
一、mysql简介
数据库
是一个能
存数据
的软件, 提供各种数据的
查询操作
, 以及对数据的
修改操作
mysql
的具体安装操作,这里就不做过多的介绍了。主要讲讲如何通过py程序来实现mysql操作。
具体的安装操作可以看下面这一篇
链接
: mysql的安装与配置
这里的操作基本都在navicat里实现可视化
1. 安装python连接mysql的模块 -> pymysql模块
pip install pymysql
2. pymysql导包:
import pymysql
二、mysql基本操作
1. 创建表
用
SQL语句
创建表格
createtable student(-- 字段=列=column=属性
sno int(10)primarykeyauto_increment,
sname varchar(50)notnull,
sbirthday datenotnull,
saddress varchar(255),
sphone varchar(12),
class_name varchar(50));
项目数据类型double小数varchar字符串date时间(年月日)datetime时间(年月日时分秒)text大文本项目约束条件primary key主键, 全表唯一值. 就像学号. 身份证号. 能够唯一的确定一条数据auto_increment主键自增. 必须是整数类型not null不可以为空.null可以为空default设置默认值
2. 修改表
-- 添加一列ALTERTABLE table_name
ADDCOLUMN column_name datatype
-- egALTERTABLE student
ADDCOLUMN f_name VARCHAR(20)NOTNULLAFTER sno;-- AFTER 用于将新加的列在指定列的后面插入-- 删除一列ALTERTABLE table_name
DROPCOLUMN column_name
-- 修改一列的数据类型ALTERTABLE table_name
MODIFYCOLUMN column_name datatype
-- 表格重命名ALTERTABLE table_name RENAMETO new_name;
3. 在navicat中实现创建表和修改表
3.1 navicat与mysql连接
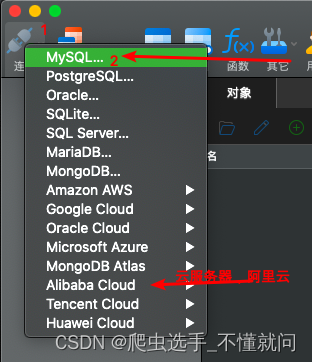
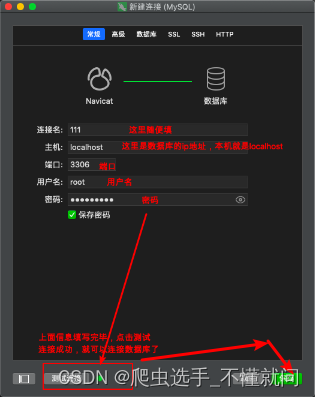
创建完毕后,还需要右键或者双击打开连接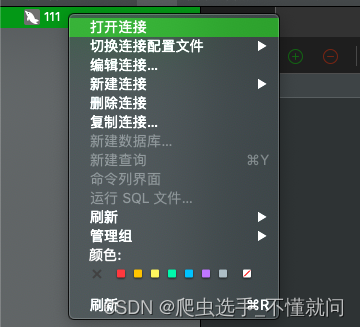
3.2 navicat创建数据库
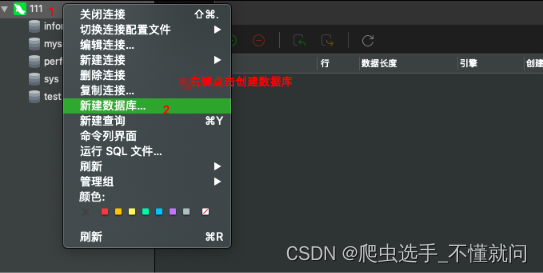
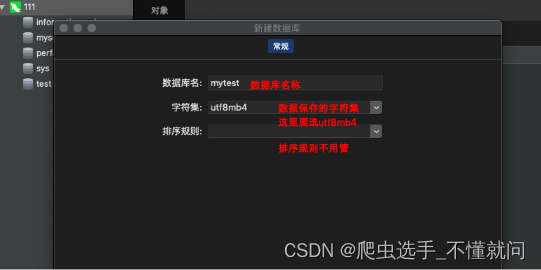
和连接一样,也是需要进行开启的
至此, Navicat可以操纵你的数据库了.
3.3 navicat创建表
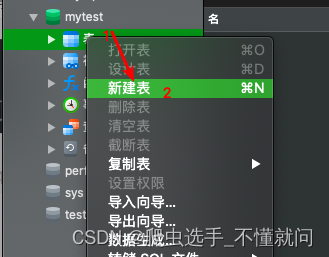
傻瓜式操作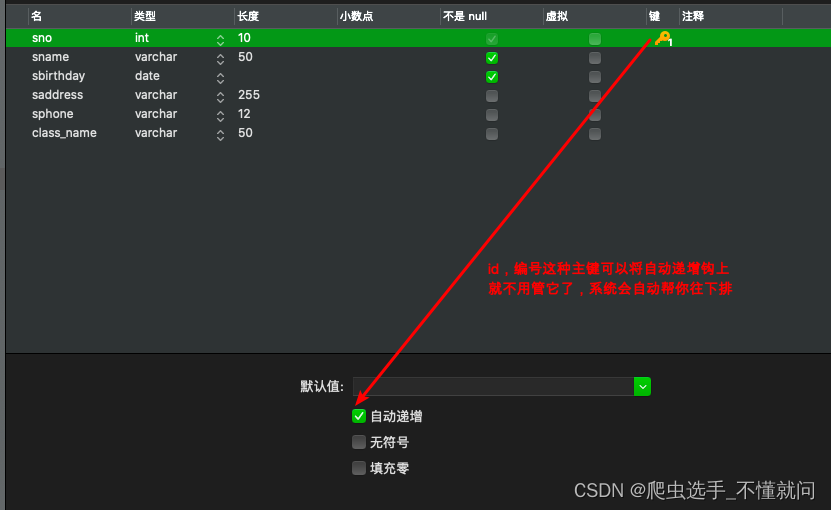
3.4 navicat设计表
选择创建好的表,右键设计表,就可以进行修改表操作了
4. 数据的操作-增删改查-数据
4.1 增加数据
INSERTINTO table_name(col1, col2, col3...)values(val1,val2,val3)
-- 添加学生信息INSERTINTO STUDENT(sname, sbirthday, saddress, sage, class_name)values('周杰伦','2020-01-02',"北京市昌平区",18,"二班");
注意, 如果
主键设置自增
, 就
不用处理主键
了. mysql会
自动
的帮我们
按照自然顺序
进行
逐一自增
.
4.2 删除数据
DELETEFROM table_name where_clause
-- 删除学生信息DELETEFROM STUDENT where sno =1;
4.3 修改数据
UPDATE table_name SET col1 = val1, col2 = val2... where_clause
-- 修改学生信息UPDATE STUDENT SET SNAME ='王力宏'where sno =1;
4.4 查询数据
4.4.1 基础查询
SELECT*|col1, col2, col3
FROM table_name
where_clause
-- 全表查询SELECT*FROM STUDENT;-- 查询学生姓名, 年龄SELECT sname, sage FROM STUDENT;-- 查询学号是1的学生信息select*from student where sno =1;-- 查询年龄大于20的学生信息select*from student where sage >20;-- 查询学生年龄大于20 小于40的信息(包含)select*from student where sage >=20and sage <=40;select*from student where sage between20and40;-- 查询姓张的学生信息-- _一位字符串-- %多位字符串select*from student where sname like'张%';
4.4.2 分组查询和聚合函数
如何查询每个班级学生的平均年龄?
我们先把数据扩充一下下
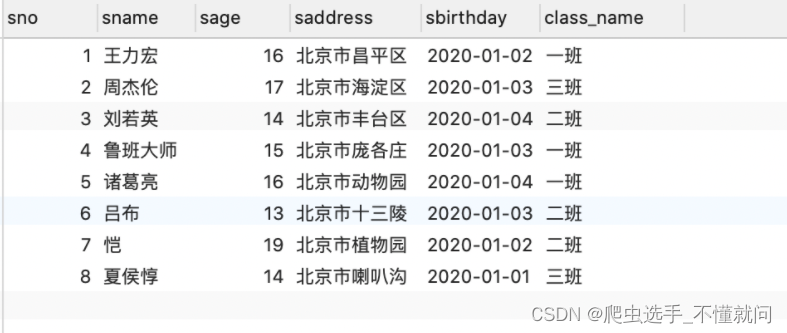
每个班级的平均年龄. 我们是不是需要先把班级与班级先分开. 每个班级自己内部进行计算.对吧. 此时, 我们需要的就是一个分组的操作. 此时需要用到group by语句
select*from table_name groupby col_name
注意, 上方的sql是无法使用的. sql要求分组后, 到底要做什么必须明确指出. 否则报错
那很容易呀, 我们分完组要计算每个班级的平均年龄. 平均数如何计算, 这就要用到聚合函数. sql中提供5种聚合函数, 分别是: avg(), sum(), min(), max(), count()
-- 查询每一个班级的平均年龄selectavg(sage), class_name from STUDENT groupby class_name;-- 查询每个班级最小的年龄selectmin(sage), class_name from STUDENT groupby class_name;-- 查询每个班的最大年龄selectmax(sage), class_name from STUDENT groupby class_name;-- 查询每个班的学生数量selectcount(*), class_name from STUDENT groupby class_name;-- 查询每个班级的年龄和selectsum(sage), class_name from STUDENT groupby class_name;
注意, 不要把没有放在group by的内容直接放在select中. 你想想. 按照班级来查询平均年龄, 你非要把某一个人的信息放在结果里. 是不合适的.
4.4.4 having语句
如果我们需要对聚合函数计算的结果进一步的筛选. 可以用having语句
-- 查询平均年龄在15岁以上的班级信息selectavg(sage), class_name from student groupby class_name havingavg(sage)>15;
having和where的区别
:
- where, 在原始数据上进行的
数据筛选. - having, 在聚合函数计算后的
结果进行筛选.
4.4.5 排序
sql中使用
order by
语句对查询结果进行
排序
.
-- 按照年龄从小到大查询学生信息select*from student orderby sage asc-- 按照年龄从大到小查询学生信息select*from student orderby sage desc
4.5 多表联合查询
在实际使用中, 一个表格肯定是无法满足我们数据存储的. 比如, 在学生选课系统中. 我们就可以设计成以下表结构:
- 学生表: 学号, 姓名, 性别, 住址等…
- 课程表: 课程编号, 课程名称, 授课教师等…
- 学生课程-成绩表: 成绩表编号, 学号, 课程编号, 成绩
在这样的表结构中:
优势
: 每个表的结构相对明确. 不存在歧义. 数据保存完整, 没有冗余.
劣势
: 新手不太好想. 想不通为什么要这样设计. 这里涉及到数据库表结构设计范式, 该模型属于第三范式(听过就行).
在该模型表结构中. 成绩表是非常重要的. 在成绩表中, 明确的说明了哪个学生的哪一门课程得了多少分. 它将两个原来毫不相关的表关联了起来. 建立了主外键关系.
何为
主外键关系
:
把A表中的主键放在另一张表里作为普通字段使用, 但数据要求必须来自于A. 这个很好理解. 比如, 学生成绩表中的学生编号数据就必须来自于学生表. 否则该数据是无意义的.
注意, 以上结构只是为了讲解多表关系. 并非完整的学生选课系统表结构.
建表语句:
-- 创建学生表, 课程表, 成绩表-- 1. 学生表: 学号, 姓名, 性别, 住址等...-- 2. 课程表: 课程编号, 课程名称, 授课教师等...-- 3. 学生课程-成绩表: 成绩表编号, 学号, 课程编号, 成绩createtable stu(
sid intprimarykeyauto_increment,
sname varchar(50)notnull,
gender int(1),
address varchar(255));createtable course(
cid intprimarykeyauto_increment,
cname varchar(50)notnull,
teacher varchar(50));createtable sc(
sc_id intprimarykeyauto_increment,
s_id int,
c_id int,
score int,CONSTRAINT FK_SC_STU_S_ID FOREIGNkey(s_id)REFERENCES stu(sid),CONSTRAINT FK_SC_COURSE_C_ID FOREIGNkey(c_id)REFERENCES course(cid));
4.5.1 子查询
在where语句中可以进行另外的一个查询.
例如, 查询选择了"编程"这门课的学生
-- 查询选择了"编程"这门课的学生-- 先查询编程课程的编号select cid from course where cname ='编程';-- 根据cid可以去sc表查询出学生的idselect s_id from sc where c_id =2;-- 根据学生ID查询学生信息select*from stu where sid in(1,2,3,4,5,6);-- 把上面的sql穿起来 select*from stu where sid in(select s_id from sc where c_id in(select cid from course where cname ='编程'));-- 查询课程名称为“编程”,且分数低于60的学生姓名和分数select stu.sname, sc.score from stu, sc where stu.sid = sc.s_id and sc.score <60and sc.c_id in(select cid from course where cname ='编程')
4.5.2 关联查询
关联查询
就是把多个表格通过
join的方式
合并在一起. 然后进行条件检索.
语法规则:
select...from A xxx join B on A.字段1= b.字段2
表示: A表和B表连接. 通过A表的字段1和b表的字段2进行连接. 通常on后面的都是主外键关系
4.5.2.1 inner join
-- 查询每门课程被选修的学生数-- count(*)-- group by cidselect c.cid,c.cname,count(*)from sc innerjoin course c on sc.c_id = c.cid groupby c.cid, c.cname
4.5.2.2 left join
-- 查询所有学生的选课情况select s.sname, c.cname from stu s leftjoin sc on s.sid= sc.s_id leftjoin course c on sc.c_id = c.cid
-- 查询任何一门课程成绩在70分以上的姓名、课程名称和分数-- score > 70 sc-- sname student-- cname courseselect s.sname, c.cname, sc.score from stu s innerjoin sc on s.sid = sc.s_id innerjoin course c on sc.c_id = c.cid
where sc.score >70
三、python连接mysql
3.1 查找数据
import pymysql # 导入模块from pymysql.cursors import DictCursor # 导入字典模块# 1. 创建连接
conn = pymysql.connect(# 当忘记参数是什么的时候,直接按住commond点进去看看
user='root',# 用户名
password="x",# 密码
host='127.0.0.1',# 端口
database='test',# 数据库名)# 2. 创建cursor, 游标 -> 用于执行sql语句,,以及获取sql执行结果
cursor = conn.cursor()# 2.1 执行sql语句
cursor.execute('select * from student')
r = cursor.fetchall()# 获取结果print(r)# 运行完毕,会发现是元组套元组的形式 # ( (), () )# 而我们喜欢的数据类型应该是 [{cno:1, cname:xxx, xxx: xxx}, {}, {}]# 所以需要导入一个字典模块# 将导入的模块放到游标里
cursor1 = conn.cursor(DictCursor)# 2.1 执行sql语句
cursor1.execute('select * from student')
r = cursor1.fetchall()# 获取结果print(r)# 可以发现已经成为我们想要的那个类型了
运行结果
3.2 新增数据
import pymysql # 导入模块from pymysql.cursors import DictCursor # 导入字典模块# 1. 创建连接
conn = pymysql.connect(# 当忘记参数是什么的时候,直接按住commond点进去看看
user='root',# 用户名
password="x",# 密码
host='127.0.0.1',# 端口
database='test',# 数据库名)# 2. 新增数据
cursor = conn.cursor()
sname ='wby'
sbirthday ='2010-08-10'
saddress ='浙江宁波'
class_name ='少年团'# 准备好sql语句# 注意: 这种sql的问题 1. 很乱, 2. 有被注入的风险,可以选择下面的方式
sql =f'insert into student(sname, sbirthday, saddress, class_name) values ("{sname}", "{sbirthday}", "{saddress}", "{class_name}")'
cursor.execute(sql)# 数据增加后,需要提交
conn.commit()# %s字符串的占位符 用来预处理,有几个参数要填入,就写几个%s -> 推荐这种方法
sql =f'insert into student(sname, sbirthday, saddress, class_name) values (%s, %s, %s, %s)'# 在execute中放预处理的内容, 注意传入的是元组的形式
cursor.execute(sql,(sname, sbirthday, saddress, class_name))
conn.commit()
四、关于mysql总结
- 爬虫常用的
增加数据操作
insertinto 表(字段1,字段2,字段3...)values(值1,值2,值3...)
- 爬虫常用的
修改数据操作
update 表 set 字段=值, 字段=值 where 条件
- 爬虫常用的
删除数据操作
deletefrom 表 where 条件
- 爬虫常用的
查询数据操作
select*from 表 where 条件
版权归原作者 爬虫选手_不懂就问 所有, 如有侵权,请联系我们删除。