
一、实验目的
1、用KNN实现基于身高和体重的性别预测。通过本实验,加强对K近邻(KNN)算法的基本原理和工作机制的理解。
2、通过实际操作加强Python编程语言的使用能力,包括基本语法、控制结构、函数编写以及数据处理等。
3、熟悉scikit-learn库的使用。scikit-learn是一个强大的机器学习工具包,学习使用scikit-learn构建和训练KNN模型。
二、概要设计
1.机器学习算法简述
本次实验采用的是K近邻(K-Nearest Neighbors,KNN)算法。KNN是一种基于实例的学习方法,属于监督学习算法。它的基本原理是对于一个给定的测试数据点,算法在训练集中找到与之最相近的K个数据点,这些数据点的最频繁标签(在分类任务中)或属性值的平均值(在回归任务中)就被赋予给测试数据点作为预测结果。KNN算法的核心是距离度量(如欧氏距离),K值的选择,以及分类决策规侧。
K-Nearest Neighbors(KNN)是一种简单且常用的分类和回归算法。以下是使用KNN算法时的六个基本步骤:
- 选择K值 确定最近邻的数量K。K的选择会影响算法的结果,常见的做法是通过交叉验证来选择一个最优的K值。
- 距离度量 选择一种方法来量化数据点之间的距离。最常见的距离度量方法是欧氏距离(Euclidean distance),但也可以根据数据的特点选择曼哈顿距离(Manhattan distance)、闵可夫斯基距离(Minkowski distance)等。
- 寻找最近邻 对于每一个测试数据点,计算它与训练集中所有点的距离,然后选择距离最近的K个点作为最近邻。
- 分析邻居 对于分类问题,看这K个最近邻点的类别标签哪个最多,测试点就被分到那个类别。对于回归问题,通常会取这K个最近邻点的目标值的平均值作为预测结果。
- 预测结果 对测试集中的每个数据点重复上述过程,将每个点分到最常见的类别或计算出一个回归结果。
- 模型评估 使用适当的评估指标,例如准确率、混淆矩阵、均方误差等,来评估模型的性能。基于评估结果,可能需要调整K值或考虑其他模型改进方法。
2.训练数据集和测试数据集介绍
在本次实验中,我们使用了一个包含人的身高©、体重(kg)和性别(male/female)的数据集。这个数据集被分为训练集和测试集,训练集用于训练KNN模型,而测试集用于评估模型的性能。为了探究数据量对模型性能的影响,我们尝试了增加训练集和测试集的数据量。此外,我们还考虑了不同的K值对模型预测准确率的影响。数据集的具体介绍如下:
①基于身高和体重的性别预测:
- 训练数据集包含多个样本,每个样本有两个属性:身高©和体重(kg), 以及一个类别标签:性别(male/female)。 身高 158 170 183 191 155 163 180 158 170 168 体重 64 86 84 80 49 59 67 54 67 65 性别 Male male male male female female female female female male
- 测试数据集同样由身高和体重组成,并用于评估模型对性别的预测准确性。 身高 168 180 160 169 体重 65 96 52 67 性别 Male male female female
②基于身高和性别的体重预测:
- 训练数据集同样包括身高和性别属性,但此时目标变量变为体重,这是一个连 续值,因此这部分实验属于回归问题。
- 测试数据集包括身高和性别属性,用于评估模型预测体重的准确性。
3.实验内容介绍
本次实验完成了以下两个内容:
- 基于身高和体重的性别预测- 使用KNN算法根据身高和体重预测性别,这是一个分类任务。我们尝试通过增加 训练集和测试集的数据量来提升模型的预测准确率。- 为了确定最佳的K值,我们尝试了不同的K值,并根据预测结果的准确率选择了最 佳的K值。
- 基于身高和性别的体重预测- 使用KNN算法根据身高和性别预测体重,这是一个回归任务。我们同样尝试通过 增加训川练集和测试集的数据量来提高预测的准确率。- 通过尝试不同的K值,我们评估了不同K值对预测准确率的影响,并选定了最佳K 值。
在这两个实验任务中,我们通过实验验证了KNN算法处理不同类型的预测问题的能力,并且通过增加数据量(训练集和测试集)和调整K值的方法,探索了提高KNN模型性能的策略。
三、详细设计
(1)实验内容一:基于身高和体重的性别预测
- 算法流程介绍: 本程序通过使用KNN算法实现基于身高和体重的性别预测,大致可以分为以下步骤:
- 数据准备与可视化:导入必要的库,准备训练数据并通过散点图进行可视化,以直观地查看数据分布。
- 数据预处理:对性别标签进行二值化处理,将文本标签转换为数值型标签,以便算法处理。
- 模型训练与预测:选择KNN分类器,设置邻居数(K值),用处理过的训练数据训川练模型,并进行预测。
- 结果评估:计算模型在测试集上的准确率,以评估模型性能。
- 模型优化:改变k值、训练集和测试集样本数量,从而来优化模型,提高模型准确率。
代码详细介绍:
- 数据准备与可视化部分 功能:这段代码首先导入数据,并绘制散点图以可视化数据。通过不同的标记(男性为’x,女性为’D),我们可以了解数据的分布情况,从而对后续步聚做更好的决策,比如选择合适的K值。
import numpy as np
from sklearn.preprocessing import LabelBinarizer
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import numpy as np
import matplotlib.pyplot as plt
#画散点图
X_train = np.array([[158,64],[170,86],[183,84],[191,80],[155,49],[163,59],[180,67],[158,54],[170,67],[168,65],[180,96],[160,52],[169,67],[172,68],[174,70],[178,72],[182,74],[186,76],[154,54],[166,60]])
y_train =['male','male','male','male','female','female','female','female','female','male','male','female','female','male','male','male','male','male','female','female']
plt.figure()
plt.title('Human Heights and Weights by Sex')
plt.xlabel('Height in cm')
plt.ylabel('Weight in kg')for i, x inenumerate(X_train):
plt.scatter(x[0], x[1], c='k', marker='x'if y_train[i]=='male'else'D')
plt.grid(True)
plt.show()
- 数据预处理部分 功能:这段代码使用LabelBinarizer对标签进行二值化处理,将类别标签从字符串转换为模型可以处理的数值型标签。这是准备数据的重要一步,确保数据适用于KNN算法。
# 测试数据集
X_test = np.array([[168,65],[180,96],[160,52],[169,67],# 原始测试数据[170,67],[182,74]# 额外测试数据])
y_test =['male','male','female','female',# 原始测试标签'female','male'# 额外测试标签]# 对训练集和测试集进行二值化预处理
lb = LabelBinarizer()
y_train_binarized = lb.fit_transform(y_train)
y_test_binarized = lb.transform(y_test)print('Binarized labels: %s'% y_test_binarized.T[0])
- 模型训练与预测 功能:这段代码首先设置K值为3(通常通过交叉验证选择最佳K值),然后创建KNN分类器,并用二值化后的训练数据来“训练”模型。虽然KNN是一种惰性算法,但这里的训练实际上是将数据存储起来以备后续查询。然后代码对测试数据进行预测。
K =3
clf = KNeighborsClassifier(n_neighbors=K)
clf.fit(X_train, y_train_binarized.reshape(-1))
predictions_binarized = clf.predict(X_test)
- 结果评估 功能:计算模型预测的准确率,评估模型的性能。准确率是预测正确的样本数除以总样本数。这个指标非常直观,是评价分类模型常用的指标之一。
print('Binarized predictions: %s'% predictions_binarized)print('Predicted labels: %s'% lb.inverse_transform(predictions_binarized))# Calculate and print the prediction accuracy as a percentage
accuracy = accuracy_score(y_test_binarized, predictions_binarized)print('Accuracy: {:.2f}%'.format(accuracy *100))
(2)实验内容二:基于身高和性别的体重预测
算法流程介绍:
- 数据可视化:展示数据分布,有助于理解数据特性和后续的K值选择。
- 数据预处理:在这个例子中,性别已经被预处理为二进制特征(男性为1,女性为0),以便算法可以处理。
- 选择K值并训练模型:选择K值,并创建KNN回归模型,然后用训练数据拟合模型。
- 执行预测:使用拟合好的模型对测试数据进行预测。
- 评估模型:使用R²分数来评估模型的性能。
代码详细介绍:
- 数据准备与可视化部分 功能:这段代码首先定义了训练集数据和测试数据,然后使用matplot1ib库绘制原始训练数据的散点图,展示了不同性别的身高和体重分布情况。这有助于我们直观地看到数据的分布,从而为选择K值和理解模型的预测提供直观依据。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsRegressor
from sklearn.metrics import r2_score
#定义训练数据
X_train = np.array([[158,1],# 男性用 1 表示[170,1],[183,1],[191,1],[155,0],# 女性用 0 表示[163,0],[180,0],[158,0],[170,0],[175,1],# 增加的数据点[160,0],[165,1],[172,0],[180,1],[167,0]])
y_train = np.array([64,# 男性体重86,84,80,49,# 女性体重59,67,54,67,72,# 增加的数据点对应的体重53,68,60,75,55])#定义测试数据
X_test = np.array([[168,0],[180,1],[160,0],[169,0],[190,1]])
y_test =[65,76,52,67,79]
plt.figure()
plt.title('Human Heights and Weights by Sex')
plt.xlabel('Height in cm')
plt.ylabel('Weight in kg')for i, x inenumerate(X_train):
plt.scatter(x[0], x[1], c='k', marker='x'if y_train[i]=='male'else'D')
plt.grid(True)
plt.show()
- 模型训练部分 功能:在这段代码中,我们已经有了经过预处理的训练数据(性别特征已经是二进制),并且设置了K值为3。然后我们创建了一个KNN回归器KNeighborsRegressor实例,并使用训练数据对其进行拟合。这个过程是构建模型并为后续的预测做准备。
# 设置K值
K =3# 创建K近邻回归模型
clf = KNeighborsRegressor(n_neighbors=K)# 使用训练数据拟合模型
clf.fit(X_train, y_train)# 对测试数据进行预测
predictions = clf.predict(X_test)
- 执行预测并评估摸型 功能:这段代码使用之前拟合的模型对测试数据进行预测,并打印出预测的体重和实际体重。然后,代码使用r2_score函数来计算预测值和实际值之间的R²分数,这是评估回归模型性能的一个常用指标。 > R²分数表示模型对数据的拟合程度。如果R²分数接近1,表示模型的预测非常接近实际值,模型拟合效果好;如果R²分数接近0,表示模型的预测效果差。
# 输出预测结果和实际结果print('Predicted weights: %s'% predictions)print('Actual weights: %s'% y_test)# 计算R^2分数print(r2_score(y_test, predictions))# r2_score(y_test, predictions)是一个用于评估回归模型性能的函数,# 它计算了预测值(predictions)与实际值(y_test)之间的R²分数。# R²分数是决定系数,用于衡量模型对数据的拟合程度。# R²分数的值范围在0到1之间,值越接近1表示模型拟合效果越好,# 值越接近0表示模型拟合效果较差。
四、实验结果
(1) 实验内容一:基于身高和体重的性别预测
- 首次运行结果:
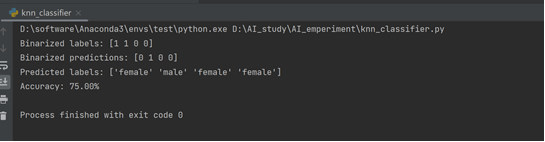
- 分析:算法成功运行,但是准确率不高,尝试提高训练集和测试集样本数以及改变k值来提高算法准确率
- 增大数据集并且改变k值为5后的准确率可以看到有提高:
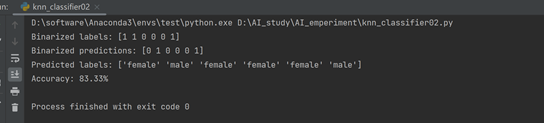
- 分析:KNN是一种基于实例的学习算法,这意味着它使用训练数据直接进行预测,而不是尝试学习并建立一个可泛化的内部模型。因此,有更多的数据通常会带来更好的结果,因为这意味着有更多的实例可以依赖于进行预测。K值代表算法在做出决策时考虑的最近邻居的数量。选择一个合适的K值对于KNN的性能至关重要。当K值较小,模型可能过于复杂,容易受到噪声点的影响,导致过拟合。当K值较大,模型可能过于简单,可能会忽略较小的模式,导致欠拟合。 因此,选择一个合适的K值可以帮助我们在偏差(模型的简单性)和方差(对训练数据的敏感性)之间找到一个良好的平衡,从而在未知数据上获得更好的预测性能。
(2)实验内容二:基于身高和性别的体重预测
- 首次运行结果:
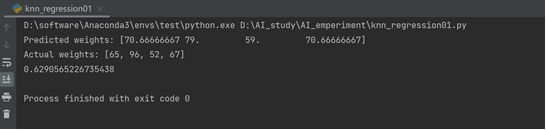
- 分析:算法成功运行,但是准确率不高,尝试提高训练集和测试集样本数以及改变k值来提高算法准确率
- 增大数据集并且改变k值后的准确率可以看到有提高:
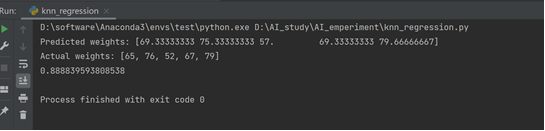
- 分析:适当地增大数据集和选择合适的K值都可以提高KNN算法的准确率,但是这需要根据具体的应用场景和数据特性来进行调整。
版权归原作者 是瑶瑶子啦 所有, 如有侵权,请联系我们删除。