
分析项目需求
黑客打开这个攻击系统后,首先看到的就是一个“功能菜单”。
以便让黑客选择所需要的功能。
假设需求如下:
1.网站404攻击
2.网站篡改攻击
3.网站攻击记录
4.DNS攻击
5.服务器重启攻击
项目实现
创建一个空项目CP1
添加文件admin.c
#include <iostream>
#include <Windows.h>
/*1.网站404攻击
2.网站篡改攻击
3.网站攻击记录
4.DNS攻击
5.服务器重启攻击*/
int main(void)
{
std::cout << "1.网站404攻击" << std::endl;
std::cout << "2.网站篡改攻击" << std::endl;
std::cout << "3.网站攻击记录" << std::endl;
std::cout << "4.DNS攻击" << std::endl;
std::cout << "5.服务器重启攻击" << std::endl;
system("pause");return 0;
}
运行结果:

执行方式1(开发时使用)
使用调试模式执行:再单击按钮 
执行方式 2
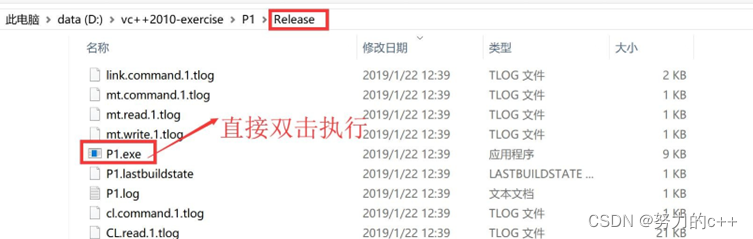
直接双击运行调试模式下的可执行文件:

执行方式 3
使用发布模式:
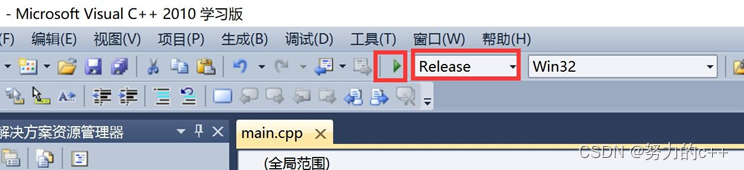
最后直接运行:
执行方式 4
直接运行发布模式下编译后的可执行文件:
发布模式和调试模式的区别:
调试模式中会生成很多调试信息,便于排查错误,但是对执行效率有影响。 确认程序正确后,使用发布模式生成可执行文件。
下面对于初学者c++的基础语法:
原始的规则:
各“语法单位”(组成部分)使用任意个(至少 1 个)分隔符隔开。分隔符有:空格,或 tab 键,或换行符。
int main(void) int main(void) (以上两个都是合法的) intmain(void) (是非法的) 2.必须使用英文输入法输入(仅双引号括起来的“字符串”中可使用中文) 3.每条代码的后面使用 ;表示这个指令代码结束。 4.#include 等预处理指令,必须一条指令占一行 其他规则不需记忆,在后面的项目实践中掌握。
头文件的使用:
程序中有很多元素(std::cout, system), 都是一个个演员。但是他们之间都互不认识, 但是却要一起合作, 强行编译, 就会导致错误! 得预先介绍他们, 知道他们各自的名号和用法
解决方案:
包含相应的头文件! (头文件中, 含有相关元素的介绍说明)
std::cout 头文件: iostream
system 头文件: Windows.h
#include <Windows.h> 表示把文件 Windows.h 中的所有内容拷贝(复制)到“这里”。
头文件的查找路劲
#include <Windows.h>
<>表示,从编译器默认的路径中去找文件 stdio.h
这个默认路径,取决于编译器。不同平台下不同编译器的路径都不相同。 这个默认路径下,已经包含了 c 标准库所需要的所有头文件。
使用 C++标准库的头文件使用该方式。
#include “mytest.h”
“”表示从当前目录下寻找文件 mytest.h
如果在当前目录下找不到,再从编译器默认的路径中查找。
使用用户自定义的头文件使用该方式。
头文件的位置
要求放在文件的最前面。
#include 的作用是,把相关的声明拷贝到这个文件内, 所以都习惯把#include 放到文件的最前面。
如果放到后面,当 include 之前出现了相关的函数,就会有问题,例如
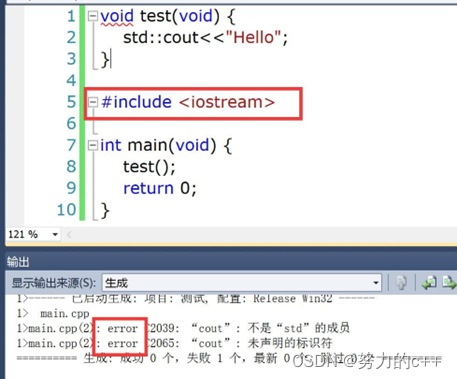
** main函数的介绍:**
每个软件也各不相同,包含不同的函数,但是都是从 main 函数开始:
main 函数的要求:
- 返回类型
- 参数
- 返回值
main函数的作用:
main 函数是程序的唯一入口。
也就是说,程序运行时,首先从 main 函数开始执行。
一个程序,必须要有一个 main 函数,而且也只能有一个 main 函数。
main函数的格式:
格式 1:
int main(void) {
}
格式 2:
具体用法在后面的函数部分,再详细讲解
int main(int argc , char* argv) {
}
main 函数的返回值
main 函数应该用 return 返回一个 int 类型数据,也就是说,必须返回一个整数。一般用法:
程序成功结束,则 main 函数返回 0
程序有异常,则返回一个大于 0 的整数。
字符串常量介绍:
字符串常量:内容永远不会发生变化的字符串。
字符串常量:用半角(英文输入法)双引号“”括起来。
常量和变量的区别?
常量:在程序整个运行期间,值不会发生任何变化。 变量:在程序整个运行期间,值随时可以发生变化。
在c语言/c++中的输出语句使用:
C++风格的打印:
实例:
std::cout << “hello! world” ;
std::cout << hello! world.” << std::endl;
使用要求:
需要包含头文件 #include <iostream>
注意不是#include <iostream.h>
std 是一个命名空间。
cout 是 std 命名空间内的一个“对象”。
endl 也是 std 命名空间内的一个对象,用来表示“回车符”(换到下一行的最前面)
对象:先简单的理解为一个具体的实体。
std::cout << 相当于调用了一个特殊的函数(但不是函数),用来打印数据。
std::cout, 可以连续输出任意多个数据,中间用 << 隔开。
C 风格的打印:
实例:
printf(“工资:%d”, 30000);
printf(“工资:%d 年假:%d”, 30000, 12);
printf(“%f”, 3.1415);
printf(“圆周率:%f”, 3.1415);
说明:
占位符的使用
%d 整数,%f 浮点数(带小数部分的数据)
使用要求: 需要包含头文件 #include <stdio.h>
特别注意:
std::cout 和 printf 还有很多用法,现在只需要掌握以上最常用的用法,其他的用法现在不需要关注。
打印语句的使用场合:
‘打印’常常指:把信息输出到“标准输出设备”(标准输出设备,就是显示器中的“终端”)。
- 控制台应用程序的输出
- 程序调试 Bug 的重要手段
C++避免名字冲突:使用命名空间
使用命名空间。
用法1:
#include <iostream> #include <string>
namespace China {
float population = 14.1;
std::string capital = "北京";
}
namespace Japan {
float population = 1.27;
std::string capital = "东京";
}
using namespace Japan; int main(void) {
std::cout << " 首都:" << capital << std::endl; std::cout << "人口:" << population << std::endl;
std::cout << " 首都:" << China::capital << std::endl; std::cout << "人口:" << China::population << std::endl;
system("pause"); return 0;
}
用法2:
#include <iostream> #include <string>
namespace China {
float population = 14.1; //单位: 亿
std::string capital = "北京";
}
namespace Japan {
float population = 1.27; //单位: 亿
std::string capital = "东京";
}
//注意:没有namespace
//直接指定命名空间中的标识符,而不是整个域名using China::capital;
using Japan::population;
int main(void) {
std::cout << " 首都:" << capital << std::endl;
std::cout << "人口:" << population << std::endl;
system("pause");
return 0;
}
用法3:
#include <iostream> #include <string>
namespace China {
float population = 14.1; //单位: 亿
std::string capital = "北京";
}
namespace Japan {
float population = 1.27; //单位: 亿
std::string capital = "东京";
}
using namespace China; using Japan::population;
int main(void) {
std::cout << "首都:" << capital << std::endl;
std::cout << "人口:" << population << std::endl; //出错!
system("pause");
return 0;
}
错误提示:
population”: 不明确的符号
错误原因:

解决方案:
指定完整的域名(Japan::population )来表示。
......
int main(void) {
std::cout << "首都:" << capital << std::endl;
std::cout << "人口:" << Japan::population << std::endl; //出错!
system("pause");
return 0;
}
c++的编译过程:
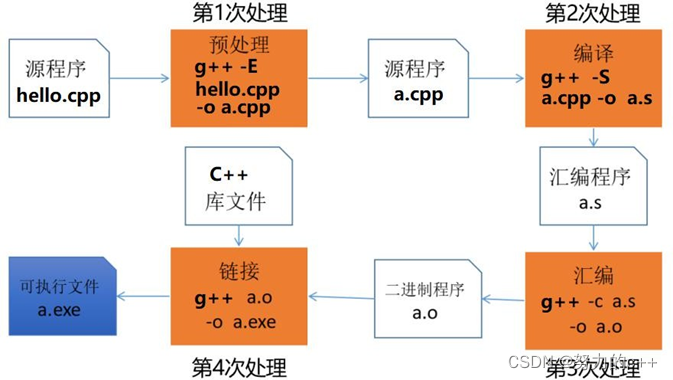
** 程序注释:**
注释的目的:
为了让程序更方便阅读(“可读”),以便于维护。
需要注释的内容:
- 重要变量名的作用(用来表示什么)
- 比较复杂的算法思想
- 程序中的关键步骤
注释的方式
有两种注释方式
单行注释 //
在行尾,或代码的上一行 在代码的下一行也可以,但很少有人这么做。 2.多行注释 /* */不支持嵌套。 3.不要为了注释而注释! 过多的注释,反而有害!会把真正需要注意的东西淹没。 注释的风格:在行尾注释 使用//注释
在代码的上一行使用//注释
多方内容的注释,使用 /* */
函数的注释
常见错误总结
错误 1:VS 的中文乱码问题
VS 最知名的错误(被程序员吐槽最多的 BUG)。
VS 支持多种中文编码,但是使用不当时,常常导致中文乱码,而且难以解决。
中文乱码的原因:
- 中文在不同编码格式下, 存储的方式不一样.
- 如果程序是A 编码方式编译运行的,但是控制台却是以B 编码方式来显示, 就会出现乱码.
- vs 的控制台默认编码是 GB2312,编号号是 836
注意:GBK 编码是兼容 GB2312 的,一般描述 GBK 常常就是指 BG2312
如果源代码文件的编码如果是其他编码格式, 就会导致中文乱码.
正常场景:
在 vs 中新建文件时,该文件默认都是 GB2312 编码.
因为控制台默认也是 GB2312 编码,所以一般情况下,都不会出现中文乱码.
错误场景:
- 直接在项目中导入了其他已经创建好的源代码文件,
如果该文件不是 BG2312 编码, 而且含有中文的话, 就必定会出现中文乱码.
- 从其他文件中复制代码到 vs 的文件中, 也可能导致编码错乱.
- 网络编程中, 和服务器交互通信, 两端的编码很可能不同.
我们的”黑客攻击系统”的服务端木马, 就是 UTF-8 编码格式的.
解决方案一: 修改文件的编码
修改源代码文件的”编码格式”, 使其和控制台的编码格式保持一致.
代码文件的编码格式,可以通过 vs 很方便的修改: 先用 vs 打开对应的文件, 然后如下操作:


解决方案二: 强制指定文件执行
#pragma execution_character_set("gbk")
不修改文件的编码, 而是直接指定程序执行时使用的编码, 使其和运行程序的控制台的编码一致.
解决方案三: 修改控制台的编码格式
修改 vs 控制台的编码, 使其和源代码的编码保持一致. 修改注册表, 可以修改控制台的编码格式.
注意:
不建议使用该方式.
因为, 把控制台的默认编码改为其他编码后, 在该控制台输入中文, 很可能导致输入的中文
无法识别.
在 vs2010 中存在该问题.
解决方案四: 对数据进行编码转换
适用于: 服务器端和客户端, 或多个客户端之间的编码不一致时.
- 收到对方的其他编码数据时, 先使用特定的接口来进行编码转换.
- 发送本地数据给对方之前, 先使用特定的接口来进行编码转换.
错误 2:360 报告病毒
项目执行时,360 安全卫士报告病毒,程序被拦截,提示如下:
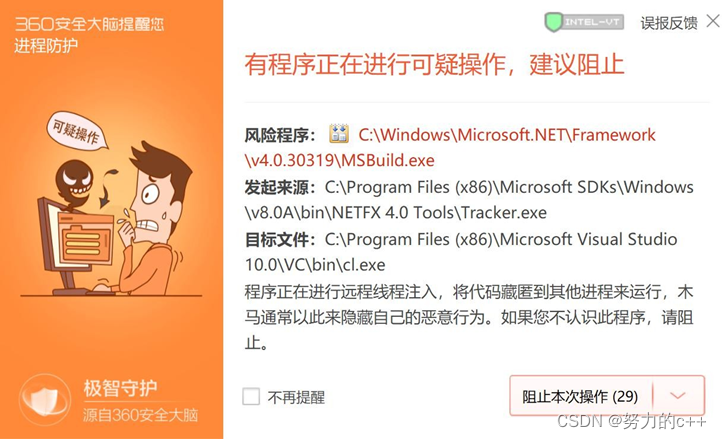
解决方法:
方法 1. 关闭 360
方式 2. 在 360 中添加白名单。
错误 3:代码正确,但是无法通过编译
代码看不出错误,而且报错信息莫名其妙,则很可能是因为代码使用全角字符方式输入的。 特别是各种符号,比如双引号,圆括号,分号等。
其他错误:
LINK : fatal error LNK1561: 必须定义入口点
原因:没有 main 函数,或者 main 函数的 main 写错了
下篇介绍:主要该程序的主要编写
版权归原作者 会飞的鱼-blog 所有, 如有侵权,请联系我们删除。