

图神经网络(GNNs)已经成为学习图数据的标准工具箱。gnn能够推动不同领域的高影响问题的改进,如内容推荐或药物发现。与图像等其他类型的数据不同,从图形数据中学习需要特定的方法。正如Michael Bronstein所定义的:
这些方法基于图形上的某种形式的消息传递,允许不同的节点交换信息。
为了完成图上的特定任务(节点分类,链接预测等),GNN层通过所谓的递归邻域扩散(或消息传递)来计算节点和边缘表示。根据此原理,每个图节点从其邻居接收并聚合特征以表示局部图结构:不同类型的GNN层执行各种聚合策略。
GNN层的最简单公式(例如图卷积网络(GCN)或GraphSage)执行各向同性聚合,其中每个邻居均做出同等贡献以更新中心节点的表示形式。这篇文章介绍了一个专门用于图注意力网络(GAT)分析的微型系列文章(共2条),该系列定义了递归邻域扩散中的各向异性操作。利用各向异性范式,通过注意力机制提高了学习能力,注意力机制为每个邻居的贡献赋予了不同的重要性。
GCN vs GAT -数学基础
这个热身是基于Deep Graph Library网站的GAT细节。
在理解GAT层的行为之前,让我们回顾一下GCN层执行的聚合背后的数学运算。

N是节点i的单跳邻居的集合,也可以通过添加一个自循环将该节点包含在邻居中。
c是基于图结构的归一化常数,定义了各向同性平均计算。
σ是一个激活函数,它在变换中引入了非线性。
W为特征变换采用的可学习参数的权矩阵。
GAT层扩展了GCN层的基本聚合功能,通过注意系数为每条边分配不同的重要性。

公式(1)是嵌入h_i的下层的线性变换,W是其可学习的权重矩阵。此转换有助于实现足够的表达能力,以将输入要素转换为高级且密集的特征。
公式(2)计算两个邻居之间的成对非标准化注意力得分。在这里,它首先连接两个节点的z嵌入,其中||表示串联。然后,采用这种串联的点积和可学习的权重向量a。最后,将LeakyReLU应用于点积的结果。注意分数表示消息传递框架中邻居节点的重要性。
公式(3)应用softmax来标准化每个节点进入边缘上的注意力得分。softmax将前一步的输出编码为概率分布。结果,在不同节点之间的注意力得分更具可比性。
公式(4)与GCN聚合类似(请参阅本节开头的公式)。来自邻居的嵌入被聚集在一起,并按照注意力得分进行缩放。此缩放过程的主要结果是从每个邻居节点获悉不同的贡献。
NumPy实现
第一步是准备成分(矩阵)来表示一个简单的图形,并执行线性变换。
print('\n\n----- One-hot vector representation of nodes. Shape(n,n)\n')
X = np.eye(5, 5)
n = X.shape[0]
np.random.shuffle(X)
print(X)
print('\n\n----- Embedding dimension\n')
emb = 3
print(emb)
print('\n\n----- Weight Matrix. Shape(emb, n)\n')
W = np.random.uniform(-np.sqrt(1. / emb), np.sqrt(1. / emb), (emb, n))
print(W)
print('\n\n----- Adjacency Matrix (undirected graph). Shape(n,n)\n')
A = np.random.randint(2, size=(n, n))
np.fill_diagonal(A, 1)
A = (A + A.T)
A[A > 1] = 1
print(A)
第一个矩阵定义了节点的一个热编码表示。然后,利用定义的嵌入维数定义一个权重矩阵。我突出显示了W的第3列向量,因为正该向量定义了节点1的更新表示形式(在第三位置初始化了一个1值)。我们可以执行线性变换,以从这些要素开始为节点特征实现足够的表达能力。此步骤旨在将(一次热编码)输入特征转换为低而密集的表示形式。
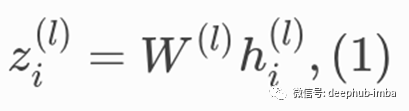
# equation (1)
print('\n\n----- Linear Transformation. Shape(n, emb)\n')
z1 = X.dot(W.T)
print(z1)
接下来的操作是为每个边缘引入自注意系数。我们将源节点的表示和目标节点的表示的表示连接起来。该邻接过程由邻接矩阵A启用,邻接矩阵A定义了图中所有节点之间的关系。

# equation (2) - First part
print('\n\n----- Concat hidden features to represent edges. Shape(len(emb.concat(emb)), number of edges)\n')
edge_coords = np.where(A==1)
h_src_nodes = z1[edge_coords[0]]
h_dst_nodes = z1[edge_coords[1]]
z2 = np.concatenate((h_src_nodes, h_dst_nodes), axis=1)
在上一个块中,我突出显示了代表与节点1连接的4个边缘的4行。每行的前3个元素定义节点1邻居的嵌入表示,而每行的其他3个元素定义节点1的嵌入。节点1本身(您会注意到,第一行编码一个自循环)。
完成此操作后,我们可以引入注意力系数,并将它们与边缘表示相乘,这是由串联过程产生的。最后,Leaky Relu函数应用于该产品的输出。
# equation (2) - Second part
print('\n\n----- Attention coefficients. Shape(1, len(emb.concat(emb)))\n')
att = np.random.rand(1, z2.shape[1])
print(att)
print('\n\n----- Edge representations combined with the attention coefficients. Shape(1, number of edges)\n')
z2_att = z2.dot(att.T)
print(z2_att)
print('\n\n----- Leaky Relu. Shape(1, number of edges)')
e = leaky_relu(z2_att)
print(e)
在此过程的最后,我们为图形的每个边缘获得了不同的分数。在上面的方框中,我强调了与第一条边相关的系数的演变。然后,为了使系数可以轻松地在不同节点之间进行比较,将softmax函数应用于每个目标节点的所有邻居的贡献。

# equation (3)
print('\n\n----- Edge scores as matrix. Shape(n,n)\n')
e_matr = np.zeros(A.shape)
e_matr[edge_coords[0], edge_coords[1]] = e.reshape(-1,)
print(e_matr)
print('\n\n----- For each node, normalize the edge (or neighbor) contributions using softmax\n')
alpha0 = softmax(e_matr[:,0][e_matr[:,0] != 0])
alpha1 = softmax(e_matr[:,1][e_matr[:,1] != 0])
alpha2 = softmax(e_matr[:,2][e_matr[:,2] != 0])
alpha3 = softmax(e_matr[:,3][e_matr[:,3] != 0])
alpha4 = softmax(e_matr[:,4][e_matr[:,4] != 0])
alpha = np.concatenate((alpha0, alpha1, alpha2, alpha3, alpha4))
print(alpha)
print('\n\n----- Normalized edge score matrix. Shape(n,n)\n')
A_scaled = np.zeros(A.shape)
A_scaled[edge_coords[0], edge_coords[1]] = alpha.reshape(-1,)
print(A_scaled)
为了解释定义归一化边缘得分的最后一个矩阵的含义,让我们回顾一下邻接矩阵的内容。
----- Adjacency Matrix (undirected graph). Shape(n,n)[[1 1 1 0 1]
[1 1 1 1 1]
[1 1 1 1 0]
[0 1 1 1 1]
[1 1 0 1 1]]
如您所见,我们没有使用1个值来定义边,而是重新缩放了每个邻居的贡献。最后一步是计算邻域聚合:将邻居的嵌入合并到目标节点中,并按注意力分数进行缩放。

# equation (4)
print('\n\nNeighborhood aggregation (GCN) scaled with attention scores (GAT). Shape(n, emb)\n')
ND_GAT = A_scaled.dot(z1)
print(ND_GAT)
下一步
在以后的文章中,我将描述多头GAT层背后的机制,并且我们将看到一些用于链接预测任务的应用程序。
以下代码提供了代码的运行版本。https://github.com/giuseppefutia/notebooks/blob/main/gnns/gat.ipynb
作者:Giuseppe Futia
原文地址:https://towardsdatascience.com/graph-attention-networks-under-the-hood-3bd70dc7a87
deephub翻译组