
文章参考了两篇csdn文章:
手动使用EEGlab进行脑电数据预处理的全过程_fdgdf5535的博客-CSDN博客 (本篇使用了文章框架)
脑电数据预处理:手把手教你手动调用EEGlab函数,完成EEG数据预处理(附完整代码)_eeg预处理代码-CSDN博客
第一期:使用Matlab和eeglab对脑电数据进行预处理_哔哩哔哩_bilibili
学习了eeglab的UI界面全过程。 这个视频将重参考步骤放到第四步,滤波之前,文章一将重参考放到最后并说明了好处。
学习了UI界面和调用函数代码的操作和批处理的过程。将UI界面和代码操作说明清楚,降低学习难度。
脑电数据分析预处理步骤
1.(Import data)导入数据
2.(Channel locations)电极定位+降采样率
3.(Select data)剔除无用电极
4.(filter the data)滤波
5.(Extract epochs and Remove baseline)分段和基线校正
6.Artifact rejection (bad channel and epoch) (剔除坏段、插值坏导)
7.(Independent component analysis, ICA)独立成分分析(ICA)
8.(Remove components)剔除伪迹成分(去伪迹)
9.(Reject extreme values)自动去除极端值
10.(Re-reference)重参考
脑电数据分析预处理详细步骤
0.(Start EEGLAB)启动EEGLAB
关于版本
matlab2022a
eeglab v2023.1
(1)启动matlab
(2)将eeglab文件夹添加至路径(全英文路径!)
Set path→Add with subfolders 选择eeglab文件夹点击 save后点击close



选择文件夹后按ctrl+A全选
(3)command window 命令行窗口输入eeglab以后弹出eeglab界面


1.(Import data)导入数据
clc;clear;
%% Specify Basic information of different groups 将cdt文件转换成set文件,降采样为500,去除无用电极,保存。
group_dir = 'D:\demo'; % 此处路径需要设置为自己的文件目录
group_files = dir([group_dir, filesep, '*.cdt']); %filesep是\的意思
for i=1:length(group_files)
subj_fn = group_files(i).name;
EEG = loadcurry(strcat(group_dir, filesep, subj_fn), 'CurryLocations', 'False'); %导入原始数据
EEG = pop_resample( EEG, 500); %降采样
EEG = pop_eegfiltnew(EEG, 'locutoff',1,'hicutoff',80); %带通滤波
EEG = pop_eegfiltnew(EEG, 'locutoff',48,'hicutoff',52,'revfilt',1); %陷波滤波
EEG = pop_select( EEG, 'rmchannel',{'M1','M2','HEO','VEO','TRIGGER'}); %去除无关电极
EEG = pop_saveset( EEG, 'filename',strcat(group_files(i).name(1:end-4), '.set'), 'filepath',strcat(group_dir, filesep, '_step1')); %注意需要在运行代码之前,文件目录下建一个_resam_remch的文件夹,以下雷同
end
%% 运行 ICA
group1_dir = 'D:\demo'; % 此处路径需要设置为自己的文件目录
group1_dir1 = 'D:\demo\_preica'; % 此处路径需要设置为自己的文件目录
group1_files = dir([group1_dir1, filesep, '*.set']); %filesep是\的意思
for i=1:length(group1_files)
subj_fn = group1_files(i).name;
EEG = pop_loadset('filename',strcat(subj_fn(1:end-4), '.set'), 'filepath', strcat(group1_dir, filesep, '_preica')); %导入数据
EEG = pop_runica(EEG, 'icatype', 'runica', 'extended',1,'interrupt','on'); % 跑ICA
EEG = pop_saveset( EEG, 'filename',strcat(group1_files(i).name(1:end-4), '.set'), 'filepath',strcat(group1_dir, filesep, '_ica')); %保存数据
end
%% 使用ICLabel自动去除ICA成分
group1_dir = 'D:\demo'; % 此处路径需要设置为自己的文件目录
group1_dir2 = 'D:\demo\_ica';
group1_files = dir([group1_dir2, filesep, '*.set']); %filesep是\的意思
for i=1:length(group1_files)
subj_fn = group1_files(i).name;
EEG = pop_loadset('filename',strcat(subj_fn(1:end-4), '.set'), 'filepath', group1_dir2);
EEG = pop_iclabel(EEG, 'default');
EEG = pop_icflag(EEG, [NaN NaN;0.9 1;0.9 1;NaN NaN;NaN NaN;NaN NaN;NaN NaN]); % 标记伪迹成分。这里可以自定义设定阈值,依次为Brain, Muscle, Eye, Heart, Line Noise, Channel Noise, Other.
EEG = pop_subcomp( EEG, [], 0) %去除上述伪迹成分
EEG = pop_reref( EEG, []); %全脑平均重参考
EEG = eeg_checkset( EEG );
EEG = pop_saveset( EEG, 'filename',strcat(group1_files(i).name(1:end-4), '.set'), 'filepath',strcat(group1_dir, filesep, '_rm_ica'));
end
(1)File→Import data
以插件自带的.vhdr格式文件为例

(2)File→load existing data(导入EEGLAB处理后的数据文件,文件格式为.set)
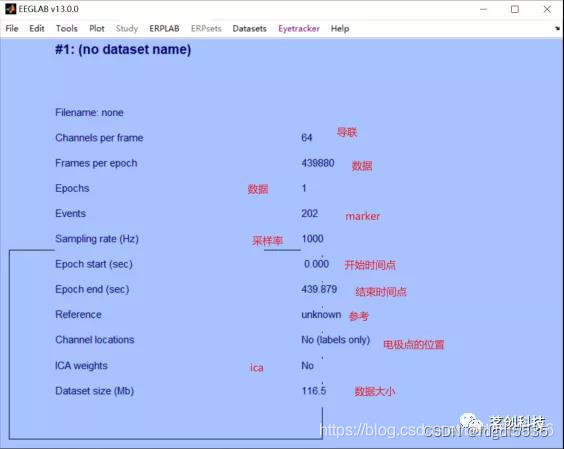
输入 >> EEG.history,可以看到代码实现过程
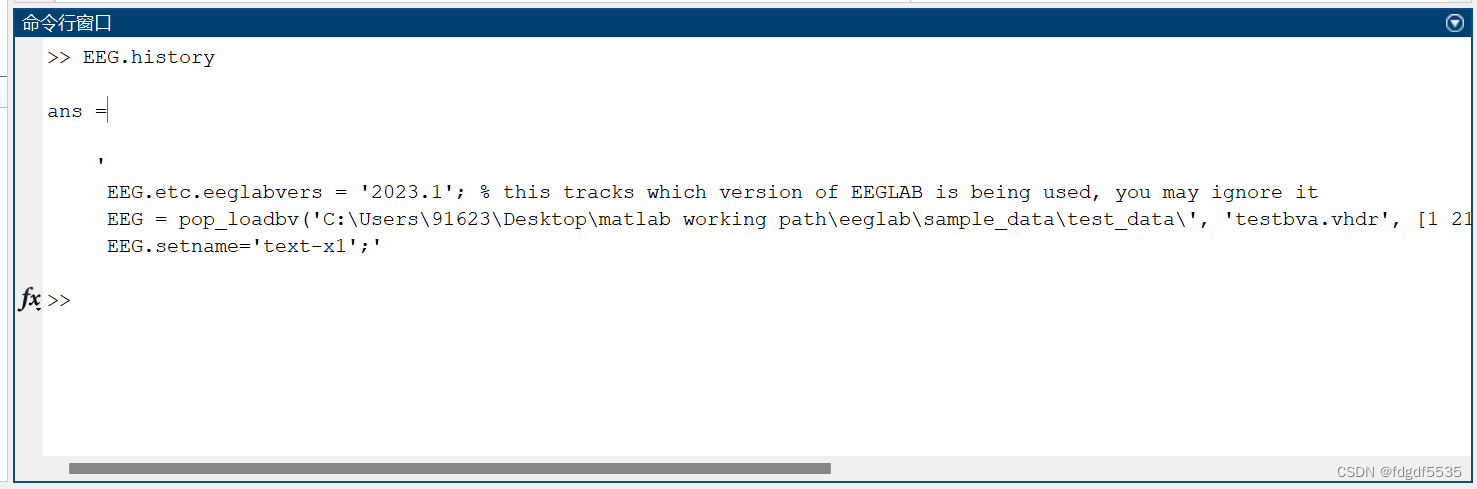
EEG.history
ans =
'
EEG.etc.eeglabvers = '2023.1'; % this tracks which version of EEGLAB is being used, you may ignore it
EEG = pop_loadbv('C:\Users\91623\Desktop\matlab working path\eeglab\sample_data\test_data\', 'testbva.vhdr', [1 2112], [1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32]);
EEG.setname='text-x1';'
想代码运行,输入
EEG = pop_loadbv('C:\Users\91623\Desktop\matlab working path\eeglab\sample_data\test_data', 'testbva.vhdr', [1 2112], [1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32]);

输入回车之后
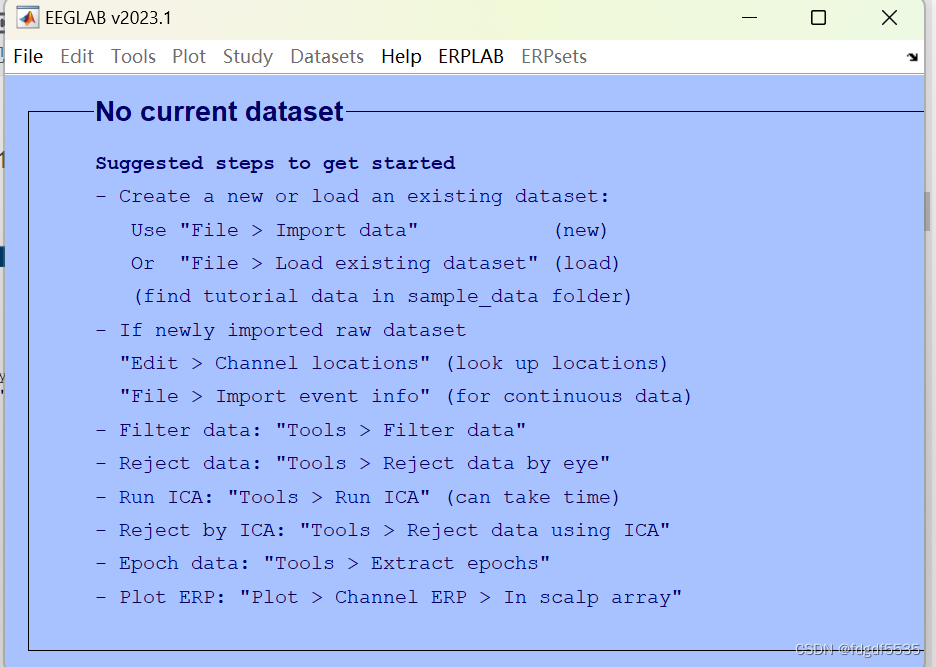
页面未更新
输入eeglab redraw;后页面更新

输入代码
EEG = pop_loadbv('C:\Users\91623\Desktop\matlab working path\eeglab\sample_data\test_data', 'testbva.vhdr', [1 2112], [1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32]);
运行过程如下:
pop_loadbv(): reading header file
Done.
pop_loadbv(): reading EEG data
pop_loadbv(): scaling EEG data
pop_loadbv(): reading marker file
Done
pop_loadbv():读取头文件
完成。
pop_loadbv():读取脑电图数据
pop_loadbv():缩放脑电图数据
pop_loadbv():读取标记文件
完成
第一步 UI界面和代码处理过程完成。
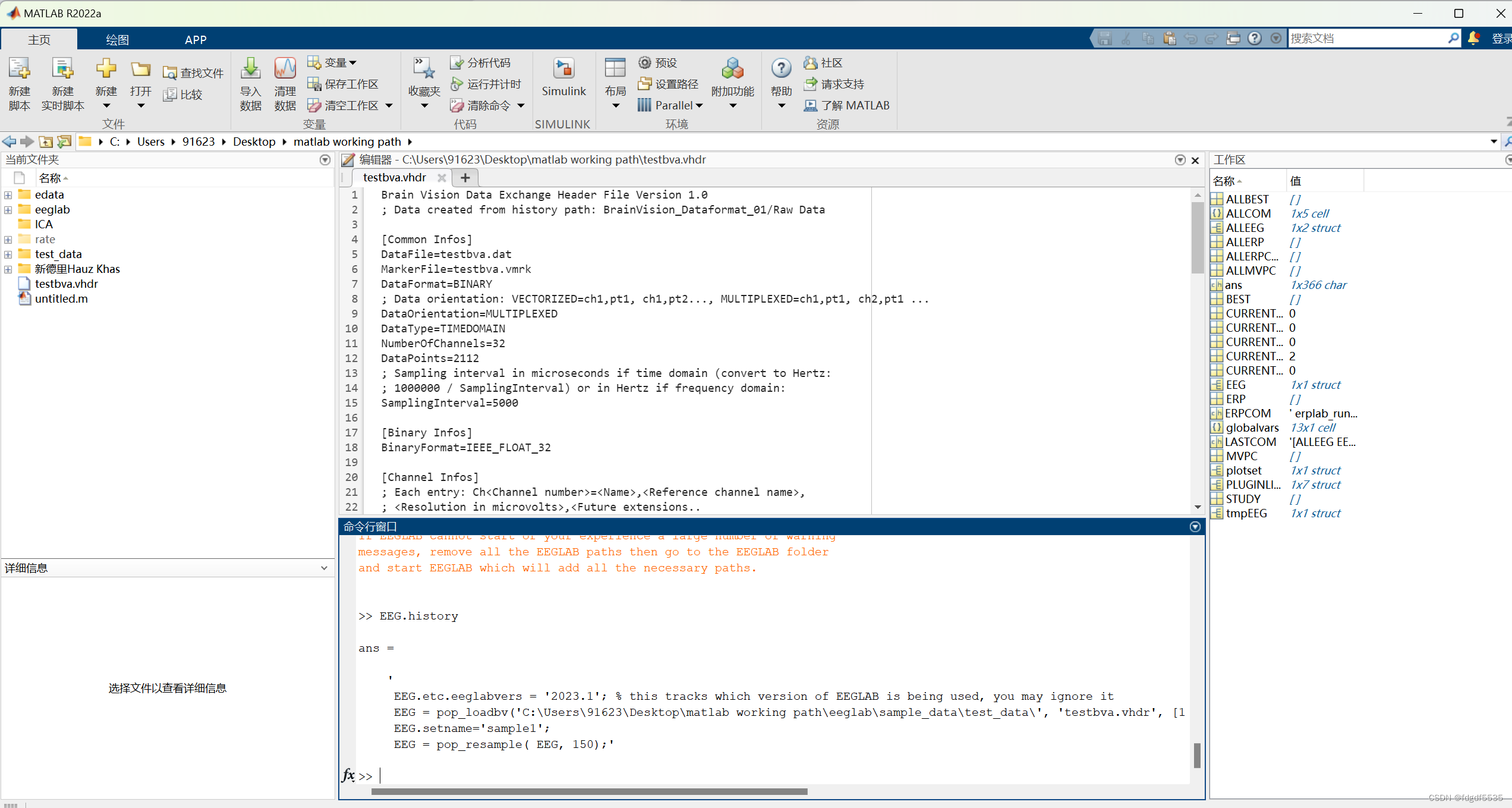
2.(Channel locations)电极定位+降采样率
Edit→Channel locations,如果你的脑电数据中包括了电极分布文件就会显示各电极的位置信息。
操作截图如下:

再点击Plot-2D画出电极分布图。

降采样率
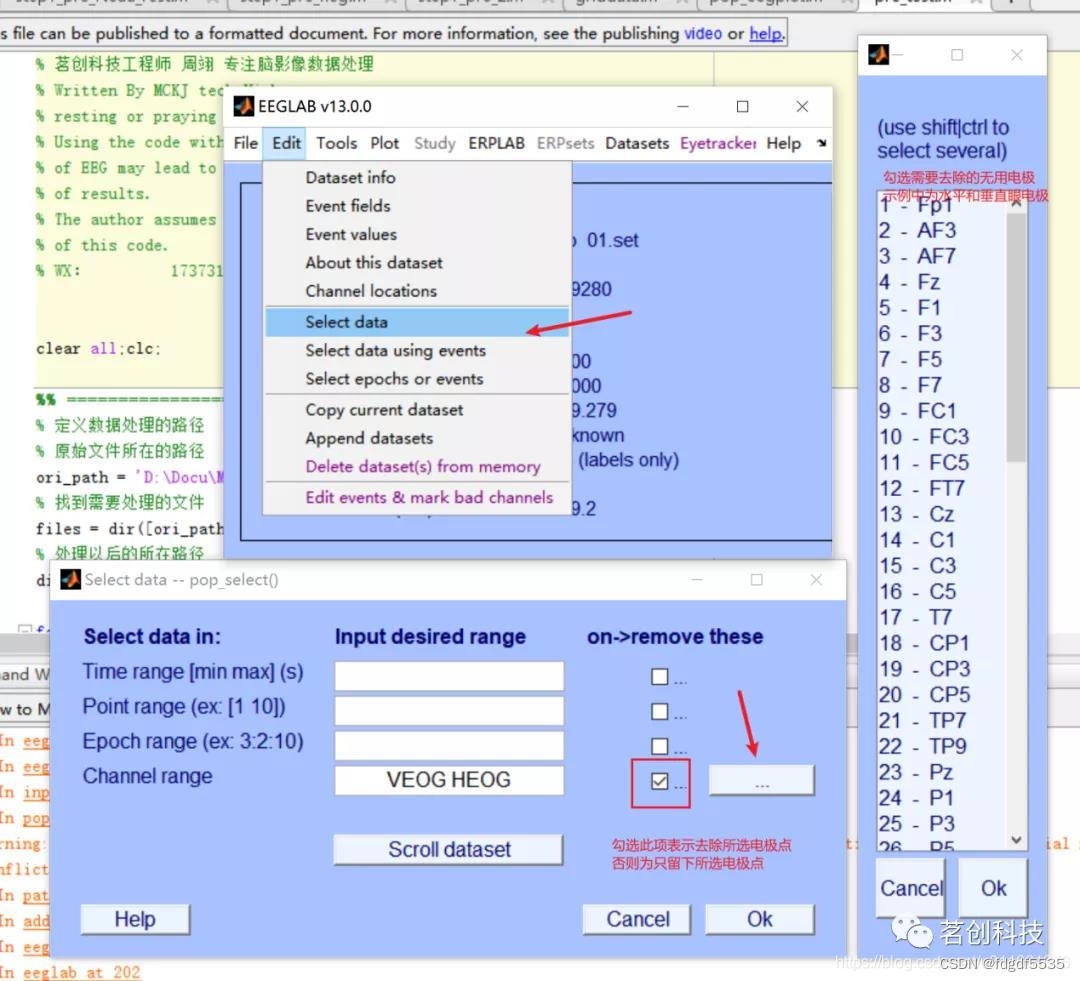
3.(Select data)剔除无用电极
Edit→Select data
无用电极指的是在整个脑电信号处理的过程(包括画地形图)中没有用的电极,一般来说活动电极是没用的(做参考和特殊用途的除外) 。如果通道全部保留可以跳过此步。
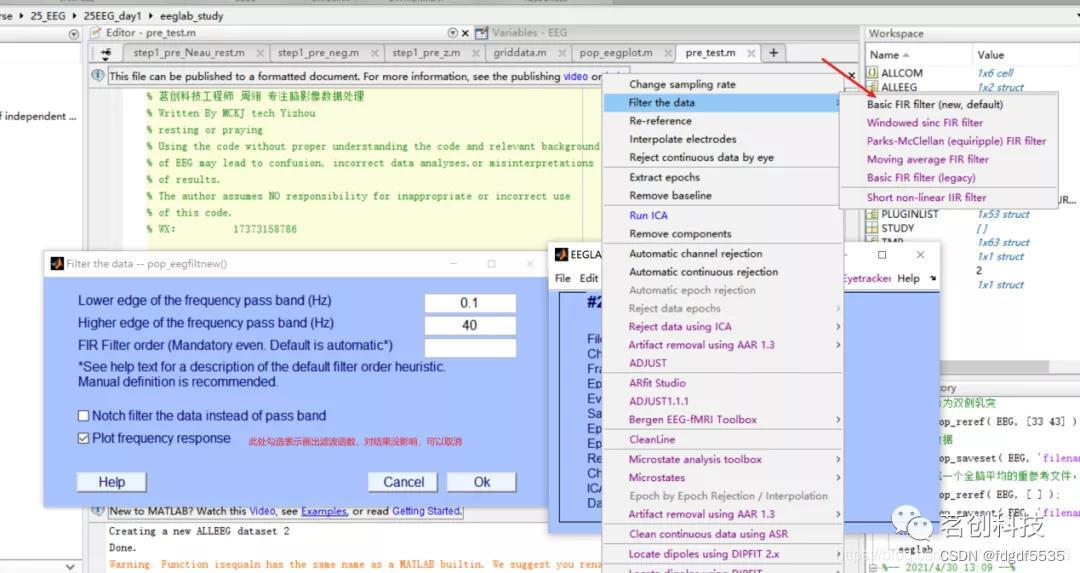
4.(filter the data)滤波
Tools→Filter the data→Basic FIR filter→(1Hz Lower Edge of the frequency pass band)→Overwrite it in memory
Tools→Filter the data→Basic FIR filter→(30Hz Higher Edge of the frequency pass band)→Overwrite it in memory
几种常见的滤波方式
高通滤波:设置一个下限,滤除这个下限以下的噪声,比如我们设置一个0.1Hz
低通滤波:设置一个上限,滤除这个上限以上的噪声,比如我们设置一个40Hz
带通滤波:同时设置上下限,通过这个上下限之间的信号,比如0.1~40Hz
凹陷滤波:设置一个范围,把这个范围以内的噪声直接去掉,比如常见的就是48~52Hz
ERP常见的滤波范围一般是0.1~40Hz,也是本例中采用的滤波范围,需要注意,越低的高通滤波下限,则运算量越大
若需要做时频或者频域,则可以考虑把滤波范围扩展到0.1~70Hz,或者0.5~70Hz,甚至0.5~100Hz,简单地说就是当涉及到频域信息的时候,就需要更高的低通滤波,以囊括更多的高频信息
本例中带通滤波的操作:
补充:凹陷滤波(消除工频干扰)
通常0.1~40Hz带通滤波后并不需要进行50Hz凹陷滤波。这在更宽的滤波范围中是必需的操作。
当然带通滤波也不是除了频段外的频率成份完成被消除,为了实验数据更好可以做50hz陷波滤波。
带通滤波40hz低通是为了去除波形中的毛刺,0.1hz高通是为了使波形更平稳。

关于凹陷滤波的范围选取,是49~51Hz,或是48~52Hz的选取,可以持续关注我们的更新。
5.(Extract epochs and Remove baseline)分段和基线校正
Tools右Extract epochs, 弹出如下窗口
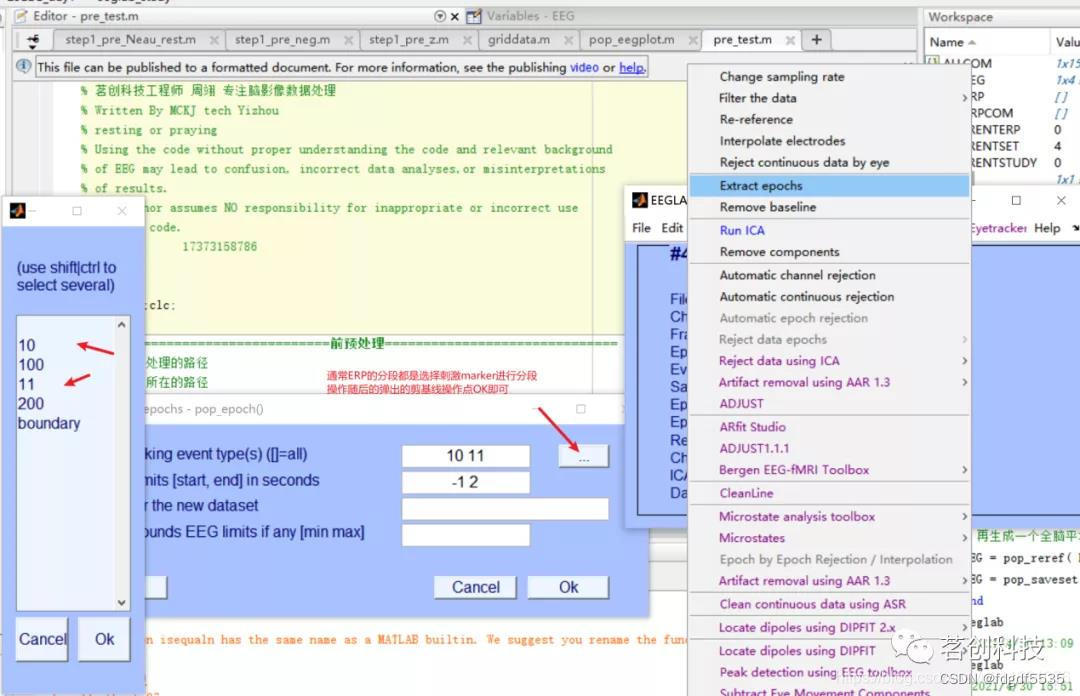
在这里,我们不需要把每个epoch 的limit 进行更改。这里每个epoch 时间长度为3s。
6.Artifact rejection (bad channel and epoch) (剔除坏段、插值坏导)
剔除坏段就是把表现不好的trail 直接去掉,但是ERP分析希望是trail多一些好。尽量不要剔除坏段。
Plot→Channel data scroll→选中某坏段点击reject
剔除坏段不得超过总trail数的10%
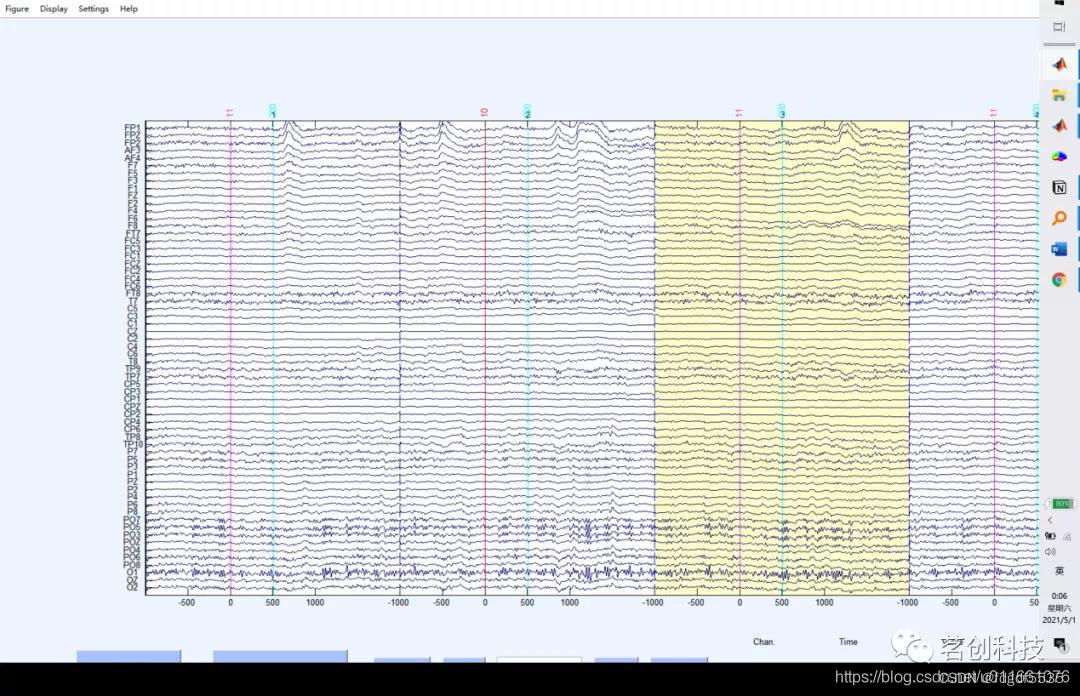
插值坏导就是,因为EEG信号空间分辨率低,每一个通道应该和周围通道的输出相似,所以说可以用周围的几个通道的输出来代替某个表现不佳的通道。当然这是对应通道较多的脑电设备,如果通道较少建议更换电极,调整电极接触头皮的松紧度,而不是用插值坏导。再或者通过先验知识,用一个大致相同的通道来代替。
第一种方法是代码操作:
EEG.data(a,:,:)=EEG.data([b,c,d],:,:)。
其中a代表坏掉的电极点数值,b c d 代表要进行插值平均的电极点数值。

例如:EEG.data(17,:,:)=EEG.data([8,18,26,16],:,:)
第二种方法是画板操作:
第二种方法是面板操作,用eeglab的默认算法进行

7.(Independent component analysis, ICA)独立成分分析
研究人员提出还有一种更好的选择,就是将ICA方法应用于多通道EEG记录,并通过消除人为因素对头皮传感器的影响,从EEG记录中删除各种伪影。研究结果表明,ICA可以有效地检测,分离和消除EEG记录中的各种伪迹,其结果与使用基于回归或基于PCA的方法获得的结果相比更具有优势。
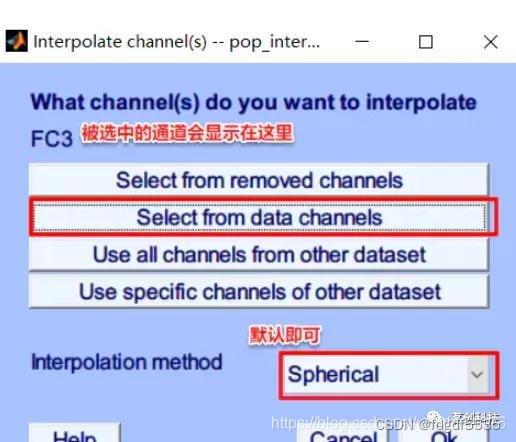
Tools→RUN ICA (插值坏导后用到pca)
脑电是由源信号和噪声混合而成的,如果我们能将源信号和噪声源分开,再将源信号重构即可达到脑电信号去噪的效果。ICA就是得到构成脑电信号的所有的源。
一般源的个数要小于通道的个数。使用插值坏导需用到pca,最大成分为总电极导数减去插值坏导数。
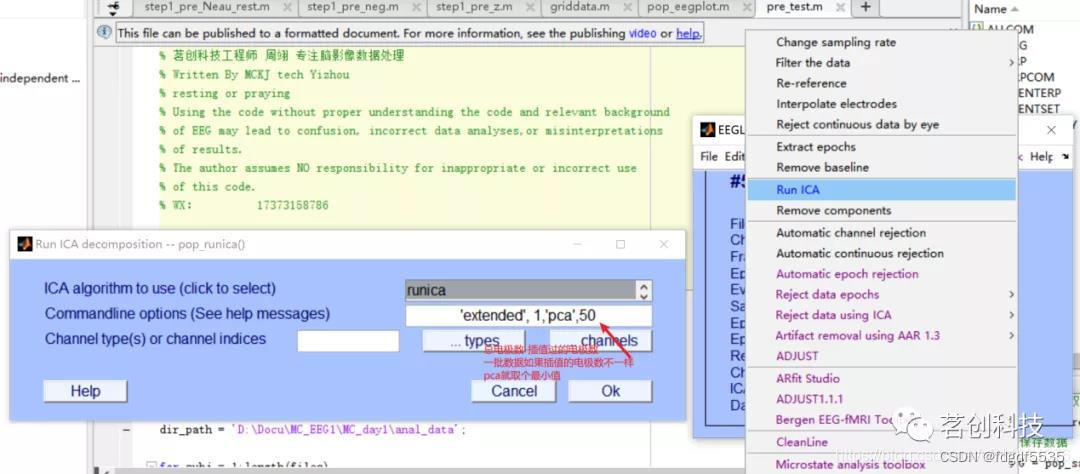
接下来是茶歇时间,依据电脑性能的不同可能会有10~30分钟
8.(Remove components)剔除伪迹成分
识别标记噪声成份
Tools→Reject data using ICA→Reject component by map
这些源会按顺序排列,对脑电信号影响大的会排在前面,影响小的会排在后面
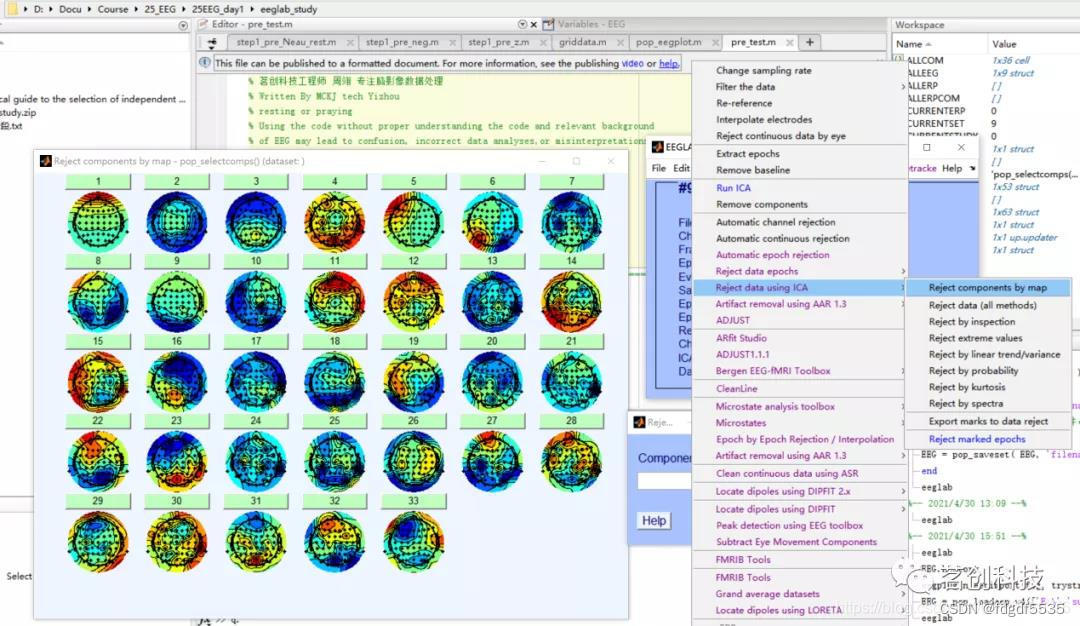
最常见的噪声
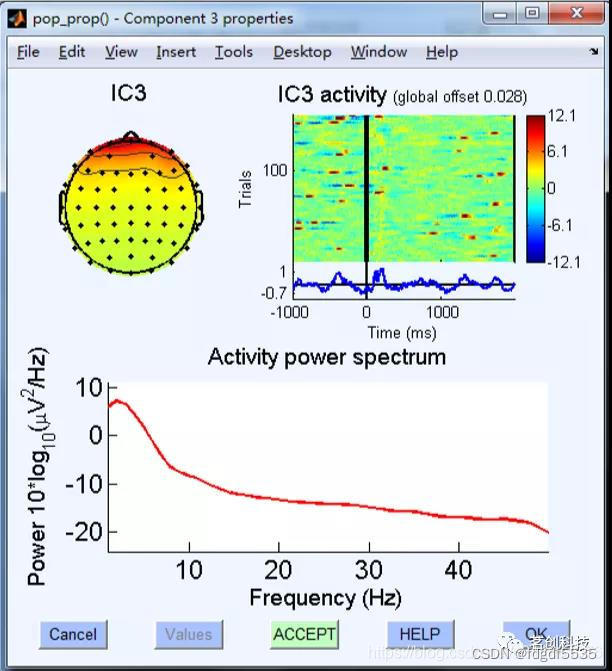
眨眼
1.前端分布(颜色深,大红大蓝)
2.小方块相对集中
3.成份排序靠前
4.随机分布
5.低频能量高(眨眼频率低)
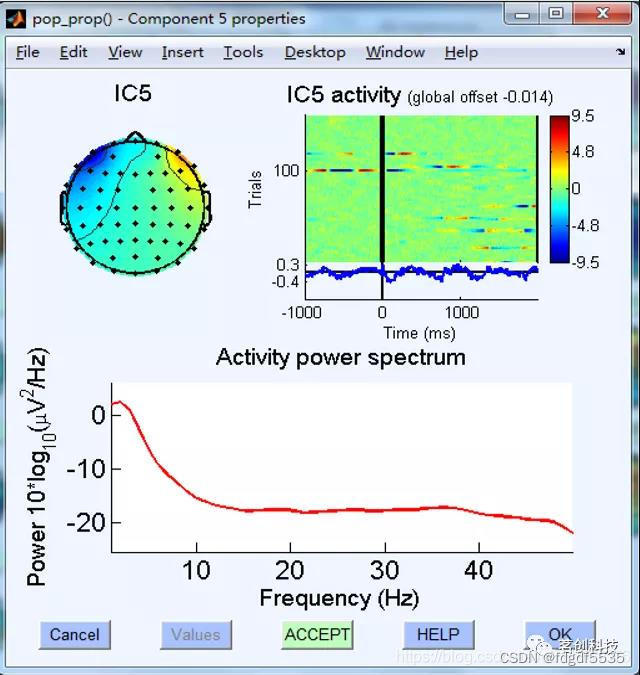
眼漂
前端两侧分布,红蓝相对(眼漂时左右不对称)
长条状,红蓝相间
一般成份排行前20,在眨眼之后
低频能量高(眼漂同样频率低)
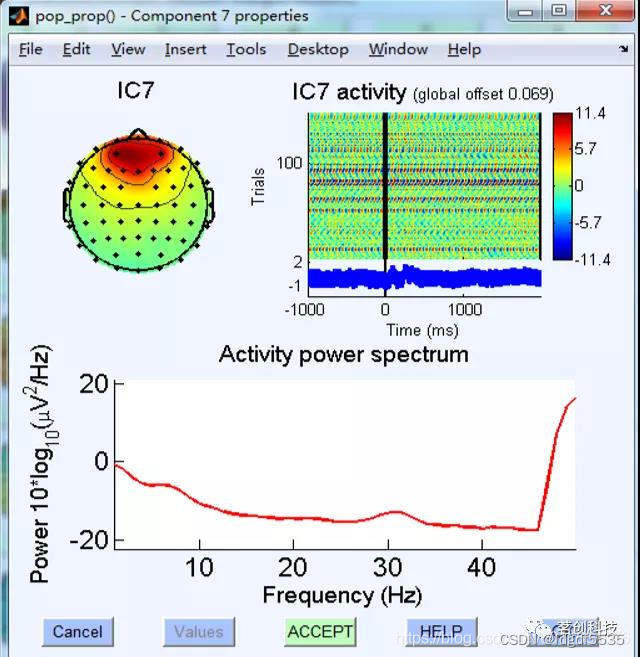
工频干扰
1.50Hz左右能量分布高
2.分布在地线周围

头动
1.四周能量分布
2.在单个trail有非常明显的漂移(plot data scroll)
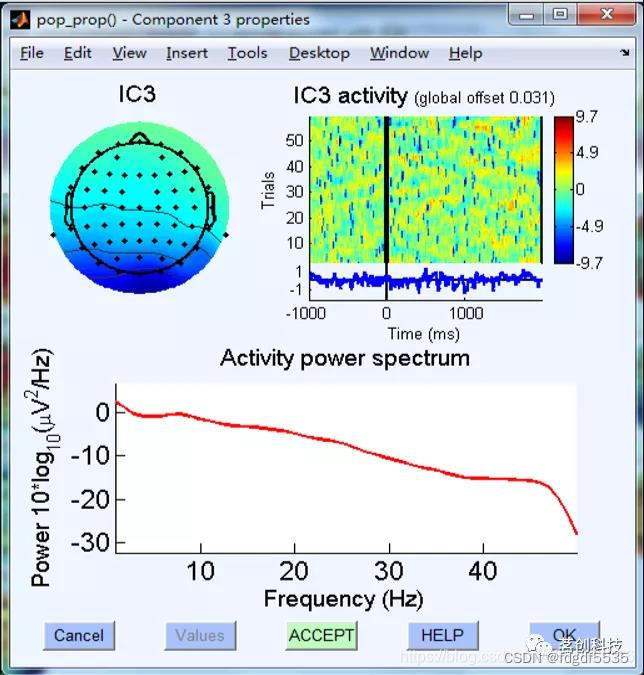
心电
1.后端分布
2.时间短促有力
(3)剔除噪声成份
Tools→Remove components
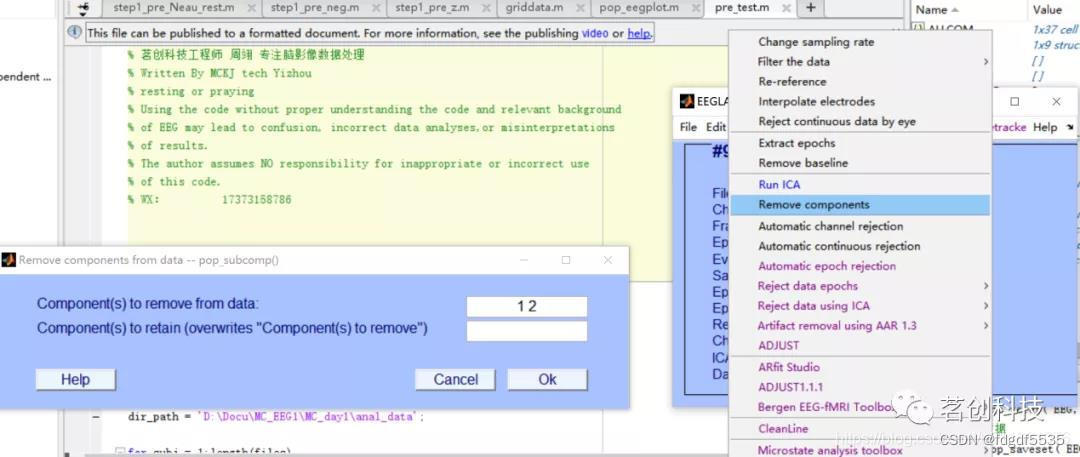
此处示例为剔除成分1和2
注:剔除ICA的原则是不确定的就不去,不要过去有数据洁癖
- (Reject extreme values)自动去除极端值
这一步的目的是自动去除一些在前面没有注意到的伪迹段,理论依据是生理信号都不会超过正负100微伏,所以卡一个阈值,去除超过正负100微伏,甚至更严格的会选取80微伏的数据段,操作方式如下

若这一步拒绝太多的伪迹段,则要考虑在回到前面的步骤剔除更多的伪迹成分
10.(Re-reference)重参考
重参考的主要目的是为了与前人的文献进行对比
做实验的时候一般会选择一个足够稳定的点作为参考点
分析数据的时候就会换个参考点,为了与前人的文献做对比
常见的参考方式包括
双侧乳突:大部分的ERP实验,TP9/TP10,M1/M2,A1/A2

图表 1双侧乳突
鼻尖参考:听觉实验可能会采用这个参考,现实就是鼻尖参考非常难实现
全脑平均:出现在全脑分析的时候,比如功能连接,比如溯源,需要预先删除掉不在头皮的电极点,还有一些坏电极
零参考:出现在全脑分析中,还有溯源分析中,主要北师大的人在用,需要使用独立的插件实现,笔者实测发现结果波形与全脑平均参考并无显著的差别
为什么重参考要放在最后面:
1,采用的参考点质量如果不好,可以及时发现,否则若在一开始就进行了重参考,就看不到参考点的数据质量
2,如果参考点只是有一些问题,这个噪声可以去除,能够在重参考之前及时改进数据质量
3,如果后期需要转其它的重参考,会更加的方便,而不需要重做预处理
关于参考点的一些tips:
1,双侧乳突是不能插值的,因为采集的数据不是同类型的,正常电极点采集的是头皮的信号,而乳突采集的是皮肤和颅骨信号
2,参考点的质量是非常重要的,一定要做实验的时候保证参考点的质量
3,不同参考点的选择,依赖对前人当前领域惯例
4,不同的参考方式,不能够对比数据分析的结果
重参考的操作方式:

03 结语
到此,预处理就算正式完成,但是还是需要重新打开数据观察数据状况,避免不必要的意外发生。
9.ICA
打开已保存的ICA数据
Load existing dataset 加载现有数据集

ICA过程
tools 工具>decompose data by ICA 用ICA分解数据> 'pca',29>保存ICA数据 save current data as > 查看轨迹图 channel spectra and maps 信道频谱和映射

’pca‘,后的数字判断根据 channels per frame 的 数据减去插值坏导的数(删去的数),如上27=28-1

10.移除伪迹
tools>inspect/label compenents by maps
版权归原作者 fdgdf5535 所有, 如有侵权,请联系我们删除。