")
data1.filter(num => {
//将数据按行分割
val lines = num.split("\t")
var judge = true
//遍历数组元素
for (s <- lines) {
if (s.isEmpty) {
judge = false
}
}
//返回boolean类型
judge
}).saveAsTextFile("data/product_clean1")
val data2 = sc.textFile("data/order_goods.txt")
data2.filter(num => {
//将数据按行分割
val lines = num.split("\t")
var judge = true
//遍历数组元素
for (s <- lines) {
if (s.isEmpty) {
judge = false
}
}
//返回boolean类型
judge
}).saveAsTextFile("data/order_good_clean1")
sc.stop()
}
}
2运行结果
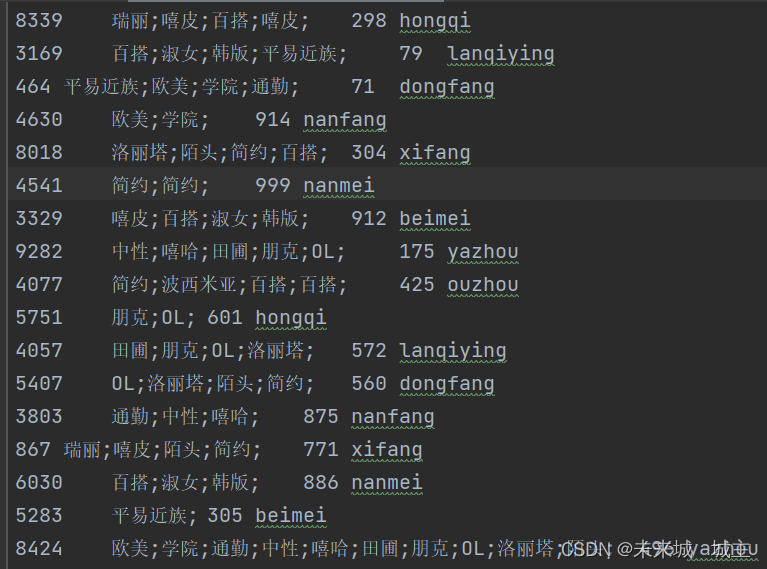

五、计算商铺服装风格实现思路是?最终程序的运行结果是?
代码
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object CompactStyle {
def main(args: Array[String]): Unit = {
//第二步 商家画像 将商户所有的风格进行合并
val Conf = new SparkConf().setMaster("local").setAppName("CompactStyle")
val sc = new SparkContext(Conf)
val value = sc.textFile("data/product_clean1/part-00000")
.map(line => line.split("\t"))
.map(kv => (kv(2), kv(1)))
.reduceByKey(_ + _)
.mapValues(v => {
val strings: Array[String] = v.split(";")
var list = List[String]()
for(values<-strings){
if(!list.contains(values)){
list=values::list
}
}
list.mkString(";")
})
.map(t => t._1 + "\t" + t._2)
.saveAsTextFile("data/product_compact2")
}
}
1读入数据后,将数据进行切分,然后将店铺id和风格映射成(店铺id,风格)的元组
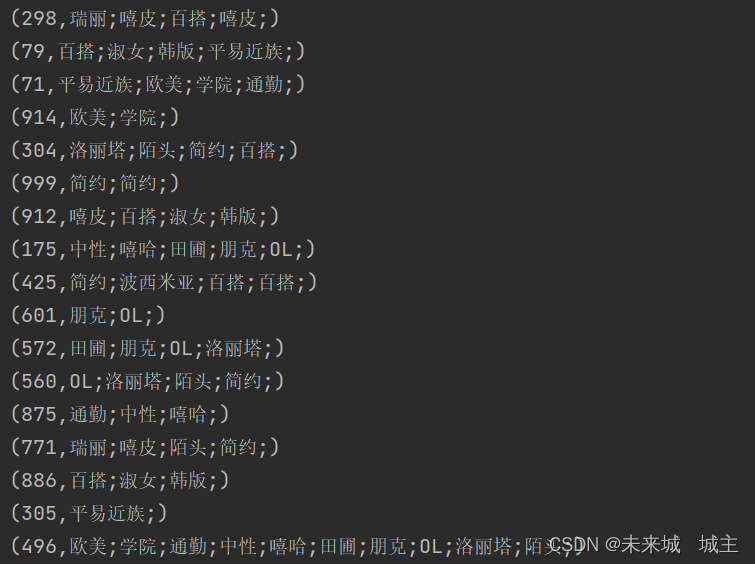
2运用reduceBykey将数据进行累加

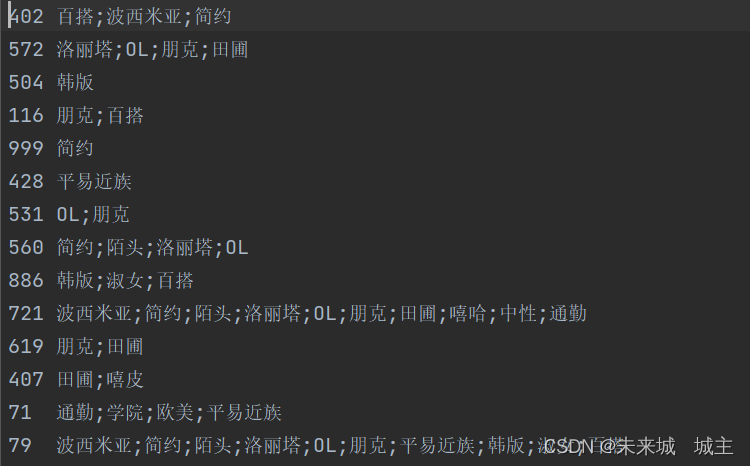
3但是我们不难发现第一行数据中风格有重复,所以我们要去重,运用mapvalues将数据中的风格生成list,遍历通过是否包含来达到去重的目的,结果如下也是最终结果。
六、计算店铺订单数时如何实现的?结果如何?
代码
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object OrdersCalculate {
def main(args: Array[String]): Unit = {
val Conf = new SparkConf().setMaster("local").setAppName("Calculate")
val sc = new SparkContext(Conf)
val data1: RDD[String] = sc.textFile("data/order_good_clean1/part-00000")
val data2: RDD[String] = sc.textFile("data/product_clean1/part-00000")
val data1_split: RDD[Array[String]] = data1.map(line => line.split("\t"))
val data2_split: RDD[Array[String]] = data2.map(line => line.split("\t"))
val rd1: RDD[(String, String)] = data1_split.map(v => (v(1), v(0))) //(商品id,用户id)
val rd2: RDD[(String, (String, String))] = data2_split.map(v => (v(0), (v(1), v(2)))) //(商品id,(风格,店铺id))
val rd3: RDD[(String, (String, (String, String)))] = rd1.join(rd2)
val rd4: RDD[(String, ((String, String), String))] = rd3.map(v => (v._1, ((v._2._1, v._2._2._1), v._2._2._2)))
val rd5: RDD[(String, Int)] = rd4.map(v => (v._2._2, 1))
val rd6: RDD[(String, Int)] = rd5.reduceByKey(_ + _)
//rd6.collect().foreach(println)
val data3: RDD[String] = sc.textFile("data/product_compact2")
val rdd1: RDD[Array[String]] = data3.map(line => line.split("\t"))
val rdd2: RDD[(String, String)] = rdd1.map(kv => (kv(0), kv(1)))
val rdd3: RDD[(String, (Int, String))] = rd6.join(rdd2)
rdd3.collect().foreach(println)
val rd7: RDD[(String, (Int, String))] = rdd3.sortBy(_._2._1, false)
//rd7.collect().foreach(println)
val rd8: RDD[String] = rd7.map(v => v._1 + "\t" + v._2._1 + "\t" + v._2._2)
rd8.saveAsTextFile("data/store_number3")
sc.stop()
}
}
1读取product和order清洗过的数据并且进行映射,两者的key都用商品id为接下来的join操作做准备
(商品id,用户id)

(商品id,(风格,店铺id))
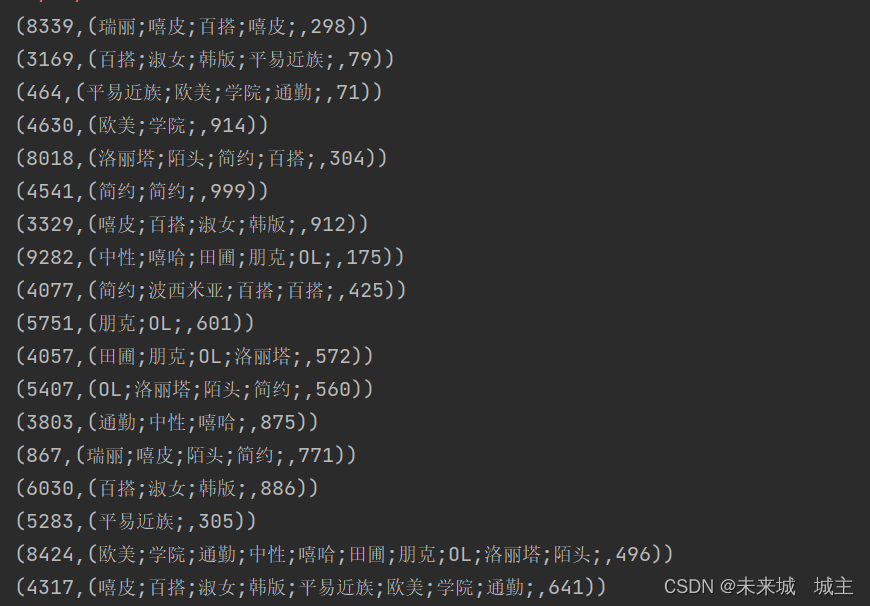
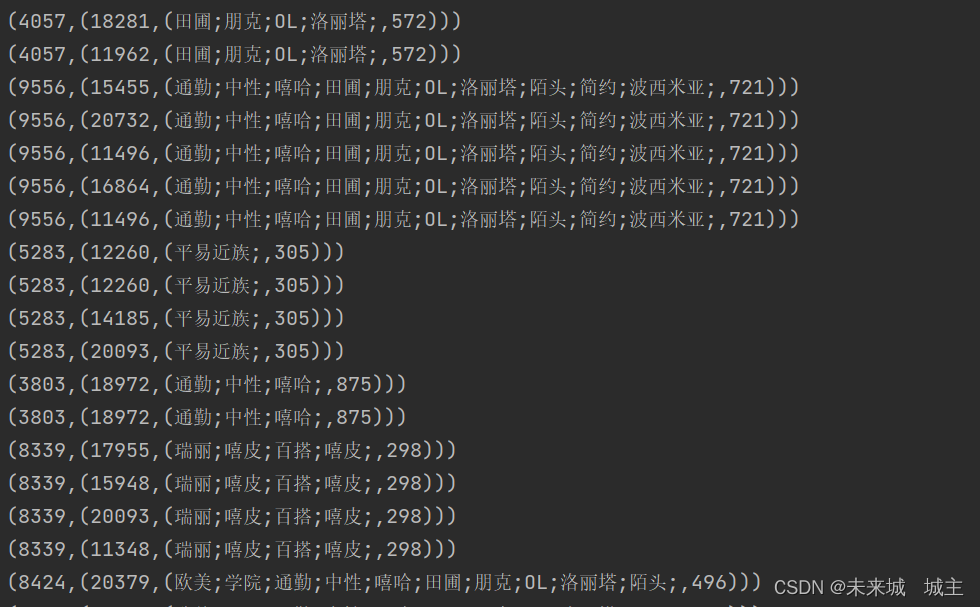
3通过join链接两个rdd,相同商品id的会链接在一起 结果如下图1
然后通过map变成题目要求中rdd
(商品 id,((用户 id,商品风 格),店铺 id)))如下图2
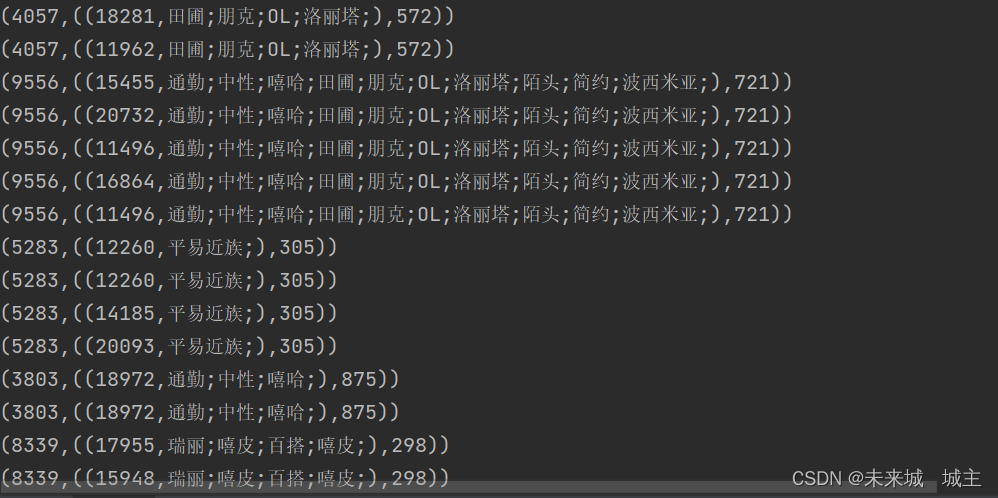
4取出店铺id,通过map操作将其映射为(店铺id,1),然后通过reducebykey累加,计算该店铺的订单但数量,至此我们得到了(店铺id,数量)的rdd。

5我们一定得到了店铺的订单数量的一个rdd,假设我们是一个大数据推荐系统的话,我们肯定会把订单数量最高的推荐给用户,亦或者把用户所需要的风格销量最高的店铺或者商品推荐给用户,因为之前我们做过商户画像,所以这里直接拿它的结果来用,进行一个jion操作,并且进行排序。
画像结果如下
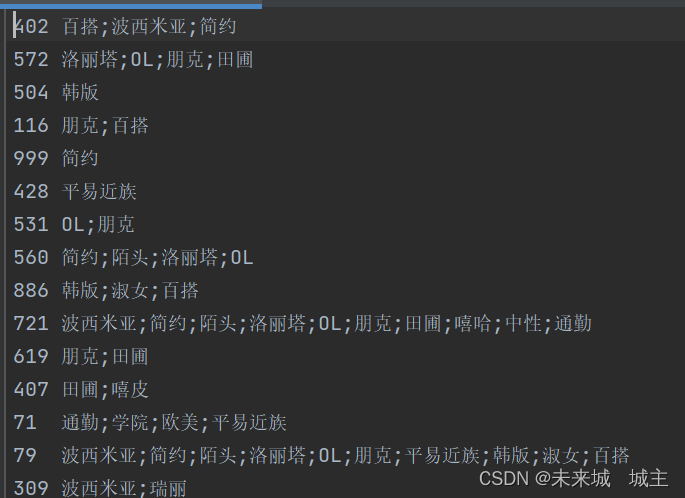
通过店铺id join的结果为(店铺id,(订单数,风格))如下
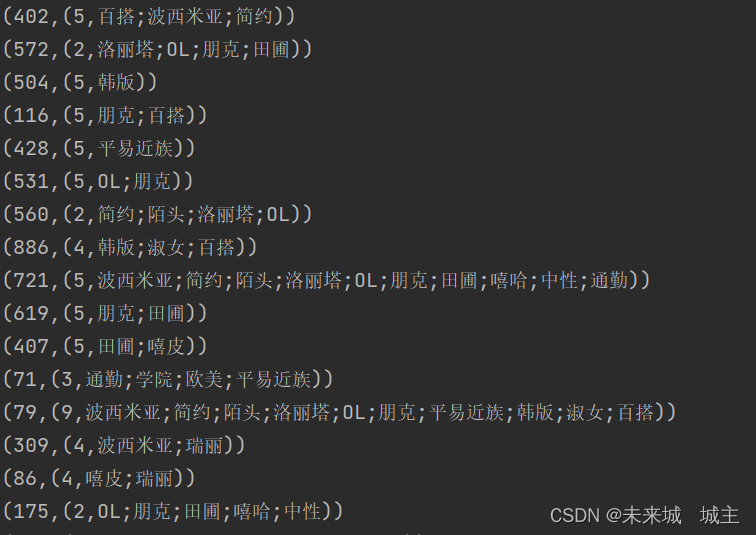
通过订单数进行排序得到的最终结果就是如下

通过此图可以看出,如果用户趋向于买某个风格的衣服,可以从上而下进行筛选推荐,如果我想买ol的衣服,就会推荐79,531,721,357店铺,更加立体显明。
七、计算买家服装风格画像的实现思路是?最终程序的运行结果是?
代码如下
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object OrderStyle {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local").setAppName("OrderStyle")
val sc = new SparkContext(sparkConf)
val data1: RDD[(String,String)] = sc.textFile("data/order_good_clean1/part-00000")
.map(v => v.split("\t"))
.map(v => (v(1),v(0))) //商品id,用户id
val data2: RDD[(String, String)] = sc.textFile("data/product_clean1/part-00000")
.map(v => v.split("\t"))
.map(v => (v(0), v(1))) //商品id,风格
val data_join: RDD[(String, (String, String))] = data1.join(data2)
//data_join.collect().foreach(println)
val rd1: RDD[(String, String)] = data_join.map(v => (v._2._1, v._2._2))
//rd1.collect().foreach(println)
val rd2: RDD[(String, String)] = rd1.reduceByKey(_ + _)
rd2.collect().foreach(println)
val rd3: RDD[(String, String)] = rd2.mapValues(v=>{
val strings: Array[String] = v.split(";")
var list = List[String]()
for(values<-strings){
if(!list.contains(values)){
list=values::list
}
}
list.mkString(";")
})
rd3.collect().foreach(println)
//rd3.map(v => v._1+"\t"+v._2).saveAsTextFile("data/orders_style_sta4")
sc.stop()
}
}
1读取producst和order_goods清洗过的数据并且进行映射,两者的key都用商品id为接下来的join操作做准备
结果为(商品id,(用户id,风格)如下
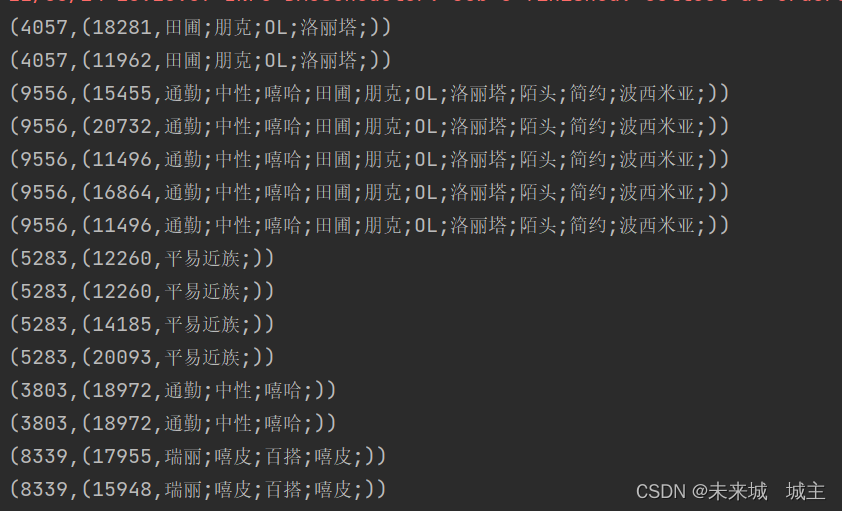
2我们可从图中看出,无论是店铺还是用户都是由重复的,接下来就是要进行风格的合并,店铺id对我们来说已经没有用了,我们要将其舍弃,将其映射为(用户id,风格)
结果为
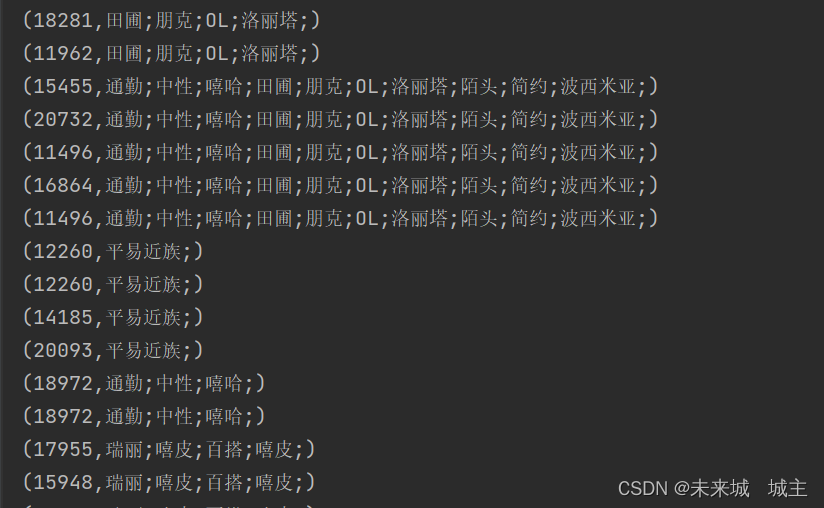
3通过用户id进行风格累加并且去重
累加结果为

我们可以看到有很多风格重复
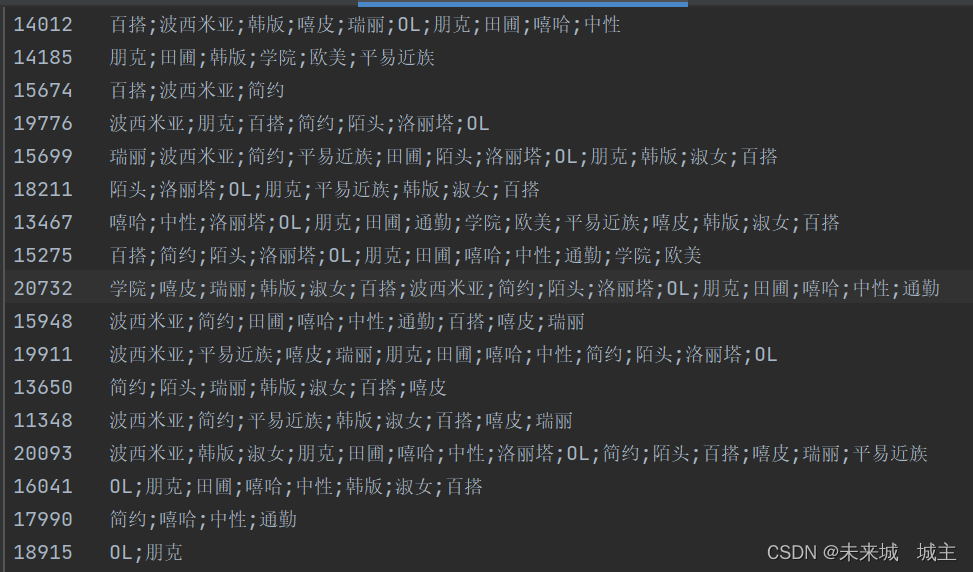
去重结果

最终结果就是将其存储 如下
八、 消费习惯是如何实现的?最终的运行结果是?
代码如下
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import java.util.{Calendar, Date}
object BuyTime {
def main(args: Array[String]): Unit = {
def weekArr(i: Int):Int ={
var a = i
if(a==1) {
a = 7
}else{
a -=1
}
a
}
val sparkConf = new SparkConf().setMaster("local").setAppName("BuyTime")
sparkConf.set("spark.default.parallelism", "1")
val sc = new SparkContext(sparkConf)
val data: RDD[String] = sc.textFile("data/orders.txt")
val datas: RDD[Array[String]] = data.map(_.split("\t"))
val value_date: RDD[(String, Int)] = datas.map(d => {
val date = new Date(d(1).toLong)
val cal = Calendar.getInstance()
cal.setTime(date)
val date_week = weekArr(cal.get(Calendar.DAY_OF_WEEK))
(d(0),date_week)
})
//value_date.collect().foreach(println)
val week_gp: RDD[((String, Int), Iterable[(String, Int)])] = value_date.groupBy(week => week)
//week_gp.collect().foreach(println)
val week_tj: RDD[((String, Int), Int)] = week_gp.map(week => (week._1, week._2.toList.count(num => num != null)))
week_tj.collect().foreach(println)
val week_px: RDD[((String, Int), Int)] = week_tj.sortBy({
t => t._2
},false)
.sortBy({
t => t._1._2
},true)
week_px.map(k => k._1._1+"\t"+k._1._2+"\t"+k._2)
.saveAsTextFile("data/shopping_habit5")
sc.stop()
}
}
1读入数据拆分,首先要对购买日期进行处理,将毫秒值转换成星期,因为中外文化差异,国外一周的第一天是周六,所以有编写了函数date_week()将其转化成中式的
并且将其映射成(用户id,周几)
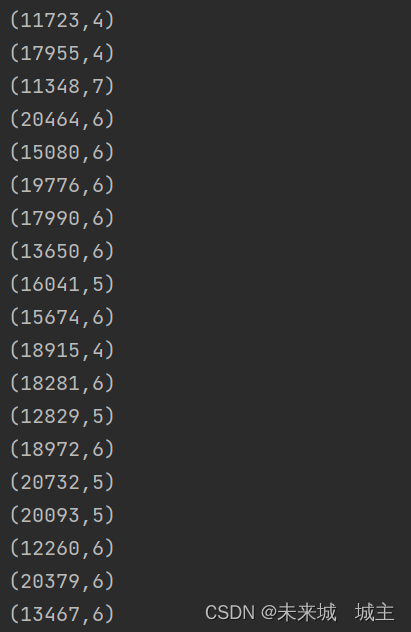
2通过groupby分组 CompactBuffer的长度就是购买次数
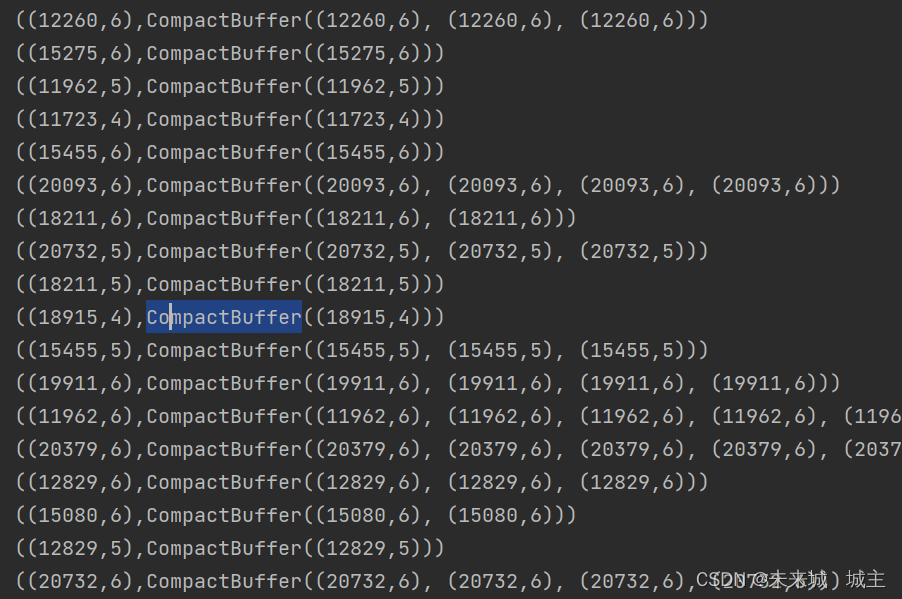
3通过map操作构成((用户id,周几),次数)

4根据购买次数排序,根据周数排序要将同一周的排在一起
结果如下
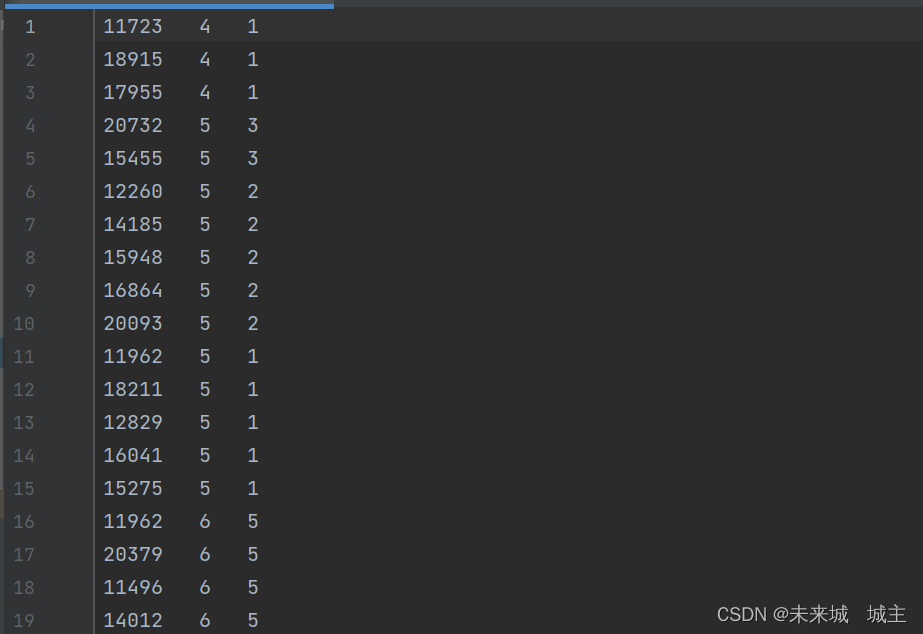
九 、开发过程中遇到的技术难点有哪些?如何解决的?
1.针对同一店铺或者同一卖家,进行风格累加时,会造成风格重复问题
解决:运用mapvalues针对值进行操作,按照‘;’进行分割,遍历通过是否包含来达到去重的目的。
2.join问题,不理解这个join操作认为这一步没有用
解决:仔细发现我们所需要的数据在两个文件中,只能通过join操作链接,这个操作类似于数据空中的链接操作。
3.排序问题(最后一步的)
解决:如果用两个单独的排序达不到想要的结果,只有连续的排序才可以,就是先安周数排序,再组内排序。
十、本项目开发中获得的经验和不足?
经验:亲身经历了从数据清洗到结果输出的过程,越发理解大数据的内涵,把大量的,杂乱的数据通过spark技术得出相应的更加立体的数据结果的时候,才真正发现数据的价值,更能通过这些数据结果对未来进行预测,是一件非常有成就感的事情,借此希望学习更多的大数据技术。
不足:发现自己处理数据的思路单一,不连贯,不够抽象化,可能还是接触项目太少吧,希望以后浪潮能够提供更多的项目案例,提升实战经验提高自我。
版权归原作者 马武寨山的猴子 所有, 如有侵权,请联系我们删除。