
前言
在实际开发中,需要做数据同步的场景是非常多的,比如不同的应用之间不想直接通过RPC的方式进行数据交互,或者说下游应用需要检测来自上游应用的某些业务指标数据的变化时,这些都可以考虑使用数据同步的方式完成;
数据同步通常分为离线同步,和准实时同步,以同步mysql数据为例,当下游应用需要通过监控上游的mysql某个表的数据变化来完成自身的业务时,数据同步的实现方式可以有很多种,比如通过canal的方式在应用层做监控,这也是比较常用的一种方式;
在大数据场景下,我们可以考虑另一种方式,即Flink CDC,这也是一种比较通用的数据同步解决方案;
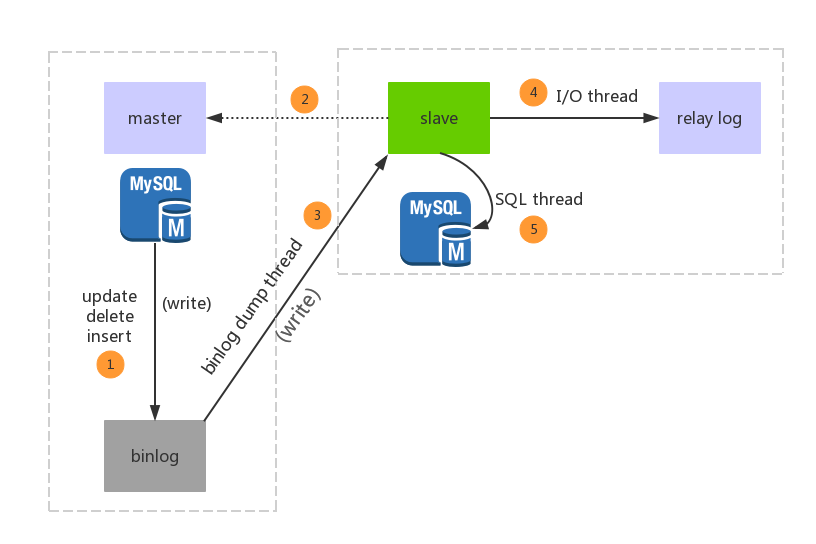
不管是使用哪种方式,其底层的核心原理都是通过监控mysql的binlog的日志变化,从而进行日志解析,得到变化的数据;
下面通过Flink CDC提供的2种常用的数据同步方式,演示下如何使用Flink CDC同步mysql的数据,github配置参考地址:https://github.com/ververica/flink-cdc-connectors
前置准备
1、安装并启动mysql服务,并开启binlog;
注意,这里的: binlog_format一定要选择为 row的模式
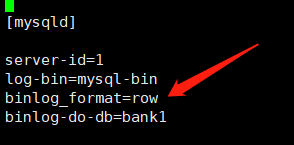
从上面的配置可以看到,这里监控的是bank1这个数据库,为了方便后面演示,提前创建一张测试使用的表,建表sql如下:
CREATE TABLE `record`(`id` varchar(12) DEFAULT NULL,
`name` varchar(22) DEFAULT NULL,
`version` int(12) DEFAULT NULL
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
2、导入代码需要的依赖
<dependencies><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>1.12.0</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java_2.12</artifactId><version>1.12.0</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients_2.12</artifactId><version>1.12.0</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.1.3</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.49</version></dependency><dependency><groupId>com.alibaba.ververica</groupId><artifactId>flink-connector-mysql-cdc</artifactId><version>1.2.0</version></dependency><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.75</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-planner-blink_2.12</artifactId><version>1.12.0</version></dependency></dependencies>
一、DataStream 方式的实现mysql数据同步
官方提供了几种关于mysql数据同步的实现,其中DataStream 的方式使用起来非常灵活,可以监控一个库,也可以监控多个库,下面直接贴出核心的代码
importcom.alibaba.ververica.cdc.connectors.mysql.MySQLSource;importcom.alibaba.ververica.cdc.connectors.mysql.table.StartupOptions;importcom.alibaba.ververica.cdc.debezium.DebeziumSourceFunction;importcom.alibaba.ververica.cdc.debezium.StringDebeziumDeserializationSchema;importorg.apache.flink.streaming.api.datastream.DataStreamSource;importorg.apache.flink.streaming.api.environment.StreamExecutionEnvironment;publicclassCdcTest1{publicstaticvoidmain(String[] args)throwsException{//1.创建执行环境StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);//2、连接mysql数据源DebeziumSourceFunction<String> sourceFunction =MySQLSource.<String>builder().hostname("IP").port(3306).username("root").password("root").databaseList("bank1").tableList("bank1.record").startupOptions(StartupOptions.initial()).deserializer(newStringDebeziumDeserializationSchema()).build();//3、添加到envDataStreamSource<String> streamSource = env.addSource(sourceFunction);//打印输出
streamSource.print();
env.execute("flinkCdc");}}
运行这段代码,观察控制台日志输出,可以看到已经就绪,准备监控表的数据变化

测试1:给record表新插入一条数据,可以看到,控制台很快输出了数据变化的日志信息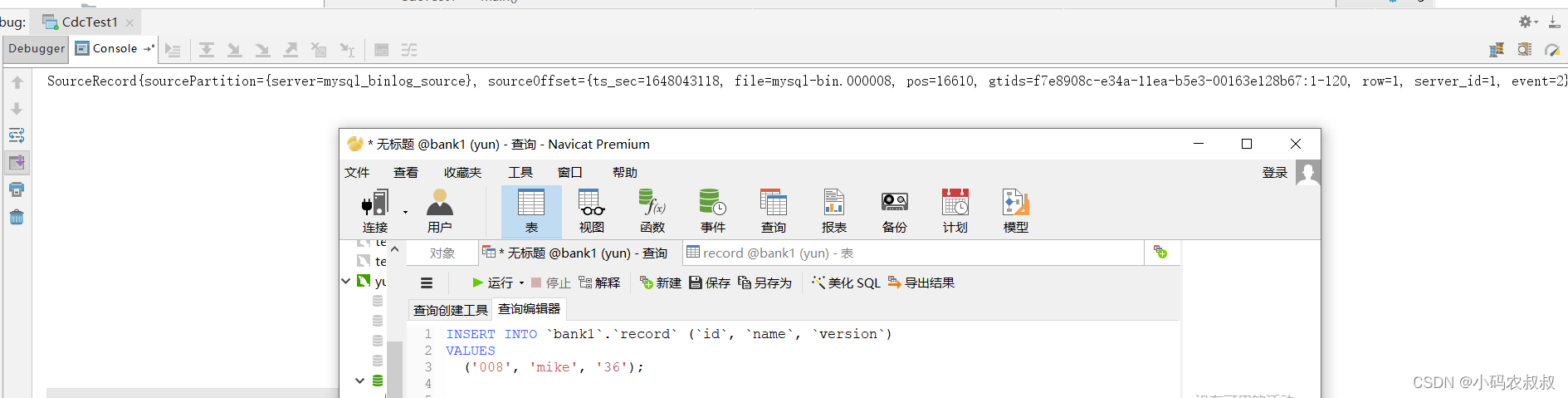
我们贴出完整的日志,后面还会对这段日志做一下说明
SourceRecord{sourcePartition={server=mysql_binlog_source}, sourceOffset={ts_sec=1648043118, file=mysql-bin.000008, pos=16610, gtids=f7e8908c-e34a-11ea-b5e3-00163e128b67:1-120, row=1, server_id=1, event=2}} ConnectRecord{topic='mysql_binlog_source.bank1.record', kafkaPartition=null, key=null, keySchema=null, value=Struct{after=Struct{id=008,name=mike,version=36},source=Struct{version=1.4.1.Final,connector=mysql,name=mysql_binlog_source,ts_ms=1648043118000,db=bank1,table=record,server_id=1,gtid=f7e8908c-e34a-11ea-b5e3-00163e128b67:121,file=mysql-bin.000008,pos=16739,row=0,thread=152},op=c,ts_ms=1648043119363}, valueSchema=Schema{mysql_binlog_source.bank1.record.Envelope:STRUCT}, timestamp=null, headers=ConnectHeaders(headers=)}
测试2:删除一条数据,很快检测到了数据的变化并输出到控制台中

FlinkSQL 方式实现数据同步
官方还提供了另一种基于FlinkSQL 的实现,下面贴出核心的代码
importorg.apache.flink.api.java.tuple.Tuple2;importorg.apache.flink.streaming.api.datastream.DataStream;importorg.apache.flink.streaming.api.environment.StreamExecutionEnvironment;importorg.apache.flink.table.api.Table;importorg.apache.flink.table.api.bridge.java.StreamTableEnvironment;importorg.apache.flink.types.Row;publicclassCdcTest2{publicstaticvoidmain(String[] args)throwsException{//1.创建执行环境StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);StreamTableEnvironment tableEnv =StreamTableEnvironment.create(env);//2.创建 Flink-MySQL-CDC 的 Source
tableEnv.executeSql("CREATE TABLE user_info1 ("+" id STRING NOT NULL,"+" name STRING NOT NULL,"+" version INTEGER NOT NULL"+") WITH ("+" 'connector' = 'mysql-cdc',"+" 'hostname' = 'IP',"+" 'port' = '3306',"+" 'username' = 'root',"+" 'password' = 'root',"+" 'database-name' = 'bank1',"+" 'table-name' = 'record'"+")");//tableEnv.executeSql("select * from user_info1").print();Table table = tableEnv.sqlQuery("select * from user_info1");DataStream<Tuple2<Boolean,Row>> retractStream = tableEnv.toRetractStream(table,Row.class);//结果打印输出
retractStream.print();
env.execute("flinkCdcSql");}}
简单解释下这段代码中的那段sql的含义,即通过一个sql创建一张表,这张表可以理解为一张逻辑上的表,用于检测数据库中的那张物理表 record的数据变化,当record表数据发生变化的时候,将会同步到usr_info1这张表中,那么程序就可以读取到usr_info1的数据了;
启动上面的程序,观察控制台日志输出,此时可以看到,监控已经就绪;
下面给record表插入一条数据,几乎是实时的检测到了数据变化并输出到控制台中
再尝试删除一条数据

自定义反序列化器
在上面的控制台输出日志中,我们发现了一个问题,就是使用DataStream 方式的实现尽管比较灵活和方便,但是输出到控制台的日志其实并不是很直观,下面是截取的完整控制台日志

了解程序的同学可能还能大概看得懂日志要表达的意思,但这种日志对应用来说,解析的时候相当不方便,那该怎么办呢?
举例来说,如果当前的程序需要将这段日志输出到kafka,为下游的某个应用使用,这对于下游应用来说将会很不友好,还需要花费很多功夫去搞清楚日志里面内容的含义才能知道数据是怎么变化的;
Flink CDC 提供了一种叫做自定义序列化的方式,通过编写自定义序列化的代码,完成我们的解析目标;
1、自定义反序列化类
实现DebeziumDeserializationSchema接口,然后重写里面的方法,在重写的方法里面完成日志的解析工作;
importcom.alibaba.fastjson.JSONObject;importcom.alibaba.ververica.cdc.debezium.DebeziumDeserializationSchema;importio.debezium.data.Envelope;importorg.apache.flink.api.common.typeinfo.TypeInformation;importorg.apache.flink.util.Collector;importorg.apache.kafka.connect.data.Field;importorg.apache.kafka.connect.data.Struct;importorg.apache.kafka.connect.source.SourceRecord;publicclassMyDeserializationimplementsDebeziumDeserializationSchema<String>{/**
* 期望的数据格式
* {
* "database" : "",
* "tableName" : "",
* "type" : "crud",
* "before" :"",
* "after" : "",
* //time :
* }
* @param sourceRecord
* @param collector
* @throws Exception
*/@Overridepublicvoiddeserialize(SourceRecord sourceRecord,Collector<String> collector)throwsException{//获取主题信息,包含着数据库和表名String topic = sourceRecord.topic();String[] arr = topic.split("\\.");String db = arr[1];String tableName = arr[2];//获取操作类型 READ DELETE UPDATE CREATEEnvelope.Operation operation =Envelope.operationFor(sourceRecord);//获取值信息并转换为 Struct 类型Struct value =(Struct) sourceRecord.value();//得到变化后的数据Struct after = value.getStruct("after");//创建 JSON 格式的数据对象用于存储数据信息JSONObject data =newJSONObject();for(Field field : after.schema().fields()){Object o = after.get(field);
data.put(field.name(), o);}//创建 JSON 格式的数据对象,用于封装最终返回值数据信息JSONObject result =newJSONObject();
result.put("operation", operation.toString().toLowerCase());
result.put("data", data);
result.put("database", db);
result.put("table", tableName);//发送数据给下游
collector.collect(result.toJSONString());}@OverridepublicTypeInformation<String>getProducedType(){returnTypeInformation.of(String.class);}}
2、在核心代码中使用自定义的反序列化器
importcom.alibaba.ververica.cdc.connectors.mysql.MySQLSource;importcom.alibaba.ververica.cdc.connectors.mysql.table.StartupOptions;importcom.alibaba.ververica.cdc.debezium.DebeziumSourceFunction;importcom.alibaba.ververica.cdc.debezium.StringDebeziumDeserializationSchema;importorg.apache.flink.api.java.tuple.Tuple2;importorg.apache.flink.streaming.api.datastream.DataStream;importorg.apache.flink.streaming.api.datastream.DataStreamSource;importorg.apache.flink.streaming.api.environment.StreamExecutionEnvironment;importorg.apache.flink.table.api.Table;importorg.apache.flink.table.api.bridge.java.StreamTableEnvironment;importorg.apache.flink.types.Row;importjava.util.Properties;publicclassCdcTest3{publicstaticvoidmain(String[] args)throwsException{//1.创建执行环境StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);StreamTableEnvironment tableEnv =StreamTableEnvironment.create(env);DebeziumSourceFunction<String> sourceFunction =MySQLSource.<String>builder().hostname("IP").port(3306).username("root").password("root").databaseList("bank1").tableList("bank1.record").startupOptions(StartupOptions.initial()).deserializer(newMyDeserialization()).build();DataStreamSource<String> streamSource = env.addSource(sourceFunction);
streamSource.print();
env.execute("flinkCdc");}}
运行上面的程序,可以看到此时已经就绪
下面给record表添加一条数据
接下来再修改一条数据
通过控制台的打印日志可以发现,通过自定义的反序列化器得到的数据更方便阅读,以及后续数据的传输;
版权归原作者 小码农叔叔 所有, 如有侵权,请联系我们删除。