
Python中RabbitMQ的使用
文章目录
一、AMQP协议
参考深入理解AMQP协议
AMQP(Advanced Message Queuing Protocol,高级消息队列协议)是一个进程间传递异步消息的网络协议(两个对等节点的信息交换规则)。

1、工作过程
发布者(Publisher)发布消息(Message),经由交换机(Exchange);
交换机根据路由规则将收到的消息分发给与该交换机绑定的队列(Queue);
最后 AMQP 代理会将消息投递给订阅了此队列的消费者,或者消费者按照需求自行获取
2、细节问题
1、发布者、交换机、队列、消费者都可以有多个。同时因为 AMQP 是一个网络协议,所以这个过程中的发布者,消费者,消息代理可以分别存在于不同的设备上。
2、发布者发布消息时可以给消息指定各种消息属性(Message Meta-data)。有些属性有可能会被消息代理(Brokers)使用,然而其他的属性则是完全不透明的,它们只能被接收消息的应用所使用。
3、从安全角度考虑,网络是不可靠的,又或是消费者在处理消息的过程中意外挂掉,这样没有处理成功的消息就会丢失。基于此原因,AMQP 模块包含了一个消息确认(Message Acknowledgements)机制:当一个消息从队列中投递给消费者后,不会立即从队列中删除,直到它收到来自消费者的确认回执(Acknowledgement)后,才完全从队列中删除。
4、在某些情况下,例如当一个消息无法被成功路由时(无法从交换机分发到队列),消息或许会被返回给发布者并被丢弃。或者,如果消息代理执行了延期操作,消息会被放入一个所谓的死信队列中。此时,消息发布者可以选择某些参数来处理这些特殊情况。
3、Exchange交换机
交换机是用来发送消息的 AMQP 实体。
交换机拿到一个消息之后将它路由给一个或零个队列。
它使用哪种路由算法是由交换机类型和绑定(Bindings)规则所决定的。
AMQP 0-9-1 的代理提供了四种交换机:
交换机可以有两个状态:持久(durable)、暂存(transient)。
持久化的交换机会在消息代理(broker)重启后依旧存在,而暂存的交换机则不会(它们需要在代理再次上线后重新被声明)。
直连交换机:
如果我们以 Rotuing key=create 和 Rotuing key=confirm 发送消息时,这时消息只会被推送到 Queue2 队列中,其他 Routing Key 的消息将会被丢弃。
扇形交换机:
扇型交换机(funout exchange)将消息路由给绑定到它身上的所有队列,而不理会绑定的路由键。如果 N 个队列绑定到某个扇型交换机上,当有消息发送给此扇型交换机时,交换机会将消息的拷贝分别发送给这所有的 N 个队列。扇型用来交换机处理消息的广播路由(broadcast routing)。
使用案例:
- 大规模多用户在线(MMO)游戏可以使用它来处理排行榜更新等全局事件
- 体育新闻网站可以用它来近乎实时地将比分更新分发给移动客户端
- 分发系统使用它来广播各种状态和配置更新
- 在群聊的时候,它被用来分发消息给参与群聊的用户。(AMQP 没有内置 presence 的概念,因此 XMPP 可能会是个更好的选择)
主题交换机:
前面提到的 direct 规则是严格意义上的匹配,换言之 Routing Key 必须与 Binding Key 相匹配的时候才将消息传送给 Queue. 而Topic 的路由规则是一种模糊匹配,可以通过通配符满足一部分规则就可以传送。
它的约定是:
1)binding key 中可以存在两种特殊字符 “” 与“#”,用于做模糊匹配,其中 “” 用于匹配一个单词,“#”用于匹配多个单词(可以是零个)
2)routing key 为一个句点号 “.” 分隔的字符串(我们将被句点号 “. ” 分隔开的每一段独立的字符串称为一个单词),如“stock.usd.nyse”、“nyse.vmw”、“quick.orange.rabbit”
binding key 与 routing key 一样也是句点号 “.” 分隔的字符串使用案例:
- 分发有关于特定地理位置的数据,例如销售点
- 由多个工作者(workers)完成的后台任务,每个工作者负责处理某些特定的任务
- 股票价格更新(以及其他类型的金融数据更新)
- 涉及到分类或者标签的新闻更新(例如,针对特定的运动项目或者队伍)
- 云端的不同种类服务的协调
- 分布式架构 / 基于系统的软件封装,其中每个构建者仅能处理一个特定的架构或者系统。
头交换机:
headers 类型的 Exchange 不依赖于 routing key 与 binding key 的匹配规则来路由消息,而是根据发送的消息内容中的 headers 属性进行匹配。
头交换机可以视为直连交换机的另一种表现形式。但直连交换机的路由键必须是一个字符串,而头属性值则没有这个约束,它们甚至可以是整数或者哈希值(字典)等。灵活性更强(但实际上我们很少用到头交换机)。工作流程:
1)绑定一个队列到头交换机上时,会同时绑定多个用于匹配的头(header)。
2)传来的消息会携带header,以及会有一个 “x-match” 参数。当 “x-match” 设置为 “any” 时,消息头的任意一个值被匹配就可以满足条件,而当 “x-match” 设置为 “all” 的时候,就需要消息头的所有值都匹配成功。交换机小结:





4、Queue队列
AMQP 中的队列(queue)跟其他消息队列或任务队列中的队列是很相似的:它们存储着即将被应用消费掉的消息。
队列属性:
队列跟交换机共享某些属性,但是队列也有一些另外的属性。
- Name
- Durable(消息代理重启后,队列依旧存在)
- Exclusive(只被一个连接(connection)使用,而且当连接关闭后队列即被删除)
- Auto-delete(当最后一个消费者退订后即被删除)
- Arguments(一些消息代理用他来完成类似与 TTL 的某些额外功能)
队列创建:
队列在声明(declare)后才能被使用。如果一个队列尚不存在,声明一个队列会创建它。如果声明的队列已经存在,并且属性完全相同,那么此次声明不会对原有队列产生任何影响。如果声明中的属性与已存在队列的属性有差异,那么一个错误代码为 406 的通道级异常就会被抛出。
队列持久化:
持久化队列(Durable queues)会被存储在磁盘上,当消息代理(broker)重启的时候,它依旧存在。没有被持久化的队列称作暂存队列(Transient queues),Rabbit服务重启后队列就会消失,并不是所有的场景和案例都需要将队列持久化。
持久化的队列并不会使得路由到它的消息也具有持久性。倘若消息代理挂掉了,重新启动,那么在重启的过程中持久化队列会被重新声明,无论怎样,只有经过持久化的消息才能被重新恢复。
持久化队列和非持久化队列的区别是,持久化队列会被保存在磁盘中,固定并持久的存储,当Rabbit服务重启后,该队列会保持原来的状态在RabbitMQ中被管理,而非持久化队列不会被保存在磁盘中,。
5、Consumer消费者
消息如果只是存储在队列里是没有任何用处的。被应用消费掉,消息的价值才能够体现。在 AMQP 0-9-1 模型中,有两种途径可以达到此目的:
1)将消息投递给应用 (“push API”)
2)应用根据需要主动获取消息 (“pull API”)使用 push API,应用(application)需要明确表示出它在某个特定队列里所感兴趣的,想要消费的消息。如是,我们可以说应用注册了一个消费者,或者说订阅了一个队列。一个队列可以注册多个消费者,也可以注册一个独享的消费者(当独享消费者存在时,其他消费者即被排除在外)。
每个消费者(订阅者)都有一个叫做消费者标签的标识符。它可以被用来退订消息。消费者标签实际上是一个字符串。
6、消息机制
消息确认:
消费者应用(Consumer applications) - 用来接受和处理消息的应用 - 在处理消息的时候偶尔会失败或者有时会直接崩溃掉。而且网络原因也有可能引起各种问题。这就给我们出了个难题,AMQP 代理在什么时候删除消息才是正确的?AMQP 0-9-1 规范给我们两种建议:1)自动确认模式:当消息代理(broker)将消息发送给应用后立即删除。(使用 AMQP 方法:basic.deliver 或 basic.get-ok))
2)显式确认模式:待应用(application)发送一个确认回执(acknowledgement)后再删除消息。(使用 AMQP 方法:basic.ack)如果一个消费者在尚未发送确认回执的情况下挂掉了,那 AMQP 代理会将消息重新投递给另一个消费者。如果当时没有可用的消费者了,消息代理会死等下一个注册到此队列的消费者,然后再次尝试投递。
拒绝消息:
当一个消费者接收到某条消息后,处理过程有可能成功,有可能失败。应用可以向消息代理表明,本条消息由于 “拒绝消息(Rejecting Messages)” 的原因处理失败了(或者未能在此时完成)。当拒绝某条消息时,应用可以告诉消息代理如何处理这条消息——销毁它或者重新放入队列。
当此队列只有一个消费者时,请确认不要由于拒绝消息并且选择了重新放入队列的行为而引起消息在同一个消费者身上无限循环的情况发生。
在 AMQP 中,basic.reject 方法用来执行拒绝消息的操作。但 basic.reject 有个限制:你不能使用它决绝多个带有确认回执(acknowledgements)的消息。但是如果你使用的是 RabbitMQ,那么你可以使用被称作 negative acknowledgements(也叫 nacks)的 AMQP 0-9-1 扩展来解决这个问题。
预取消息:
在多个消费者共享一个队列的案例中,明确指定在收到下一个确认回执前每个消费者一次可以接受多少条消息是非常有用的。这可以在试图批量发布消息的时候起到简单的负载均衡和提高消息吞吐量的作用。For example, if a producing application sends messages every minute because of the nature of the work it is doing.(???例如,如果生产应用每分钟才发送一条消息,这说明处理工作尚在运行。)
注意,RabbitMQ 只支持通道级的预取计数,而不是连接级的或者基于大小的预取。
消息属性:
AMQP 模型中的消息(Message)对象是带有属性(Attributes)的。有些属性及其常见,以至于 AMQP 0-9-1 明确的定义了它们,并且应用开发者们无需费心思思考这些属性名字所代表的具体含义。例如:
- Content type(内容类型)
- Content encoding(内容编码)
- Routing key(路由键)
- Delivery mode (persistent or not) 投递模式(持久化 或 非持久化)
- Message priority(消息优先权)
- Message publishing timestamp(消息发布的时间戳)
- Expiration period(消息有效期)
- Publisher application id(发布应用的 ID)
有些属性是被 AMQP 代理所使用的,但是大多数是开放给接收它们的应用解释器用的。有些属性是可选的也被称作消息头(headers)。他们跟 HTTP 协议的 X-Headers 很相似。消息属性需要在消息被发布的时候定义。
消息主体:
AMQP 的消息除属性外,也含有一个有效载荷 - Payload(消息实际携带的数据),它被 AMQP 代理当作不透明的字节数组来对待。消息代理不会检查或者修改有效载荷。消息可以只包含属性而不携带有效载荷。它通常会使用类似 JSON 这种序列化的格式数据,为了节省,协议缓冲器和 MessagePack 将结构化数据序列化,以便以消息的有效载荷的形式发布。AMQP 及其同行者们通常使用 “content-type” 和 “content-encoding” 这两个字段来与消息沟通进行有效载荷的辨识工作,但这仅仅是基于约定而已。
消息持久化:
消息能够以持久化的方式发布,AMQP 代理会将此消息存储在磁盘上。如果服务器重启,系统会确认收到的持久化消息未丢失。简单地将消息发送给一个持久化的交换机或者路由给一个持久化的队列,并不会使得此消息具有持久化性质:它完全取决与消息本身的持久模式(persistence mode)。将消息以持久化方式发布时,会对性能造成一定的影响(就像数据库操作一样,健壮性的存在必定造成一些性能牺牲)。
7、其他
连接:
AMQP 连接通常是长连接。AMQP 是一个使用 TCP 提供可靠投递的应用层协议。AMQP 使用认证机制并且提供 TLS(SSL)保护。当一个应用不再需要连接到 AMQP 代理的时候,需要优雅的释放掉 AMQP 连接,而不是直接将 TCP 连接关闭。通道:
有些应用需要与 AMQP 代理建立多个连接。无论怎样,同时开启多个 TCP 连接都是不合适的,因为这样做会消耗掉过多的系统资源并且使得防火墙的配置更加困难。AMQP 0-9-1 提供了通道(channels)来处理多连接,可以把通道理解成共享一个 TCP 连接的多个轻量化连接。在涉及多线程 / 进程的应用中,为每个线程 / 进程开启一个通道(channel)是很常见的,并且这些通道不能被线程 / 进程共享。
一个特定通道上的通讯与其他通道上的通讯是完全隔离的,因此每个 AMQP 方法都需要携带一个通道号,这样客户端就可以指定此方法是为哪个通道准备的。
虚拟主机:
为了在一个单独的代理上实现多个隔离的环境(用户、用户组、交换机、队列 等),AMQP 提供了一个虚拟主机(virtual hosts - vhosts)的概念。这跟 Web servers 虚拟主机概念非常相似,这为 AMQP 实体提供了完全隔离的环境。当连接被建立的时候,AMQP 客户端来指定使用哪个虚拟主机。AMQP 是可扩展的:
AMQP 0-9-1 拥有多个扩展点:1)定制化交换机类型:可以让开发者们实现一些开箱即用的交换机类型尚未很好覆盖的路由方案。例如 geodata-based routing。)
2)交换机和队列的声明中可以包含一些消息代理能够用到的额外属性。例如 RabbitMQ 中的 per-queue message TTL 即是使用该方式实现。)
3)特定消息代理的协议扩展。例如 RabbitMQ 所实现的扩展。
新的 AMQP 0-9-1 方法类可被引入。)
4)消息代理可以被其他的插件扩展,例如 RabbitMQ 的管理前端 和 已经被插件化的 HTTP API。这些特性使得 AMQP 0-9-1 模型更加灵活,并且能够适用于解决更加宽泛的问题。
AMQP 0-9-1 客户端生态系统:
AMQP 0-9-1 拥有众多的适用于各种流行语言和框架的客户端。其中一部分严格遵循 AMQP 规范,提供 AMQP 方法的实现。另一部分提供了额外的技术,方便使用的方法和抽象。有些客户端是异步的(非阻塞的),有些是同步的(阻塞的),有些将这两者同时实现。有些客户端支持 “供应商的特定扩展”(例如 RabbitMQ 的特定扩展)。因为 AMQP 的主要目标之一就是实现交互性,所以对于开发者来讲,了解协议的操作方法而不是只停留在弄懂特定客户端的库就显得十分重要。这样一来,开发者使用不同类型的库与协议进行沟通时就会容易的多。
二、rabbitMQ基本概念
参考
- python中RabbitMQ的使用(安装和简单教程)
- 理解RabbitMQ中的AMQP-0-9-1模型
1、简介
RabbitMQ(Rabbit Message Queue)是流行的开源消息队列系统,用erlang语言开发。
1.1 关键词说明:
Broker:消息队列服务器实体。
Exchange:消息交换机,它指定消息按什么规则,路由到哪个队列。
Queue:消息队列载体,每个消息都会被投入到一个或多个队列。
Binding:绑定,它的作用就是把exchange和queue按照路由规则绑定起来。
Routing Key:路由关键字,exchange根据这个关键字进行消息投递。
vhost:虚拟主机,一个broker里可以开设多个vhost,用作不同用户的权限分离。
producer:消息生产者,就是投递消息的程序。
consumer:消息消费者,就是接受消息的程序。
channel:消息通道,在客户端的每个连接里,可建立多个channel,每个channel代表一个会话任务。
1.2 消息队列运行机制:
1)客户端连接到消息队列服务器,打开一个channel。
2)客户端声明一个exchange,并设置相关属性。
3)客户端声明一个queue,并设置相关属性。
4)客户端使用routing key,在exchange和queue之间建立好绑定关系。
客户端投递消息到exchange。5)exchange接收到消息后,就根据消息的key和已经设置的binding,将消息投递到一个或多个队列里。
Note:这里的客户端应该是发布端
1.3 exchange类型:
1)Direct交换机
特点:依据key进行投递
例如绑定时设置了routing key为”hello”,那么客户端提交的消息,只有设置了key为”hello”的才会投递到队列。
2)Topic交换机
特点:对key模式匹配后进行投递,符号”#”匹配一个或多个词,符号”*”匹配一个词
例如”abc.#”匹配”abc.def.ghi”,”abc.*”只匹配”abc.def”。
3)Fanout交换机
特点:不需要key,采取广播模式,一个消息进来时,投递到与该交换机绑定的所有队列
2、rabbitMQ的安装
参考
- windows10环境下的RabbitMQ安装步骤(图文)
Note:注意安装rabbitMQ指定版本的Erlang,否则会提示Erlang版本过低或过高,无法安装rabbitMQ。
假设目录是:D:\Program Files\RabbitMQ Server\rabbitmq_server-3.7.3\sbin
然后在后面输入
rabbitmq-plugins enable rabbitmq_management
命令进行安装
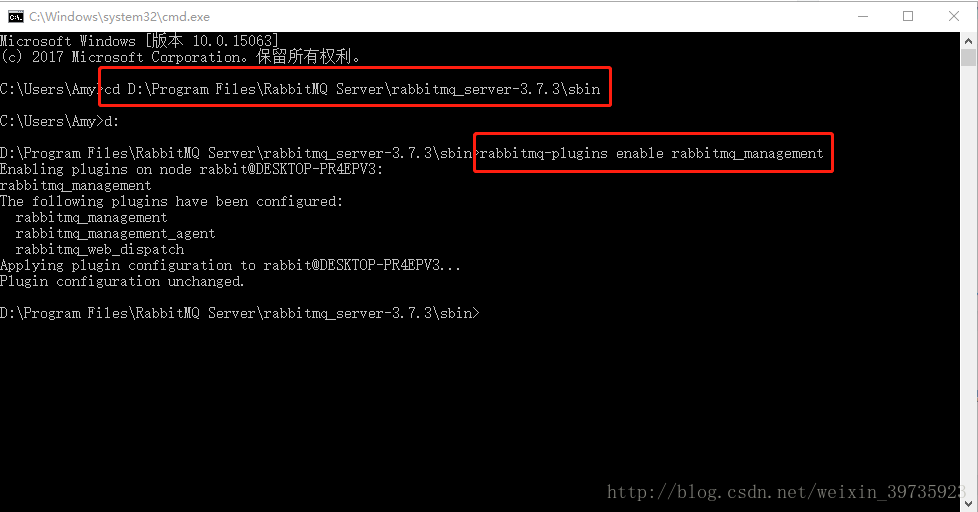
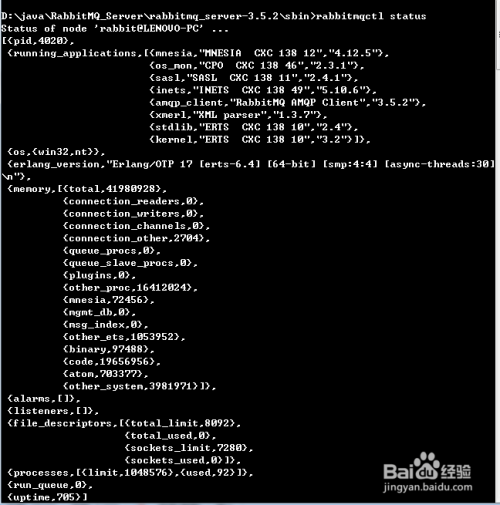
打开命令行,进入RabbitMQ的安装目录: sbin,输入
rabbitmqctl status
, 如果出现以下的图,说明安装是成功的,并且说明现在RabbitMQ Server已经启动了,运行正常。
[
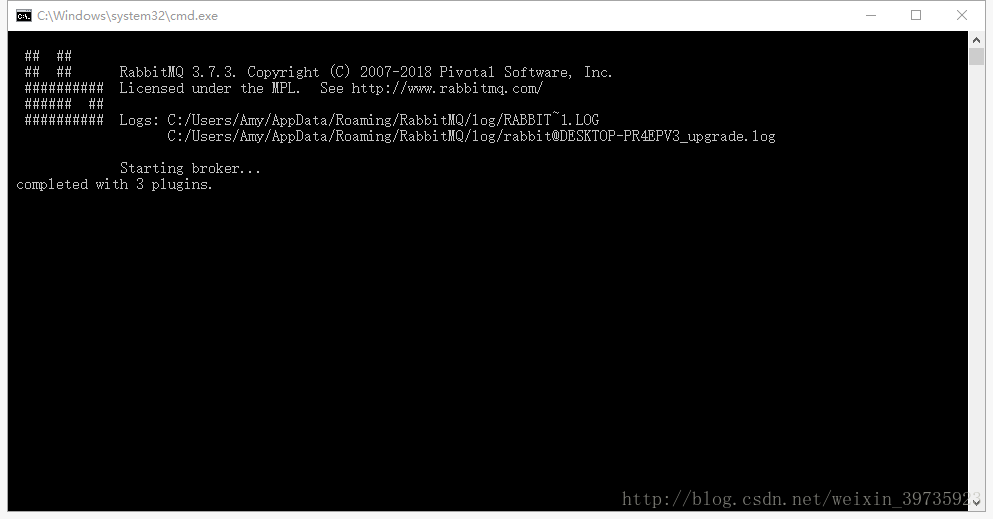
打开sbin目录,双击rabbitmq-server.bat
等几秒钟看到这个界面后,访问http://localhost:15672
然后可以看到如下界面
默认用户名和密码都是guest,登陆即可。
3、常见问题
参考
- 解决win10安装rabbitMQ出现Error: unable to perform an operation on node 'rabbit@。。。的问题
- windows中安装RabbitMQ时:,unable to connect to node rabbit@xxx: nodedown的解决方式
启动rabbitMQ server报错:
Error: unable to perform an operation on node 'rabbit@DESKTOP-5R02C26'. Please see diagnostics information and suggestions below.

解决方法:不用管,直接启动
server.bat
即可
三、rabbitMQ客户端 - pika的使用
参考
- pika 官方文档
- RabbitMQ Tutorials
- python使用pika操作rabbitmq总结(一)
1、生产者 & 消费者
cosumer.py:
#!/usr/bin/env pythonimport pika
auth = pika.PlainCredentials('guest','guest')
connection = pika.BlockingConnection(pika.ConnectionParameters(host='127.0.0.1', port=5672))#如果写成15672,rabbitmq会报错 pika.exceptions.IncompatibleProtocolError: StreamLostError: (‘Transport indicated EOF’,)
channel = connection.channel()
channel.queue_declare(queue='TEST01')defcallback(ch, method, properties, body):print(" [x] Received %r"% body)
channel.basic_consume(on_message_callback=callback,
queue='TEST01',
auto_ack=True)print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()---#未执行producer[*] Waiting for messages. To exit press CTRL+C #如果没消息,会一直堵塞#执行producer[*] Waiting for messages. To exit press CTRL+C
[x] Received b'Hello World!'
poducer.py:
import pika
auth = pika.PlainCredentials('guest','guest')
connection = pika.BlockingConnection(pika.ConnectionParameters(host='127.0.0.1', port=5672))
channel = connection.channel()
channel.queue_declare(queue='TEST01')
channel.basic_publish(exchange='',
routing_key='TEST01',
body='Hello World!')print(" [x] Sent 'Hello World!'")
connection.close()---[x] Sent 'Hello World!'
Queue创建成功:

2、常见操作
a、登录验证
auth = pika.PlainCredentials('guest','guest')
b、创建阻塞连接
'''
The BlockingConnection creates a layer on top of Pika’s asynchronous core providing methods
that will block until their expected response has returned. Due to the asynchronous nature
of the Basic.Deliver and Basic.Return calls from RabbitMQ to your application, you can still
implement continuation-passing style asynchronous methods if you’d like to receive messages
from RabbitMQ using basic_consume or if you want to be notified of a delivery failure when
using basic_publish.
'''
connection = pika.BlockingConnection(pika.ConnectionParameters(host='127.0.0.1', port=5672))
c、创建Channel
'''
Create a new channel with the next available channel number or pass in a channel number to use.
Must be non-zero if you would like to specify but it is recommended that you let Pika manage the
channel numbers.
'''
channel = connection.channel()
d、创建/声明/删除队列
'''
Declare queue, create if needed. This method creates or checks a queue. When creating a new queue the
client can specify various properties that control the durability of the queue and its contents, and
the level of sharing for the queue.
'''
channel.queue_declare(queue='TEST01')#这里注意,消息不能直接发到队列,需要通过exchange
channel.queue_delete(queue='TEST01')
e、消费消息Consume & call_back接口
参考Channel.basic_consume
'''
queue (str) – The queue to consume from. Use the empty string to specify the most recent server-named queue for this channel
on_message_callback (callable) –
The function to call when consuming with the signature on_message_callback(channel, method, properties, body), where
channel: pika.channel.Channel
method: pika.spec.Basic.Deliver
properties: pika.spec.BasicProperties
body: bytes
auto_ack (bool) – if set to True, automatic acknowledgement mode will be used (see http://www.rabbitmq.com/confirms.html). This corresponds with the ‘no_ack’ parameter in the basic.consume AMQP 0.9.1 method
'''defcallback(ch, method, properties, body):print(" [x] Received %r"% body)
channel.basic_consume(on_message_callback=callback,
queue='TEST01',
auto_ack=True)
channel.start_consuming()
f、消费消息get
参考RabbitMQ中BasicGet与BasicConsume的区别
在RabbitMQ中消费者有2种方式获取队列中的消息:
a) 一种是通过basic.consume命令,订阅某一个队列中的消息,channel会自动在处理完上一条消息之后,接收下一条消息。(同一个channel消息处理是串行的)。除非关闭channel或者取消订阅,否则客户端将会一直接收队列的消息。
b) 另外一种方式是通过basic.get命令主动获取队列中的消息,但是绝对不可以通过循环调用basic.get来代替basic.consume,这是因为basic.get RabbitMQ在实际执行的时候,是首先consume某一个队列,然后检索第一条消息,然后再取消订阅。如果是高吞吐率的消费者,最好还是建议使用basic.consume。
简单总结一下就是说:
consume是只要队列里面还有消息就一直取。
get是只取了队列里面的第一条消息。
因为get开销大,如果需要从一个队列取消息的话,首选consume方式,慎用循环get方式!!!。
g、发布消息(★★★★★)
参考
- Channel.basic_publish
- RabbitMQ 四种类型发送接收数据方式
'''
basic_publish(exchange, routing_key, body, properties=None, mandatory=False)
Parameters:
exchange (str) – The exchange to publish to
routing_key (str) – The routing key to bind on
body (bytes) – The message body
properties (pika.spec.BasicProperties) – Basic.properties
mandatory (bool) – The mandatory flag
'''
channel.basic_publish(exchange='',
routing_key='TEST01',
body='Hello World!')
h、请求头配置
classpika.spec.BasicProperties(content_type=None, content_encoding=None, headers=None, delivery_mode=None, priority=None, correlation_id=None, reply_to=None, expiration=None, message_id=None, timestamp=None,type=None, user_id=None, app_id=None, cluster_id=None)
3、摄像头读写操作
producer: np.array转list转json
frame_json = json.dumps(img.tolist())
channel.basic_publish(exchange='',
routing_key='FallDetect',
body=frame_json)
consumer:json转np.array
channel.queue_declare(queue='FallDetect')while(True):defcallback(ch, method, properties, body):
frame_byte = body
frame_json =str(frame_byte,encoding='utf-8')
frame = np.array(json.loads(frame_json),dtype=np.uint8)
cv2.imshow("res",frame)
cv2.waitKey(15)print(" [x] Received %r"% body)
channel.basic_consume(on_message_callback=callback,
queue='FallDetect',
auto_ack=True)print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
4、更多操作
参考
- RabbitMQ pika简单使用
- python 之 RabbitMQ队列模块 pika的使用
5、常见异常
参考https://pika.readthedocs.io/en/latest/modules/exceptions.html
1)StreamLostError:InvalidFrameError
pika.exceptions.StreamLostError: Stream connection lost: InvalidFrameError: Invalid frame received: 'Invalid FRAME_END marker'
参考pika 的坑(pika.exceptions.StreamLostError: Stream connection lost: ConnectionResetError)
我的解决方法是,重新创建连接和channel
defmq_reconnect(self,index,frame_queue,detect_queue):# 如果connection已关闭,则重新创建if(self.connection.is_closed):
self.connection = pika.BlockingConnection(pika.ConnectionParameters(host='127.0.0.1', port=5672))# 如果frame_queue,detect_queue已关闭,则重新创建
frame_queue_name = index +"_frame_queue"
detect_queue_name = index +"_detect_queue"if(frame_queue !=Noneand frame_queue.is_closed):
frame_queue = self.connection.channel()
frame_queue.queue_declare(frame_queue_name)
self.prod_frame_queue[index]= frame_queue
if(detect_queue !=Noneand detect_queue.is_closed):
detect_queue = self.connection.channel()
detect_queue.queue_declare(detect_queue_name)
self.prod_detect_queue[index]= detect_queue
return frame_queue,detect_queue
2)DuplicateGetOkCallback
#如果有两个任务,同时获得channel,进行basic_get(),会报错pika.exceptions.DuplicateGetOkCallback
frame_byte = frame_queue.basic_get(queue=frame_queue_name,
auto_ack=True)[2]
设置标志位,避免多个任务争抢一个channel
if(self.isConsFrameThreading[index]==False):
self.isConsFrameThreading[index]==True...
basic_get()
self.isConsFrameThreading[index]==False
3)pop from an empty deque
raise self._closed_result.value.error
pika.exceptions.StreamLostError: Stream connection lost: IndexError('pop from an empty deque',)
6、rabbitMQ创建长连接
参考rebbitmq之python_pika监控远程连接及自动恢复(七)
connection和channel的重要方法
connection.is_closed:判断当前的TCP是否关闭,如果是关闭返回True,如果处于连接状态,返回False;connection.is_closing:判断当前的TCP连接已发起关闭,但关闭还没有完成的状态,如果是关闭返回True,如果处于连接状态,返回False;connection.is_open:判断当前的TCP连接是否打开,打开返回True,关闭返回False;channel.is_open:判断当前的channel是否打开,打开返回True,关闭返回False;channel.is_closed:判断当前的channel是否打开,如果是关闭返回True,如果打开返回False
注意
- connection关闭后,该连接下面的所有的channel都会关闭;
- is_closed和is_open这种函数只能判断客户端的连接是否打开或关闭,但是无法判断服务端连接的状态,所以当服务端远程关闭了连接时,客户端是不能感知到的;
- 可以设置心跳用来自动关闭异常的TCP连接;
- 如果服务端远程关闭了连接,当客户端发送消息时,捕捉异常并重新建立连接;
四、rabbitMQ使用心得体会
1、个人心得
一开始想使用rabbitMQ的原因是为了解决算法接口不一致,设计统一接口比较麻烦的问题,因此想通过将检测视频帧写入到消息队列中,再从消息队列中读出视频帧,这样代码就很简洁了,如下所示。其中表单是一个摄像头资源,除了配置基本信息之外,还配置了算法模型。为了让算法解耦合,分成如下3个模块,这样每个表单和指定模型,指定消息队列绑定,在算法实现逻辑上解耦合。而且还由于模型处理帧需要一定时间,为了后期通过RPC去远程调用其他服务器中模型的检测结果,可以大大减少监控时延。
但是在实际单机操作中,我却低估了消息队列带来的开销。下面是不使用消息队列的版本
1)无消息队列版
@monitorB.route('/video_start/<channel>')defvideo_start(channel):
camera = Camera()
camera.channel = channel #通道名称一旦创建,只能删除,不能修改
index = channel
#检测该设备是否可以打开if(index in c_mManager.DEVICES.keys()):
key = c_mManager.MODELS[index]
camera = Camera.query.filter_by(channel = channel).first()if(camera.model.interface_type =='video'):
key +=("_"+ channel)
frame = c_mManager.produce_detect_frame(index,key)return Response(frame, mimetype='multipart/x-mixed-replace; boundary=frame')
'''@Info 根据通道名称,算法id、模型id、接口类型,循环获取指定通道的视频检测帧'''defproduce_detect_frame(self,index,key):'''
将检测的frame,res插入到消息队列中
:param index: 摄像头通道名称
:param key: 算法id,模型id,模型接口类型构成的键
:return: 视频帧
'''
camera = self.CAMERAS[index]
device = self.DEVICES[index]
frame_queue_name = index +"_frame_queue"
detect_queue_name = index +"_detect_queue"
frame_queue = self.prod_frame_queue[index]
detect_queue = self.prod_detect_queue[index]
detector = self.detector_dict[key]
event = self.events[index]
detectRespone = DetectRespone()while(True):if(event.isSet()):break# 将读取视频帧的任务交给videoStream类来处理(决定是返回单帧frame,还是count帧frames)
success, frame = camera.read()
algo_id = key.split('_')[0]ifnot success:
camera = cv2.VideoCapture(device)else:
frame = cv2.resize(frame,(640,480))if(algo_id =='1'):'''1、摔倒检测'''# global detectR
r = random.randint(0,50)if(r %2==0):
detectRespone.isFall =Falseelse:
detectRespone.isFall =True# 无法传输帧给openpifpaf接口,只能传递摄像头路径
frame, _ = detector.detect(rtsp=device)elif(algo_id =='2'):'''2、表情识别'''
frame, emotion = detector.detect(frame=frame)
detectRespone.emotion = emotion
elif(algo_id =='3'):'''3、头部位姿估计'''
frame, _ = detector.detect(frame=frame)elif(algo_id =='4'):'''眨眼检测(4.5sec内尝试获取帧)'''
flag =Falsefor i inrange(0,15):
time.sleep(0.3)for frame_t in detector.detect(frame=frame):
frame = frame_t
flag =Truebreakif(flag):break
ret,buffer= cv2.imencode('.jpg', frame)
frame =buffer.tobytes()# 使用yield语句,将帧数据作为响应体返回,content-type为image/jpegyield(b'--frame\r\n'+b'Content-Type: image/jpeg\r\n\r\n'+ frame +b'\r\n')pass
效果如下:延时较高
2)有消息队列版
@monitorB.route('/video_start/<channel>')defvideo_start(channel):
camera = Camera()
camera.channel = channel #通道名称一旦创建,只能删除,不能修改
index = channel
#检测该设备是否可以打开if(index in c_mManager.DEVICES.keys()):
key = c_mManager.MODELS[index]
camera = Camera.query.filter_by(channel = channel).first()if(camera.model.interface_type =='video'):
key +=("_"+ channel)#为produce_detect_frame开启线程,异步执行if(c_mManager.isProdThreadings[index]==False):
c_mManager.isProdThreadings[index]=True
executor.submit(c_mManager.produce_detect_frame,index,key)for frame in c_mManager.gen_frame(camera):return Response(frame, mimetype='multipart/x-mixed-replace; boundary=frame')
defproduce_detect_frame(self,index,key):'''
将检测的frame,res插入到消息队列中
:param index: 摄像头通道名称
:param key: 算法id,模型id,模型接口类型构成的键
:return: 视频帧
'''
camera = self.CAMERAS[index]
device = self.DEVICES[index]
frame_queue_name = index +"_frame_queue"
detect_queue_name = index +"_detect_queue"
frame_queue = self.prod_frame_queue[index]
detect_queue = self.prod_detect_queue[index]
detector = self.detector_dict[key]
event = self.events[index]
detectRespone = DetectRespone()while(True):if(event.isSet()):break# 将读取视频帧的任务交给videoStream类来处理(决定是返回单帧frame,还是count帧frames)
success, frame = camera.read()
algo_id = key.split('_')[0]ifnot success:
camera = cv2.VideoCapture(device)else:
frame = cv2.resize(frame,(640,480))if(algo_id =='1'):'''1、摔倒检测'''# global detectR
r = random.randint(0,50)if(r %2==0):
detectRespone.isFall =Falseelse:
detectRespone.isFall =True# 无法传输帧给openpifpaf接口,只能传递摄像头路径
frame, _ = detector.detect(rtsp=device)elif(algo_id =='2'):'''2、表情识别'''
frame, emotion = detector.detect(frame=frame)
detectRespone.emotion = emotion
elif(algo_id =='3'):'''3、头部位姿估计'''
frame, _ = detector.detect(frame=frame)elif(algo_id =='4'):'''眨眼检测(4.5sec内尝试获取帧)'''
flag =Falsefor i inrange(0,15):
time.sleep(0.3)for frame_t in detector.detect(frame=frame):
frame = frame_t
flag =Truebreakif(flag):break'''写入消息队列(不要删,以后可能会用在分布式中)'''#重新创建连接
frame_queue,detect_queue = self.prodMq_reconnect(index,frame_queue,detect_queue)# 写入detect消息生产队列
detect_json = json.dumps(detectRespone.__dict__)
detect_queue.basic_publish(exchange='',
routing_key=detect_queue_name,
body=detect_json)print("写入detect消息生产队列")# 写入frame消息生产队列
frame_json = json.dumps(frame.tolist())
frame_queue.basic_publish(exchange='',
routing_key=frame_queue_name,
body=frame_json)print("写入frame消息生产队列")pass'''@Info 根据指定通道对应的消息队列,返回ndarray类型的视频帧'''defgen_frame(self,camera)-> np.ndarray:
index = camera.channel
frame_queue_name = index +"_frame_queue"
frame_queue = self.consume_frame_queue[index]while(True):#开启消费线程# if (self.isConsFrameThreading[index] == False):# self.consume_executor.submit(self.consume_frame,index)#避免多个客户端同时利用mq的channel访问queueif(self.isConsFrameThreading[index]==False):# self.consume_executor.submit(self.consume_frame,index)
self.isConsFrameThreading[index]=True# 开始消费
frame_queue, _ = self.consumeMq_reconnect(index, frame_queue,None)# 重新连接print("basic_get before")
frame_byte = frame_queue.basic_get(queue=frame_queue_name,auto_ack=True)[2]print("basic_get after")if(frame_byte !=None):
frame_json =str(frame_byte, encoding='utf-8')
frame = np.array(json.loads(frame_json), dtype=np.uint8)
self.FRAMES[index]= frame
self.isConsFrameThreading[index]=False# 结束消费
frame = self.FRAMES[index]
ret,buffer= cv2.imencode('.jpg', frame)
frame =buffer.tobytes()yield(b'--frame\r\n'+b'Content-Type: image/jpeg\r\n\r\n'+ frame +b'\r\n')
效果:延时更大,而且有时会宕机,并非高可用

主要原因是:对于每一个表单对应的摄像头,需要通过一个消息队列对检测的帧进行publish和consume,同步的过程开销很大。在单机中,不如直接用yield,作为一个生成器来输出结果。还有补充一点,RabbitMQ只是传统的消息队列,不能完全做到分布式。
2、别人的总结 - RabbitMQ 主从 vs Kafka分布式
参考
- 消息队列-如何保证消息队列的高可用?
问题
如何保证消息队列的高可用?
面试题剖析
如果有人问到你 MQ 的知识,高可用是必问的。这个问题这么问是很好的,因为不能问你 Kafka 的高可用性怎么保证?ActiveMQ 的高可用性怎么保证?一个面试官要是这么问就显得很没水平,人家可能用的就是 RabbitMQ,没用过 Kafka,你上来问人家 Kafka 干什么?这不是摆明了刁难人么。
所以有水平的面试官,问的是 MQ 的高可用性怎么保证?这样就是你用过哪个 MQ,你就说说你对那个 MQ 的高可用性的理解。
1. RabbitMQ 的高可用性
RabbitMQ 是比较有代表性的,因为是基于主从(非分布式)做高可用性的,我们就以 RabbitMQ 为例子讲解第一种 MQ 的高可用性怎么实现。
RabbitMQ 有三种模式:单机模式、普通集群模式、镜像集群模式。
a、单机模式
单机模式,就是 Demo 级别的,一般就是你本地启动了玩玩儿的,没人生产用单机模式。
b、普通集群模式(无高可用性)
普通集群模式,意思就是在多台机器上启动多个 RabbitMQ 实例,每个机器启动一个。你创建的 queue,只会放在一个 RabbitMQ 实例上,但是每个实例都同步 queue 的元数据(元数据可以认为是 queue 的一些配置信息,通过元数据,可以找到 queue 所在实例)。你消费的时候,实际上如果连接到了另外一个实例,那么那个实例会从 queue 所在实例上拉取数据过来。(我的理解:对于同一个queue,有不同实例,实例在取值时需要多个实例对应的queue进行同步)
这种方式确实很麻烦,也不怎么好,没做到所谓的分布式,就是个普通集群。因为这导致你要么消费者每次随机连接一个实例然后拉取数据,要么固定连接那个 queue 所在实例消费数据,前者有数据拉取的开销,后者导致单实例性能瓶颈。
而且如果那个放 queue 的实例宕机了,会导致接下来其他实例就无法从那个实例拉取,如果你开启了消息持久化,让 RabbitMQ 落地存储消息的话,消息不一定会丢,得等这个实例恢复了,然后才可以继续从这个 queue 拉取数据。
所以这个事儿就比较尴尬了,这就没有什么所谓的高可用性,这方案主要是提高吞吐量的,就是说让集群中多个节点来服务某个 queue 的读写操作。
c、镜像集群模式(高可用性)
这种模式,才是所谓的 RabbitMQ 的高可用模式。跟普通集群模式不一样的是,在镜像集群模式下,你创建的 queue,无论元数据还是 queue 里的消息都会存在于多个实例上,就是说,每个 RabbitMQ 节点都有这个 queue 的一个完整镜像,包含 queue 的全部数据的意思。然后每次你写消息到 queue 的时候,都会自动把消息同步到多个实例的 queue 上。
那么如何开启这个镜像集群模式呢?其实很简单,RabbitMQ 有很好的管理控制台,就是在后台新增一个策略,这个策略是镜像集群模式的策略,指定的时候是可以要求数据同步到所有节点的,也可以要求同步到指定数量的节点,再次创建 queue 的时候,应用这个策略,就会自动将数据同步到其他的节点上去了。
这样的话,好处在于,你任何一个机器宕机了,没事儿,其它机器(节点)还包含了这个 queue 的完整数据,别的 consumer 都可以到其它节点上去消费数据。坏处在于,第一,这个性能开销也太大了吧,消息需要同步到所有机器上,导致网络带宽压力和消耗很重!第二,这些玩儿,不是分布式的,就没有扩展性可言了,如果某个 queue 负载很重,你加机器,新增的机器也包含了这个 queue 的所有数据,并没有办法线性扩展你的 queue。
2、Kafka 的高可用性
Kafka 一个最基本的架构认识:由多个 broker 组成,每个 broker 是一个节点;你创建一个 topic,这个 topic 可以划分为多个 partition,每个 partition 可以存在于不同的 broker 上,每个 partition 就放一部分数据。
这就是天然的分布式消息队列,就是说一个 topic 的数据,是分散放在多个机器上的,每个机器就放一部分数据。
实际上 RabbitMQ 之类的,并不是分布式消息队列,它就是传统的消息队列,只不过提供了一些集群、HA(High Availability, 高可用性) 的机制而已,因为无论怎么玩儿,RabbitMQ 一个 queue 的数据都是放在一个节点里的,镜像集群下,也是每个节点都放这个 queue 的完整数据。
Kafka 0.8 以前,是没有 HA 机制的,就是任何一个 broker 宕机了,那个 broker 上的 partition 就废了,没法写也没法读,没有什么高可用性可言。
比如说,我们假设创建了一个 topic,指定其 partition 数量是 3 个,分别在三台机器上。但是,如果第二台机器宕机了,会导致这个 topic 的 1/3 的数据就丢了,因此这个是做不到高可用的。
Kafka 0.8 以后,提供了 HA 机制,就是 replica(复制品) 副本机制。每个 partition 的数据都会同步到其它机器上,形成自己的多个 replica 副本。所有 replica 会选举一个 leader 出来,那么生产和消费都跟这个 leader 打交道,然后其他 replica 就是 follower。写的时候,leader 会负责把数据同步到所有 follower 上去,读的时候就直接读 leader 上的数据即可。只能读写 leader?很简单,要是你可以随意读写每个 follower,那么就要 care 数据一致性的问题,系统复杂度太高,很容易出问题。Kafka 会均匀地将一个 partition 的所有 replica 分布在不同的机器上,这样才可以提高容错性。
这么搞,就有所谓的高可用性了,因为如果某个 broker 宕机了,没事儿,那个 broker上面的 partition 在其他机器上都有副本的。如果这个宕机的 broker 上面有某个 partition 的 leader,那么此时会从 follower 中重新选举一个新的 leader 出来,大家继续读写那个新的 leader 即可。这就有所谓的高可用性了。
写数据的时候,生产者就写 leader,然后 leader 将数据落地写本地磁盘,接着其他 follower 自己主动从 leader 来 pull 数据。一旦所有 follower 同步好数据了,就会发送 ack 给 leader,leader 收到所有 follower 的 ack 之后,就会返回写成功的消息给生产者。(当然,这只是其中一种模式,还可以适当调整这个行为)
消费的时候,只会从 leader 去读,但是只有当一个消息已经被所有 follower 都同步成功返回 ack 的时候,这个消息才会被消费者读到。
看到这里,相信你大致明白了 Kafka 是如何保证高可用机制的了,对吧?不至于一无所知,现场还能给面试官画画图。要是遇上面试官确实是 Kafka 高手,深挖了问,那你只能说不好意思,太深入的你没研究过。




3、常见消息队列对比
参考消息队列Kafka、RocketMQ、RabbitMQ的优劣势比较
在高并发业务场景下,典型的阿里双11秒杀等业务,消息队列中间件在流量削峰、解耦上有不可替代的作用。
Mike前面分享了MQ消息队列的设计、核心原理、以及与RPC远程调用的区别等内容。今天我们一起来探讨:
- 全量的消息队列究竟有哪些?
- Kafka、RocketMQ、RabbitMQ的优劣势比较;
- 以及消息队列的选型;
一、最全MQ消息队列有哪些
那么目前在业界有哪些比较知名的消息引擎呢?如下图所示:
这里面几乎完全列举了当下比较知名的消息引擎,包括:
- ZeroMQ
- 推特的Distributedlog
- ActiveMQ:Apache旗下的老牌消息引擎
- RabbitMQ、Kafka:AMQP的默认实现。
- RocketMQ
- Artemis:Apache的ActiveMQ下的子项目
- Apollo:同样为Apache的ActiveMQ的子项目的号称下一代消息引擎
- 商业化的消息引擎IronMQ
- 以及实现了JMS(Java Message Service)标准的OpenMQ。
二、MQ消息队列的技术应用
1.解耦
解耦是消息队列要解决的最本质问题。
2.最终一致性
最终一致性指的是两个系统的状态保持一致,要么都成功,要么都失败。
最终一致性不是消息队列的必备特性,但确实可以依靠消息队列来做最终一致性的事情。
2.广播
消息队列的基本功能之一是进行广播。
有了消息队列,我们只需要关心消息是否送达了队列,至于谁希望订阅,是下游的事情,无疑极大地减少了开发和联调的工作量。
3.错峰与流控
典型的使用场景就是秒杀业务用于流量削峰场景。
由于篇幅的关系,本文重点介绍消息队列比较,详细应用场景可参考我的往期文章《什么是流量消峰?如何解决秒杀业务的削峰场景》。
三、Kafka、RocketMQ、RabbitMQ比较
1.ActiveMQ
优点
- 单机吞吐量:万级
- topic数量都吞吐量的影响:
- 时效性:ms级
- 可用性:高,基于主从架构实现高可用性
- 消息可靠性:有较低的概率丢失数据
- 功能支持:MQ领域的功能极其完备
缺点: 官方社区现在对ActiveMQ 5.x维护越来越少,较少在大规模吞吐的场景中使用。
2.Kafka
号称大数据的杀手锏,谈到大数据领域内的消息传输,则绕不开Kafka,这款为大数据而生的消息中间件,以其百万级TPS的吞吐量名声大噪,迅速成为大数据领域的宠儿,在数据采集、传输、存储的过程中发挥着举足轻重的作用。
Apache Kafka它最初由LinkedIn公司基于独特的设计实现为一个分布式的提交日志系统( a distributed commit log),之后成为Apache项目的一部分。
目前已经被LinkedIn,Uber, Twitter, Netflix等大公司所采纳。
优点
- 性能卓越,单机写入TPS约在百万条/秒,最大的优点,就是吞吐量高。
- 时效性:ms级
- 可用性:非常高,kafka是分布式的,一个数据多个副本,少数机器宕机,不会丢失数据,不会导致不可用
- 消费者采用Pull方式获取消息, 消息有序, 通过控制能够保证所有消息被消费且仅被消费一次;
- 有优秀的第三方Kafka Web管理界面Kafka-Manager;
- 在日志领域比较成熟,被多家公司和多个开源项目使用;
- 功能支持:功能较为简单,主要支持简单的MQ功能,在大数据领域的实时计算以及日志采集被大规模使用
缺点:
- Kafka单机超过64个队列/分区,Load会发生明显的飙高现象,队列越多,load越高,发送消息响应时间变长
- 使用短轮询方式,实时性取决于轮询间隔时间;
- 消费失败不支持重试;
- 支持消息顺序,但是一台代理宕机后,就会产生消息乱序;
- 社区更新较慢;
3.RabbitMQ
RabbitMQ 2007年发布,是一个在AMQP(高级消息队列协议)基础上完成的,可复用的企业消息系统,是当前最主流的消息中间件之一。
RabbitMQ优点:
- 由于erlang语言的特性,mq 性能较好,高并发;
- 吞吐量到万级,MQ功能比较完备
- 健壮、稳定、易用、跨平台、支持多种语言、文档齐全;
- 开源提供的管理界面非常棒,用起来很好用
- 社区活跃度高;
RabbitMQ缺点:
- erlang开发,很难去看懂源码,基本职能依赖于开源社区的快速维护和修复bug,不利于做二次开发和维护。
- RabbitMQ确实吞吐量会低一些,这是因为他做的实现机制比较重。
- 需要学习比较复杂的接口和协议,学习和维护成本较高。
4.RocketMQ
RocketMQ出自 阿里公司的开源产品,用 Java 语言实现,在设计时参考了 Kafka,并做出了自己的一些改进。
RocketMQ在阿里集团被广泛应用在订单,交易,充值,流计算,消息推送,日志流式处理,binglog分发等场景。
RocketMQ优点:
- 单机吞吐量:十万级
- 可用性:非常高,分布式架构
- 消息可靠性:经过参数优化配置,消息可以做到0丢失
- 功能支持:MQ功能较为完善,还是分布式的,扩展性好
- 支持10亿级别的消息堆积,不会因为堆积导致性能下降
- 源码是java,我们可以自己阅读源码,定制自己公司的MQ,可以掌控
RocketMQ缺点:
- 支持的客户端语言不多,目前是java及c++,其中c++不成熟;
- 社区活跃度一般
- 没有在 mq 核心中去实现JMS等接口,有些系统要迁移需要修改大量代码
四、消息队列选择建议
1.Kafka
Kafka主要特点是基于Pull的模式来处理消息消费,追求高吞吐量,一开始的目的就是用于日志收集和传输,适合产生大量数据的互联网服务的数据收集业务。
大型公司建议可以选用,如果有日志采集功能,肯定是首选kafka了。
2.RocketMQ
天生为金融互联网领域而生,对于可靠性要求很高的场景,尤其是电商里面的订单扣款,以及业务削峰,在大量交易涌入时,后端可能无法及时处理的情况。
RoketMQ在稳定性上可能更值得信赖,这些业务场景在阿里双11已经经历了多次考验,如果你的业务有上述并发场景,建议可以选择RocketMQ。
3.RabbitMQ
RabbitMQ :结合erlang语言本身的并发优势,性能较好,社区活跃度也比较高,但是不利于做二次开发和维护。不过,RabbitMQ的社区十分活跃,可以解决开发过程中遇到的bug。
如果你的数据量没有那么大,小公司优先选择功能比较完备的RabbitMQ。



版权归原作者 王小希ww 所有, 如有侵权,请联系我们删除。