
版本信息
python 3.8.16
datahub v0.10.0
操作记录
安装datahub v0.10.0

详见datahub官网 A Metadata Platform for the Modern Data Stack | DataHub
执行命令
python3 -m pip install --upgrade pip wheel setuptools
python3 -m pip install --upgrade acryl-datahub==0.10.0
查看版本
python3 -m datahub version

datahub 快速部署
将datahub v0.10.0分支下的docker-compose-without-neo4j.quickstart.yml文件准备到本地
datahub/docker-compose-without-neo4j.quickstart.yml at v0.10.0 · datahub-project/datahub · GitHub
确保以下端口未被占用
- 3306 for MySQL
- 9200 for Elasticsearch
- 9092 for the Kafka broker
- 8081 for Schema Registry
- 2181 for ZooKeeper
- 9002 for the DataHub Web Application (datahub-frontend)
- 8080 for the DataHub Metadata Service (datahub-gms)
如有占用在命令行传参进行替换
datahub docker quickstart --mysql-port 53306
执行
python3 -m datahub docker quickstart -f ./docker-compose-without-neo4j.quickstart.yml --version v0.10.0
开始拉取镜像

成功构建容器,datahub启动成功
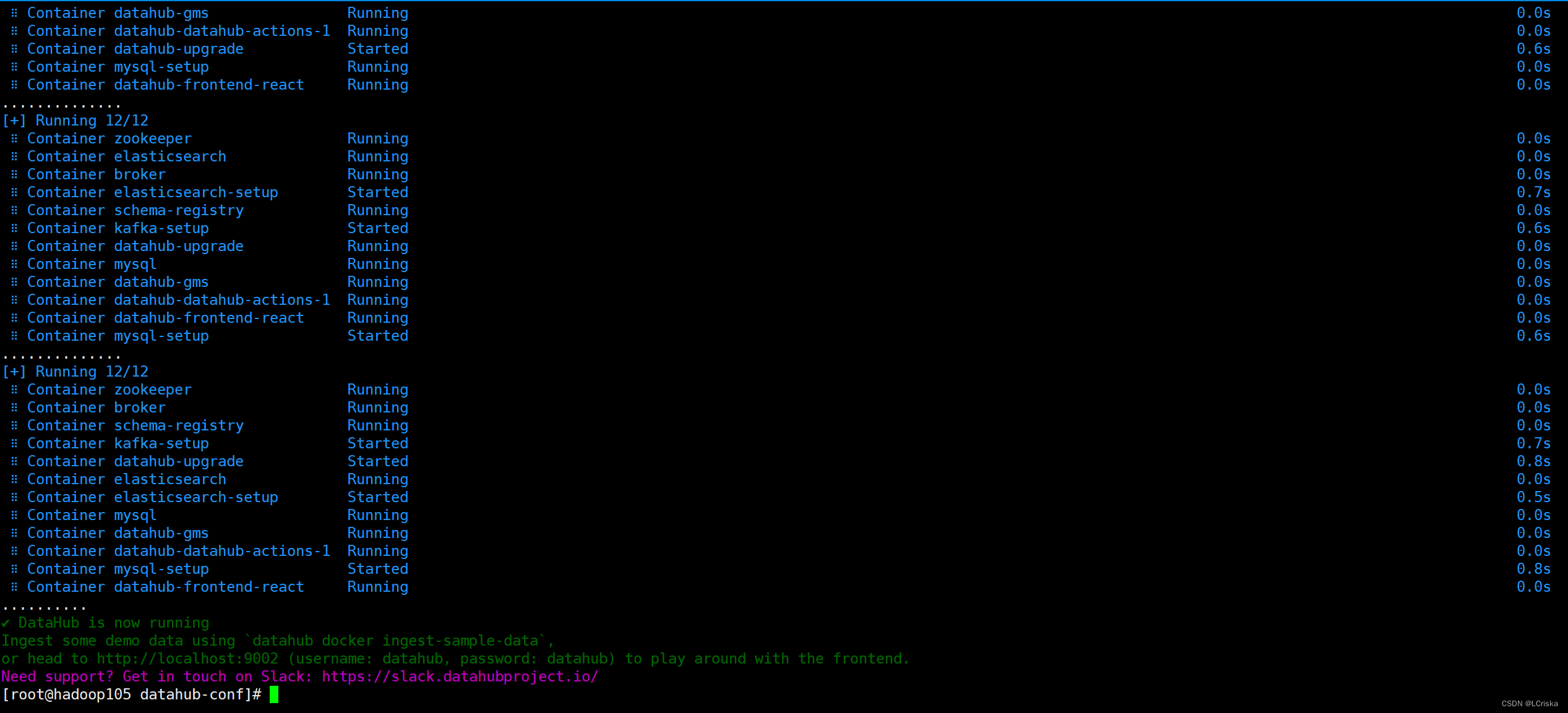
访问hadoop105:9002

输入账号、密码datahub

元数据摄取
安装hive插件
python3 -m pip install 'acryl-datahub[hive]'
安装过程中报错

尝试安装依赖项
yum -y install gcc gcc-c++ python-devel.x86_64 cyrus-sasl-devel.x86_64 gcc-c++.x86_64
再次安装hive插件
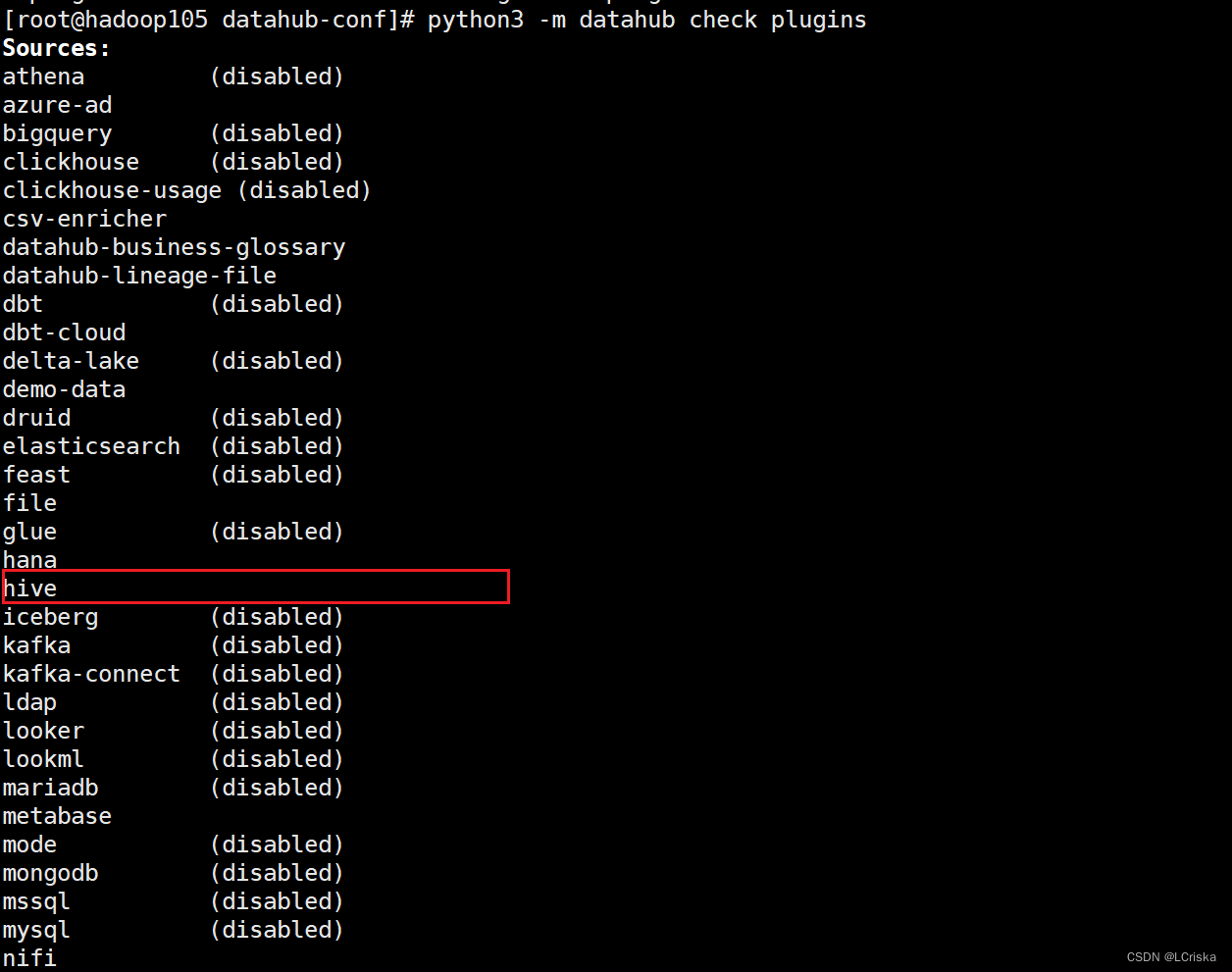
检查datahub插件
python3 -m datahub check plugins
hive插件成功安装
编写摄取hive元数据的配置文件
source:
type: "hive"
config:
host_port: "hadoop102:10000" # hiveserver2
sink:
type: "datahub-rest"
config:
server: "http://hadoop105:8080" # datahub gms server
开始摄取hive元数据
python3 -m datahub ingest -c ./hive-metadata-ingestion.yml
元数据摄取完成
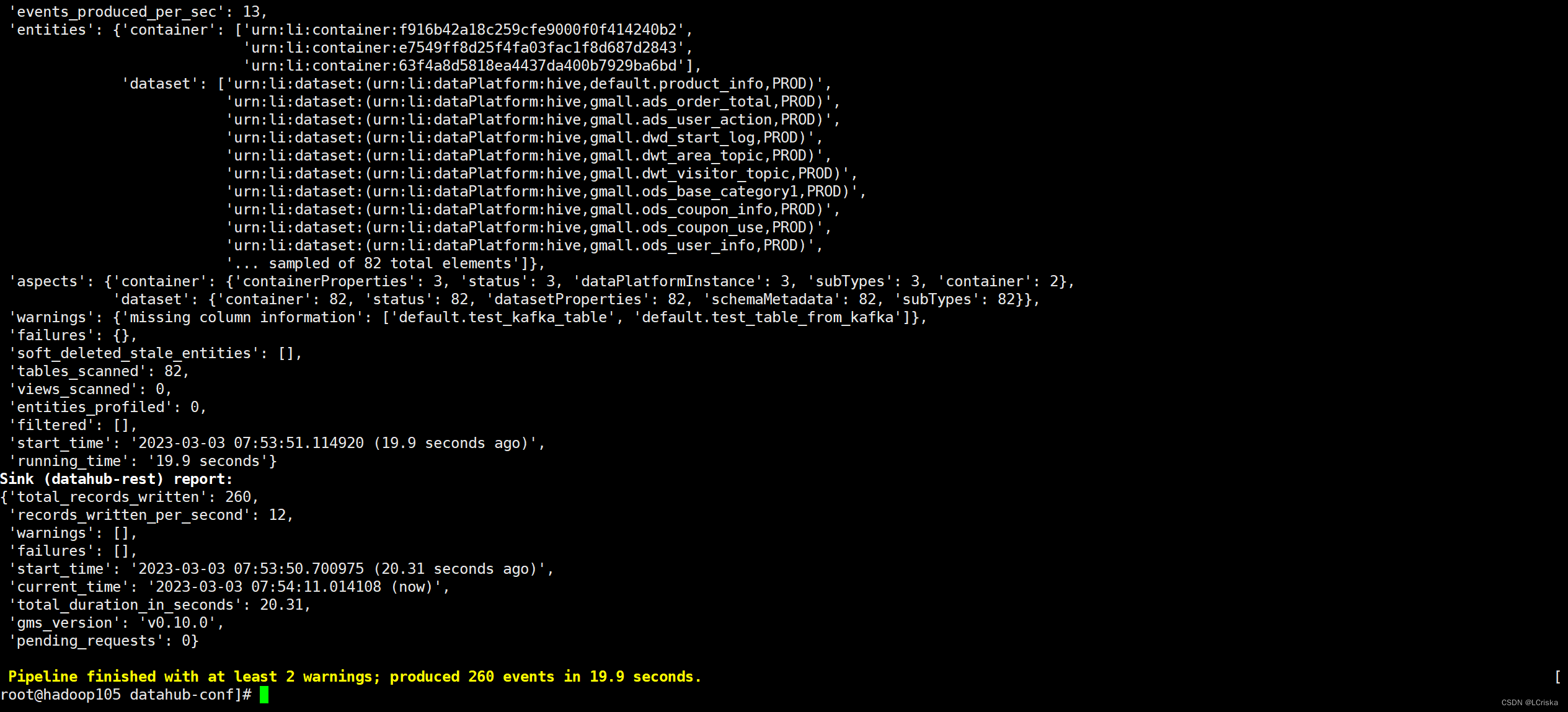
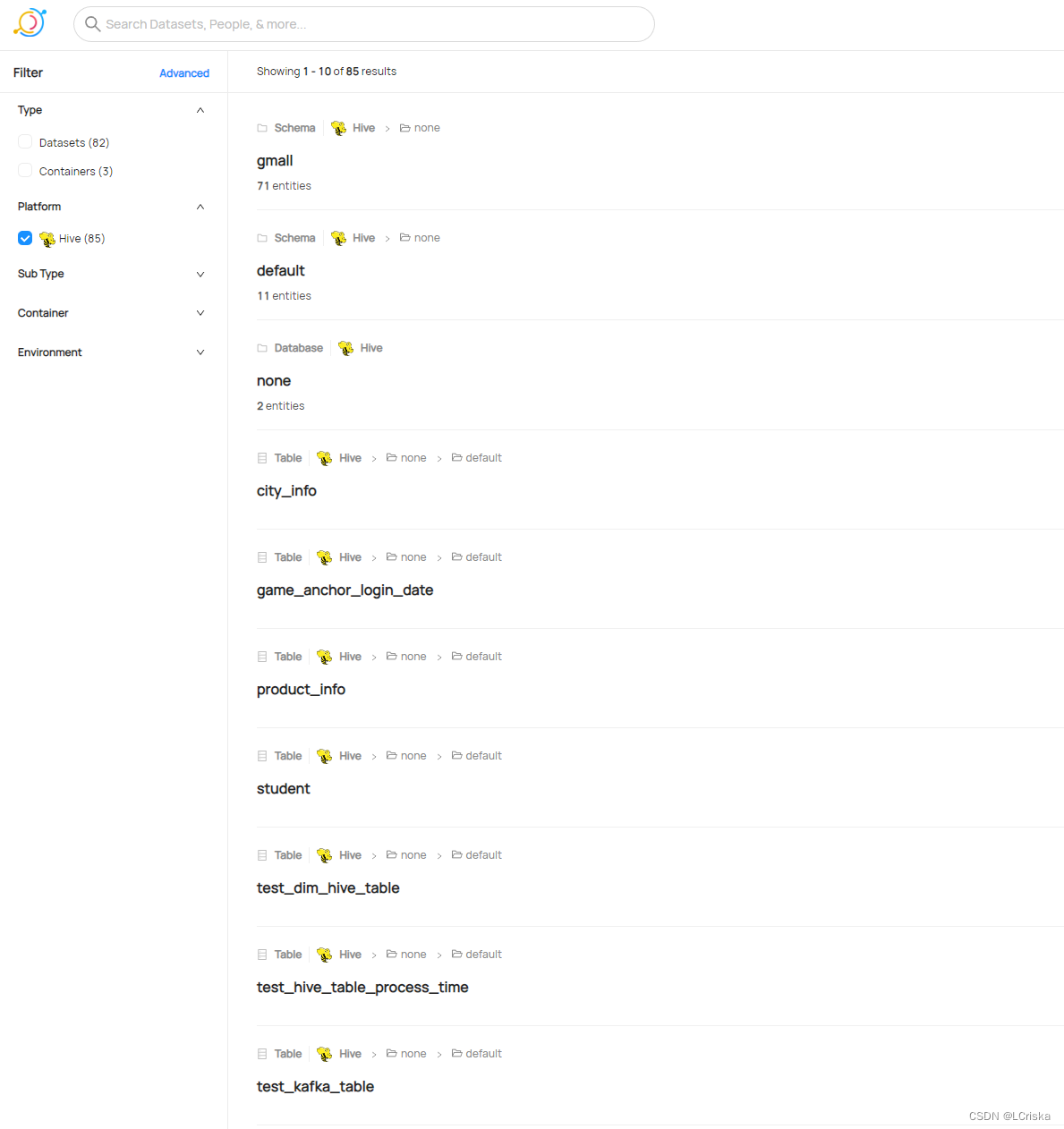
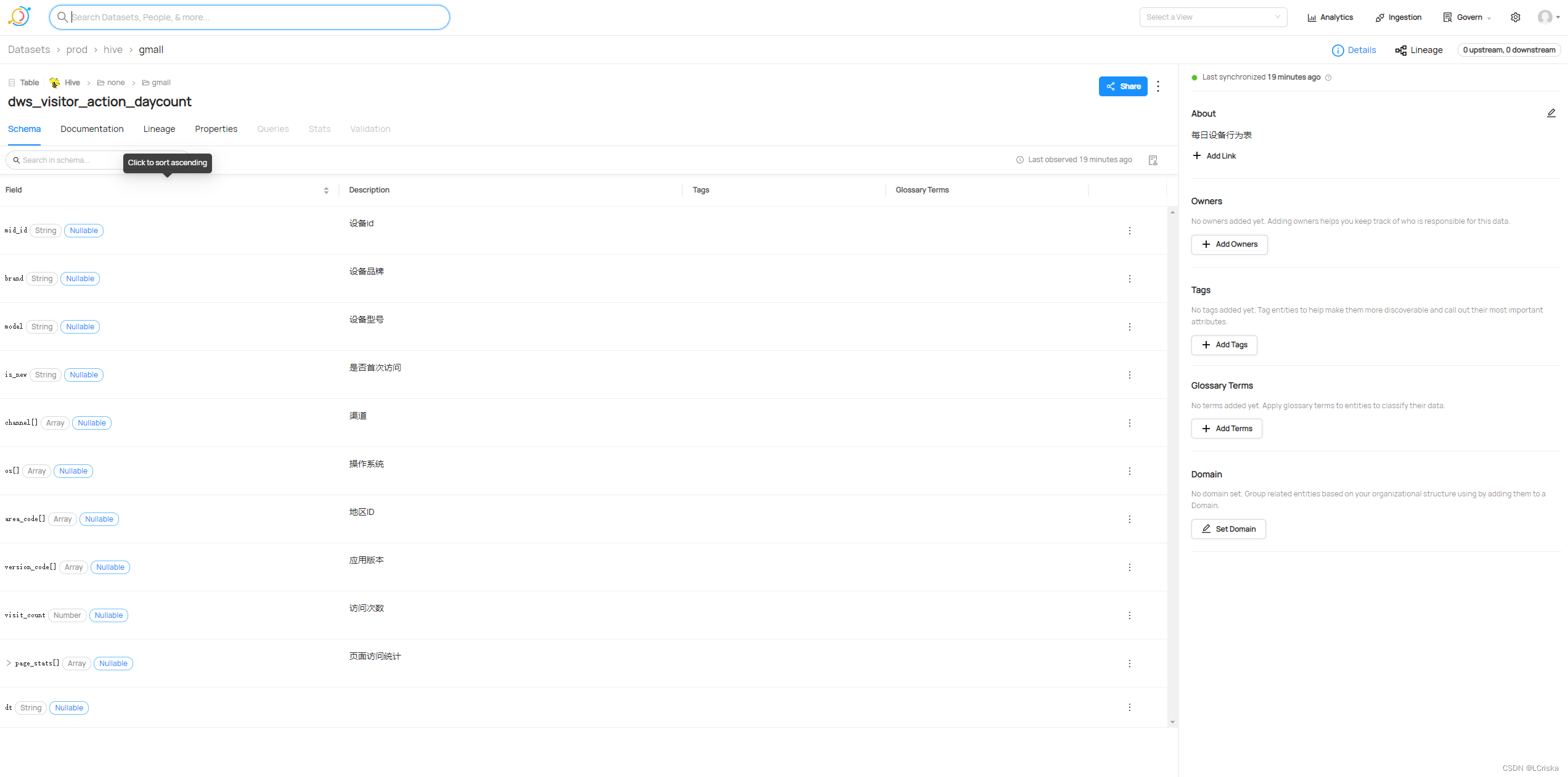
进入web页面查看

通过sqllineage获取指定sql文件中HiveSQL的字段级血缘关系,并将结果提交到datahub
参考datahub官方文档给出的提交细粒度血缘的脚本datahub/lineage_emitter_dataset_finegrained.py at master · datahub-project/datahub · GitHub
参考sqllineage文档Getting Started — sqllineage 1.3.7 documentation
结合sqllineage,获取指定sql的列级血缘,再调用datahub rest api,将结果提交到datahub
具体py代码如下
from sqllineage.runner import LineageRunner
import datahub.emitter.mce_builder as builder
from datahub.emitter.mcp import MetadataChangeProposalWrapper
from datahub.emitter.rest_emitter import DatahubRestEmitter
from datahub.metadata.com.linkedin.pegasus2avro.dataset import (
DatasetLineageType,
FineGrainedLineage,
FineGrainedLineageDownstreamType,
FineGrainedLineageUpstreamType,
Upstream,
UpstreamLineage,
)
import sys
'''
解析目标sql文件的HiveSQL生成列级血缘,提交到datahub
sql文件路径作为命令行参数传入脚本
提交到datahub的platform = hive
'''
# 库名设置
def datasetUrn(tableName):
return builder.make_dataset_urn("hive", tableName) # platform = hive
# 表、列级信息设置
def fieldUrn(tableName, fieldName):
return builder.make_schema_field_urn(datasetUrn(tableName), fieldName)
# 目标sql文件路径
sqlFilePath = sys.argv[1]
sqlFile = open(sqlFilePath, mode='r', encoding='utf-8')
sql = sqlFile.read().__str__()
# 获取sql血缘
result = LineageRunner(sql)
# 获取sql中的下游表名
targetTableName = result.target_tables[0].__str__()
print(result)
print('===============')
# 打印列级血缘结果
result.print_column_lineage()
print('===============')
# 获取列级血缘
lineage = result.get_column_lineage
# 字段级血缘list
fineGrainedLineageList = []
# 用于冲突检查的上游list
upStreamsList = []
# 遍历列级血缘
for columnTuples in lineage():
# 上游list
upStreamStrList = []
# 下游list
downStreamStrList = []
# 逐个字段遍历
for column in columnTuples:
# 元组中最后一个元素为下游表名与字段名,其他元素为上游表名与字段名
# 遍历到最后一个元素,为下游表名与字段名
if columnTuples.index(column) == len(columnTuples) - 1:
downStreamFieldName = column.raw_name.__str__()
downStreamTableName = column.__str__().replace('.' + downStreamFieldName, '').__str__()
# print('下游表名:' + downStreamTableName)
# print('下游字段名:' + downStreamFieldName)
downStreamStrList.append(fieldUrn(downStreamTableName, downStreamFieldName))
else:
upStreamFieldName = column.raw_name.__str__()
upStreamTableName = column.__str__().replace('.' + upStreamFieldName, '').__str__()
# print('上游表名:' + upStreamTableName)
# print('上游字段名:' + upStreamFieldName)
upStreamStrList.append(fieldUrn(upStreamTableName, upStreamFieldName))
# 用于检查上游血缘是否冲突
upStreamsList.append(Upstream(dataset=datasetUrn(upStreamTableName), type=DatasetLineageType.TRANSFORMED))
fineGrainedLineage = FineGrainedLineage(upstreamType=FineGrainedLineageUpstreamType.DATASET,
upstreams=upStreamStrList,
downstreamType=FineGrainedLineageDownstreamType.FIELD_SET,
downstreams=downStreamStrList)
fineGrainedLineageList.append(fineGrainedLineage)
fieldLineages = UpstreamLineage(
upstreams=upStreamsList, fineGrainedLineages=fineGrainedLineageList
)
lineageMcp = MetadataChangeProposalWrapper(
entityUrn=datasetUrn(targetTableName), # 下游表名
aspect=fieldLineages
)
# 调用datahub REST API
emitter = DatahubRestEmitter('http://datahub-gms:8080') # datahub gms server
# Emit metadata!
emitter.emit_mcp(lineageMcp)
执行py脚本
python3 sql-lineage-to-datahub.py target.sql
查看web界面
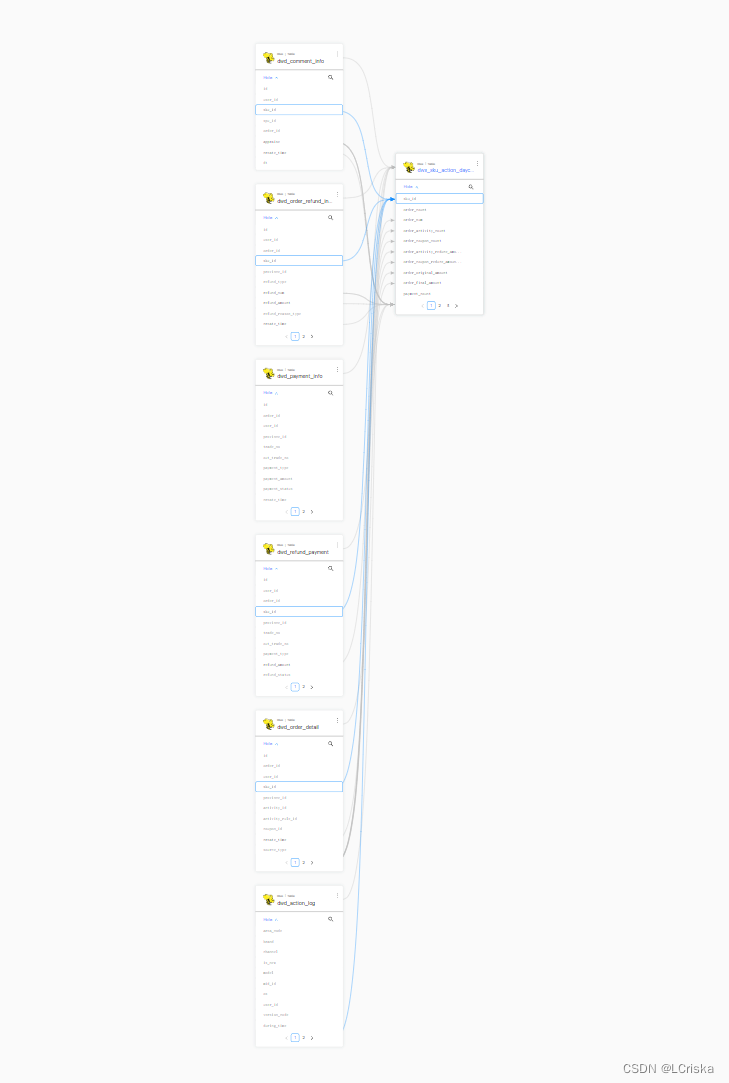
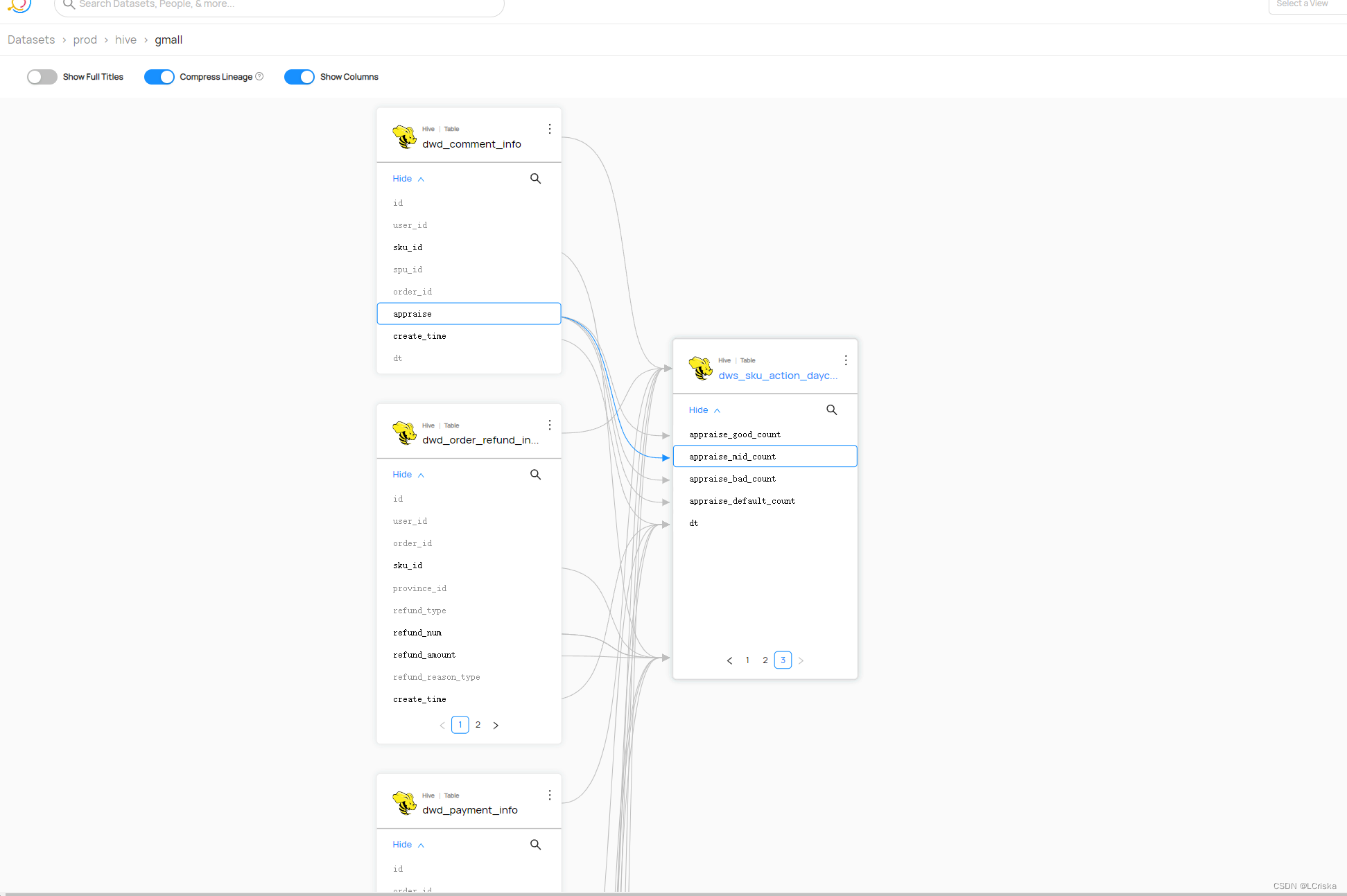
本文转载自: https://blog.csdn.net/LCriska/article/details/129329492
版权归原作者 LCriska 所有, 如有侵权,请联系我们删除。
版权归原作者 LCriska 所有, 如有侵权,请联系我们删除。