
RAG是什么
简而言之,RAG 是一种在将数据发送到 LLM 之前从数据中查找相关信息并将其注入到提示中的方法。这样LLM将获得(希望)相关信息,并能够使用这些信息进行回复,这应该会减少产生幻觉的可能性。
实现方法:
- 全文(关键字)搜索。该方法使用 TF-IDF 和 BM25 等技术,通过将查询中的关键字(例如,用户询问的内容)与文档数据库进行匹配来搜索文档。它根据每个文档中这些关键字的频率和相关性对结果进行排名。
- 矢量搜索,也称为“语义搜索”。使用嵌入模型将文本文档转换为数字向量。然后,它根据查询向量和文档向量之间的余弦相似度或其他相似度/距离度量来查找文档并对其进行排名,从而捕获更深层次的语义。
- 结合多种搜索方法(例如全文+向量)通常可以提高搜索的效率。
RAG的两个步骤
RAG 过程分为 2 个不同的阶段:索引(indexing) 和 **检索(retrieval)**。
索引(Indexing)
此过程可能会根据所使用的信息检索方法而有所不同。对于矢量搜索,这通常涉及清理文档,用额外的数据和元数据丰富它们,将它们分成更小的片段(也称为分块),嵌入这些片段,最后将它们存储在嵌入存储(又称为矢量数据库)中。
索引阶段通常离线进行,这意味着它不需要最终用户等待其完成。例如,这可以通过 cron 定时任务来实现,该定时任务每周在周末重新索引一次公司内部文档。负责索引的代码也可以是仅处理索引任务的单独应用程序。
但是,在某些情况下,最终用户可能希望上传其自定义文档,以便 LLM 可以访问它们。在这种情况下,索引应该在线执行并成为主应用程序的一部分。
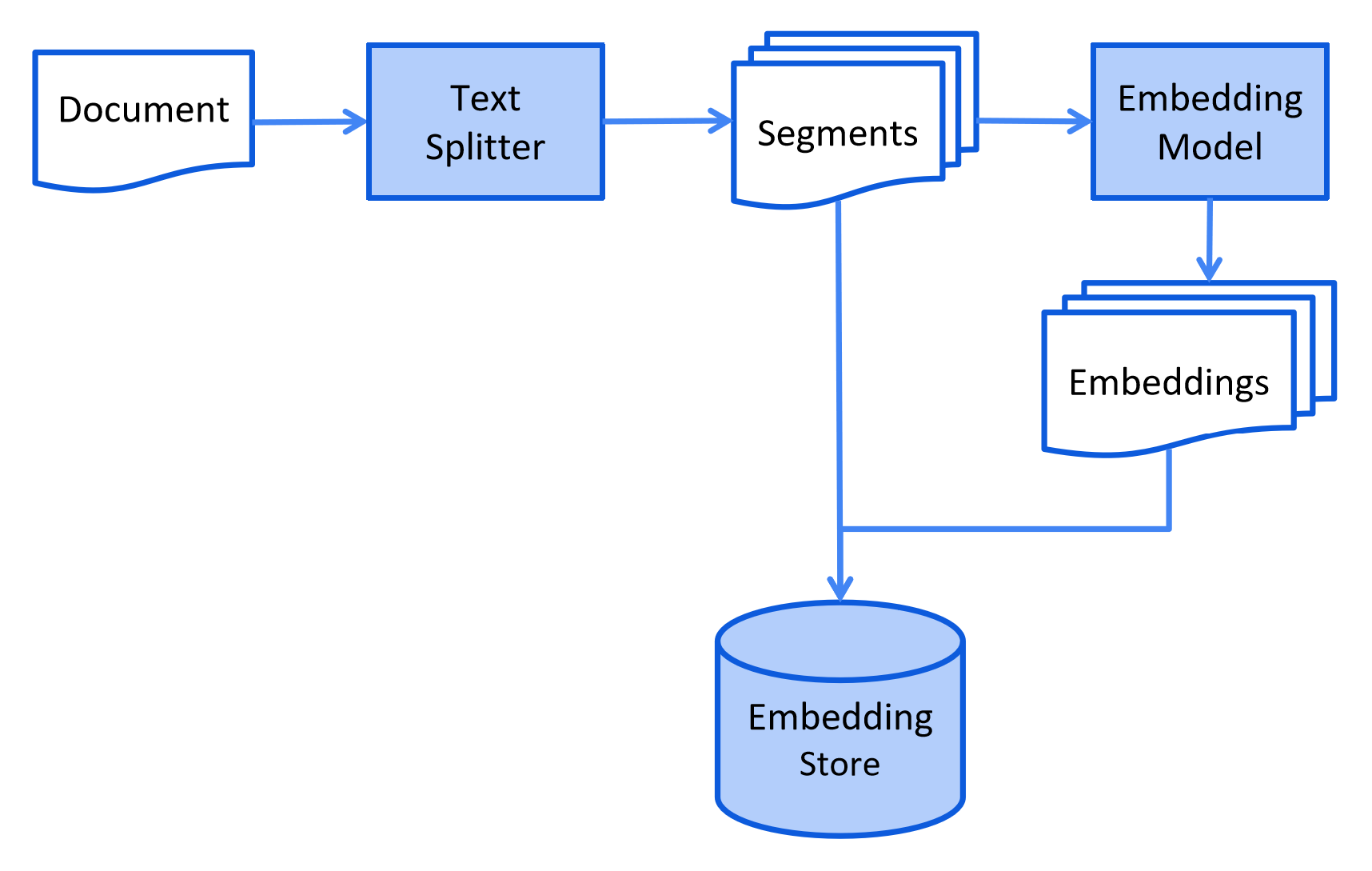
检索(Retrieval)
检索过程通常发生在用户提交文档使用索引回答用户问题时。
此过程可能会根据所使用的信息检索方法而有所不同。对于向量搜索,这通常涉及嵌入用户的查询(问题)并在嵌入存储中执行相似性搜索。然后相关片段(原始文档的片段)被注入到提示中并发送到LLM。
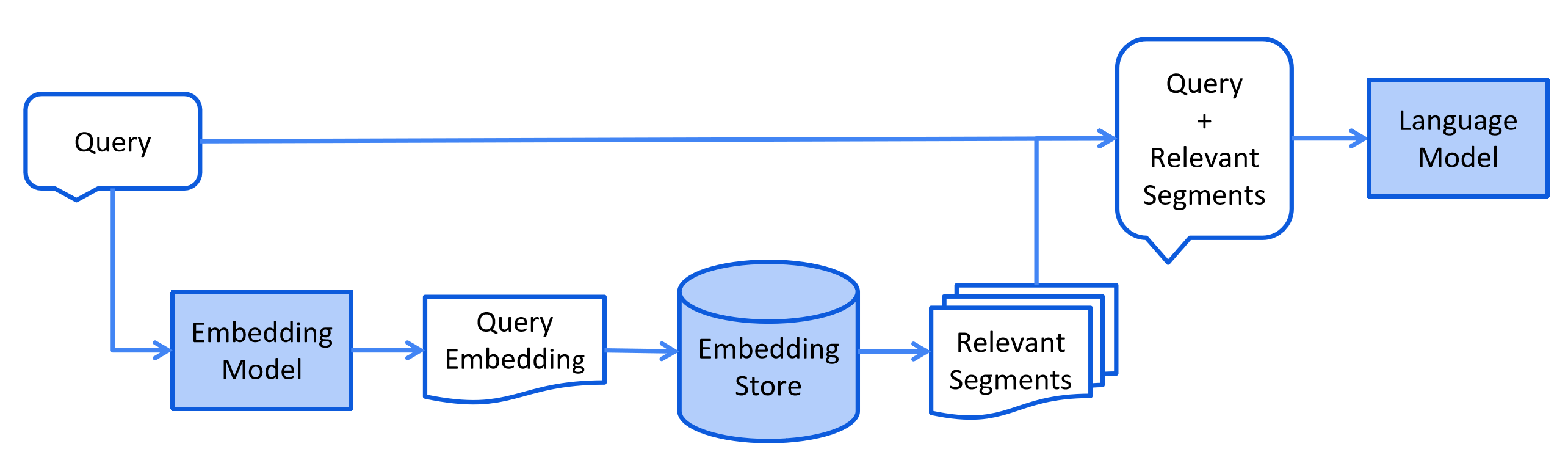
Easy RAG
LangChain4j 有一个“Easy RAG”功能,可以让 RAG 上手变得尽可能简单。不必了解嵌入、选择向量存储、找到正确的嵌入模型、弄清楚如何解析和分割文档等。只需指向您的文档,LangChain4j 就会发挥其魔力。
导入
angchain4j-easy-rag
依赖
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-easy-rag</artifactId>
<version>0.33.0</version>
</dependency>
官方示例:
public class Easy_RAG_Example {
/**
* This example demonstrates how to implement an "Easy RAG" (Retrieval-Augmented Generation) application.
* By "easy" we mean that we won't dive into all the details about parsing, splitting, embedding, etc.
* All the "magic" is hidden inside the "langchain4j-easy-rag" module.
* <p>
* If you want to learn how to do RAG without the "magic" of an "Easy RAG", see {@link Naive_RAG_Example}.
*/
public static void main(String[] args) {
// First, let's load documents that we want to use for RAG
List<Document> documents = loadDocuments(toPath("documents/"), glob("*.txt"));
// Second, let's create an assistant that will have access to our documents
Assistant assistant = AiServices.builder(Assistant.class)
.chatLanguageModel(OpenAiChatModel.builder().baseUrl(OPENAI_API_URL).apiKey(OPENAI_API_KEY).build()) // it should use OpenAI LLM
.chatMemory(MessageWindowChatMemory.withMaxMessages(10)) // it should remember 10 latest messages
.contentRetriever(createContentRetriever(documents)) // it should have access to our documents
.build();
// Lastly, let's start the conversation with the assistant. We can ask questions like:
// - Can I cancel my reservation?
// - I had an accident, should I pay extra?
startConversationWith(assistant);
}
private static ContentRetriever createContentRetriever(List<Document> documents) {
// Here, we create and empty in-memory store for our documents and their embeddings.
InMemoryEmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();
// Here, we are ingesting our documents into the store.
// Under the hood, a lot of "magic" is happening, but we can ignore it for now.
EmbeddingStoreIngestor.ingest(documents, embeddingStore);
// Lastly, let's create a content retriever from an embedding store.
return EmbeddingStoreContentRetriever.from(embeddingStore);
}
}
List<Document> documents = FileSystemDocumentLoader.loadDocuments("/home/langchain4j/documentation");
LangChain4j支持了15种向量存储的方式, 为了简单起见, 这里的Easy RAG就是用了内存存储。
InMemoryEmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();
EmbeddingStoreIngestor.ingest(documents, embeddingStore);
最后一步: 创建一个AI服务来调用LLM的API
interface Assistant {
String chat(String userMessage);
}
Assistant assistant = AiServices.builder(Assistant.class)
.chatLanguageModel(OpenAiChatModel.withApiKey(OPENAI_API_KEY))
.chatMemory(MessageWindowChatMemory.withMaxMessages(10))
.contentRetriever(EmbeddingStoreContentRetriever.from(embeddingStore))
.build();
现在就可以正常聊天了
String answer = assistant.chat("How to do Easy RAG with LangChain4j?");
Accessing Sources
如果想要获取访问源(检索到的 Content 用于扩充消息),您可以通过将返回类型包装在 Result 类中轻松实现:
interface Assistant {
Result<String> chat(String userMessage);
}
Result<String> result = assistant.chat("How to do Easy RAG with LangChain4j?");
String answer = result.content();
List<Content> sources = result.sources();
RAG APIs
LangChain4j 提供了一组丰富的 API,可以轻松构建自定义 RAG 管道,从简单的管道到高级的管道。
Document 文件
Document 类代表整个文档,例如单个 PDF 文件或网页。目前, Document 只能表示文本信息,但未来的更新将使其能够支持图像和表格。
使用方法:
Document.text()返回Document的文本Document.metadata()返回Document的Metadata(见下文)**Document.toTextSegment()**将Document转换为TextSegment(见下文), 主要是为了更好的将文档分段向量化,在上下文窗口限制比较小的时候比较适用。Text Segment 文本段Document.from(String, Metadata)从文本和Metadata创建DocumentDocument.from(String)从带有空Metadata的文本创建Document
Metadata 元数据
每个
Document
包含
Metadata
。它存储有关
Document
的元信息,例如其名称、来源、上次更新日期、所有者或任何其他相关详细信息。
Metadata
存储为键值映射,其中键为 String 类型,值可以为以下类型之一:
String
、
Integer
、
Long
、
Float
、
Double
。
Metadata
很有用,有几个原因:
- 当在 LLM 的提示中包含
Document的内容时,还可以包含元数据条目,为 LLM 提供要考虑的附加信息。例如,提供Document名称和来源可以帮助提高LLM对内容的理解。 - 当搜索要包含在提示中的相关内容时,可以按
Metadata条目进行过滤。例如,您可以将语义搜索范围缩小到仅属于特定所有者的Document。 - 当 Document 的来源更新时(例如,文档的特定页面),可以通过其元数据条目(例如“id”、 “源”等)并在 EmbeddingStore 中更新它以保持同步。
这里需要结合官方的示例学习, Metadata算是一个很重要的东西, 可以按照我们想要的方式把不同的文档数据进行隔离和过滤, 这样可以实现私有知识库的隔离。会对特定的回答达到更精确的效果。
静态过滤使用示例
void Static_Metadata_Filter_Example() {
// given
TextSegment dogsSegment = TextSegment.from("Article about dogs ...", metadata("animal", "dog"));
TextSegment birdsSegment = TextSegment.from("Article about birds ...", metadata("animal", "bird"));
EmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();
embeddingStore.add(embeddingModel.embed(dogsSegment).content(), dogsSegment);
embeddingStore.add(embeddingModel.embed(birdsSegment).content(), birdsSegment);
// embeddingStore contains segments about both dogs and birds
Filter onlyDogs = metadataKey("animal").isEqualTo("dog");
ContentRetriever contentRetriever = EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore)
.embeddingModel(embeddingModel)
.filter(onlyDogs) // by specifying the static filter, we limit the search to segments only about dogs
.build();
Assistant assistant = AiServices.builder(Assistant.class)
.chatLanguageModel(chatLanguageModel)
.contentRetriever(contentRetriever)
.build();
// when
String answer = assistant.answer("Which animal?");
// then
assertThat(answer)
.containsIgnoringCase("dog")
.doesNotContainIgnoringCase("bird");
}
按用户id动态过滤示例
interface PersonalizedAssistant {
String chat(@MemoryId String userId, @dev.langchain4j.service.UserMessage String userMessage);
}
@Test
void Dynamic_Metadata_Filter_Example() {
// 这里就是将文本设置Meta的userId, 区分所属用户
TextSegment user1Info = TextSegment.from("My favorite color is green", metadata("userId", "1"));
TextSegment user2Info = TextSegment.from("My favorite color is red", metadata("userId", "2"));
EmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();
embeddingStore.add(embeddingModel.embed(user1Info).content(), user1Info);
embeddingStore.add(embeddingModel.embed(user2Info).content(), user2Info);
// embeddingStore contains information about both first and second user
Function<Query, Filter> filterByUserId =
(query) -> metadataKey("userId").isEqualTo(query.metadata().chatMemoryId().toString());
ContentRetriever contentRetriever = EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore)
.embeddingModel(embeddingModel)
// 动态过滤, 只检索MemoryId等于当前用户id的文档数据
.dynamicFilter(filterByUserId)
.build();
PersonalizedAssistant personalizedAssistant = AiServices.builder(PersonalizedAssistant.class)
.chatLanguageModel(chatLanguageModel)
.contentRetriever(contentRetriever)
.build();
// when
String answer1 = personalizedAssistant.chat("1", "Which color would be best for a dress?");
// then
assertThat(answer1)
.containsIgnoringCase("green")
.doesNotContainIgnoringCase("red");
// when
String answer2 = personalizedAssistant.chat("2", "Which color would be best for a dress?");
// then
assertThat(answer2)
.containsIgnoringCase("red")
.doesNotContainIgnoringCase("green");
}
动态字段过滤实现一个简单的推荐系统
@Test
void LLM_generated_Metadata_Filter_Example() {
// given
TextSegment forrestGump = TextSegment.from("Forrest Gump", metadata("genre", "drama").put("year", 1994));
TextSegment groundhogDay = TextSegment.from("Groundhog Day", metadata("genre", "comedy").put("year", 1993));
TextSegment dieHard = TextSegment.from("Die Hard", metadata("genre", "action").put("year", 1998));
// 将元数据键描述为SQL表中的字段, 模拟sql表的结构
TableDefinition tableDefinition = TableDefinition.builder()
.name("movies")
.addColumn("genre", "VARCHAR", "one of: [comedy, drama, action]")
.addColumn("year", "INT")
.build();
LanguageModelSqlFilterBuilder sqlFilterBuilder = new LanguageModelSqlFilterBuilder(chatLanguageModel, tableDefinition);
EmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();
embeddingStore.add(embeddingModel.embed(forrestGump).content(), forrestGump);
embeddingStore.add(embeddingModel.embed(groundhogDay).content(), groundhogDay);
embeddingStore.add(embeddingModel.embed(dieHard).content(), dieHard);
ContentRetriever contentRetriever = EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore)
.embeddingModel(embeddingModel)
.dynamicFilter(query -> sqlFilterBuilder.build(query)) // LLM will generate the filter dynamically
.build();
Assistant assistant = AiServices.builder(Assistant.class)
.chatLanguageModel(chatLanguageModel)
.contentRetriever(contentRetriever)
.build();
// when
String answer = assistant.answer("Recommend me a good drama from 90s");
System.out.println(answer);
// then
assertThat(answer)
.containsIgnoringCase("Forrest Gump")
.doesNotContainIgnoringCase("Groundhog Day")
.doesNotContainIgnoringCase("Die Hard");
}
核心使用方法
Metadata底层实际上就是一个HashMap
Metadata.from(Map)从Map创建MetadataMetadata.put(String key, String value) / put(String, int)/等等,向Metadata添加一个条目Metadata.getString(String key) / getInteger(String key)/等等,返回Metadata条目的值,将其转换为所需的类型Metadata.containsKey(String key)检查Metadata是否包含具有指定keyMetadata.remove(String key)通过键从Metadata中删除对应键值对Metadata.copy()返回Metadata的副本Metadata.toMap()将Metadata转换为Map
Document Loader 文档加载器
可以从
String
创建
Document
,但更简单的方法是使用库中包含的文档加载器之一:
langchain4j模块下的FileSystemDocumentLoader: 根据本地文件路径加载文档langchain4j模块下的UrlDocumentLoader: 读取可以url访问下载的文档langchain4j-document-loader-amazon-s3模块下的AmazonS3DocumentLoaderlangchain4j-document-loader-azure-storage-blob模块的AzureBlobStorageDocumentLoaderlangchain4j-document-loader-github模块的GitHubDocumentLoader: 读取github上文档的工具, 可以选择仓库,分支,和文件路径langchain4j-document-loader-tencent-cos模块的TencentCosDocumentLoader: 根据腾云cos读取文档
Document Parser 文档解析器
Document
可以表示各种格式的文件,例如 PDF、DOC、TXT 等。为了解析这些格式中的每一种,库中有一个
DocumentParser
接口,其中包含多个实现:
TextDocumentParser来自langchain4j模块,它可以解析纯文本格式的文件(例如TXT、HTML、MD等)ApachePdfBoxDocumentParser来自langchain4j-document-parser-apache-pdfbox模块,可以解析PDF文件- 来自
langchain4j-document-parser-apache-poi模块的ApachePoiDocumentParser,它可以解析MS Office文件格式(例如DOC,DOCX,PPT,PPTX,XLS,XLSX等) ApacheTikaDocumentParser来自langchain4j-document-parser-apache-tika模块,可以自动检测和解析几乎所有现有的文件格式
// 加载单个文档
Document document = FileSystemDocumentLoader.loadDocument("/home/langchain4j/file.txt", new TextDocumentParser());
// 加载目录下所有文档
List<Document> documents = FileSystemDocumentLoader.loadDocuments("/home/langchain4j", new TextDocumentParser());
// 加载目录下所有".txt"结尾的文档
PathMatcher pathMatcher = FileSystems.getDefault().getPathMatcher("glob:*.txt");
List<Document> documents = FileSystemDocumentLoader.loadDocuments("/home/langchain4j", pathMatcher, new TextDocumentParser());
// 加载目录下和子目录下的所有文档
List<Document> documents = FileSystemDocumentLoader.loadDocumentsRecursively("/home/langchain4j", new TextDocumentParser());
Document Transformer 文档转换器
DocumentTransformer
实现可以执行各种文档转换,例如:
- cleaning:这涉及从
Document文本中删除不必要的噪音,这可以节省 tokens 并减少干扰。 - Filtering:从搜索中完全排除特定的
Document。(这里就可以结合前面提到的Metadata来进行条件过滤) - Enriching: 可以将附加信息添加到
Document中,以潜在地增强搜索结果。 Summarizing:Document可以被总结,它的简短总结可以存储在 Metadata 中,稍后包含在每个TextSegment中(我们将在下面介绍)以潜在地改进搜索。
官方只提供了一个实现类:
HtmlTextExtractor
实现了对原始
HTML
文件提取文本内容和
Metadata
元数据。
后续可能官方会有更多的实现工具,官方建议可以根据自己的需求来实现
DocumentTransformer
满足自己的文档解析的需求。
官方示例:
@Test
public void test() {
List<Document> docs = new ArrayList<>();
docs.add(Document.document("abc xyz", Metadata.metadata("lang", "en")));
docs.add(Document.document("jkl 123", Metadata.metadata("lang", "en")));
docs.add(Document.document("mno qrs", Metadata.metadata("lang", "fr")));
List<Document> results = ((DocumentTransformer) document -> {
if (document.metadata().get("lang").equals("en")) {
return Document.document(
document.text().toUpperCase(Locale.ROOT),
document.metadata());
} else {
return null;
}
}).transformAll(docs);
assertThat(results).containsOnly(
Document.document("ABC XYZ", Metadata.metadata("lang", "en")),
Document.document("JKL 123", Metadata.metadata("lang", "en"))
);
}
这里就是一个实例,
DocumentTransformer
实现一个如果是
Metadata
中的
lang
标识为
en
的英文文档,则将文本内容进行大写的转换。
Text Segment 文本段
一旦
Document
被加载,就可以将它们分割(块)成更小的段(片)。
LangChain4j
的域模型包含一个
TextSegment
类,它表示
Document
的一部分。顾名思义,
TextSegment
只能表示文本信息。
有时候可能只想在提示中包含几个相关部分而不是整个知识库,原因有多种:
- LLMs 的上下文窗口有限,因此整个知识库可能不适合
- 在提示中提供的信息越多,LLM 处理该信息并做出响应的时间就越长
- 提示中不相关的信息可能会分散 LLM 的注意力并增加产生幻觉的机会
- 在提示中提供的信息越多,就越难根据 LLM 响应的信息进行解释
我们可以通过将知识库分成更小、更容易理解的部分来解决这些问题。
目前有两种广泛使用的方法
- 每个文档(例如 PDF 文件、网页等)都是原子且不可分割的。在 RAG 管道中检索期间,将检索 N 个最相关的文档并将其注入到提示中。在这种情况下,您很可能需要使用长上下文 LLM,因为文档可能会很长。如果检索完整文档很重要(不能错过某些细节时),则适合使用此方法。
优点:不会丢失上下文。
缺点:
- 消耗更多的tokens。- 有时,文档可以包含多个部分/主题,并且并非所有部分/主题都与查询相关。- 矢量搜索质量会受到影响,因为各种大小的完整文档被压缩为单个固定长度的矢量。
- 文档被分成更小的部分,例如章节、段落,有时甚至是句子。在 RAG 管道中检索期间,将检索 N 个最相关的段并将其注入到提示中。挑战在于确保每个细分都为 LLM 提供足够的上下文/信息来理解它。缺少上下文可能会导致 LLM 误解给定的片段并产生幻觉。一种常见的策略是将文档分割成重叠的片段,但这并不能完全解决问题。一些先进的技术可以在这里提供帮助,例如“句子窗口检索”、“自动合并检索”和“父文档检索”。但本质上,这些方法有助于获取有关检索到的段的更多上下文,为 LLM 提供检索到的段之前和之后的附加信息。
优点:
- 更好的矢量搜索质量。- 减少代币消耗。
缺点:一些上下文可能仍然丢失。
核心使用方法
TextSegment.text()返回TextSegment的文本TextSegment.metadata()返回TextSegment的MetadataTextSegment.from(String, Metadata)从文本创建TextSegment和MetadataTextSegment.from(String)从带有空Metadata的文本创建TextSegment
Document Splitter 文档分割器
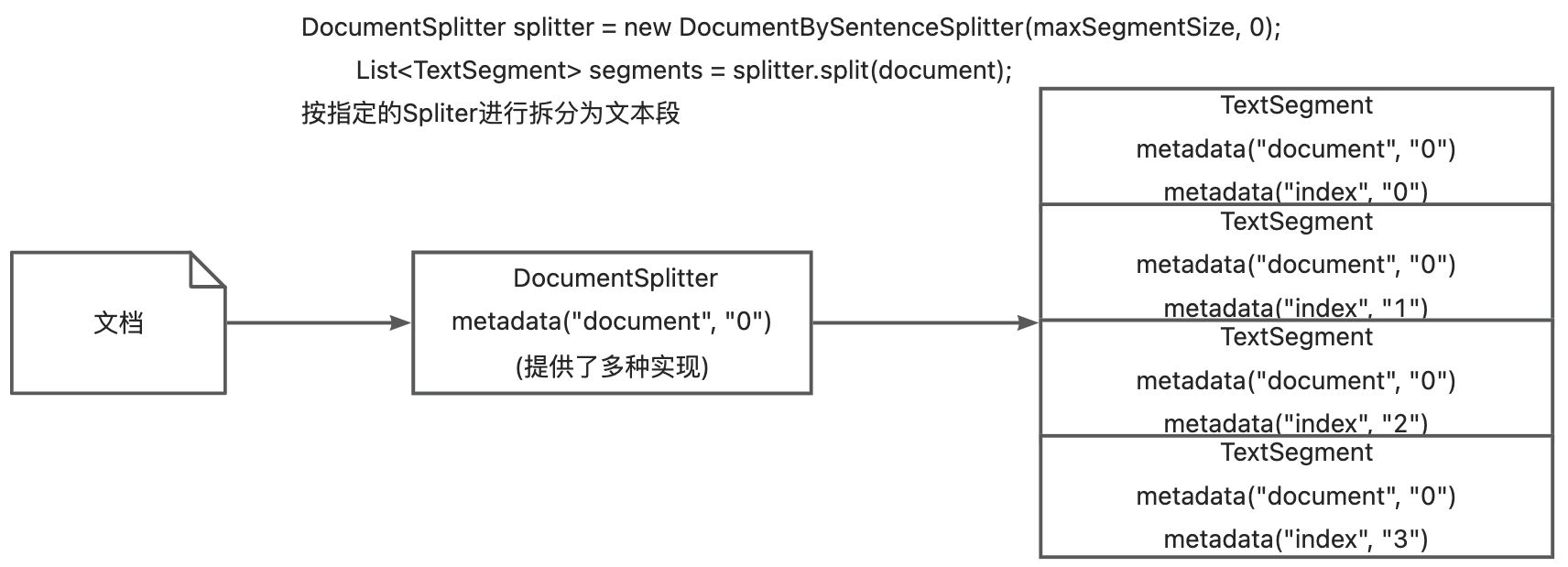
原理:
DocumentSplitter,指定TextSegment的所需大小,以及字符或tokens的重叠(可选)。调用
DocumentSplitter的split(Document)或splitAll(List<Document>)方法。DocumentSplitter将给定的Document分割成更小的单元,其性质随分割器的不同而变化。例如:DocumentByParagraphSplitter将文档分割为段落(由两个或多个连续换行符定义)-DocumentBySentenceSplitter使用OpenNLP库的句子检测器将文档分割为句子,等等。
DocumentSplitter将这些较小的单元(段落、句子、单词等)组合成TextSegment,尝试在单个TextSegment不超过步骤 1 中设置的限制。如果某些单元仍然太大而无法放入TextSegment中,则会调用子拆分器。这是另一个能够将不适合更细化单元的单元拆分的DocumentSplitter。所有Metadata条目都从Document复制到每个TextSegment。唯一的元数据条目“索引”被添加到每个文本段。第一个TextSegment将包含index=0,第二个index=1,依此类推。
Text Segment Transformer 文本段转换器
官方只是提供了定义,仍然建议我们自行去根据业务去实现自定义的转换器。
使用场景: 一种对于提高检索效果非常有效的技术是在每个
TextSegment
中包含
Document
标题或简短摘要。
官方的使用示例:
class TextSegmentTransformerTest implements WithAssertions {
public static class LowercaseFnordTransformer implements TextSegmentTransformer {
@Override
public TextSegment transform(TextSegment segment) {
//对文本进行小写转换
String result = segment.text().toLowerCase();
//对包含指定字符的文本段进行过滤, 可以考虑安全隐患的一些数据过滤场景
if (result.contains("fnord")) {
return null;
}
return TextSegment.from(result, segment.metadata());
}
}
@Test
public void test_transformAll() {
TextSegmentTransformer transformer = new LowercaseFnordTransformer();
TextSegment ts1 = TextSegment.from("Text");
ts1.metadata().put("abc", "123"); // metadata is copied over (not transformed
TextSegment ts2 = TextSegment.from("Segment");
TextSegment ts3 = TextSegment.from("Fnord will be filtered out");
TextSegment ts4 = TextSegment.from("Transformer");
List<TextSegment> segmentList = new ArrayList<>();
segmentList.add(ts1);
segmentList.add(ts2);
segmentList.add(ts3);
segmentList.add(ts4);
assertThat(transformer.transformAll(segmentList))
.containsExactly(
TextSegment.from("text", ts1.metadata()),
TextSegment.from("segment"),
TextSegment.from("transformer"));
}
}
Embedding 嵌入
Embedding
类封装了一个数值向量,表示已嵌入内容(通常是文本,例如
TextSegment
)的“语义含义”。
使用方法:
Embedding.dimension()返回嵌入向量的维度(其长度)CosineSimilarity.between(Embedding, Embedding)计算 2 个Embedding之间的余弦相似度Embedding.normalize()标准化嵌入向量
Embedding Model 嵌入模型
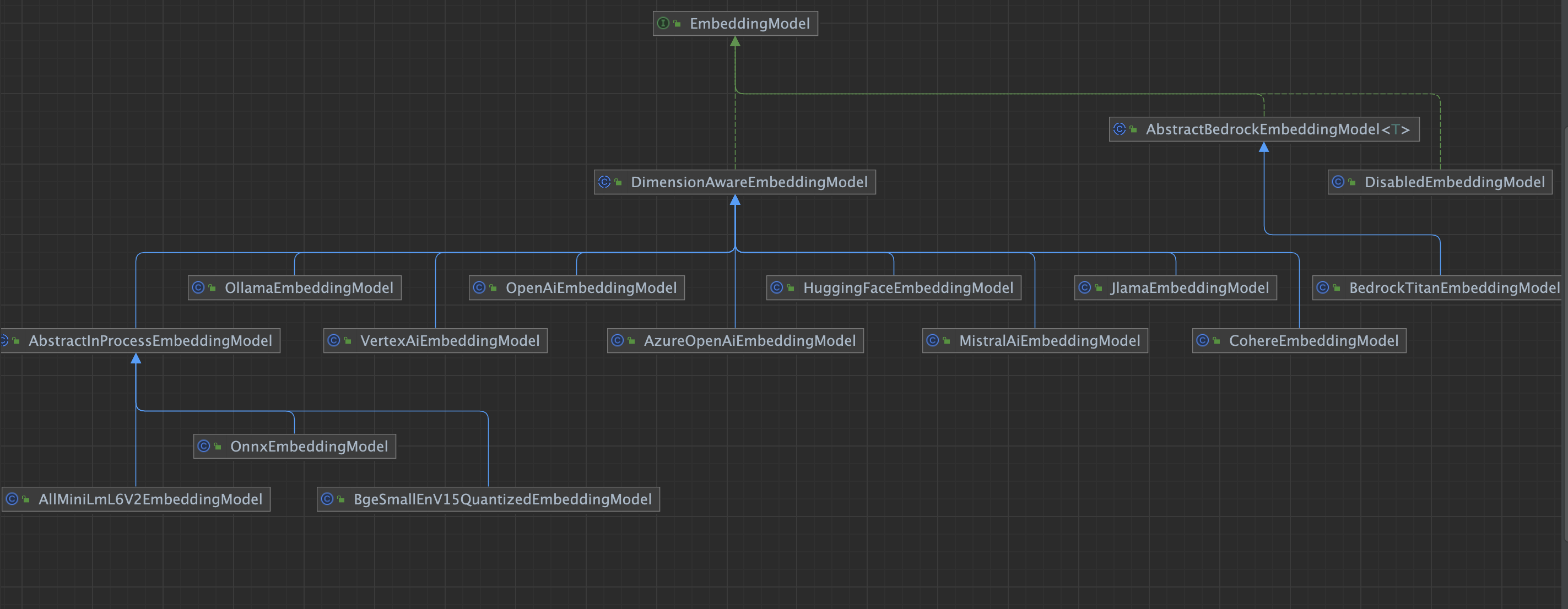
使用方法:
EmbeddingModel.embed(String)嵌入给定的文本EmbeddingModel.embed(TextSegment)嵌入给定的TextSegmentEmbeddingModel.embedAll(List<TextSegment>)嵌入所有给定的TextSegmentEmbeddingModel.dimension()返回此模型生成的Embedding的尺寸
Embedding Store 嵌入存储
EmbeddingStore
接口代表
Embedding
的存储,也称为矢量数据库。它允许存储和有效搜索相似的(在嵌入空间中接近的)
Embedding
。
EmbeddingStore
可以单独存储
Embedding
,也可以与相应的
TextSegment
一起存储:
- 它只能通过 ID 存储
Embedding。原始嵌入数据可以存储在其他地方并使用 ID 进行关联。 - 它可以存储
Embedding和已嵌入的原始数据(通常是TextSegment)。
使用方法:
EmbeddingStore.add(Embedding)将给定的Embedding添加到存储并返回随机 IDEmbeddingStore.add(String id, Embedding)将具有指定 ID 的给定Embedding添加到存储中EmbeddingStore.add(Embedding, TextSegment)将给定的Embedding以及关联的TextSegment添加到存储中并返回随机 IDEmbeddingStore.addAll(List<Embedding>)将给定Embedding的列表添加到存储中并返回随机 ID 的列表EmbeddingStore.addAll(List<Embedding>, List<TextSegment>)将给定的Embedding列表以及关联的TextSegment列表添加到存储中并返回随机 ID 列表EmbeddingStore.search(EmbeddingSearchRequest)搜索最相似的EmbeddingEmbeddingStore.remove(String id)根据 ID 从存储中删除单个EmbeddingEmbeddingStore.removeAll(Collection<String> ids)通过 ID 从存储中删除多个EmbeddingEmbeddingStore.removeAll(Filter)从存储中删除与指定Filter匹配的所有EmbeddingEmbeddingStore.removeAll()从存储中删除所有Embedding
官方
ElasticsearchEmbeddingStore
的存储使用示例:
public class ElasticsearchEmbeddingStoreExample {
public static void main(String[] args) throws InterruptedException {
try (ElasticsearchContainer elastic = new ElasticsearchContainer("docker.elastic.co/elasticsearch/elasticsearch:8.9.0")
.withEnv("xpack.security.enabled", "false")) {
elastic.start();
EmbeddingStore<TextSegment> embeddingStore = ElasticsearchEmbeddingStore.builder()
.serverUrl("http://" + elastic.getHttpHostAddress())
.dimension(384)
.build();
EmbeddingModel embeddingModel = new AllMiniLmL6V2EmbeddingModel();
TextSegment segment1 = TextSegment.from("I like football.");
Embedding embedding1 = embeddingModel.embed(segment1).content();
embeddingStore.add(embedding1, segment1);
TextSegment segment2 = TextSegment.from("The weather is good today.");
Embedding embedding2 = embeddingModel.embed(segment2).content();
embeddingStore.add(embedding2, segment2);
Thread.sleep(1000); // to be sure that embeddings were persisted
Embedding queryEmbedding = embeddingModel.embed("What is your favourite sport?").content();
List<EmbeddingMatch<TextSegment>> relevant = embeddingStore.findRelevant(queryEmbedding, 1);
EmbeddingMatch<TextSegment> embeddingMatch = relevant.get(0);
System.out.println(embeddingMatch.score()); // 0.81442887
System.out.println(embeddingMatch.embedded().text()); // I like football.
}
}
}
Embedding Store Ingestor 嵌入存储摄取器
EmbeddingStoreIngestor
表示摄取管道,负责将
Document
摄取到
EmbeddingStore
中。
在最简单的配置中,
EmbeddingStoreIngestor
使用指定的
EmbeddingModel
嵌入提供的
Document
,并将它们及其
Embedding
存储在指定的
EmbeddingStore
:
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
.embeddingModel(embeddingModel)
.embeddingStore(embeddingStore)
.build();
ingestor.ingest(document1);
ingestor.ingest(document2, document3);
ingestor.ingest(List.of(document4, document5, document6));
一般在使用
EmbeddingStoreIngestor
之前会使用
DocumentTransformer
对
Document
进行清理、丰富或格式化,有助于后续在向量提取的时候效果更好。
官方示例:
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
// adding userId metadata entry to each Document to be able to filter by it later
.documentTransformer(document -> {
document.metadata().put("userId", "12345");
return document;
})
// splitting each Document into TextSegments of 1000 tokens each, with a 200-token overlap
.documentSplitter(DocumentSplitters.recursive(1000, 200, new OpenAiTokenizer()))
// adding a name of the Document to each TextSegment to improve the quality of search
.textSegmentTransformer(textSegment -> TextSegment.from(
textSegment.metadata("file_name") + "\n" + textSegment.text(),
textSegment.metadata()
))
.embeddingModel(embeddingModel)
.embeddingStore(embeddingStore)
.build();
documentTransformer: 它为每个文档添加了一个userId的元数据项,值为"12345"。这意味着无论处理多少文档,所有文档都将被标记为属于同一个用户ID。这在需要按用户过滤结果时非常有用。documentSplitter: 分割器以1000个令牌为单位进行分割,但每个片段之间会有200个令牌的重叠。这有助于确保在搜索时,即使查询文本落在片段边界附近,也能检索到相关的文本片段。textSegmentTransformer: 它将每个文本片段的原始文本与其file_name元数据项的值(文件名)相结合,中间用换行符分隔。这样做的目的是在搜索时,不仅考虑文本片段的内容,还考虑它所属的文档(或文件)的名称,这可能会提高搜索的相关性。
版权归原作者 Box_clf 所有, 如有侵权,请联系我们删除。