

Presto介绍
一、Presto出现背景
Presto是Facebook在2012年开发的,是专为Hadoop打造的一款数据仓库工具。在早期Facebook依赖Hive做数据分析,Hive底层依赖MapReduce,随着数据量越来越大,使用Hive进行数据分析,时间可能需要分钟级到小时级别,不能满足交互式查询的数据分析场景。2012年秋季,Facebook开发Presto,目前该项目在Facebook中运行超过30000个查询,每日处理数据PB以上。Presto的查询速度是Hive的5-10倍。
综上,Presto是由Facebook2012年开发,基于内存、支持并行计算的分布式SQL交互式查询引擎,不是数据库,支持多种数据源,针对GB~PB数据查询可以达到秒级返回结果,主要用于秒级查询OLAP数据分析场景。
Presto官网地址:https://prestodb.io

二、Presto特点
- 多数据源
Presto可以支持MySQL、PostgreSQL、cassandra、Hive、Kafka等多种数据源查询。
- 支持SQL
Presto支持部分标准SQL对数据进行查询,并提供SQL shell进行SQL查询。但是Presto不支持存储过程,不适合大表Join操作,因为Presto是基于内存的,多张大表关联可能给内存带来压力。
- 扩展性
Presto有很好的扩展向,可以自定义开发特定数据源的Connector,使用SQL分析指定Connector中的数据。
- 混合计算
在Presto中可以根据业务需要使用特定类型的Connector来读取不同数据源的数据,进行join关联计算。
- 基于内存计算,高性能
Presto是基于内存计算的,减少磁盘IO,计算更快。Presto性能是Hive的10倍以上。Presto能够处理PB级别的数据,但Presto并不是把PB级别的数据一次性加载到内存中计算,而是根据处理方式,例如:聚合场景,边读取数据,聚合,再清空内存,再去读取数据加载内存,再聚合计算,再清空内存... 这种方式。如果使用Join查询,那么就会产生大量的中间数据,速度会变慢。
- 流水线
由于Presto是基于PipeLine进行设计的,因此在进行海量数据处理过程中,终端用户不用等到所有的数据都处理完成才能看到结果,而是可以向自来水管一样,一旦计算开始,就可以产生一部分结果数据,并且结果数据会一部分接一部分的返回到客户端。
三、Presto架构
Presto查询引擎是一个Master-Slave的架构,由一个Coordinator节点,一个Discovery Server节点,多个Worker节点组成,Discovery Server通常内嵌于Coordinator节点中。Presto架构图如下:
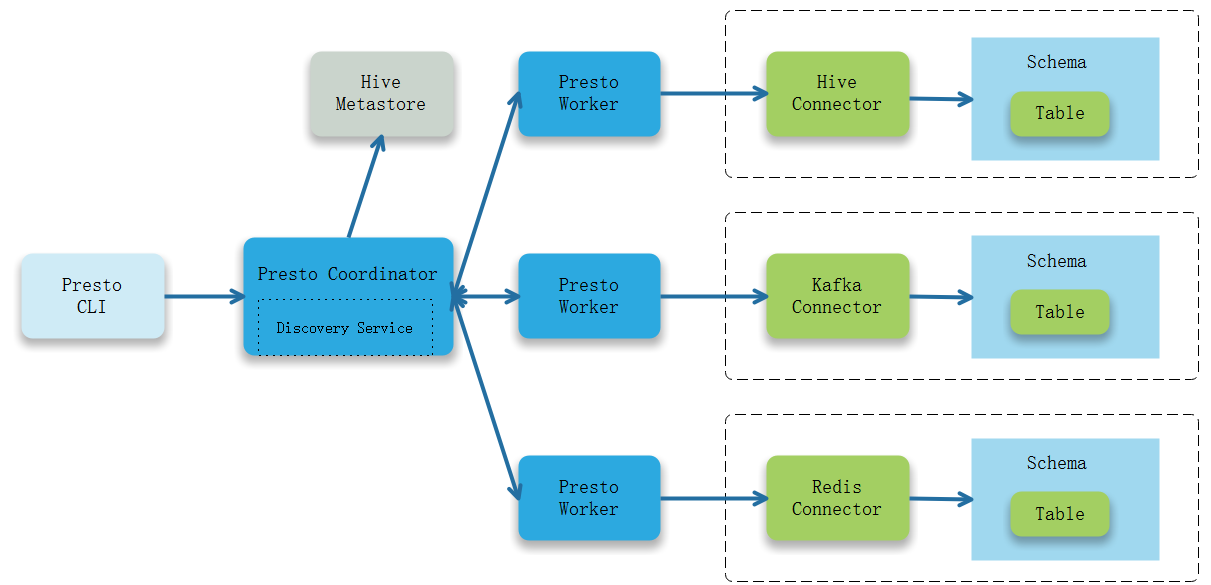
上图中各个角色功能如下:
- Presto Coordinator:
主要负责解析SQL语句,生成执行计划,分发执行任务给Worker节点执行。所有的Worker启动后都会注册给Discovery Server,Coordinator通过内嵌的Discovery Server来知道将任务发送给哪些个Worker节点。
- Presto Worker:
主要负责实际执行查询任务,Worker节点启动之后,向Discovery Server服务注册,Coordinator从Discovery Server获得可以正常工作的Worker节点。当Worker接收到task后,就会到对应的数据源通过各种Connnector将数据提取出来。
- Hive Metastore(配置Hive Connector才会有)
Presto通过Hive Connector读取Hive数据时,配置Hive Metastore服务为Presto提供Hive元数据信息,可以让Worker节点与HDFS交互读取数据。
- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨
版权归原作者 Lansonli 所有, 如有侵权,请联系我们删除。