
如果也有朋友着急需要,可以直接联系我,我尽快帮你做
准备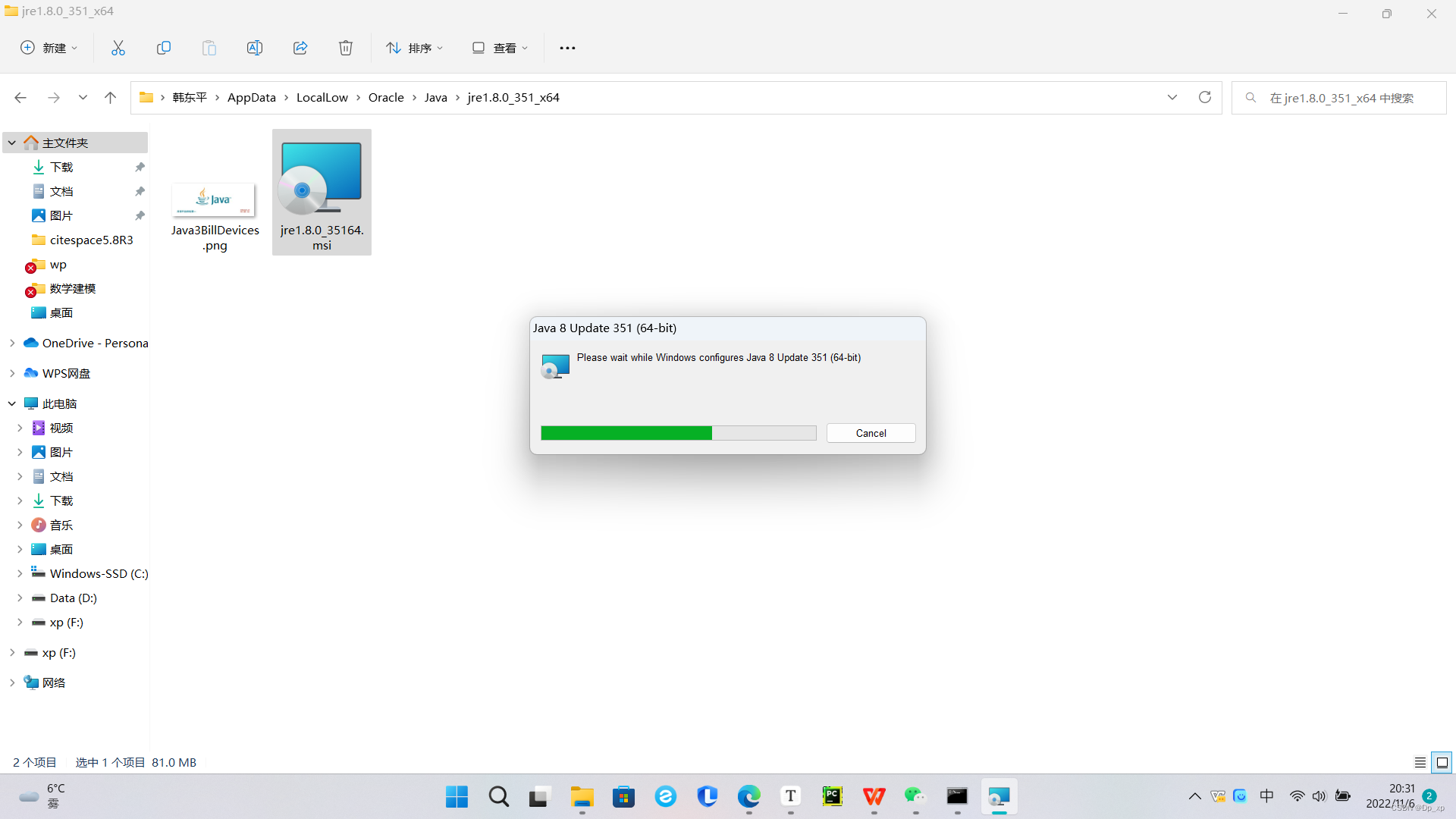
默认路径:AppData\LocalLow\Oracle\Java\jre1.8.0_351x64
点击安装就可以
- 也可以使用我默认的jdk安装环境
C:\Program Files\Java\jre1.8.0_351\bin\javaw.exe
1打开环境
将时间改为2020年前就好

2.版本
5.8.3版本全功能
6.1.3版本(新手入门版)
我可以给你安装包,配置环境
一、如何从知网获取研究主题的关键信息
第一步:打开知网,选择高级搜索。

第二步:在高级检索中选择期刊,为了避免垃圾期刊的影响,尽量不要选择全部期刊,尽可能地是北大核心或者CSCD,一般称C刊。

第三步:输入主题,开始进行检索,我这里输入小学语文教材插图,搜索结果如下:

第四步:首先使用知网的计量可视化工具看一下。


可以看到,会出现很多统计图,其中每个统计图都很有意思 ,还可以单独操作。以主要主题为例。

通过双击不同柱子,例如我单独点击了小学语文,小学语文教材,等几个柱子,在上方会出现一个新的对比统计分析图,会把单独挑出来的主题进行分析对比。如果没有出现比较分析,先点击一个东西如下图:然后再点击不同的主题的柱子。
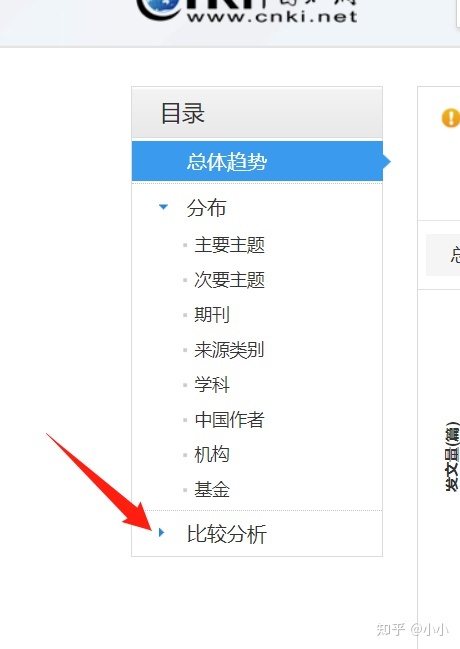

此外,对于这些柱状图还有不同的形式呈现,


对于其他几种分析结果可以有同样的操作。
根据作者统计分析图,可以看出在这领域中的专家都有哪些,排名前几的这几个人论文肯定是要下载下来好好看一下的!

二、使用citespace进行文献分析
1、首先安装citespace,打开citespace的官网,很明显看到requirement需要先安装JRE,如果电脑本身没有,请先装这个。然后再下载CiteSpace。
JRE下载地址:链接:https://pan.baidu.com/s/1fo5Bng5l_xgZliKWUy8-nw
提取码:nzeo

安装完java之后检测是否安装,win+R打开运行窗口输入cmd,在命令行中输入java -version

安装成功!
2、安装citespace
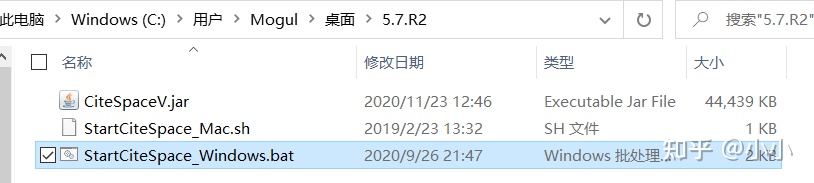
打开之后直接启动.bat文件,然后再这个过程中会下载一些东西,可能会比较慢。耐心等待,如果安装出错,需要再C盘中清除.citespace文件夹,然后重新启动。

安装完成以后,界面是这样的。

三、CiteSpace的使用
1、首先选择一个盘符,建立工程文件夹项目,建议不要存放在C盘!不要存放在C盘!不要存放在C盘!

2、下载分析数据,再知网高级搜索中选择相应设置。以这次为例,选择期刊文献。

可以看到检索结果有20条。如果数据比较多的话,建议还是逐个筛选一下,尽量选择期刊质量高或者知名作者的论文。

然后全选,导出Refworks。下载完成之后将其重命名为download_xxxx(这个自己定)放到之前建好的Citespace_data文件夹中。

3、导入数据



选择完成之后开始点击CNKI Format Conversion。

在CNKI_output文件夹中,然后将这些转换完成的所有txt转移到CNKI_data。

4、新建工程
在新建工程这里,建议先使用Wos,如果出现错误,就重新建一个工程选择使用CSSCI再试一下。

保存完成之后,在这里可以根据具体年份选择一下,如果不清楚年限的直接点go就行了。

不出意外,会直接报错:或者是显示年限不对等,这是由于下载的文献中并不包含参考文献这个字段。

这是因为这里选择的节点类型不太对,这里的每一个类型都可以尝试,那么现在换成Author试一下。

再次点击GO
然后选择Visualize。可视化完成之后背景会变成白色

这个时候点击选择黑色背景,


其他字段如果不出现报错信息,就进行可视化分析就行了!
四.CiteSpace关键词聚类图谱含义详细解析
我们来看一下上次推文做出来的关键词共现图谱:
人工不好归纳!那怎么聚类呢? 此时便可使用CiteSpace的聚类功能啦! 如下所示:我们可以清晰地看到上边的关键词共现网络聚成了一个个不规则区域,每一个区域都对应着一个标签。
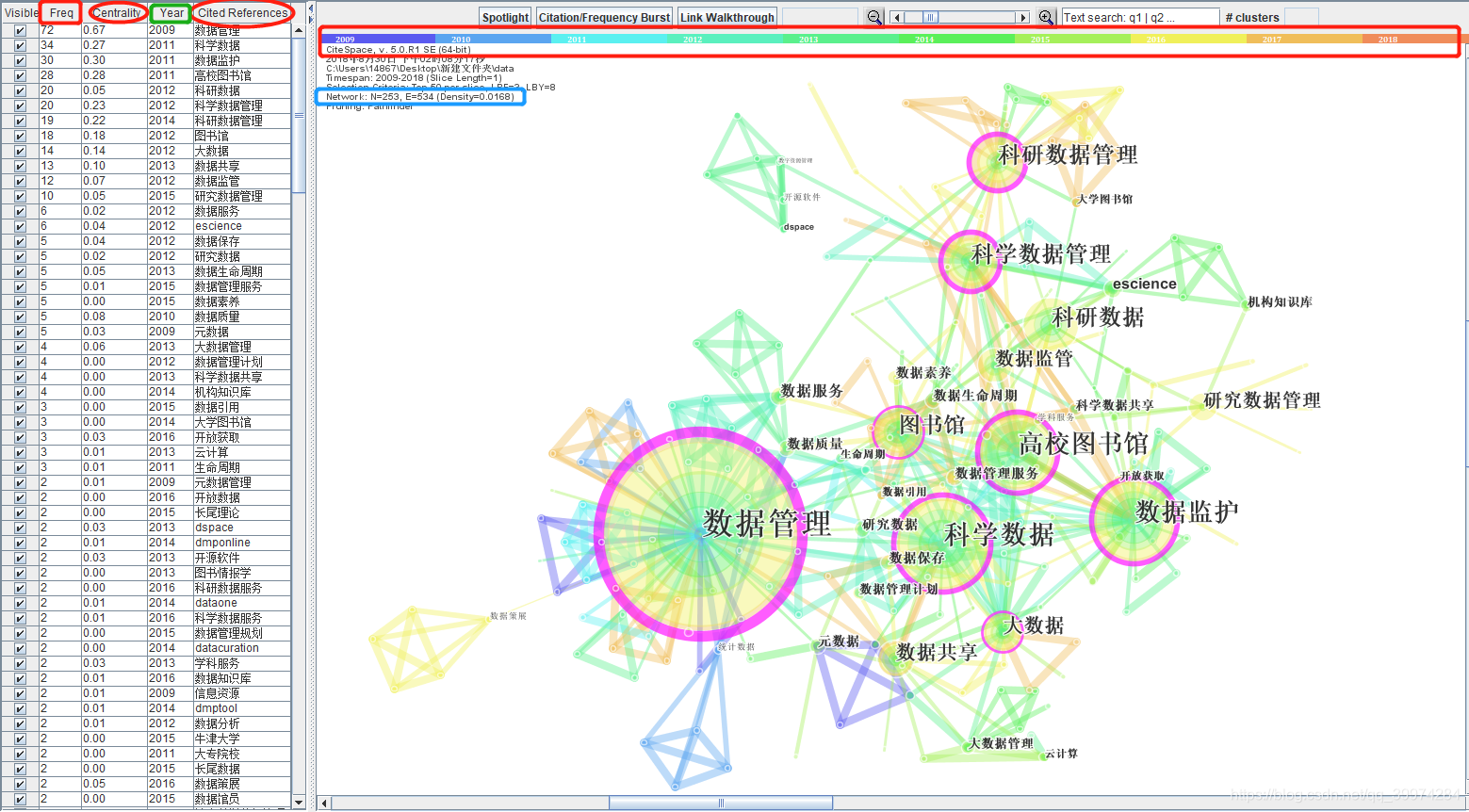
顺序是从0到7,数字越小,聚类中包含的关键词越多,每个聚类是多个紧密相关的词组成的,具体是那些关键词我们可以通过导出得报告得到详细信息。 在这个网络中我们需要注意两个数值,一个是Q值一个是S值,这两个数值表征着聚类想过的好坏,一般认为:
Modularity::聚类模块值(Q值),一般认为Q>0.3意味着聚类结构显著
Silhouette:S值:聚类平均轮廓值 ,一般认为S>0.5聚类类就是合理的,S>0.7意味着聚类是令人信服的。
如果这两个值不在此范围内,我们可以调节每年出现的次数或者网络的剪切算法。 但是,我们不能为了调值而调值,有时两个值是调好了,但是呢?图谱已经不能看了,结果根本就不符合实际啦。 所以呢,关于这两个值到底如何,我们还是需要根据图谱来判断。如果图谱合理了,即使值不在范围内也是可以。 另外,每个聚类都有一个标签,这个便签是怎么生成的呢? 这个答案,可以通过下图来回答。
比如文献定量中关键词频次排序获取研究热点,社会网络分析中点度中心性、接近中心性、中间中心性排序,获取网络中有影响力的行动者,上文CiteSpace聚类中的关键词排序得到该聚类的标签等等。
五.时间线图


3)调节节点的形状

(4)调节标注字的颜色

如果时间线,聚类不完全显示:

(1)点击control panel 中的cluster labels调整长度(直接调到最大)
(2)再点击K、LLR算法和时区聚类,重新聚类,聚类标签就显示完成。
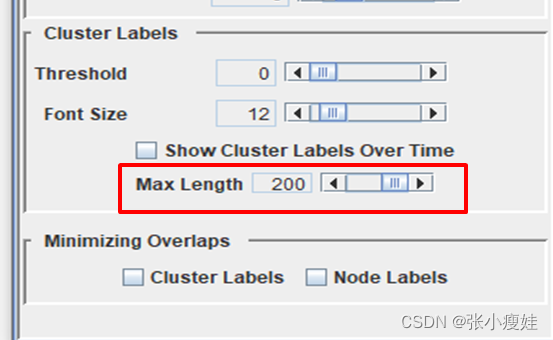

一、聚类操作 依次点击下面三个按钮进行时区聚类
只保留6个聚类
出现的对话框中选择6
发现聚类标签只显示了部分
二、调整聚类名称长度 选择【labels】,把【max length】调长一些即可。
重新点击k和LLR算法和时区聚类,现在标签就显示完整了。
(1)File(文件)中的功能主要包含Open Visualization(打开可视化结果),Save Visualization(保存.layout可视化文件),Open Layoutplus(打开布局文件),Save Layoutplus(保存.layout布局文件),Save Content Data to File(保存为.net文件),Save As PNG(保存结果为图形)以及Exit(退出)。
(2)Metrics用于计算节点的中介中心性(Compute Centrality),即当网络节点数量超过350个时,用户需要通过此菜单启动网络的中介中心性计算。
(3)原Layout菜单已修改为Visualization菜单,主要用于网络布局的控制。其中Graph views主要提供了Time view(时间线图)、Timezone view(时区图)以及Cluster view(聚类视图)等视图的显示方式。Start是静态时重新布局的按钮,Stop用来终止网络的布局过程。CiteSpace默认Layout Algorithm是Kamada and Kawa布局,提供的算法是Force Directed。
(4)Display菜单栏的主要功能是对图形显示的调节。 ①颜色的设置。Background Color是对背景颜色的选择,可以选择不同的背景颜色。Black Background是黑色背景,White Background是白色背景。Colormap Palate可以选择整个网络的颜色为Color(彩色)或Monochrome(单色,蓝色渐变)。 ②节点类型的设置。Node Rendering Type是指节点显示类型的选择,分别为Tree Ring History(引文年轮),Centrality(中介中心性),Eigenvector Centrality(特征向量中心性),Sigma(Sigma值),PageRank Scores(PR值),Uniform Size(统一大小),Cluster Membership(聚类显示),WOS TC(引证次数),WOS UI(最近180天的使用情况)以及WOS U2(从2013年开始使用的情况)。 【注】:各节点显示依据的算法 CiteSpace菜单Centrality的含义为中介中心性,是测度节点在网络中重要性的一个指标(此外,常见的测度节点重要性的指标还有度中心性,接近中心性等)。CiteSpace中使用此指标来发现和衡量文献的重要性,并用紫色圈对该类文献(或作者、期刊以及机构等,且带有紫环的节点中介中心性不小于0.1)进行重点标注。具有高中介中心性的文献通常是连接两个不同领域的关键枢纽,在CiteSpace中也称其为转折点。中介中心性的计算公式如下:
式中,gst为从节点s到节点t的最短路径数目nist为从节点S到节点t的gst条最短路径中经过节点i的最短路径数目。从信息传输角度来看,中介中心性越高,节点的重要性也越大,去除这些点之后对网络传输影响也最大。 特征向量中心性(Eigenvector Centrality)的基本算法思想是:一个节点的重要性既取决于其相邻节点的数量(节点度数),也取决于相邻节点的重要性。特征向量中心性的计算公式如下:
式中,c为常数,A=(aij)为网络的邻接矩阵,记为x=[x1x2…xN]T,因此可以将上式改写为x=cAx。那么,意味着x是矩阵A与特征值c-1对应的特征向量,故本算法称为特征向量中心性。 Sigma指数(∑)是CiteSpace中结合节点在网络结构中重要性(中介中心性)和节点在时间上的重要性(突发性)两个指标复合构造的测度节点新颖性的一个指标。计算方法为:
PageRank算法,是Google用来对网络进行排序的主要算法,基本思想就是:一个网页的重要性由两个因素决定,一个是指向该网页的其他网络的数量,二是这些页面的质量。该方法与特征向量中心性的思想类似,不仅考虑周围点的数量,还考虑其质量。 Node Shape可以选择为Circle(圆)或Square(方),该功能通常是在Term分析中应用。 Node Fill Color为节点填充颜色,当节点类型为Tree Ring History,Cluster Membe-rship,WOS TC以及Uniform Size时不可用,其他节点类型时可以使用。 Node Outline Color(节点外圈颜色)在Tree Ring History和Cluster Membership状态下不可使用。 ③标签的设置。Label Font Size中包含的Node:Uniformed/Proportional是指节点标签的统一大小,或者按照节点属性的比例进行显示。Cluster:Uniformed/Proportional是指网络图中聚类的标签按照聚类的规模来显示或者统一显示规格;Label Outline:Show/Hide,指是否显示网络中的字体标签边框。 ④网络线样式的设置。Line Shape线的形状设置,分为Straight line和Spline。 Dashed Lines:Show/Hide(显示或隐藏点划线);Dashed Lines:Set Color(点画线颜色设置);Solid Lines:Set Color(实线颜色设置);Overlay Labels:Show/Hide(显示或隐藏叠加网络标签);link Strengths:Show/Hide(显示/隐藏连线强度)以及Link Transparency0-1.0(对线的透明度的调整);当设置为0时不显示连线,为1时连线的颜色最清晰。 ⑤图中注释信息。Show/Hide Signature,显示/隐藏网络图左上角的参数信息;Show/Hide Citation Frequency,显示/隐藏节点的频次信息。 ⑥聚类图形的编辑。Show/Hide Cluster Labels,显示/隐藏聚类标签;Show/Hide Cluster IDs,显示/隐藏节点的聚类编号(在同一类中的节点,将显示相同的编号);Convex Hull:Show/Hide,显示/隐藏聚类的填充或边框;Convex Hull:Toggle Fill Color Patterns,切换填充颜色模式;Convex Hull:Select a Fill Color,选择填充颜色;Circle:Show/Hide,聚类中心圆的显示或隐藏。特别地,Circle Packing可以对聚类圆按照聚类规模进行单独显示。 ⑦Timeline视图标签的编辑。Timeline视图时主要是对节点标签偏斜的角度进行调整,默认为15度。此外还包含Text Rotate 0 Degree,Text Rotate 30 Degree,Text Rotate 45 Degree和Text Rotate 60 Degree。
(5)Network Overlays菜单主要是CiteSpace提供的网络叠加分析功能,包含Remove Network Layers,Save As a Network Layer以及Show/Hide Overlay Node labels。在使用该功能时,通常是先对整体网络进行分析,并保存整体网络的图层;然后再分析一个子网络,并保存;再依次加载整体网络和子网络,这样就能得到子网络在整体网络上的位置。 (
6)Filter菜单功能主要是对关键路径或关键节点的显示,特别是对分析的文献结果与PubMed的记录链接进行配对。
(7)Cluster菜单功能主要是执行聚类过程以及对聚类得到的结果进行查询和导出。 【注】:Cluster菜单常用功能 Clustering属于快速聚类,点击后等待软件自动聚类完成即可。使用Clustering对网络进行聚类后节点的类型将发生变化。Clustering(Advanced)也是对网络的聚类,同时可以选择将聚类的结果保存在本地MySQL数据库中。此外,该菜单栏中还提供了EM聚类算法。Expectation Maximization为最大期望算法,是一个聚类框架,它逼近最大似然或统计模型参数的后验概率估计,可以用来计算模糊聚类和基于概率模型的聚类,它是CiteSpace早期版本常采用的聚类方法。该功能的具体步骤为:依次点击可视化菜单栏的Clusters-Expectation Maximization(EM)进入EM页面-Start EM(Clustering区域)-Visualing区域查看聚类图形-Cluster instances区域查看聚类的详细表格。最后,返回到可视化界面,会发现节点的颜色随着EM的完成发生了改变。Cluster Labels是聚类标签CiteSpace提供了从标题中提取聚类名称,从索引词中提取聚类命名以及从摘要中提取聚类命名的功能。Enable/Disable cluster membership export提供的是在Project文件夹中是否建立“cluster”文件夹,并按照聚类类别导出聚类的文献到该文件夹,选择该功能时会提示Future Clustering results will be export to files或Future Clustering results will not be export to files。特别地,点击聚类并不会将结果导出到该文件夹,只有在点击命名提取位置“T,K或A”时文件夹才会导出聚类结果。Display Labels Selected by Different Algorithm的含义是使用不同的算法来提取聚类命名。三种方法分别为Latent Semantic Index,Log-Likelihood Ratio(LLR对数极大似然率)以及Mutual information(互信息)。Summarization of Cluster主要是用来查询使用不同方法得到的聚类列表,其中Cluster ID为聚类的编号,聚类规模越大,编号越小。Size代表的是聚类中所含的成员的数量,Silhouette为衡量整个聚类成员同质性的指标,数值越大,代表该聚类成员的相似性越高。Mean Year代表的是文献的平均年份,能够用来判断聚类中引用文献的远近,并列出了使用LSI,LLR以及MI算法得到的排名靠前的术语。Summarize a single cluster的功能是对特定的聚类的施引文献的重要句子的提取,以帮助理解某一特定类的内容。Select cluster-summarizing sentences的功能是从各个聚类的文献中提取重要的句子,以帮助用户对该聚类进行解释。Cluster Explorer功能提供了聚类信息查询,施引文献信息,被引文献信息以及从施引文献中提取的总结聚类的句子查询四个窗口。该功能能够清晰地了解到与聚类相关的多个方面的信息,是文献共被引分析中最常用的一个功能。
(8)Export菜单功能主要是对网络结果进行查询和导出。常用功能包含Network Summary Table(网络信息汇总表),Save Cited References to an RIS File(保存文献为RIS格式),network(导出为其他软件读取的格式),Clustering+Labeling+Save cluster Files(完成聚类、命名和结果的保存),Merge network_summary_YYYY-YYYY.csv files and structural_change_metrics.csv(文件合并)以及Generate a Narrative(生成报告)。特别地,点击Run Batch Mode能够一步完成对当前网络的聚类和生成GENETATED NATTATIVES报告。点击Network summary Table可以得到可视化网络中所有节点的列表,该表可以直接复制到Excel或Word中,也可以导出为CSV,RIS以及Html格式进行分析。在该表中,Freq代表节点的频次,Burst为突发性探测值,Centrality为中介中心性,PageRank为PR排名,Keyword为关键词,Year为时间,Title标题,Source为文献来源(如期刊),Vol为卷次,Page为起始页码,HalfLife为半衰期,Cluster为所属聚类。Save Cited Reference to an RIS File可以将网络中的文献信息保存为RIS格式,并可以进一步导入Endnote等文献管理软件中为论文写作提供便利。Network的导出功能是将当前的网络导出为常见的网络格式,如Pajek(.net),Pajek(.net with time intervals)以及UCINET Network Format(DL)。Generate a Narrative可以直接导出对网络最重要的分析结果报告,包含了MAJOR CLUSTERS(主要聚类及其聚类标签),CITATION COUNTS(高被引文献),BURSTS(突发性文献),CENTRALITY(高中心性文献),SIGMA值。
(9)Help中包含Legend,Controls和About,分别是对CiteSpace图形中的Legend的说明,包含Node,Link以及Color Mapping三个部分。Controls主要是指导用户在使用CiteSpace时可以在网络视图区进行的一些操作。About主要是关于CiteSpace的版权说明,及其Sigma的计算=Sigma=(centrality+1)^burstness。
版权归原作者 哈都婆 所有, 如有侵权,请联系我们删除。