
1.socket简介
socket(简称 套接字) 是进程间通信的一种方式,它与其他进程间通信的一个主要不同是:它能实现不同主机间的进程间通信。
创建socket
在 Python 中 使用socket 模块的函数 socket 就可以完成:
import socket
socket.socket(AddressFamily, Type)
函数 socket.socket 创建一个 socket,该函数带有两个参数:
- Address Family:可以选择 AF_INET(用于 Internet 进程间通信) 或者 AF_UNIX(用于同一台机器进程间通信),实际工作中常用AF_INET
- Type:套接字类型,可以是 SOCK_STREAM(流式套接字,主要用于 TCP 协议)或者 SOCK_DGRAM(数据报套接字,主要用于 UDP 协议)
(1) 创建一个tcp socket(tcp套接字)
import socket
# 创建tcp的套接字
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)# ...这里是使用套接字的功能(省略)...# 不用的时候,关闭套接字
s.close()
(2) 创建一个udp socket(udp套接字)
import socket
# 创建udp的套接字
s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)# ...这里是使用套接字的功能(省略)...# 不用的时候,关闭套接字
s.close()
2. udp发送与接收数据
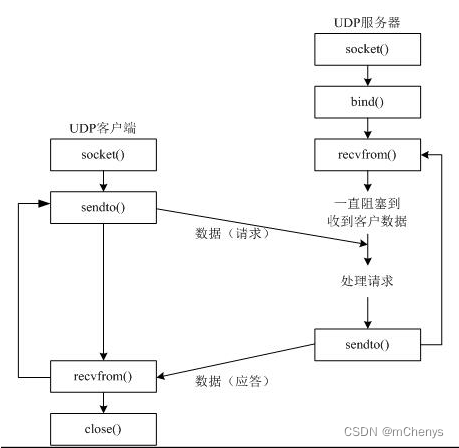
(1) 创建upd服务端
新建udp_receive.py
import socket
# 服务端
udp_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)# bind接收一个元组,用于绑定本地的ip地址和端口号,ip如果''则会绑定本机的任意一个ip, 端口如果不指定,系统会随机分配# 127.0.0.1为本地回环地址
udp_socket.bind(('127.0.0.1',1234))print("服务端已开启")whileTrue:# 接收数据, 本次接收最大支持64kb, 得到一个元组
recv_data = udp_socket.recvfrom(64*1024)# 第1个元素是对方发送的数据, 需要先解码
data = recv_data[0].decode('utf-8')# 第二个元素也是一个元组,保存了对方的ip和端口号
who = recv_data[1]print(f"收到数据:{data}{who}")if data =="bye":break
udp_socket.close()
(2) 创建udp客户端
新建udp_send.py
import socket
# 创建客户端
udp_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)whileTrue:
send_data =input("请输入要发送的数据:")# 发送数据
udp_socket.sendto(send_data.encode("utf-8"),('127.0.0.1',1234))if send_data =="bye":break
udp_socket.close()
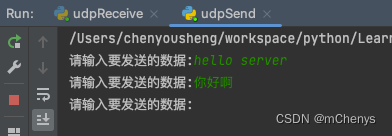
先运行服务端, 再运行客户端, 客户端这边发送消息, 服务端这边接收消息, 效果如下: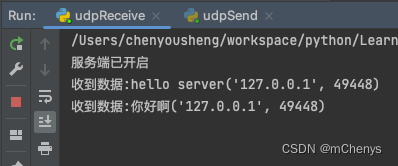
关于编码转换
字符串通过编码成为字节码,字节码通过解码成为字符串。
str->bytes: encode编码
bytes->str: decode解码
3.TCP简介
TCP协议,传输控制协议(Transmission Control Protocol,缩写为 TCP)是一种面向连接的、可靠的、基于字节流的传输层通信协议,由IETF的RFC 793定义。
TCP通信需要经过创建连接、数据传送、终止连接三个步骤。
TCP具有以下特点:
面向连接 通信双方必须先建立连接才能进行数据的传输,双方都必须为该连接分配必要的系统内核资源,以管理连接的状态和连接上的传输。 双方间的数据传输都可以通过这一个连接进行。 完成数据交换后,双方必须断开此连接,以释放系统资源。 这种连接是一对一的,因此TCP不适用于广播的应用程序,基于广播的应用程序请使用UDP协议。
可靠传输 - TCP采用发送应答机制: TCP发送的每个报文段都必须得到接收方的应答才认为这个TCP报文段传输成功- 超时重传: 发送端发出一个报文段之后就启动定时器,如果在定时时间内没有收到应答就重新发送这个报文段。TCP为了保证不发生丢包,就给每个包一个序号,同时序号也保证了传送到接收端实体的包的按序接收。然后接收端实体对已成功收到的包发回一个相应的确认(ACK);如果发送端实体在合理的往返时延(RTT)内未收到确认,那么对应的数据包就被假设为已丢失将会被进行重传。- 错误校验: TCP用一个校验和函数来检验数据是否有错误;在发送和接收时都要计算校验和。- 流量控制和阻塞管理: 流量控制用来避免主机发送得过快而使接收方来不及完全收下。
4. tcp发送与接收数据
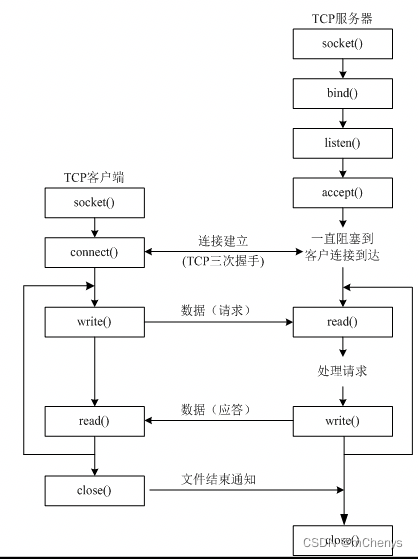
(1) 创建TCP客户端
新建tcp_send.py
import socket
# 创建一个客户端的socket对象
client = socket.socket(socket.AF_INET, socket.SOCK_STREAM)# 设置要连接的服务端的ip和端口
client.connect(('127.0.0.1',1246))# while循环是为了保证能持续进行对话whileTrue:# 输入发送的消息
sendmsg =input("请输入要发送的内容:")# 发送数据,以二进制的形式发送数据,所以需要进行编码
client.send(sendmsg.encode("utf-8"))# 如果客户端输入的是q,则停止对话并且退出程序if sendmsg =='q':break
msg = client.recv(1024)# 接收服务端返回的数据,需要解码print('收到服务端的回应:', msg.decode("utf-8"))# 关闭客户端
client.close()
(2) 创建TCP服务端
新建tcp_receive.py
import socket
# 创建服务端的socket对象socketserver
socketserver = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
host ='127.0.0.1'
port =1246# 绑定地址(包括ip地址会端口号)
socketserver.bind((host, port))# 设置监听
socketserver.listen(5)# 等待客户端的连接# 注意:accept()函数会返回一个元组, 元素1为客户端的socket对象,元素2为客户端的地址(ip地址,端口号)
client_socket, addr = socketserver.accept()# while循环是为了能让对话一直进行,直到客户端输入qwhileTrue:# 接收客户端数据, 阻塞方法
recvmsg = client_socket.recv(1024)# 把接收到的数据进行解码
strData = recvmsg.decode("utf-8")print(f"收到来自{addr}的消息:"+ strData)# 判断客户端是否发送q,是就退出此次对话if strData =='q':break
client_socket.send("已送达".encode("utf-8"))
socketserver.close()
效果图:

注意:
- tcp服务器一般情况下都需要绑定,否则客户端找不到这个服务器
- tcp客户端一般不绑定,因为是主动连接服务器,所以只要确定好服务器的ip、port等信息就好
- tcp服务器通过listen可以将socket创建出来的主动套接字变为被动的,这是做tcp服务器时必须要做的
- 当客户端需要链接服务器时,就需要使用connect进行连接,udp是不需要连接的而是直接发送,但是tcp必须先连接,只有连接成功才能通信
- 当一个tcp客户端连接服务器时,服务器端会有1个新的套接字,这个套接字用来标记这个客户端,单独为这个客户端服务
- listen后的套接字是被动套接字,用来接收新的客户端的链接请求的,而accept返回的新套接字是标记这个新客户端的
- 关闭listen后的套接字意味着被动套接字关闭了,会导致新的客户端不能够连接服务器,但是之前已经连接成功的客户端正常通信。
- 关闭accept返回的套接字意味着这个客户端已经服务完毕
- 当客户端的套接字调用close后,服务器端会recv解堵塞,并且返回的长度为0,因此服务器可以通过返回数据的长度来区别客户端是否已经下线
5. tcp文件下载实现
客户端连接上服务端后, 输入要下载的文件名, 文件存在则开始下载, 不存在则返回错误, 效果图如下:
下载成功:
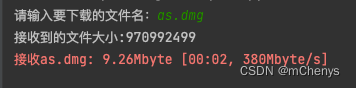
下载失败: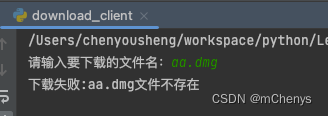
(1) 实现思路
- 客户端 - 通过connect指定的ip和端口连接到服务端- 获取服务端的rcode和下载的文件大小- 创建文件, 在循环中接收下载的数据, 并更新下载进度- 判断recv接收数据的长度为0则认为下载完毕
- 服务端 - 先绑定ip和端口, 然后再开启listen监听- 在外层循环中accept客户端的接入, 因为服务端支持多个客户端的接入- 读取客户端要下载的文件, 判断是否存在, 存在则通知客户端rcode=0和文件的大小, 否则通知rcode=-1和文件不存在提示- 在子循环通过客户端的socket对象回写文件数据
(2) 代码实现
新建download_client.py文件作为客户端
import socket
import tqdm
# 传输的分隔符
SEPARATOR ='<SEPARATOR>'defmain():# 文件缓冲区
buffer_size =10*1024# 创建socket
tcp_client_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)# 目的信息
server_ip ='127.0.0.1'
server_port =7890# 链接服务器
tcp_client_socket.connect((server_ip, server_port))# 输入需要下载的文件名
file_name =input("请输入要下载的文件名:")# 发送文件下载请求
tcp_client_socket.send(file_name.encode("utf-8"))# 接收rcode和文件大小
recv_data = tcp_client_socket.recv(1024)
rcode, file_size = recv_data.decode('utf-8').split(SEPARATOR)
rcode =int(rcode)if rcode ==0and file_size:
file_size =int(file_size)print(f'接收到的文件大小:{file_size}')# 文件接进度
progress = tqdm.tqdm(file_size,f'接收{file_name}', unit='byte', unit_divisor=buffer_size, unit_scale=True)# 创建接收文件
new_file =open("[接收]"+ file_name,"wb")whileTrue:
recv_data = tcp_client_socket.recv(buffer_size)iflen(recv_data)==0:
new_file.close()break
new_file.write(recv_data)# 更新进度
progress.update(len(recv_data))else:print(f"下载失败:{file_size}")# 关闭套接字
tcp_client_socket.close()if __name__ =="__main__":
main()
新建download_server.py作为服务端
import socket
import os
import sys
# 传输的分隔符
SEPARATOR ='<SEPARATOR>'defmain():iflen(sys.argv)!=2:print("请按照如下方式运行:python3 xxx.py 7890")returnelse:# 运行方式为python3 xxx.py 7890
port =int(sys.argv[1])# 文件缓冲区
buffer_size =4096*10# 创建socket
tcp_server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)# 本地信息
address =('', port)# 绑定本地信息
tcp_server_socket.bind(address)# 将主动套接字变为被动套接字
tcp_server_socket.listen(128)whileTrue:# 等待客户端的链接,即为这个客户端发送文件
client_socket, client_addr = tcp_server_socket.accept()# 接收对方发送过来的数据
recv_data = client_socket.recv(1024)
file_name = recv_data.decode("utf-8")
exist = os.path.exists(file_name)if exist:try:# 获取下载文件的大小
file_size = os.path.getsize(file_name)# 通知状态和大小
client_socket.sendall(f"{0}{SEPARATOR}{file_size}".encode('utf-8'))print("对方请求下载的文件名为:%s"% file_name)
f =open(file_name,'rb')whileTrue:
bytes_read = f.read(buffer_size)iflen(bytes_read)==0:break
client_socket.send(bytes_read)except Exception as result:print(f"服务端异常{result}")finally:# 关闭这个套接字
client_socket.close()else:print("下载的文件不存在")
client_socket.send(f"{-1}{SEPARATOR}{file_name}文件不存在".encode('utf-8'))# 关闭监听套接字
tcp_server_socket.close()if __name__ =="__main__":
main()
6.tcp文件上传实现
文件的上传有点类似下载的逆过程, 效果图如下:

(1) 实现思路
- 客户端 - 通过connect指定的ip和端口连接到服务端- 通知服务端上传的文件名和文件大小- 等待服务端回应, 回应后开始上传文件- 上传完后关闭socket
- 服务端 - 先绑定ip和端口, 然后再开启listen监听- 在外层循环中accept客户端的接入, 因为服务端支持多个客户端的接入- 读取客户端要上传的文件名和大小(不是必要的)- 在子循环通过客户端的socket接收客户端上传的数据,然后写到保存的文件中
(2) 代码实现
新建upload_client.py文件作为客户端
import os.path
import socket
# 传输的分隔符from tqdm import tqdm
SEPARATOR ='<SEPARATOR>'defmain():
client = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
file_name =input("请输入要上传的文件名:")
buffer_size =10*1024
exist = os.path.exists(file_name)if exist:
client.connect(('127.0.0.1',12800))# 先传输要上传的文件名和大小
file_size = os.path.getsize(file_name)
client.send(f"{file_name}{SEPARATOR}{file_size}".encode('utf-8'))# 等待服务端响应
rect = client.recv(1024).decode('utf-8')if rect:print("开始上传")
progress = tqdm(file_size,f'上传{file_name}', unit='byte', unit_divisor=buffer_size, unit_scale=True)
upload_file =open(file_name,'rb')whileTrue:
bytes_read = upload_file.read(buffer_size)if bytes_read:
client.send(bytes_read)
progress.update(len(bytes_read))else:print("上传完毕")break
upload_file.close()
client.close()else:print("服务端未响应")if __name__ =='__main__':
main()
新建upload_server.py作为服务端
import socket
# 传输的分隔符
SEPARATOR ='<SEPARATOR>'defmain():
server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server.bind(('127.0.0.1',12800))
server.listen(128)
buffer_size =10*1024whileTrue:# 等待客户端接入
client, addr = server.accept()
bytes_read = client.recv(buffer_size).decode('utf-8')
file_name, file_size = bytes_read.split(SEPARATOR)print(f"收到文件名:{file_name}, 大小:{file_size}")# 回应客户端可以开始上传了
client.send("ok".encode('utf-8'))# 接收数据file=open(f'[接收]{file_name}','wb')try:"""第一种方式: 利用文件大小来控制传输"""# file_size = int(file_size)# size = 0# while size < file_size:# remain = file_size - size# if remain > buffer_size:# bytes_read = client.recv(buffer_size)# else:# bytes_read = client.recv(remain)# # 保存数据# file.write(bytes_read)# size += len(bytes_read)"""第二种方式, 不需要客户端告知文件大小"""whileTrue:
bytes_read = client.recv(buffer_size)if bytes_read:file.write(bytes_read)else:breakexcept Exception as result:print(f"服务端异常{result}")finally:file.close()
client.close()if __name__ =='__main__':
main()
7. Web静态服务器-显示固定的页面
# coding=utf-8import socket
defhandle_client(client_socket):"为一个客户端进行服务"
recv_data = client_socket.recv(1024).decode("utf-8")
request_header_lines = recv_data.splitlines()# 打印客户端的请求头信息for line in request_header_lines:print(line)# 组织响应 头信息(header)
response_headers ="HTTP/1.1 200 OK\r\n"# 200表示找到这个资源
response_headers +="\r\n"# 用一个空的行与body进行隔开# 组织 内容(body)
response_body ="hello world"
response = response_headers + response_body
client_socket.send(response.encode("utf-8"))
client_socket.close()defmain():
server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)# 设置当服务器先close 即服务器端4次挥手之后资源能够立即释放,这样就保证了,下次运行程序时 可以立即绑定7788端口
server_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR,1)
server_socket.bind(("",7788))
server_socket.listen(128)whileTrue:
client_socket, client_addr = server_socket.accept()
handle_client(client_socket)if __name__ =="__main__":
main()
对于一个socket,可以通过setsockopt方法设置很多不同的选项,对于那些一般用途的服务器,一个最让人感兴趣的socket选项是SO_REUSEADDR,因为在一个服务器进程终止后,操作系统会保留几分钟它的端口,从而防止其他进程(甚至包括本服务器自己的另外一个实例)在超时之前使用这个端口,如果你设置了SO_REUSEADDR的标记为true,操作系统就会在服务器socket被关闭或者服务器进程终止后马上释放该服务器的端口。这样做,可以使调试程序更简单。
运行起来后,在浏览器中输入:http://http://127.0.0.1:7788, 可以看到浏览器显示如下内容: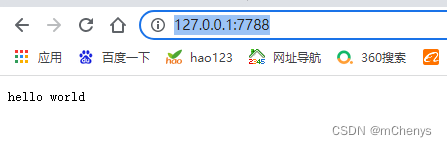
同时,pycharm控制台打印如下内容:
GET / HTTP/1.1
Host:127.0.0.1:7788
Connection: keep-alive
Cache-Control:max-age=0
sec-ch-ua:"Google Chrome";v="107","Chromium";v="107","Not=A?Brand";v="24"
sec-ch-ua-mobile: ?0
sec-ch-ua-platform:"Windows"
Upgrade-Insecure-Requests:1
User-Agent: Mozilla/5.0(Windows NT 10.0; Win64; x64) AppleWebKit/537.36(KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Sec-Fetch-Site: none
Sec-Fetch-Mode: navigate
Sec-Fetch-User: ?1
Sec-Fetch-Dest: document
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
GET /favicon.ico HTTP/1.1
Host:127.0.0.1:7788
Connection: keep-alive
sec-ch-ua:"Google Chrome";v="107","Chromium";v="107","Not=A?Brand";v="24"
sec-ch-ua-mobile: ?0
User-Agent: Mozilla/5.0(Windows NT 10.0; Win64; x64) AppleWebKit/537.36(KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36
sec-ch-ua-platform:"Windows"
Accept: image/avif,image/webp,image/apng,image/svg+xml,image/*,*/*;q=0.8
Sec-Fetch-Site: same-origin
Sec-Fetch-Mode: no-cors
Sec-Fetch-Dest: image
Referer: http://127.0.0.1:7788/
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
8. web静态服务器-按需显示指定的页面
例如在浏览器中输入:http://127.0.0.1:7788/index.html,那么返回的内容就是服务器的index.html的内容。
# coding=utf-8import socket
import re
defhandle_client(client_socket):"为一个客户端进行服务"global response_headers, response_body
recv_data = client_socket.recv(1024).decode('utf-8', errors="ignore")
request_header_lines = recv_data.splitlines()for line in request_header_lines:print(line)
http_request_line = request_header_lines[0]# 从请求头的第一行中获取请求的资源路径 ,例如http://127.0.0.1:7788/index.html ==> /index.html# 请求头第一行是:GET /index.html HTTP/1.1
req_file_name = re.match("[^/]+/([^ ]*)", http_request_line).group(1)print("file name is ===>%s"% req_file_name)# 如果没有指定访问哪个页面。例如index.html# GET / HTTP/1.1if req_file_name =="":
req_file_name ="index.html"try:
f =open(req_file_name,"rb")except IOError:# 404表示没有这个页面
response_headers ="HTTP/1.1 404 not found\r\n"
response_headers +="\r\n"
response_body ="====sorry ,file not found===="else:
response_headers ="HTTP/1.1 200 OK\r\n"
response_headers +="\r\n"# 读取文件的内容,返回给客户端
response_body = f.read()
f.close()finally:# 因为头信息在组织的时候,是按照字符串组织的,不能与以二进制打开文件读取的数据合并,因此分开发送# 先发送response的头信息
client_socket.send(response_headers.encode('utf-8'))# 再发送body
client_socket.send(response_body)
client_socket.close()defmain():"作为程序的主控制入口"
server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR,1)
server_socket.bind(("",7788))
server_socket.listen(128)whileTrue:
client_socket, clien_cAddr = server_socket.accept()
handle_client(client_socket)if __name__ =="__main__":
main()
同时在服务器端根目录下创建index.html
<!DOCTYPEhtml><htmllang="en"><head><metacharset="UTF-8"><title>Title</title></head><body><p>hello world</p></body>
</html
然后浏览器中访问,就可以看到如下内容了: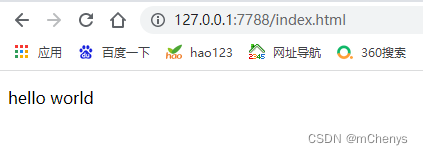
上面的做法每次只能响应一次浏览器的请求,如果想支持多次请求,那么可以使用多进程的方式来实现, 关于进程的内容后面会介绍, 这里先演示.
9. Web静态服务器-多进程响应请求
# coding=utf-8import socket
import re
import multiprocessing
classWSGIServer(object):def__init__(self, server_address):# 创建一个tcp套接字
self.listen_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)# 允许立即使用上次绑定的port
self.listen_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR,1)# 绑定
self.listen_socket.bind(server_address)# 变为被动,并制定队列的长度
self.listen_socket.listen(128)defserve_forever(self):"循环运行web服务器,等待客户端的链接并为客户端服务"whileTrue:# 等待新客户端到来
client_socket, client_address = self.listen_socket.accept()
new_process = multiprocessing.Process(target=self.handle_client, args=(client_socket,))
new_process.start()# 因为子进程已经复制了父进程的套接字等资源,所以父进程调用close不会将他们对应的这个链接关闭的
client_socket.close()defhandle_client(self, client_socket):"为一个客户端进行服务"global response_headers, response_body
recv_data = client_socket.recv(1024).decode('utf-8', errors="ignore")
request_header_lines = recv_data.splitlines()for line in request_header_lines:print(line)
http_request_line = request_header_lines[0]# 请求头第一行是:GET /index.html HTTP/1.1
req_file_name = re.match("[^/]+/([^ ]*)", http_request_line).group(1)print("file name is ===>%s"% req_file_name)# 如果没有指定访问哪个页面。例如index.html# GET / HTTP/1.1if req_file_name =="":
req_file_name ="index.html"try:
f =open(req_file_name,"rb")except IOError:# 404表示没有这个页面
response_headers ="HTTP/1.1 404 not found\r\n"
response_headers +="\r\n"
response_body ="====sorry ,file not found===="else:
response_headers ="HTTP/1.1 200 OK\r\n"
response_headers +="\r\n"# 读取文件的内容,返回给客户端
response_body = f.read()
f.close()finally:# 因为头信息在组织的时候,是按照字符串组织的,不能与以二进制打开文件读取的数据合并,因此分开发送# 先发送response的头信息
client_socket.send(response_headers.encode('utf-8'))# 再发送body
client_socket.send(response_body)
client_socket.close()# 设定服务器的端口
SERVER_ADDR =(HOST, PORT)="",8888defmain():
httpd = WSGIServer(SERVER_ADDR)print("web Server: Serving HTTP on port %d ...\n"% PORT)
httpd.serve_forever()if __name__ =="__main__":
main()
当然除了多进程的方式,也可以使用多线程的方式
10. Web静态服务器-多线程响应请求
基于多进程的方式,修改serve_forever的实现即可
defserve_forever(self):"循环运行web服务器,等待客户端的链接并为客户端服务"whileTrue:# 等待新客户端到来
client_socket, client_address = self.listen_socket.accept()
new_thread = threading.Thread(target=self.handle_client, args=(client_socket,))
new_thread.start()# 因为线程是共享同一个套接字,所以主线程不能关闭,否则子线程就不能再使用这个套接字了# client_socket.close()
版权归原作者 mChenys 所有, 如有侵权,请联系我们删除。