
Spark 作为一个数据处理框架和计算引擎
**1 Spark-Local 模式 **
**1.1 解压缩文件 **
将 spark-2.1.1-bin-hadoop3.2.tgz 文件上传到 Linux 并解压缩,放置在指定位置,路径中。
tar -zxvf spark-2.1.1-bin-hadoop2.7.tgz -C /opt/apps/
cd /opt/apps/
mv spark-2.1.1-bin-hadoop2.7 spark-local
**1.2 启动 Local 环境 **
- 进入解压缩后的路径,执行如下指令
bin/spark-shell
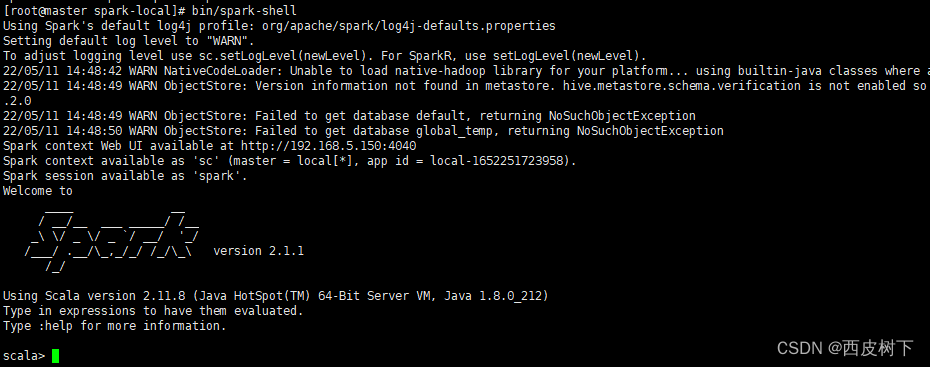 2) 启动成功后,可以输入网址进行 Web UI 监控页面访问
2) 启动成功后,可以输入网址进行 Web UI 监控页面访问
**1.4 退出本地模式 **
按键 Ctrl+C 或输入 Scala 指令 :quit
**1.5 提交应用 **
bin/spark-submit --class org.apache.spark.examples.SparkPi --master local[2] ./examples/jars/spark-examples_2.12-3.0.0.jar 10

- --class 表示要执行程序,此处可以更换
- --master local[2] 部署模式,默认为本地模式,数字表示分配的虚拟 CPU 核数量
- spark-examples_2.12-3.0.0.jar 运行的应用类所在的 jar 包,实际使用时,可以更改jar
- 数字 10 表示程序的入口参数,用于设定当前应用的任务数量
** 2 Spark-Standalone 模式 **
**1.1 解压缩文件 **
将 spark-2.1.1-bin-hadoop3.2.tgz 文件上传到 Linux 并解压缩,放置在指定位置,路径中。
tar -zxvf spark-2.1.1-bin-hadoop2.7.tgz -C /opt/apps/
cd /opt/apps/
mv spark-2.1.1-bin-hadoop2.7 spark-standalone
2.2 修改配置文件
- 进入解压缩后路径的 conf 目录,修改 slaves.template 文件名为 slaves
mv slaves.template slaves
- 修改 slaves 文件,添加 work 节点
master
slave1
slave2
- 修改 spark-env.sh.template 文件名为 spark-env.sh
mv spark-env.sh.template spark-env.sh
- 修改 spark-env.sh 文件,添加 JAVA_HOME 环境变量和集群对应的 master 节点
export JAVA_HOME=/opt/apps/jdk
SPARK_MASTER_HOST=master
SPARK_MASTER_PORT=7077
- 分发 spark-standalone 目录
6)启动集群
sbin/start-all.sh
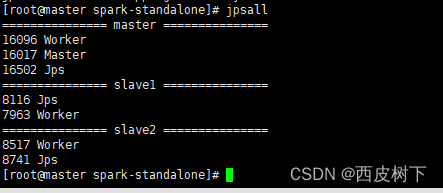
- 查看 Master 资源监控 Web UI 界面: http://master:8080
10)跑任务测试
bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://master:7077 ./examples/jars/spark-examples_2.11-2.1.1.jar 10

- --class 表示要执行程序的主类
- --master spark://master:7077 独立部署模式,连接到 Spark 集群
- spark-examples_2.11-2.1.1.jar 运行类所在的 jar 包
- 数字 10 ,用于设定当前应用的任务数量
3 Yarn 模式
**3.1 解压缩文件 **
将 spark-2.1.1-bin-hadoop3.2.tgz 文件上传到 Linux 并解压缩,放置在指定位置,路径中。
tar -zxvf spark-2.1.1-bin-hadoop2.7.tgz -C /opt/apps/
cd /opt/apps/
mv spark-2.1.1-bin-hadoop2.7 spark-yarn
3.2 修改配置文件
- 修改 hadoop 配置文件/opt/module/hadoop/etc/hadoop/yarn-site.xml, 并分发
hadoop搭建
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认
是 true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认
是 true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
- 修改 conf/spark-env.sh,添加 JAVA_HOME 和 YARN_CONF_DIR 配置
export JAVA_HOME=/opt/apps/jdk
YARN_CONF_DIR=/opt/apps/hadoop-2.7.7/etc/hadoop
3) 启动 Hadoop
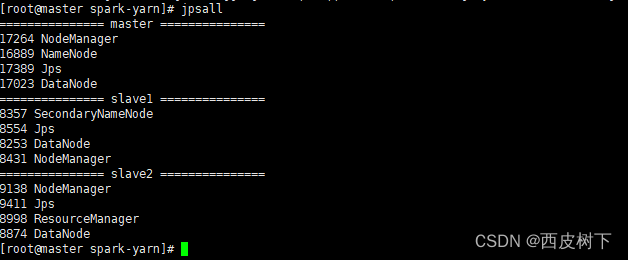
4)跑任务测试是不是成功
4.1)打印控制台
bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode client ./examples/jars/spark-examples_2.11-2.1.1.jar 10

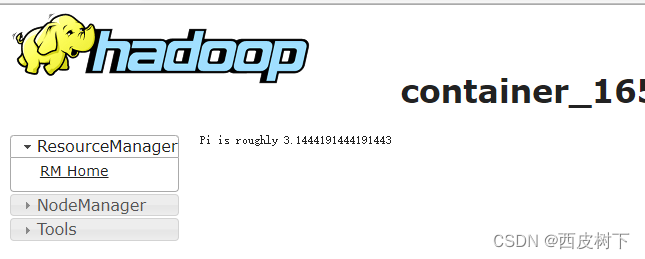
4.2)在yarn上看结果
bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster ./examples/jars/spark-examples_2.11-2.1.1.jar 10
本文转载自: https://blog.csdn.net/m0_67144365/article/details/124709759
版权归原作者 西皮树下 所有, 如有侵权,请联系我们删除。
版权归原作者 西皮树下 所有, 如有侵权,请联系我们删除。