
当MySQL中的数据量达到千万级别时,使用
COUNT()
查询可能会变得比较慢。这是因为
COUNT()
会扫描整个表并计算匹配的行数,对于大表来说,这个过程可能会非常耗时。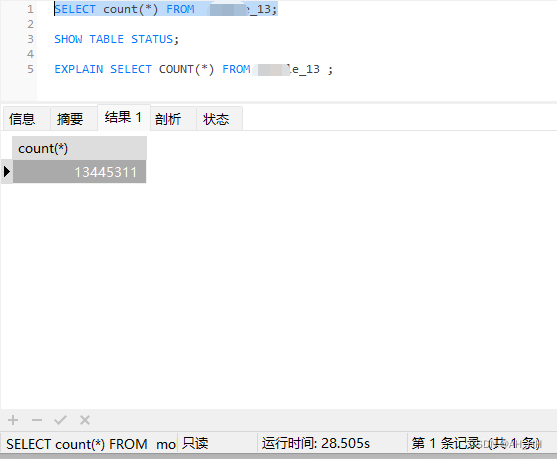
在上图中查询一千三百多万数据耗时 28s左右。
以下是一些优化COUNT(*)查询的方法:
- 使用索引: 确保查询的字段上有适当的索引。如果没有索引,
COUNT(*)将会执行全表扫描,导致性能下降。可以考虑在查询的字段上创建索引,以加快查询速度。 - 使用近似值: 如果对实时性要求不高,可以使用近似值来代替精确的
COUNT(*)。例如,可以使用近似的行数估计函数如SHOW TABLE STATUS或EXPLAIN SELECT COUNT(*) FROM table_name来获取大致的行数。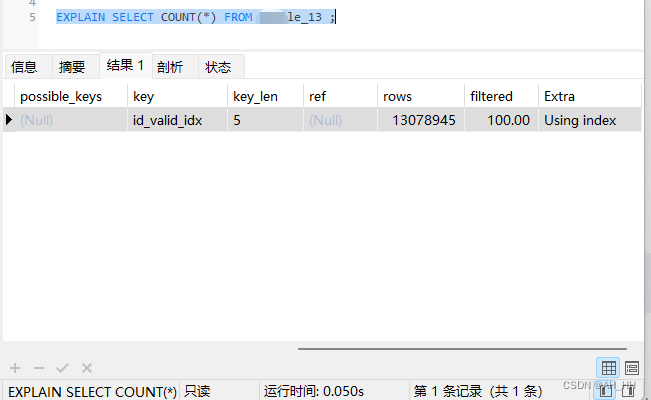
这里使用EXPLAIN 查询非常快,但是数据没有那么精准。
- 使用缓存: 如果查询的结果不需要实时更新,可以将结果缓存在缓存中,避免每次查询都执行
COUNT(*)操作。可以使用缓存技术如Redis或Memcached来实现。 - 分批查询: 如果查询的结果集很大,可以考虑将查询分批进行,每次查询一部分数据,然后累加结果。这样可以减少单次查询的数据量,提高查询速度。
- 数据分片: 如果数据量非常大,可以考虑将数据进行分片存储,将数据分散到多个表或数据库中。这样可以将查询的数据量分散到多个节点上,提高查询性能。
- 数据汇总表: 如果对实时性要求不高,可以创建一个汇总表,用于存储每个表的行数。定期更新汇总表的行数,然后查询汇总表来获取行数,避免每次都执行COUNT(*)操作。
以上是一些优化COUNT(*)查询的方法,具体的优化策略需要根据具体的业务需求和数据库结构来确定,您还有哪些解决方案分享一下。
本文转载自: https://blog.csdn.net/qq_35098526/article/details/132101439
版权归原作者 AH_HH 所有, 如有侵权,请联系我们删除。
版权归原作者 AH_HH 所有, 如有侵权,请联系我们删除。