
第1章 实验基本信息
1.1 实验目的
- 理解程序优化的10个维度
- 熟练利用工具进行程序的性能评价、瓶颈定位
- 掌握多种程序性能优化的方法
- 熟练应用软件、硬件等底层技术优化程序性能
1.2 实验环境与工具
1.2.1 硬件环境
X64 CPU;2GHz;2G RAM;256GHD Disk 以上
1.2.2 软件环境
Windows7/10 64位以上;VirtualBox/Vmware 11以上;Ubuntu 16.04 LTS 64位/优麒麟 64位 以上;1.2.3 开发X64 CPU;2GHz;2G RAM;256GHD Disk 以上
1.2.3 开发工具
Visual Studio 2010 64位以上;CodeBlocks 64位;vi/vim/gedit+gcc
1.3 实验预习
- 上实验课前,必须认真预习实验指导书
- 了解实验的目的、实验环境与软硬件工具、实验操作步骤,复习与实验有关的理论知识。
- 请写出程序优化的十个维度
- 如何编写面向编译器、CPU、存储器友好的程序。
- 性能测试方法:time、RDTSC、clock
性能测试准确性的文献查找:流水线、超线程、超标量、向量、多核、GPU、多级CACHE、编译优化Ox、多进程、多线程等多种因素对程序性能的综合影响。
第二章 实验预习
2.1 程序优化的十大方法
- 优化性能(更快)
- 减少空间占用,减少运行内存(更省)
- 美化UI界面(更美)
- 更加正确
- 增加程序可靠性
- 增加可移植性
- 有更强大功能
- 使用更方便
- 更加符合编程规范和接口规范
- 更加易懂,加注释、模块化
2.2性能优化的方法概述

2.3 Linux下性能测试的方法

2.4 Windows下性能测试的方法

**第3章 **性能优化的方法
3.1 逐条论述性能优化方法名称、原理、实现方案
一般有用的优化
原理:
通过减少重复运算的低效效代码以及一部分死代码来减少程序运行时间来提高性能。
实现方案:
代码移动:减少计算执行的频率,如果它总是产生相同的结果,将代码从循环中移出。
复杂指令简化:移位、加,替代乘法/除法,实际效果依赖于机器,取决于乘法或除法指令的成本。
公共子表达式:重用表达式的一部分,GCC 使用 –O1 选项实现这个优化。
面向编译器的优化:障碍
原理:
编译器不检查存储器别名使用情况,如果程序中有别名使用,两个不同的内存引用很容易指向同一个位置导致程序出现错误。
实现方案:
函数副作用:函数每次调用都可能改变全局变量或者状态,这需要我们合理的在函数内修改全局变量的值。
内存别名:两个不同的内存引用指向相同的位置,编译器不知道函数何时被调用,不知道内存会不会被别的函数修改,因此对函数进行内存弱优化。这要求我们养成引入局部变量的习惯。
面向超标量CPU的优化
原理:
超标量试图在一个周期取出多条指令并行执行,通过内置多条流水线来同时执行多个处理,其实质是以空间换取时间。
实现方案:
流水线、超线程、多功能部件、分支预测投机执行、乱序执行、多核
面向向量CPU的优化
原理:
cpu有向量寄存器,指令集内有向量计算的指令,使用向量计算可以加速较大数据的计算。
实现方案:
MMX/SSE/AVR
CMOVxx等指令
原理:
test/cmp+jxx指令是使用控制的条件转移,这种方法要先测试数据值,再根据测试结果改变控制流或者数据流。而采用CMOVxx等指令是使用数据的条件转移,当可行时,可以直接用一条简单的条件传送指令实现,比较高效。
实现方案:
使用CMOVxx指令代替test/cmp+jxx
嵌入式汇编
原理:
在不改变程序功能的情况下,通过修改原来程序的算法、结构,并利用软件开发工具对程序进行改进,使修改后的程序运行速度更高或代码尺寸更小。
实现方案:
嵌入式汇编程序优化可分为运行速度优化和代码尺寸优化。运行速度优化是指在充分掌握软硬件特性的基础上,通过应用程序结构调整等手段来缩短完成指定任务所需的运行时间;代码尺寸优化则是指应用程序在能够正确实现所需功能的前提下,尽可能减小程序的代码量。
面向编译器的优化
原理:
指定优化级别,获取每个优化标识所启用的优化选项,根据不同的优化选项进行不同程度的优化。
实现方案:
利用Ox:0 1 2 3 g等优化模式不同的优化模式,对内存和速度等进行不同程度的优化
面向存储器的优化
原理:
通过合理划分得到合适的工作集使得工作集可以尽可能地由高速缓存L1,L2,L3来缓存以提高读吞吐量,从而优化程序性能。
实现方案:
Cache无处不在:重新排列提高空间局部性,分块提高时间局部性。通过优化减少cache miss。
内存作为逻辑磁盘
原理:
在计算机这个系统中,高速小容量的内存与低速高容量的磁盘进行协同作业。计算机在运行程序时,必须将磁盘中的内容加载到内存中,不加载是不能运行程序的。
实现方案:
当内存足够大时,使用大量内存充当磁盘缓存。
多进程优化
原理:
使用多线程可以使得CPU的多个核心同时处理任务,提升程序的并发执行性能,提高计算资源利用率。
实现方案:
fork,每个进程负责各自的工作任务,通过mmap共享内存或磁盘等进行交互。
文件访问优化
带Cache的文件访问
并行计算
多线程优化
网络计算优化
GPU编程、算法优化
利用gpu编程
超级计算
利用性能更强的超级计算机
*第4*章 **性能优化实践
4**.1 **原始程序及说明
在此将说明以下程序的功能、流程,分析程序可能瓶颈
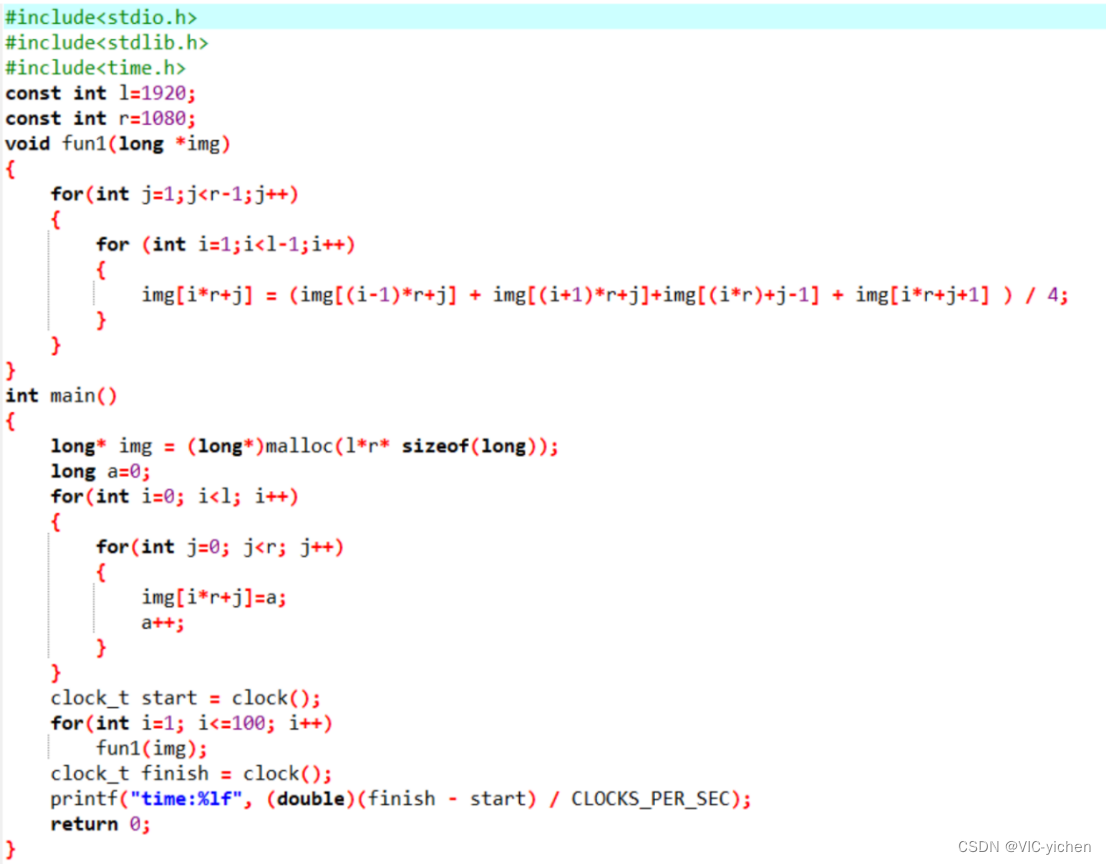
功能:图像处理程序实现图像的平滑并且输出平滑100次所需的时间。忽略边缘数据,平滑一百次是为了放大程序执行时间,更明显地比较之后的优化。
流程:先是main函数中,颜色值从0依行列递增给imp[i][j]赋初值,获取初始时间,然后调用100次平滑算法fun1(img),获取最终时间,最后输出用时。
程序可能瓶颈:循环先列后行不符合计算机先寻行再找列的方式,可能会大大增加花费的时间,算法中多次用到除法,可能会增加时间。
4**.2 **优化后的程序及说明
1**.面向Cache**进行优化
查询linux下的Cache L1 L2 L3的大小。按其高速缓存大小来分块,增加缓存命中概率。

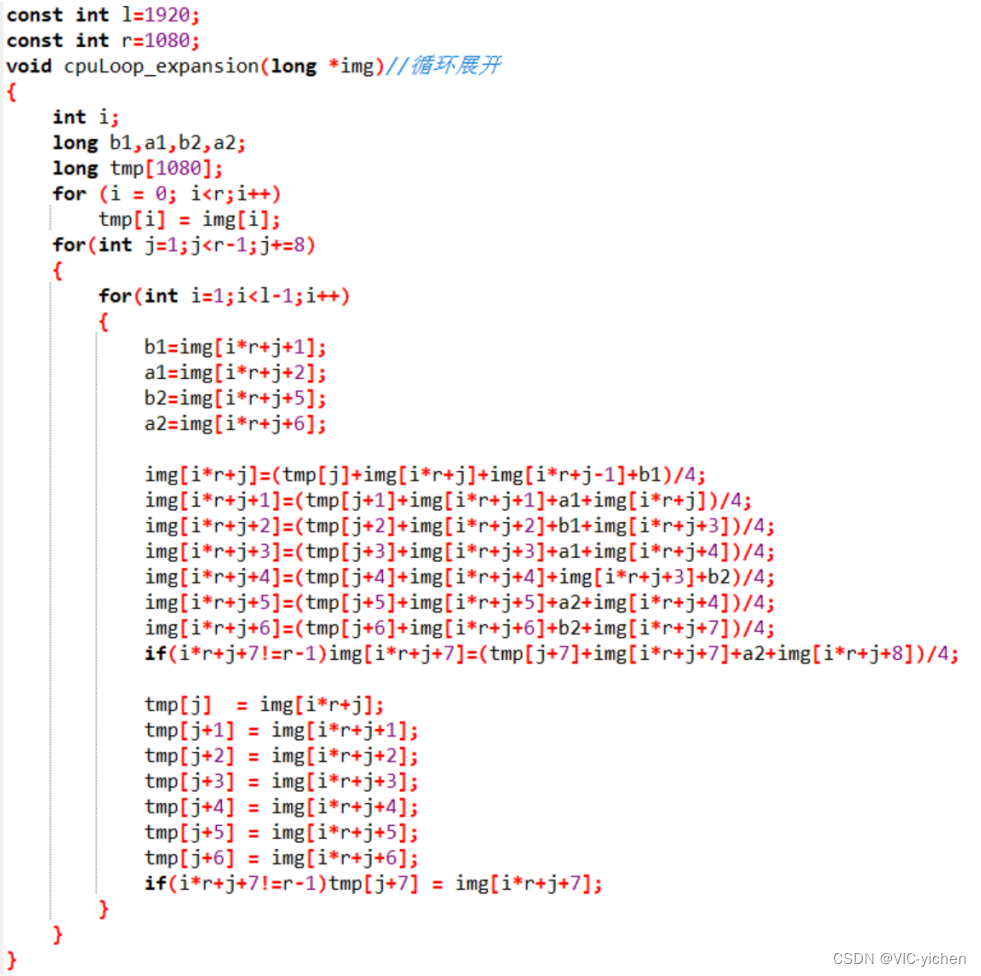
2**.面向CPU进行优化之**循环展开
在循环中,每次使用更多变量参与运算,提高流水线的效率,所以程序中用数组tmp[]来存储当前要计算的点的行-1的那个点,在循环中设置步长为8,增加a1,a2,b1,a2四个变量参与运算。
3**.**流水线优化
进行代码移动后,循环内计算时间隔两个单位进行平滑处理,因为间隔两个单位的数组元素进行平滑处理时数据上没有相互依赖,可以让流水线满载。

**4.代码移动,利用空间局部性 **
将平滑算法的双重循环,改为行优先,一行一行的扫描。
原理:因为C语言以行优先顺序存储数组,改成行优先的循环,这样内循环就有步长为1的访问模式,缓存命中的概率大大增加。原来是以列优先的循环,是一列一列的扫描数组,long imp[1920][1080]很明显这个数组很大,最糟糕的情况是每次都缓存不命中。

5.面向编译器的优化
利用o1,o2,o3对代码进行优化,牺牲编译后文件可读性,换取高速的运行程序。

4**.3 **优化前后的性能测试
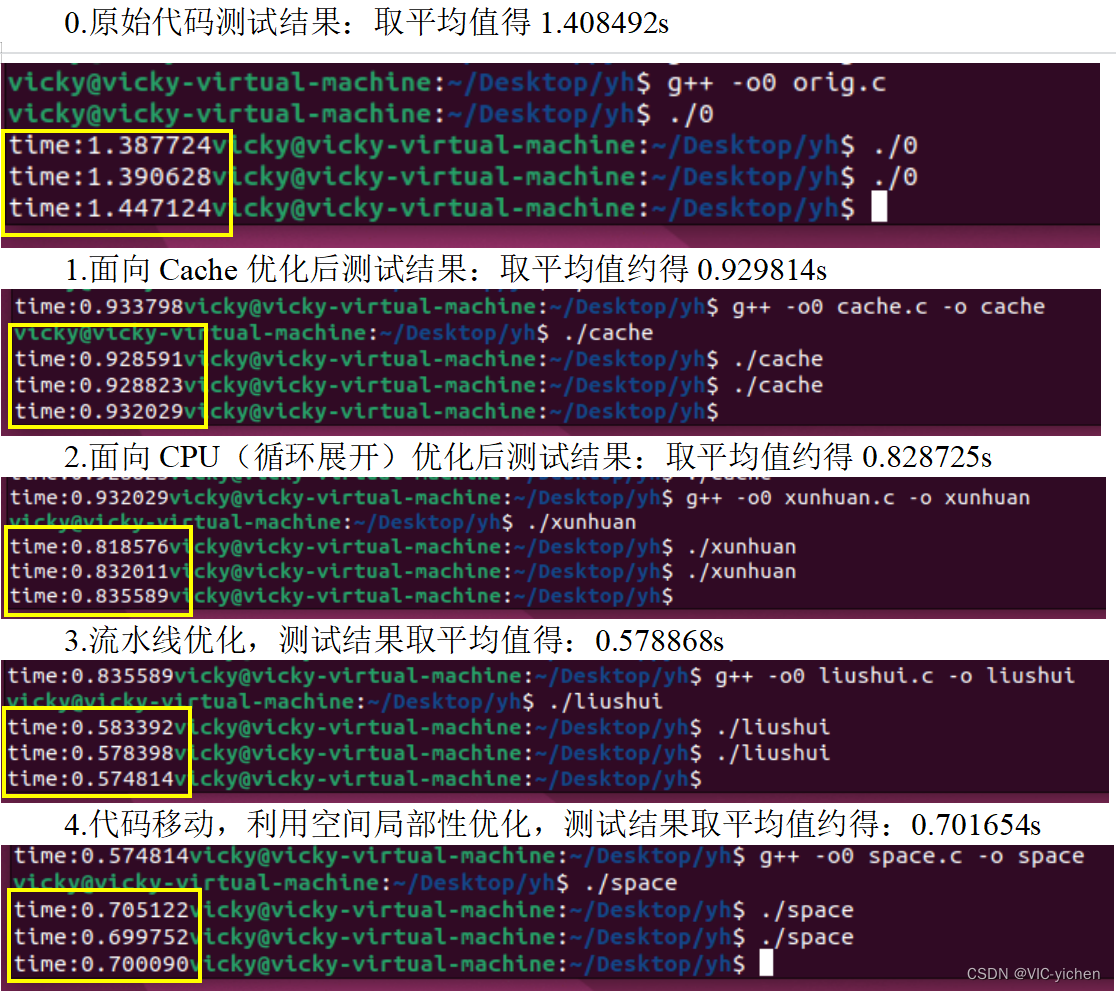
测试方法:
使用C语言中的库函数clock(),测量平滑算法开始到结束的时间,对各个优化方法的时间进行比较。
测试结果:
最终统计:
方法
用时
原始
1.408492****s
C****ache
0.929814****s
循环展开
0.828725s
代码移动+流水线优化
0****.578868****s
代码移动(空间局部性)
0****.701654****s
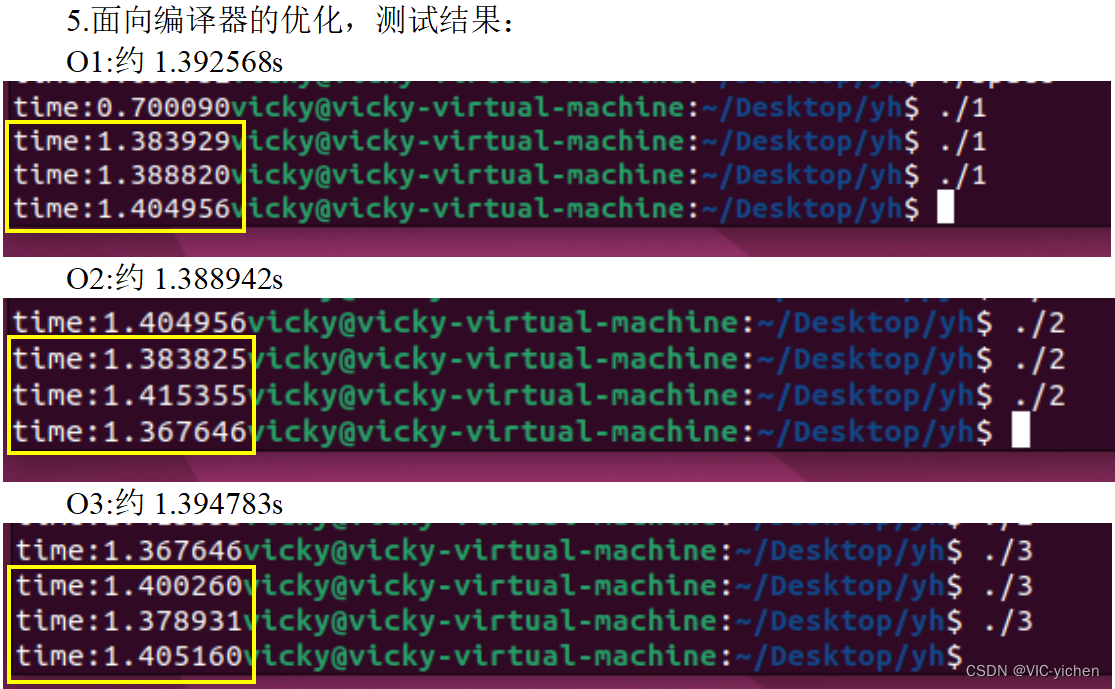
O****1
1****.392568****s
O****2
1****.388942****s
O****3
1.394783****s
4**.4 **结合计算机的硬件参数,分析优化后程序的各个参数选择依据
Cache分块依据
如图所示,查询Linux下Cache的信息可知:
L1(数据)大小为32k,64组,每组8行,每行64个字节;
L2大小为512K,1024组,每组8行,每行64个字节;
L3大小为16M,16384组,每组16行,每行64个字节。
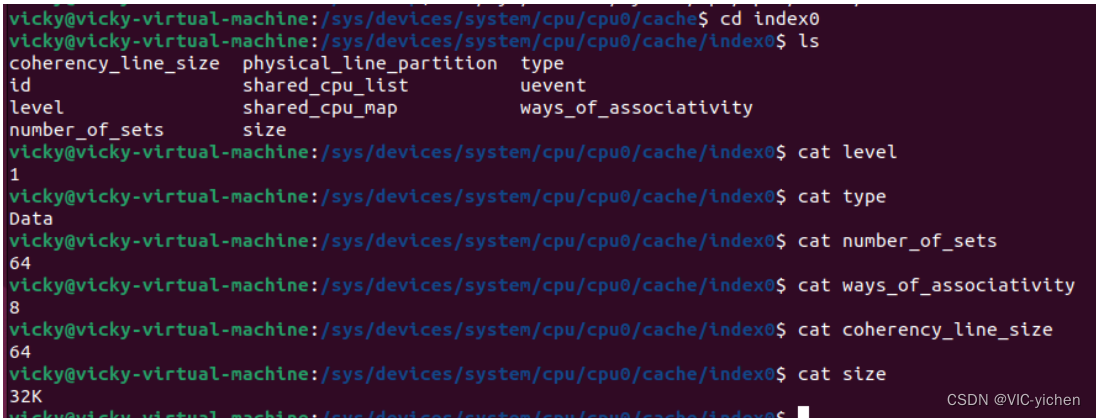
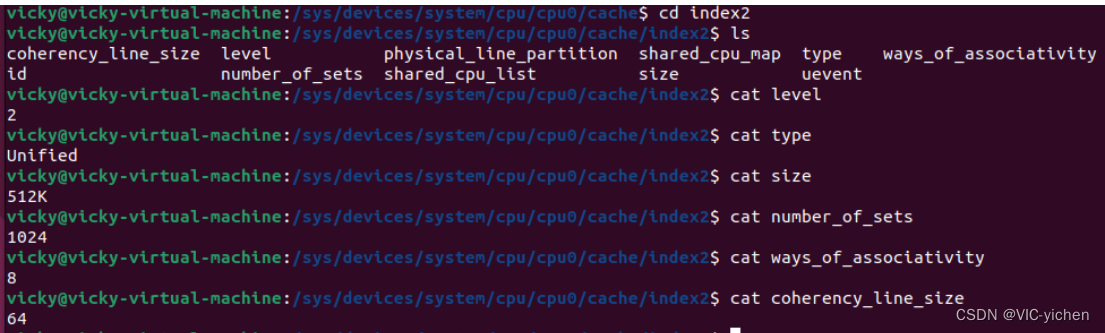

获得L1,L2,L3的信息后,结合代码数组img[1920][1080]分析。
L3分块:
数组long img[1920][1080]大小=192010808/1024/1024=15.82MB<16MB=L3所以,简单来看,L3可以存放整个数组,所以L3无需分块。
L2分块:
因为数组15.82MB>>512k=L2,所以我们可以在这里进行分块,15.82近似看成16MB, 16*1024/512=32,所以我们可以把数组按行分成32块。
L1分块:
因为每一行有10288个字节,10288/1024=8.03<32K,所以L1不用按列分。
对循环展开和流水线优化都是为了尽量装满流水线,减少排队时间,提高工作效率。
代码移动,将循环改成以符合C语言存储的按行优先为外层循环,其原理其实也是因为Cache,我们尽可能的提高缓存命中的概率。
4**.5 **还可以采取的进一步的优化方案
用位运算代替除法运算,去掉冗余运算
代码内循环中多次用到ir,ir+1,i*r-1,可以用变量a,b,c存储下来,而不是一遍一遍的计算。同时/4操作也可以用更快的>>2右移2位替换。

在windows下还可以用avx指令集进行优化
使用fock()创建子进程,使用多线程,提高程序的并发执行能力
将所有得优化进行整合,进一步优化
第5章 总结
5.1 实验收获
进一步了解了程序优化的知识,从理论到实际应用中,我发现一些理论上的优化并不适用所有的代码,比如位运算代替除法,其实在很小规模是看不出区别,还有O2,O3的优化对于一些代码来说也很难优化,比如这个双重循环,优化就收效渐微了。还学习了常用的程序性能评价工具
5.2 对本次实验内容的建议
有一些优化方法并不具体,可以增加一些例子。
参考文献
[1] 林来兴. 空间控制技术[M]. 北京:中国宇航出版社,1992:25-42.
[2] 辛希孟. 信息技术与信息服务国际研讨会论文集:A集[C]. 北京:中国科学出版社,1999.
[3] 赵耀东. 新时代的工业工程师[M/OL]. 台北:天下文化出版社,1998 [1998-09-26]. http://www.ie.nthu.edu.tw/info/ie.newie.htm(Big5).
[4] 谌颖. 空间交会控制理论与方法研究[D]. 哈尔滨:哈尔滨工业大学,1992:8-13.
[5] KANAMORI H. Shaking Without Quaking[J]. Science,1998,279(5359):2063-2064.
[6] CHRISTINE M. Plant Physiology: Plant Biology in the Genome Era[J/OL]. Science,1998,281:331-332[1998-09-23]. http://www.sciencemag.org/cgi/ collection/anatmorp.
版权归原作者 VIC-yichen 所有, 如有侵权,请联系我们删除。