
系列文章目录
一、Hive表操作
二、数据导入和导出
三、分区表
四、官方文档(了解)
五、分桶表(熟悉)
六、复杂类型(熟悉)
七、Hive乱码解决(操作。可以不做,不影响)
八、select查询(掌握)
文章目录
前言
------幼时之矢,今我身中-----
余幼贫而不知进,耽于嬉戏,误学无志,偶寄情山水,纵情声色,蹉跎岁月二十有余。忆及少时初读《送东阳马生序》,觉其晦涩难解,不知其深意。今览文而悲凉之感油然而生,历人生百苦,略悟其理。
久经四方,奔波劳碌,再回首已届而立之年。奈何花有重开日,人无再少年,重返故土,悔恨涌心。初读为文,再阅已成人生,自怜之情难禁。教育之滞后,惟至年岁方明闭环之刻。
昔高中上地理课,析城市区位优势,必言“劳动力丰富廉价”。今大学毕业,月薪未及五千,夜以继日,始知劳动力之真廉。幼时视刻舟求剑为讽刺,今则知其悲剧内核乃遗憾也。黄庭坚刻舟求坠剑,怀人挥泪著亡簪,皆此情此景之写照。
少时疑掩耳盗铃之愚,今则悟人皆凡俗,自欺欺人,亦自保之道。昔日恋爱,不知人性之规,屡受情伤,始明《氓》诗之教。遇人不淑,情爱非一味奉献与牺牲,须及时止损,双向奔赴方为佳缘。
年岁增长,赴考公编,始知范进中举之狂喜。彼之成绩,全省第七,正厅之职,今之教育厅厅长也。观其表现,情绪尚属稳定。
闯荡江湖,方知《记承天寺夜游》所言“但少闲人如吾两人者尔”之真意。浪漫难寻,知己难求,可贵非月光之美,乃月下推心置腹之情谊也。
岁月变迁,付出终有回报,乃悟《早发白帝城》之“两岸猿声啼不住,轻舟已过万重山”。功不唐捐,命运终嘉奖,信天道酬勤者皆得善果。特发此篇,以资鼓励。
----大数据小朋友感悟
本文主要介绍hive的表操作,内外部表,分区分桶表,hive复杂类型,Hive乱码解决。
一、Hive表操作
6、外部表
知识点:
创建外部表: create external table [if not exists] 外部表名(字段名 字段类型 , 字段名 字段类型 , ... )[row format delimited fields terminated by '字段分隔符'] ;
复制表: 方式1: like方式复制表结构 注意: as方式不可以使用
删除外部表: drop table 外部表名;
注意: 删除外部表效果是mysql中元数据被删除,但是存储在hdfs中的业务数据本身被保留
查看表格式化信息: desc formatted 表名; -- 外部表类型: EXTERNAL_TABLE
注意: 外部表不能使用truncate清空数据本身
总结: 外部表对HDFS上的业务数据的管理权限并不高,drop表不会删除业务数据,同时不能使用truncate和delete来删除表数据。我们可以通过HDFS的shell来删除业务数据
示例:
-- 创建数据库createdatabaseifnotexists day06;-- 使用数据库use day06;-- 创建外部表create external table outer_stu1(
id int,
name string
);-- 添加数据insertinto outer_stu1 values(1,'zhangshan');-- Hive底层对部分SQL语句进行了优化,不会变成MapReduceselect*from outer_stu1;-- 创建外部表的方式2-- 注意: 不管是什么方式创建外部表,一定要加上external关键字create external table outer_stu2 like outer_stu1;desc formatted outer_stu2;-- 大小写转换快捷键: ctrl+shift+Ucreate EXTERNAL table outer_stu3 like outer_stu1;desc formatted outer_stu3;-- 这种方式创建的还是内部表createtable stu2 like outer_stu1;-- 查看表的详细信息desc formatted stu2;-- 创建外部表的方式3-- 注意: 针对外部表,不能使用create external table 外部表名 as select 来创建create external table outer_stu4 asselect*from outer_stu1;-- 删除表-- 该表的数据存放路径 hdfs://node1:8020/user/hive/warehouse/day06.db/outer_stu1-- HDFS的路径中为什么是node1,因为namenode运行在node1上面droptable outer_stu1;-- 清空表insertinto outer_stu3 values(1,'zhangshan');select*from outer_stu3;-- truncate table outer_stu3;deletefrom outer_stu3;update outer_stu3 set name='wangwu';select*from outer_stu3;-- 创建数据库createdatabaseifnotexists day06;-- 使用数据库use day06;-- 创建外部表create external table outer_stu1(
id int,
name string
);-- 添加数据insertinto outer_stu1 values(1,'zhangshan');-- Hive底层对部分SQL语句进行了优化,不会变成MapReduceselect*from outer_stu1;-- 创建外部表的方式2-- 注意: 不管是什么方式创建外部表,一定要加上external关键字create external table outer_stu2 like outer_stu1;desc formatted outer_stu2;-- 大小写转换快捷键: ctrl+shift+Ucreate EXTERNAL table outer_stu3 like outer_stu1;desc formatted outer_stu3;-- 这种方式创建的还是内部表createtable stu2 like outer_stu1;-- 查看表的详细信息desc formatted stu2;-- 创建外部表的方式3-- 注意: 针对外部表,不能使用create external table 外部表名 as select 来创建create external table outer_stu4 asselect*from outer_stu1;-- 删除表-- 该表的数据存放路径 hdfs://node1:8020/user/hive/warehouse/day06.db/outer_stu1-- HDFS的路径中为什么是node1,因为namenode运行在node1上面droptable outer_stu1;-- 清空表insertinto outer_stu3 values(1,'zhangshan');select*from outer_stu3;-- truncate table outer_stu3;deletefrom outer_stu3;update outer_stu3 set name='wangwu';select*from outer_stu3;
快速创建外部表不支持的操作:
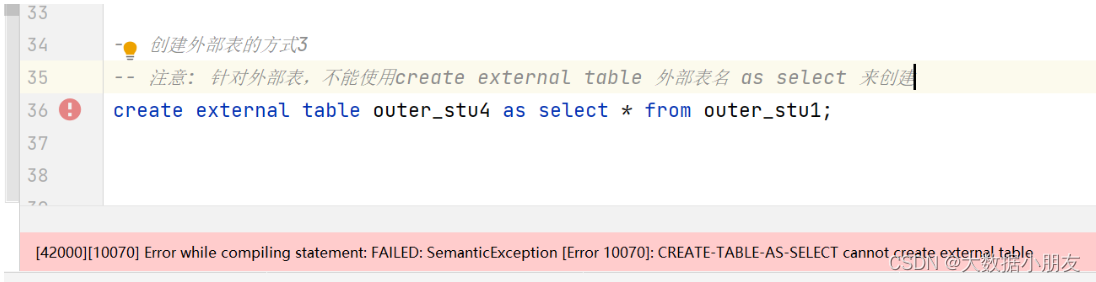
注意: 针对外部表,不能使用create external table 外部表名 as select 来创建
清空外部表的时候遇到的错误:
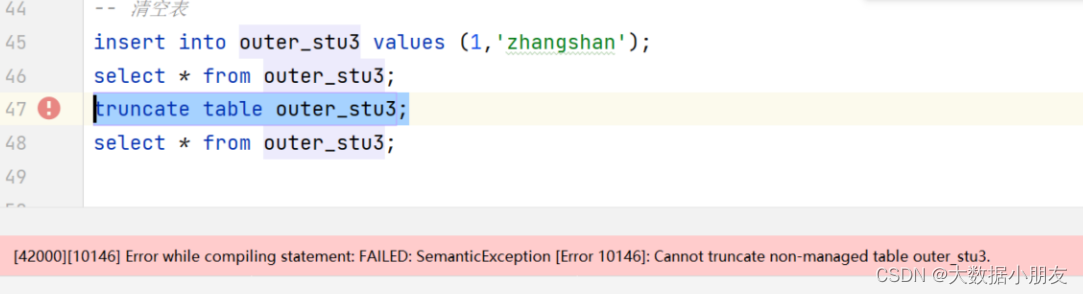
原因: 不能使用truncate语句来清空外部表
解决办法: 可以使用delete from 外部表名称。但是有前提条件,需要开启表对事务的支持(了解)
如果执行delete会报如下错误:

原因: 对表数据使用delete进行删除的时候,需要先开启事务
注意: 在公司中,默认不会去开启Hive对事务的支持,事务开启后比较消耗性能。https://cwiki.apache.org/confluence/display/Hive/Hive+Transactions

7、查看和修改表
知识点:
查看所有表: show tables;
查看建表语句: show create table 表名;
查看表信息: desc 表名;
查看表结构信息: desc 表名;
查看表格式化信息: desc formatted 表名; 注意: formatted能够展示详细信息
修改表名: alter table 旧表名 rename to 新表名
字段的添加: alter table 表名 add columns (字段名 字段类型);
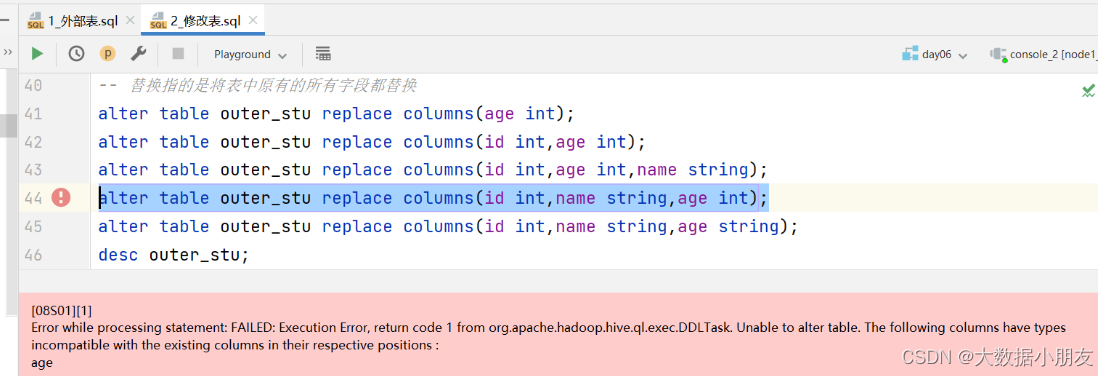
字段的替换: alter table 表名 replace columns (字段名 字段类型 , ...);
替换的时候注意: 替换的时候,是使用新的字段信息替换原有的所有字段。也就是如果某些字段不想变化,你也需要把它写到替换的信息后面。
字段名和字段类型同时修改: alter table 表名 change 旧字段名 新字段名 新字段类型;
注意: 字符串类型不能直接改数值类型,这句话是有方向的。也就是字符串不能随便变成数值,但是数值可以变成字符串。举例:"hello world"变成数值的时候,Hive内部是不知道它对应的数值是多少;123 可以变成 "123"字符串
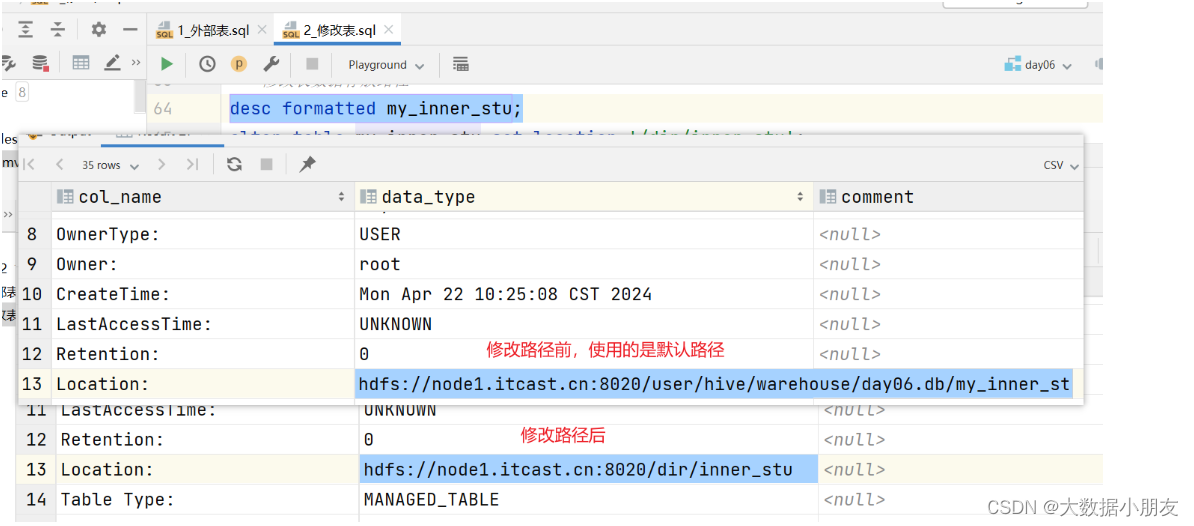
修改表路径: alter table 表名 set location 'hdfs中存储路径';
注意: 建议使用默认路径
location: 建表的时候不写有默认路径/user/hive/warehouse/库名.db/表名,当然建表的时候也可以直接指定路径
修改表属性: alter table 表名 set tblproperties ('属性名'='属性值'); 注意: 经常用于内外部表切换
内外部表类型切换: 外部表属性: 'EXTERNAL'='true' 内部表属性: 'EXTERNAL'='false'
注意: 属性中的EXTERNAL名称不能随意改动,必须与Hive官网保持一致。
表支持的属性: https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL#LanguageManualDDL-listTableProperties
示例:
use day06;-- 创建内部表和外部表createtable inner_stu (
id int,
name string
);create external table outer_stu (
id int,
name string
);-- 添加数据insertinto inner_stu values(1,'zhangshan');insertinto outer_stu values(1,'zhangshan');-- 查看当前数据库下面的所有表showtables;-- 查看建表语句showcreatetable inner_stu;showcreatetable outer_stu;-- 不管是查看内部表还是外部表的建表语句,都是show create table 表名称的语法-- show create external table outer_stu;-- 查看表的详细信息desc inner_stu;desc formatted inner_stu;-- 表字段的操作-- 表添加字段(列名是同一个意思)altertable inner_stu addcolumns(age int);desc inner_stu;-- 替换表中的字段-- 替换指的是将表中原有的所有字段都替换altertable outer_stu replacecolumns(age int);altertable outer_stu replacecolumns(id int,age int);altertable outer_stu replacecolumns(id int,age int,name string);-- 注意:字符串类型的字段不能随便直接改成数值类型。altertable outer_stu replacecolumns(id int,name string,age int);altertable outer_stu replacecolumns(id int,name string,age string);desc outer_stu;select*from outer_stu;-- 同时修改字段名称和数据类型altertable outer_stu change age new_age varchar(10);-- 注意:字符串类型的字段不能随便直接改成数值类型。-- 其中的解决办法:重新建一张表,然后把旧表的数据全部插入到新表里面去altertable outer_stu change new_age age int;desc outer_stu;-- 表的修改操作-- 修改表名称altertable inner_stu renameto my_inner_stu;-- 修改表数据存放路径-- 注意: 不推荐修改,就使用默认路径desc formatted my_inner_stu;altertable my_inner_stu set location '/dir/inner_stu';desc formatted my_inner_stu;-- 添加数据insertinto my_inner_stu values(1,'zhangshan',18);select*from my_inner_stu;desc formatted my_inner_stu;-- 修改表属性-- 内外部表相互转换-- 内部表 -> 外部表altertable my_inner_stu set tblproperties ('EXTERNAL'='true');desc formatted my_inner_stu;-- 外部表 -> 内部表desc formatted outer_stu;altertable outer_stu set tblproperties ('EXTERNAL'='false');desc formatted outer_stu;
修改表路径前后对比:
show create table中可能遇到的问题:
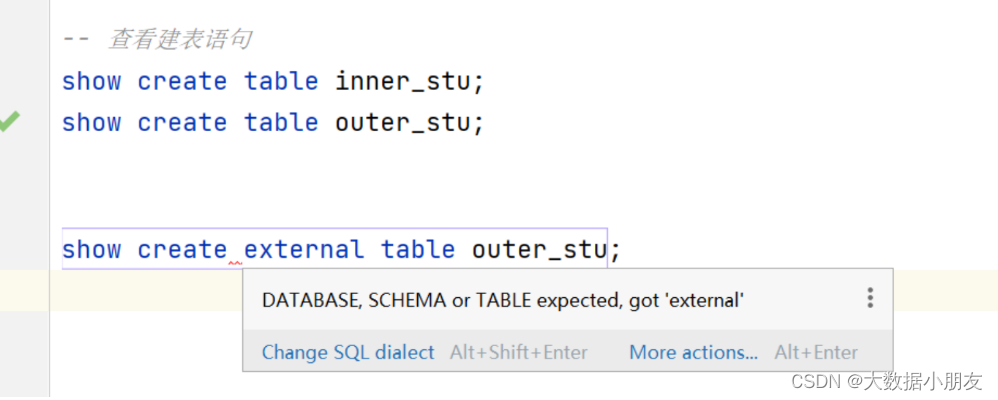
原因: 不管是查看内部表还是外部表的建表语句,都是show create table 表名称的语法
原因: 字符串类型的字段不能随便变成数值类型
8、快速映射表
知识点:
创建表的时候指定分隔符: create [external] table 表名(字段名 字段类型)row format delimited fields terminated by 符号;
加载数据: load data [local] inpath '文件路径' into table Hive表名称
示例:
HDFS示例:
use day06;-- 1- 创建表createtable jd_products(
id int,
name string,
price float,
c_id string
)row format delimited fieldsterminatedby',';-- 2- 数据上传到HDFS中-- hdfs dfs -put products.txt /day06-- 3- 加载前先检查表数据select*from jd_products;-- 4- 将HDFS中的数据加载到Hive表中loaddata inpath '/day06/products.txt'intotable jd_products;-- 5- 数据验证select*from jd_products;
本地映射示例:
use day06;-- 1- 创建表createtable jd_products_local(
id int,
name string,
price float,
c_id string
)row format delimited fieldsterminatedby',';-- 2- 加载前先检查表数据select*from jd_products_local;-- 4- 将本地中的数据加载到Hive表中-- 推举使用从HDFS上面将数据加载到Hiveloaddatalocal inpath '/home/products.txt'intotable jd_products_local;-- 5- 数据验证select*from jd_products_local;
二、数据导入和导出
1、文件数据导入
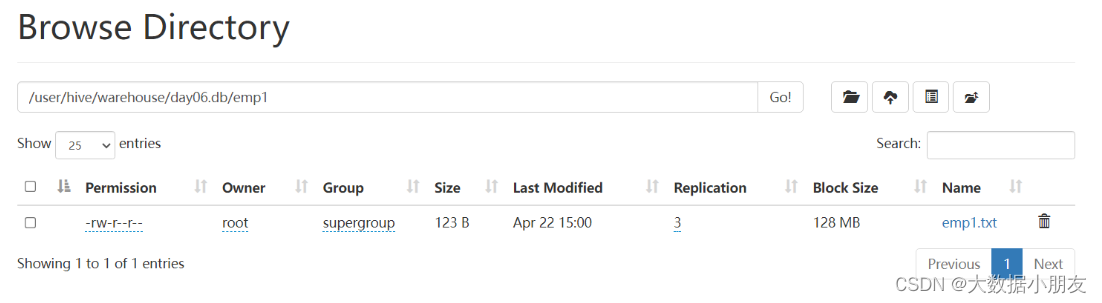
1.1 直接上传文件
- window页面上传
需求: 已知emp1.txt文件在windows/mac系统,要求使用hdfs保存此文件
并且使用hivesql建表关联数据
use day06;
-- 1- 创建Hive表
create table emp1 (
id int,
name string,
salary int,
dept string
)row format delimited fields terminated by ',';
-- 2- 通过浏览器界面将数据上传到HDFS
-- 3- 将HDFS上的数据文件加载到Hive中
load data inpath '/emp1_dir' into table emp1;
-- 4- 数据验证
select * from emp1;
-- load数据的特殊演示
-- 1- 建表
create table emp111 (
id int,
name string,
salary int,
dept string
)row format delimited fields terminated by ',';
-- 2- 通过HDFS的shell命令移动/复制数据文件到表的目录下
-- hdfs dfs -cp /user/hive/warehouse/day06.db/emp1/emp1.txt /user/hive/warehouse/day06.db/emp111/emp2.txt
select * from emp111;
- linux本地put上传
需求: 已知emp2.txt文件在linux系统,要求使用hdfs保存此文件
并且使用hivesql建表关联数据
use day06;-- 1- 创建Hive表createtable emp2 (
id int,
name string,
salary int,
dept string
)row format delimited fieldsterminatedby',';-- 2- 通过命令或者界面将windows上的文件先上传到linux-- rz-- 3- 通过命令linux上的文件上传到HDFS,并且上传到表数据所在的目录-- hdfs dfs -put emp2.txt /user/hive/warehouse/day06.db/emp2-- hdfs dfs -ls /user/hive/warehouse/day06.db/emp2-- 4- 验证数据select*from emp2;
1.2 load加载文件
从hdfs路径把文件移动到表对应存储路径中: load data inpath '文件路径' [overwrite] into table 表名称;
从linux本地把文件上传到表对应存储路径中: load data local inpath '文件路径' [overwrite] into table 表名称;
- load移动HDFS文件
use day06;-- 创建Hive表-- \t表示的是制表符createtable search_log(
dt string,
uid string,
name string,
url string
)row format delimited fieldsterminatedby'\t';-- HDFS文件演示-- 将windows本地文件上传到HDFS的非Hive表所在的目录loaddata inpath '/dir/search_log.txt'intotable search_log;select*from search_log;
- load上传Linux文件
-- Linux本地文件演示loaddatalocal inpath '/home/search_log.txt'intotable search_log;select*from search_log;
- load上传Linux文件并且使用overwrite(覆盖)
-- Linux本地文件演示,并且带上overwrite-- overwrite效果:先清空表中的原有数据,然后是新数据填充load data local inpath '/home/search_log.txt' overwrite into table search_log;select * from search_log;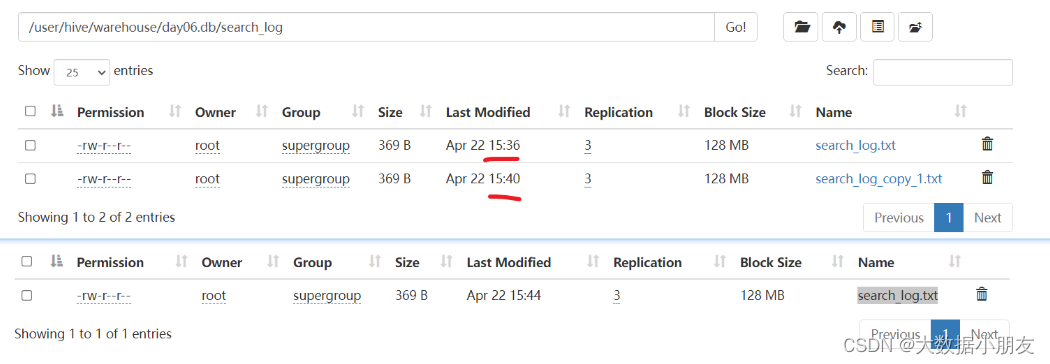
1.3 insert插入数据
从其他表查询数据'追加'插入到当前表中: insert into table 表名 select查询语句;
从其他表查询数据'覆盖'插入到当前表中: insert overwrite table 表名 select查询语句;
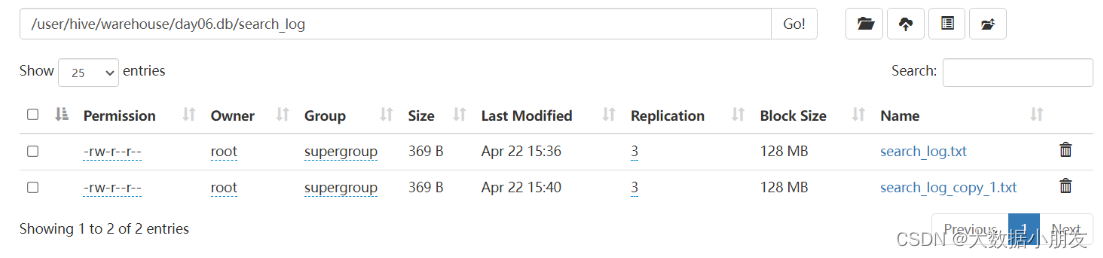
- insert追加数据
use day06;-- 创建Hive表-- \t表示的是制表符createtable search_log_copy(
dt string,
uid string,
name string,
url string
)row format delimited fieldsterminatedby'\t';select*from search_log_copy;-- 通过insert select 语句加载其他表中的数据到当前表中insertintotable search_log_copy select*from search_log;select*from search_log_copy;
- insert覆盖数据
-- insert overwrite覆盖数据insert overwrite table search_log_copy select*from search_log;select*from search_log_copy;
总结:
1- 如果文件就在windows上面,可以通过直接上传文件的方式
2- 如果文件在linux操作系统上面,可以选择直接上传文件或者load加载文件
3- 如果我们是需要从其他表中将数据复制到我自己的表中,可以使用insert插入数据
2、文件数据导出
2.1 直接下载文件
- web页面下载
需求: 已知search_log.txt文件在HFDS的/user/hive/warehouse/day06.db/search_log路径下,要下载到window系统
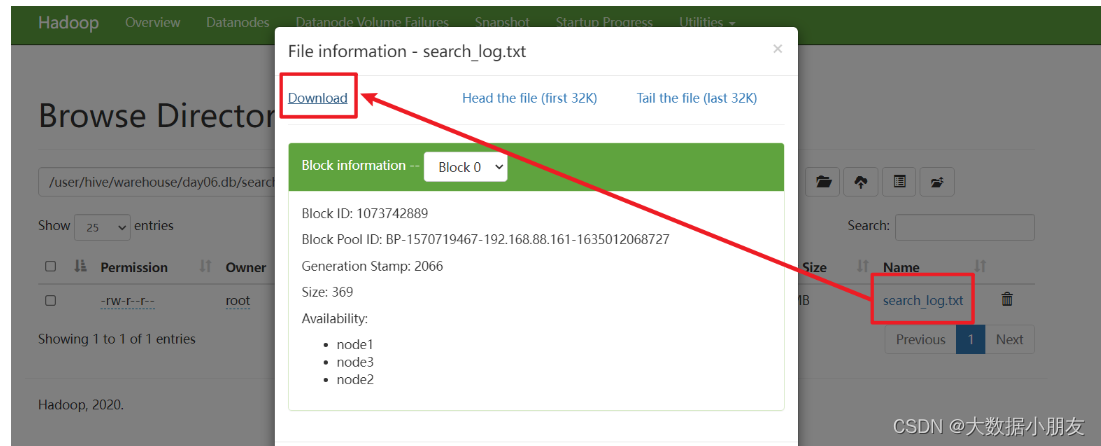
- get命令下载文件
需求: 已知search_log.txt文件在HFDS的/user/hive/warehouse/day06.db/search_log路径下,要下载到linux系统
[root@node1 home]# hdfs dfs -get /user/hive/warehouse/day06.db/search_log/search_log.txt .
2.2 insert导出数据
查询数据导出到hdfs其他路径: insert overwrite directory 'HDFS路径' select语句;
查询数据导出到linux本地中: insert overwrite local directory 'Linux路径' select语句;
注意:
1- overwrite会覆盖掉路径中已有的文件,千万注意。推荐指定一个新的空目录
2- 如果不指定分隔符,导出的文件中使用默认的Hive分隔符\001
导出数据指定分隔符添加(以HDFS为例):
insert overwrite directory '/dir'
row format delimited fields terminated by ','
select * from search_log;
- insert导出到hdfs
use day06;-- 将Hive表数据导出到HDFS的路径下-- overwrite:会覆盖指定目录中文件insert overwrite directory '/dir'select*from search_log;-- 指定分隔符insert overwrite directory '/dir'row format delimited fieldsterminatedby','select*from search_log;
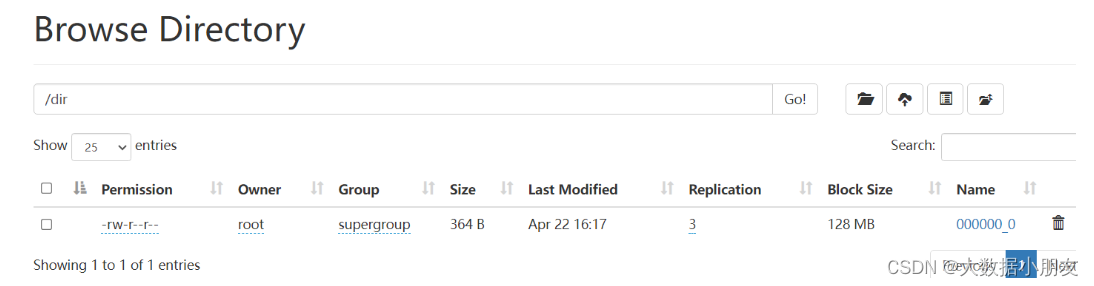
- insert导出linux
-- 将Hive表数据导出到Linux的路径下insert overwrite local directory '/home'row format delimited fieldsterminatedby','select*from search_log;
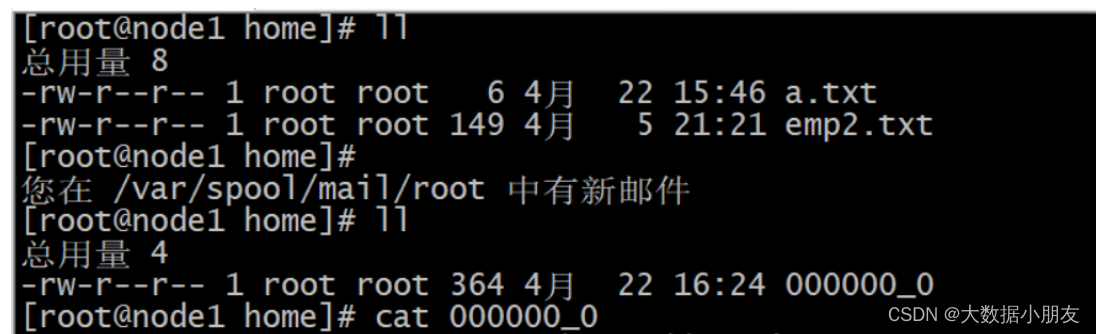
2.3 hive_shell命令
hive命令执行sql语句: hive -e "Hive 语句">存储该结果数据的Linux文件路径
hive命令执行sql脚本: hive -f hivesql文件>存储该结果数据的Linux文件路径
- hql语句导出
hive -e"select * from day06.search_log">/home/1.txt
- hql脚本导出(推荐)
[root@node1 home]# cat my_sql.sql select * from day06.search_log
hive -f my_sql.sql > /home/2.txt
- 总结1- 如果SQL语句比较简单,SQL的行数在3行以内,可以使用hive -e2- 如果SQL语句比较复杂,推荐使用hive -f
2.4 总结
1- 如果数据在Hive表的某一个文件中,可以使用直接下载文件的方式
2- 如果想将Hive表中的数据导出到HDFS路径,推荐使用insert overwrite导出命令
3- 如果只是想将Hive表中的数据导出到linux路径,可以使用insert overwrite导出命令或者hive sell命令
三、分区表
1、介绍
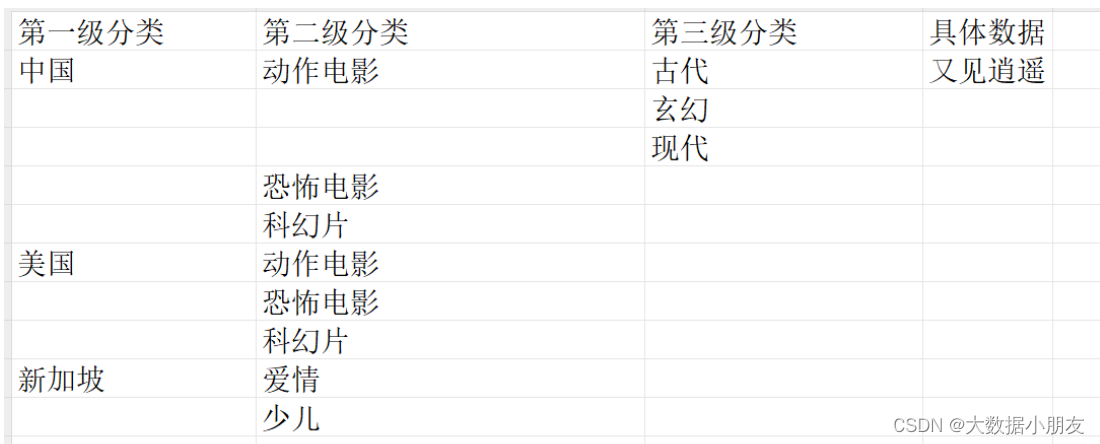
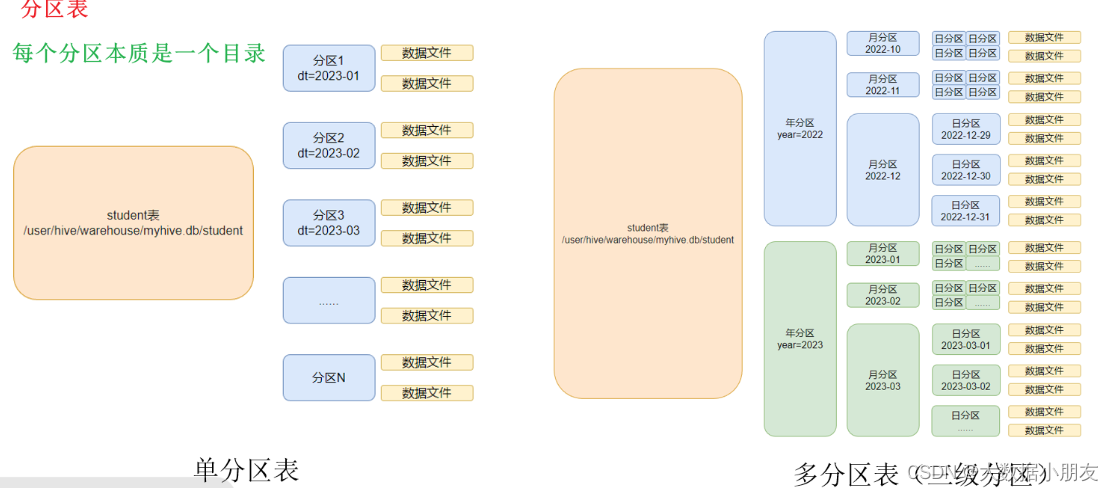
特点: 分区表会在HDFS上产生目录。查询数据的时候使用分区字段筛选数据,可以避免全表扫描,从而提升查询效率
注意: 如果是分区表,在查询数据的时候,如果没有使用分区字段,它回去进行全表扫描,会降低效率
只需要记住一点,分区表是用来提升Hive的数据分析效率
2、一级分区
知识点:
创建分区表: create [external] table [if not exists] 表名称(字段名称1 字段数据类型,字段名称2 字段数据类型..) partitioned by (分区字段 字段数据类型);
自动生成分区目录并插入数据: load data [local] inpath '文件路径' into table 表名称 partition (分区字段=值);
注意: 如果使用load导入数据,没有写local,文件路径就是HDFS上的路径。否则就是linux的路径
示例:
use day06;-- 1- 创建分区表createtable one_part_tb(
id int,
name string,
price double,
num int) partitioned by(yearint)row format delimited fieldsterminatedby' ';-- 2- 通过load将HDFS中的文件导入到Hive表中loaddata inpath '/source/order202251.txt'intotable one_part_tb partition(year=2022);loaddata inpath '/source/order202351.txt'intotable one_part_tb partition(year=2023);loaddata inpath '/source/order202352.txt'intotable one_part_tb partition(year=2023);loaddata inpath '/source/order2023415.txt'intotable one_part_tb partition(year=2023);-- 3- 数据验证select*from one_part_tb;-- 4- 使用分区select*from one_part_tb whereyear=2022;-- 5- 如果没有指定分区,那么会进行全表扫描,拖慢了效率select*from one_part_tb where price>=20;
3、多级分区
知识点:
创建分区表: create [external] table [if not exists] 表名称(字段名称1 字段数据类型,字段名称2 字段数据类型..) partitioned by (分区字段1 字段数据类型,分区字段2 字段数据类型...);
自动生成分区目录并插入数据: load data [local] inpath '文件路径' into table 表名称 partition (分区字段1=值,分区字段2=值....);
注意: 如果使用load导入数据,没有写local,文件路径就是HDFS上的路径。否则就是linux的路径
示例:
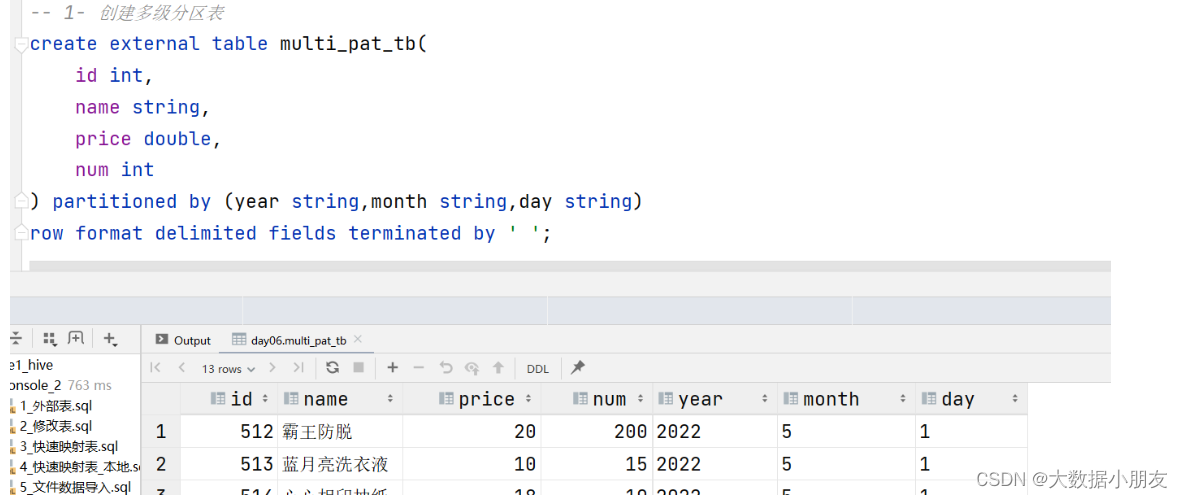
use day06;-- 1- 创建多级分区表create external table multi_pat_tb(
id int,
name string,
price double,
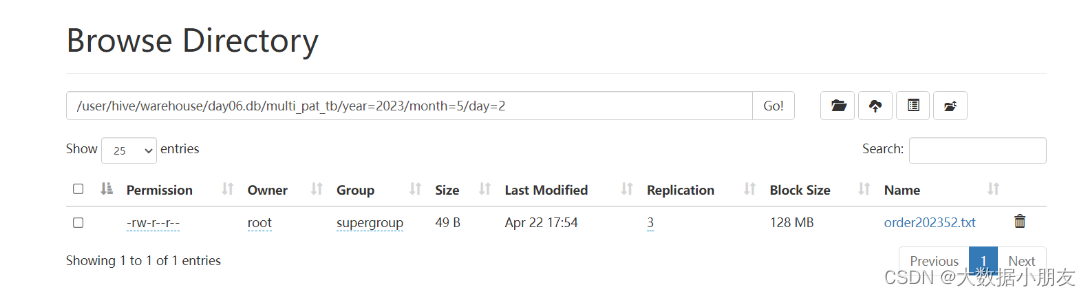
num int) partitioned by(year string,month string,day string)row format delimited fieldsterminatedby' ';-- 2- 加载HDFS数据到Hive表中loaddata inpath '/source/order202251.txt'intotable multi_pat_tb partition(year="2022",month="5",day="1");loaddata inpath '/source/order202351.txt'intotable multi_pat_tb partition(year="2023",month="5",day="1");loaddata inpath '/source/order202352.txt'intotable multi_pat_tb partition(year="2023",month="5",day="2");loaddata inpath '/source/order2023415.txt'intotable multi_pat_tb partition(year="2023",month="4",day="15");-- 3- 数据验证select*from multi_pat_tb;-- 4- 使用分区-- 注意: 如果是多分区,使用分区来提升效率的时候,需要根据需求来决定到底使用几个分区。并不需要所有的分区都用到-- 需求:要对2023全年的销售情况进行分析select*from multi_pat_tb whereyear="2023";-- 需求:要对2023年5月整个月的销售情况进行分析select*from multi_pat_tb whereyear="2023"andmonth="5";select*from multi_pat_tb whereyear="2023"andmonth="5"andday="2";-- 5- 不使用分区select*from multi_pat_tb where price>=20;
4、分区操作
知识点:
添加分区: alter table 分区表名 add partition (分区字段1=值,分区字段2=值..);
删除分区: alter table 分区表名 drop partition (分区字段1=值,分区字段2=值..);
修改分区名: alter table 分区表名 partition (分区字段1=旧分区值,分区字段2=旧分区值..) rename to partition (分区字段1=新分区值,分区字段2=新分区值..);
查看所有分区: show partitions 分区表名;
同步/修复分区: msck repair table 分区表名;
注意: 如果删除内部表的分区,那么对应的HDFS分区目录也被删除了;如果删除外部表的分区,那么对应的HDFS分区目录还保留着
示例:
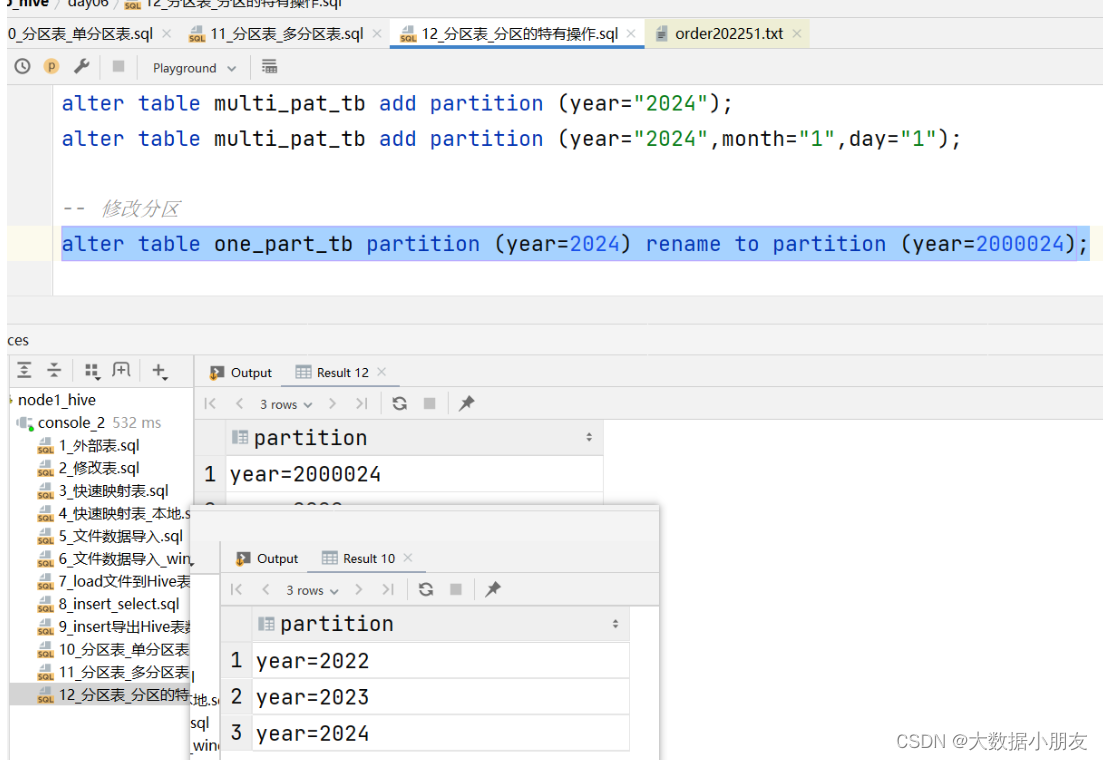
use day06;-- 查询表的分区信息show partitions one_part_tb;show partitions multi_pat_tb;-- 添加分区altertable one_part_tb addpartition(year=2024);-- 如果是多级分区,那么添加分区的时候,需要将所有的分区都添加上altertable multi_pat_tb addpartition(year="2024");altertable multi_pat_tb addpartition(year="2024",month="1",day="1");-- 修改分区altertable one_part_tb partition(year=2024)renametopartition(year=2000024);-- 删除分区-- 注意:如果删除内部表的分区,那么对应的分区目录也被删除了;如果删除外部表的分区,那么对应的HDFS分区目录还保留着altertable one_part_tb droppartition(year=2000024);altertable multi_pat_tb droppartition(year="2024",month="1",day="1");-- 修复分区-- 在执行下面的语句之前,需要手动去/user/hive/warehouse/day06.db/one_part_tb路径下创建一个year=2025分区目录
msck repair table one_part_tb;
给多级分区表添加分区遇到的错误:
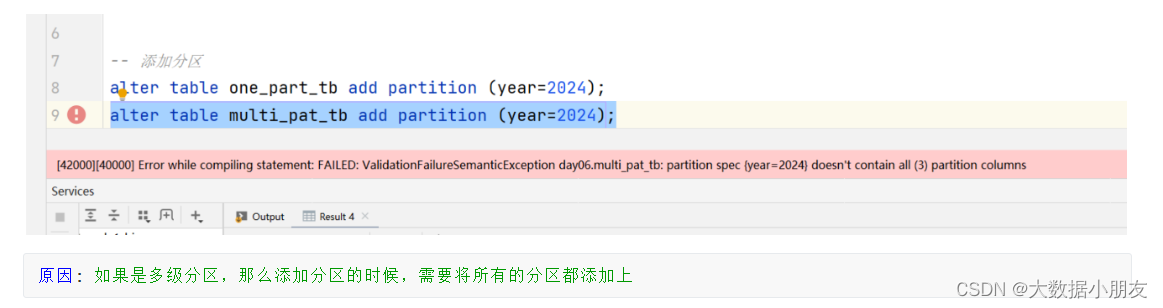
原因: 如果是多级分区,那么添加分区的时候,需要将所有的分区都添加上
修改分区效果:
四、官方文档(了解)
hive文档: https://cwiki.apache.org/confluence/display/Hive/Configuration+Properties
Hadoop官网使用说明文档: https://hadoop.apache.org/docs/stable/hadoop-mapreduce-client/hadoop-mapreduce-client-core/MapReduceTutorial.html
hdfs文档: https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
yarn文档: https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
mr文档: https://hadoop.apache.org/docs/stable/hadoop-mapreduce-client/hadoop-mapreduce-client-core/mapred-default.xml
五、分桶表(熟悉)
1、介绍
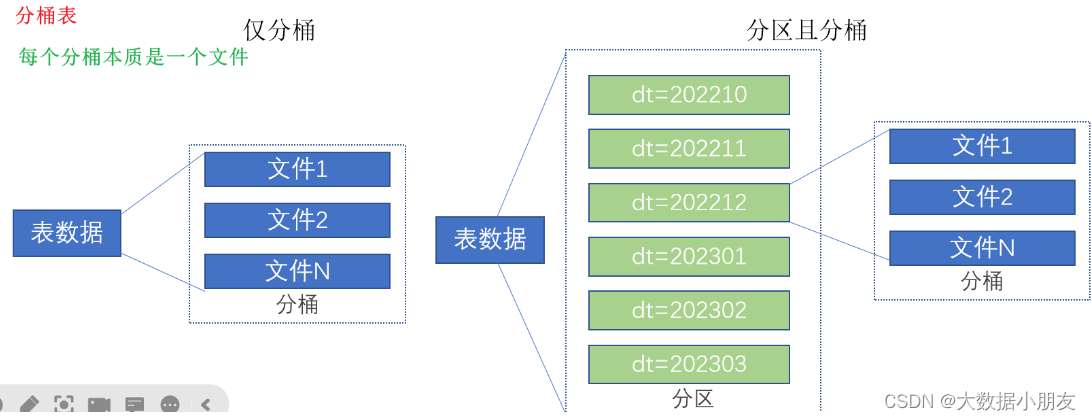
分桶表特点: 会产生分桶文件。
效率上注意: 查询数据的时候如果使用了分桶字段那么会提升数据查询效率(数据过滤where、join、分组、抽样查询);否则会进行全表扫描
分桶与分区的区别:
1- 分桶字段必须是原有的字段名称
2- 分桶产生的是多个文件;而分区产生的是多级目录
3- 分区和分桶可以同时用在同一张表中。但是只能先分区,再分桶;不能先分桶再分区,因为我们不能在文件中在去建立文件夹
2、重要参数(了解)
-- 默认开启,hive2.x版本已经被移除set hive.enforce.bucketing;-- 查看未定义因为已经被移除set hive.enforce.bucketing=true;-- 修改-- 查看reduce数量-- 参数优先级: set方式 > hive文档 > hadoop文档set mapreduce.job.reduces;-- 查看默认-1,代表自动根据桶数量匹配reduce数量set mapreduce.job.reduces=3;-- 设置参数
注意: 如果在SQL文件中设置的参数,那么只针对该会话(session)中的后续执行的SQL语句有效。其他会话中的SQL语句无效。
补充:
如何修改Hive中中文乱码的问题?
3、基础分桶表
知识点:
语法:
create [external] table [if not exists] 分桶表名称(
字段名称1 数据类型,
字段名称2 数据类型
....
)clustered by (分桶字段名称1,分桶字段名称2...) into 桶的数量 buckets;
示例:
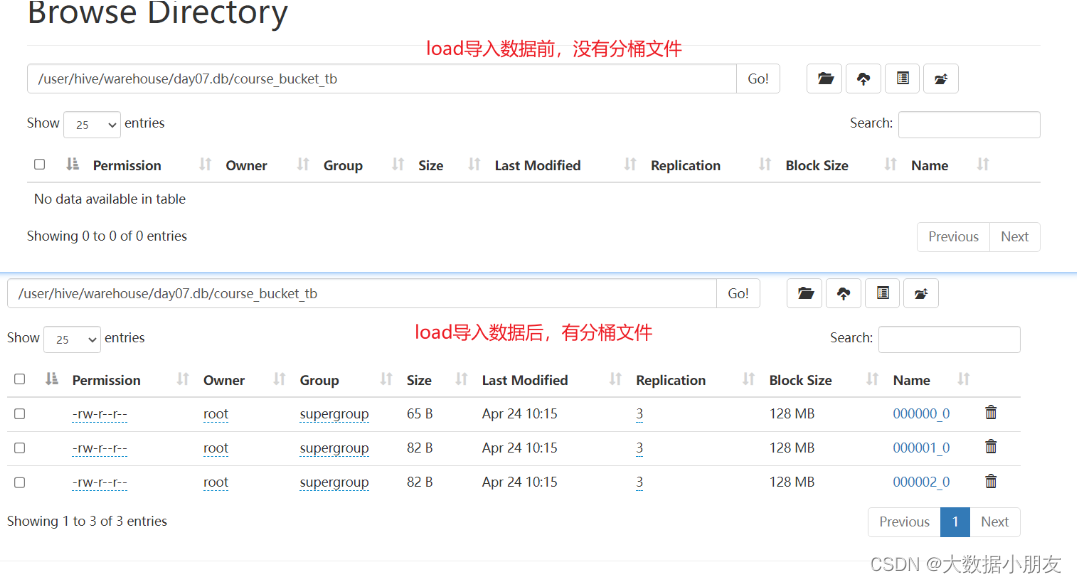
createdatabase day07;use day07;-- 创建分桶表createtable course_bucket_tb(
cid int,
cname string,
sname string
)clusteredby(cid)into3 buckets
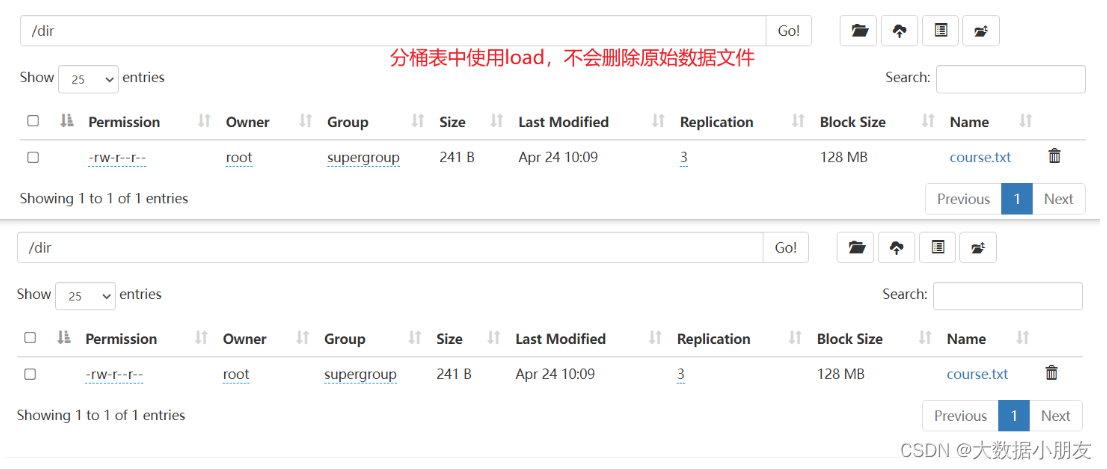
row format delimited fieldsterminatedby'\t';-- load方式将数据加载到Hive分桶表中loaddata inpath '/dir/course.txt'intotable course_bucket_tb;-- 查询数据select*from course_bucket_tb;
4、分桶表排序
知识点:
创建基础分桶表,然后桶内排序。语法:
create [external] table [if not exists] 分桶表名称(
字段名称1 数据类型,
字段名称2 数据类型
....
)
clustered by (分桶字段名称1,分桶字段名称2...)
sorted by (排序字段名称1,排序字段名称2...)
into 桶的数量 buckets;
注意:
1- 不管是clustered by还是sorted by这些字段,都只能去建表语句中选择已有的字段
2- sorted by中可以按照字段进行升序(asc ascend)或者降序(desc descend)。默认是升序。
3- clustered by中的字段与sorted by中的字段可以不一样
示例:
use day07;-- 创建分桶表并且排序create external table course_bucket_tb_sort(
cid int,
cname string,
sname string
)clusteredby(cid)-- 按照cid进行分桶
sorted by(cid desc)-- 按照cid进行降序排序into3 buckets -- 将数据分到3个桶里面去。也就是在HDFS上会创建3个文件row format delimited fieldsterminatedby'\t';-- 加载数据loaddata inpath '/dir/course.txt'intotable course_bucket_tb_sort;-- 验证数据select*from course_bucket_tb_sort;
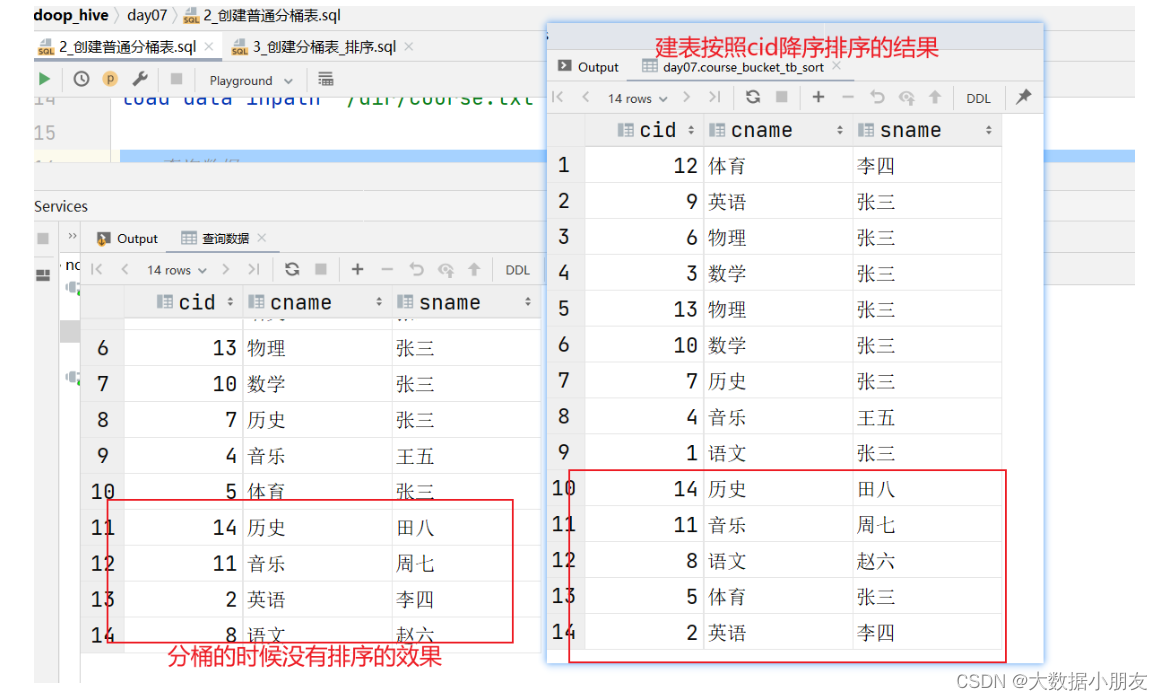
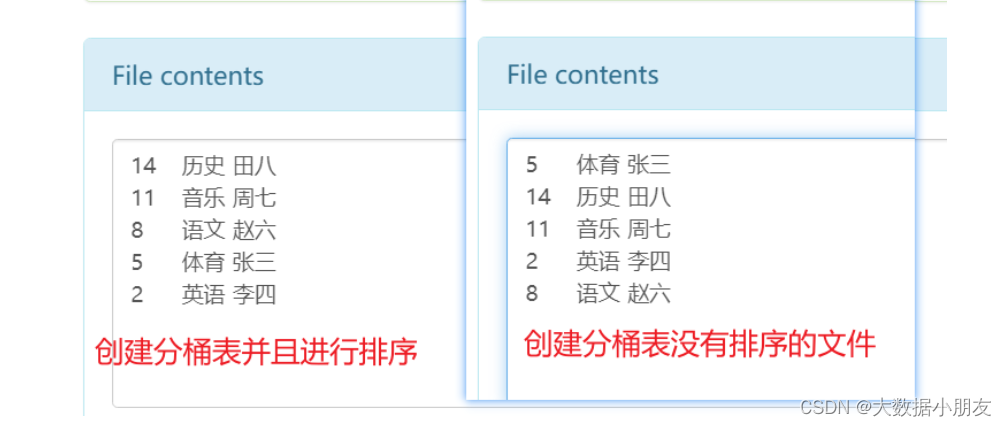
5、分桶原理
分桶原理
1.1- 如果分桶的字段是数值类型,那么直接使用字段字段与桶的数量进行取模运算,得到要放到哪个桶里面去。
1.2- 如果分桶的字段是字符串类型,那么先将字段值计算出一个Hash哈希值(是一个整数),然后拿着这个Hash值与桶的数量进行取模运算,得到要放到哪个桶里面去。
取模解释: 也就是取余数。10%3=1
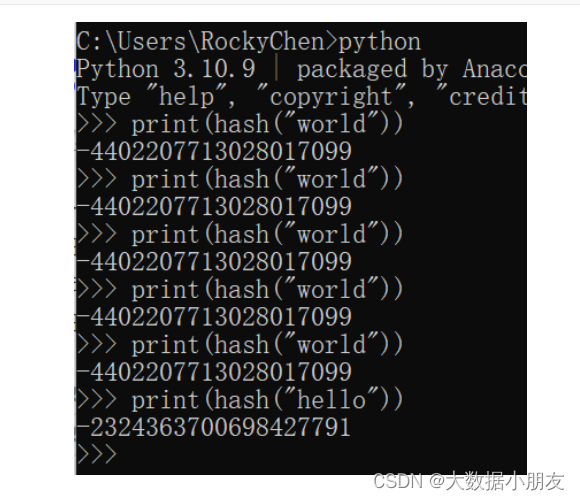
补充: 针对同一个内容,不管计算Hash值多少次,结果都是一样。例如下面world

6、分区表和分桶表区别
1- 分区表
创建表的时候使用关键字: partitioned by (字段名称 字段类型)
分区字段名注意事项: 分区字段不能在建表语句中存在
分区表好处: 数据查询的时候使用分区字段能够提升数据分析速度,也就是减少了数据扫描
分区表最直接的效果: 在HDFS下以分区字段和分区值创建了多级目录
不建议直接上传文件在hdfs表根路径下: 分区表直接不能自动识别HDFS上目录变化,分区信息必须要在MySQL元数据中存在,也就是需要单独使用msck repair修复语句进行修复
使用load方式加载hdfs中文件: 本质是移动文件到对应分区目录下
工作中的使用: 使用非常多。一般是按照日期时间进行分区
2- 分桶表
创建表的时候使用关键字: clustered by (分桶字段名) sorted by (排序字段) into 桶的数量 buckets
分桶字段名注意事项: 字段只能从建表语句中存在的字段进行挑选
分桶表好处: 使用分桶字段进行数据查询,例如:过滤、join、抽样查询等能够提升效率
分桶表最直接的效果: 在HDFS下创建分桶文件
不建议直接上传文件在hdfs表根路径下: 分桶表可以识别对应的文件中数据,但是并没有分桶的效果,不推荐使用
使用load方式加载hdfs中文件: 本质是复制文件内容到分桶文件中
工作中的使用: 使用很少。一般是结合业务进行分桶。例如将学生数据按照性别分成男性和女性俩个桶
六、复杂类型(熟悉)
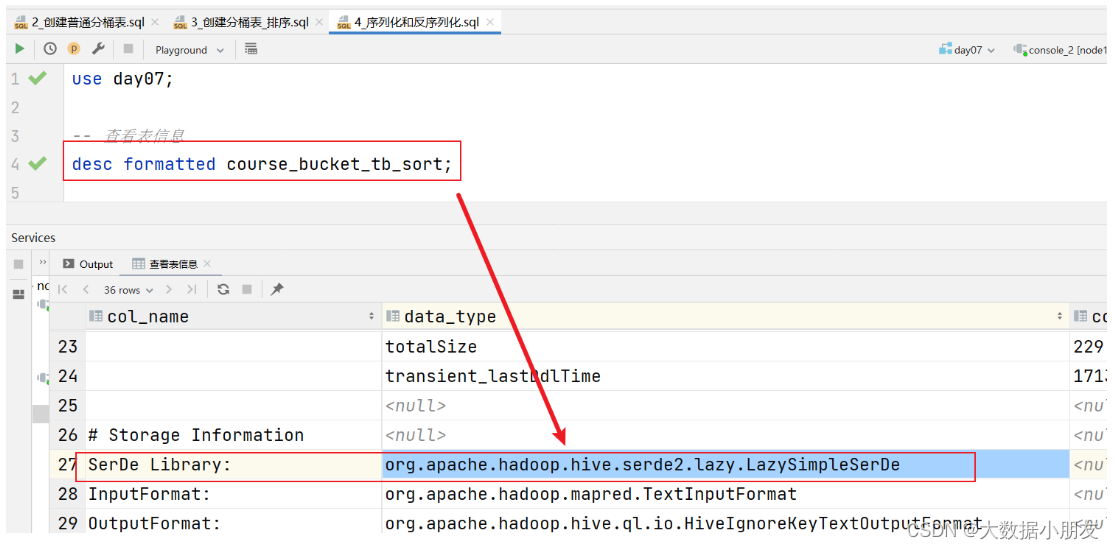
1、hvie的SerDe机制(了解)
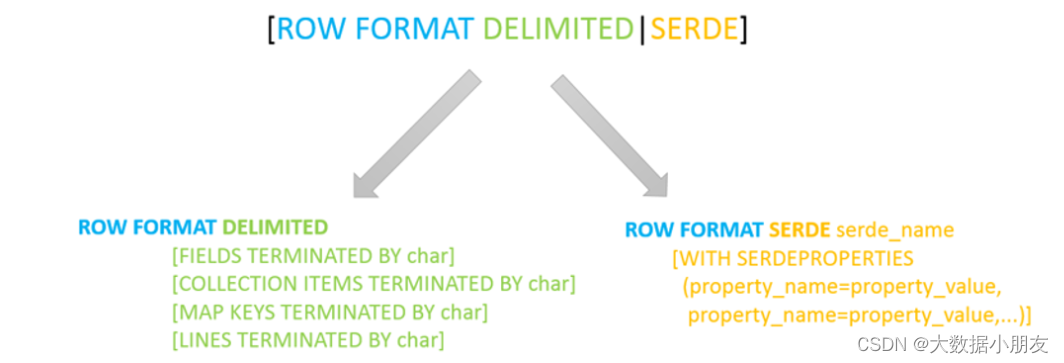
其中ROW FORMAT是语法关键字,DELIMITED和SERDE二选其一。本次我们主要学习DELIMITED关键字相关知识点
如果使用delimited: 表示底层默认使用的Serde类:LazySimpleSerDe类来处理数据。
如果使用serde:表示指定其他的Serde类来处理数据,支持用户自定义SerDe类。
Hive默认的序列化类: LazySimpleSerDe
包含4种子语法,分别用于指定字段之间、集合元素之间、map映射 kv之间、换行的分隔符号。
在建表的时候可以根据数据的类型特点灵活搭配使用。
COLLECTION ITEMS TERMINATED BY '分隔符' : 指定集合类型(array)/结构类型(struct)元素的分隔符
MAP KEYS TERMINATED BY '分隔符' : 表示映射类型(map)键值对之间用的分隔
2、复杂类型
复杂类型建表格式:
...
[row format delimited] # hive的serde机制
[fields terminated by '字段分隔符'] # 自定义字段分隔符固定格式
[collection ITEMS terminated by '集合分隔符'] # 自定义array同类型集合和struct不同类型集合
[map KEYS terminated by '键值对分隔符'] # 自定义map映射kv类型
[lines terminated by '\n'] # # 默认即可
...;
hive复杂类型: array struct map
array类型: 又叫做数组类型。用来存储相同类型的数据集合
建表指定类型: array<元素的数据类型>
取值: 字段名[索引/下标/角标]。索引是从0开始
获取长度: size(字段名)
判断是否包含某个数据: array_contains(字段名)
struct类型:又叫做结构类型。可以存储不同了类型的数据集合
建表指定类型: struct<字段名称1:数据类型,字段名称2:数据类型...>
取值: 字段名.key键的名称
map类型: 又叫做映射类型。存储的是key-value键值对数据
建表指定类型: map<key的类型,value的类型>
取值: 字段名[key的名称]
获取长度: size(字段名),实际获取的是key-value键值对的对数
获取所有key: map_keys(字段名)
获取所有value: map_values(字段名)
注意: 这3个复杂数据类型什么时候需要用到,都需要根据公司里面数据的结构来做决定
3、array示例
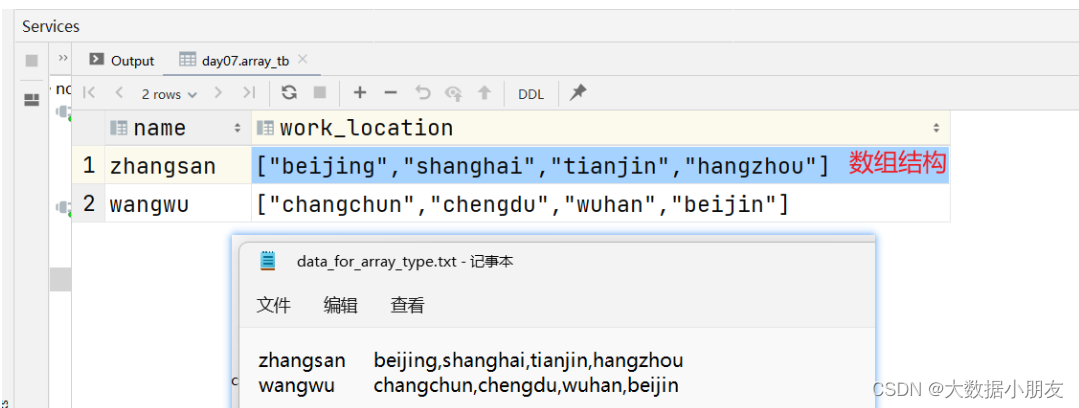
需求: 已知data_for_array_type.txt文件,存储了学生以及居住过的城市信息,要求建hive表把对应的数据存储起来
use day07;-- 创建表createtable array_tb(
name string,
work_location array<string>)row format delimited fieldsterminatedby'\t'
collection items terminatedby',';-- 指定array数组中元素间的分隔符-- load加载数据loaddata inpath '/dir/data_for_array_type.txt'intotable array_tb;-- 验证数据select*from array_tb;-- array专有的操作-- 函数:具备特殊功能的代码,例如size-- size(work_location) 统计数组中有多少个元素。该案例中也就是统计你去多少个城市工作过select name,size(work_location)as city_cnt from array_tb;-- 数组字段名称[索引/下标/角标]。索引是从0开始select name,work_location[-1]from array_tb;select name,work_location[0]from array_tb;-- 取数组中的第一个元素select name,work_location[1]from array_tb;-- 取数组中的第二个元素select name,work_location[10]from array_tb;-- 如果根据索引取不到对应的元素,那么返回的是null空值。null值(你没有去参加考试)和0(参加考试,但是考了0分)是不一样-- 判断数组中是否存在某个元素/数据-- array_contains:是一个函数,用来判断元素在数组中是否存在。如果存在返回true;如果不存在返回falseselect name,array_contains(work_location,"chengdu")from array_tb;
4、struct示例
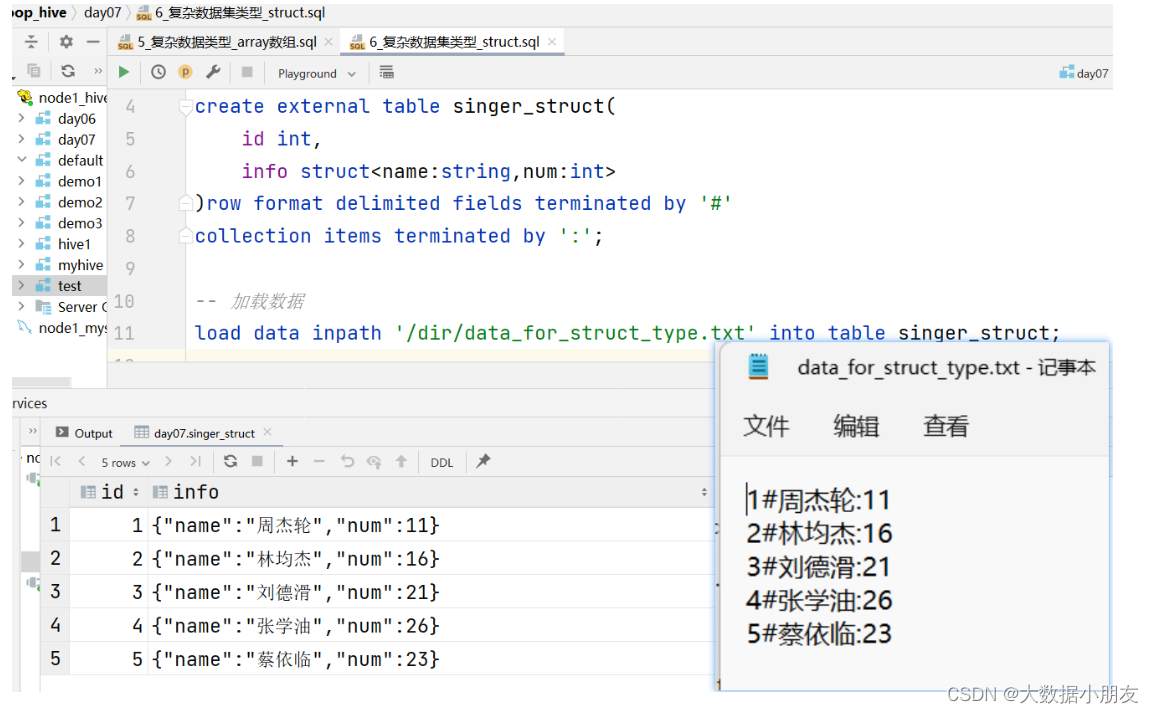
需求: 已知data_for_struct_type.txt文件存储了用户姓名和年龄基本信息,要求建hive表把对应的数据存储起来
use day07;-- 创建表create external table singer_struct(
id int,
info struct<name:string,num:int>)row format delimited fieldsterminatedby'#'
collection items terminatedby':';-- 指定struct中元素间的分隔符-- 加载数据loaddata inpath '/dir/data_for_struct_type.txt'intotable singer_struct;-- 验证数据select*from singer_struct;-- struct中特有的操作-- 如果想要看struct中的具体信息,需要通过 struct字段名称.key键select id,info.name,info.num from singer_struct;select id,info.name,info.num,info.aaaa from singer_struct;-- struct中不支持size()函数-- select id,size(info) from singer_struct;
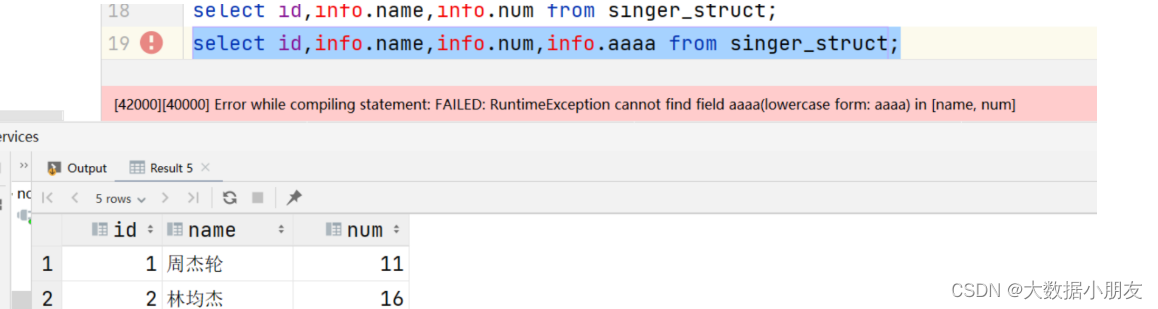
原因: 如果访问struct中不存在的key会报如上的问题。
5、map示例
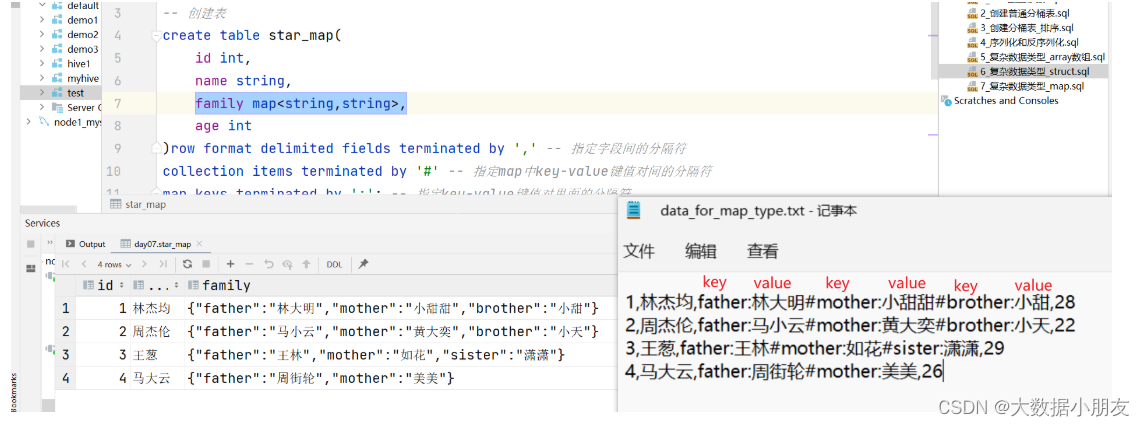
需求: 已知data_for_map_type.txt文件存储了每个学生详细的家庭信息,要求建hive表把对应数据存储起来
use day07;-- 创建表createtable star_map(
id int,
name string,
family map<string,string>,-- 前面的string是key的数据类型,后面的string是value的数据类型
age int)row format delimited fieldsterminatedby','-- 指定字段间的分隔符
collection items terminatedby'#'-- 指定map中key-value键值对间的分隔符
map keysterminatedby':';-- 指定key-value键值对里面的分隔符-- load导入数据到Hive表中loaddata inpath '/dir/data_for_map_type.txt'intotable star_map;-- 数据验证select*from star_map;-- map数据类型的特殊操作select id,name,age,family['father']as father,family['mother']as mother from star_map;-- 获取map中所有key的信息select id,name,age,map_keys(family)askeysfrom star_map;-- 获取map中所有key的信息,之后,再通过array获取数据的方式,获取指定索引的元素值select id,name,age,map_keys(family),map_keys(family)[1]askeysfrom star_map;-- 获取map中所有value的信息select id,name,age,map_values(family)askeysfrom star_map;-- 获取map中所有value的信息,之后,再通过array获取数据的方式,获取指定索引的元素值select id,name,age,map_values(family),map_values(family)[2]askeysfrom star_map;-- size函数:在map中,是用来获取key-value键值对的对数select id,name,age,size(family)from star_map;-- array_contains函数select id,name,age,map_keys(family),array_contains(map_keys(family),"brother")from star_map;
七、Hive乱码解决(操作。可以不做,不影响)
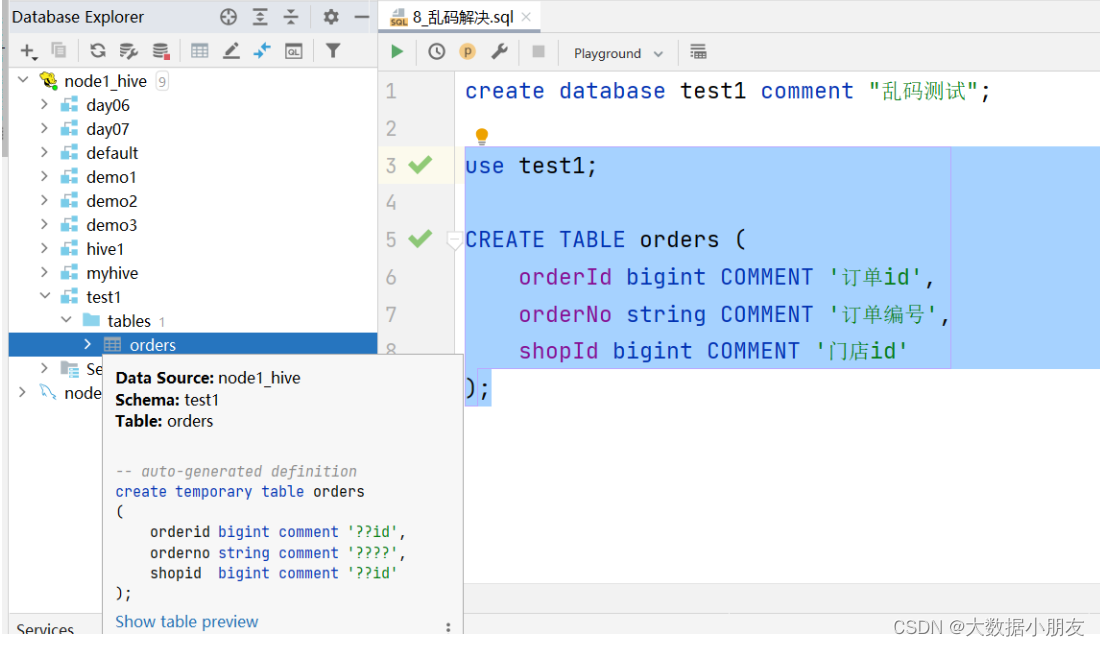
1、乱码现象
createdatabase test1 comment"乱码测试";use test1;CREATETABLE orders (
orderId bigintCOMMENT'订单id',
orderNo string COMMENT'订单编号',
shopId bigintCOMMENT'门店id');
2、处理步骤
- 注意:推荐大家先将node1虚拟机拍一个快照,拍完后再修改。
- 在node1上修改hive配置文件文件路径: /export/server/hive/conf/hive-site.xml修改内容:&useUnicode=true&characterEncoding=UTF-8修改截图:

- 修改MySQL表:注意,下面的SQL语句,要在node1的MySQL上运行
use hive3;#修改表字段注解和表注解altertable DBS modifycolumn`DESC`varchar(256)characterset utf8;altertable COLUMNS_V2 modifycolumnCOMMENTvarchar(256)characterset utf8;altertable TABLE_PARAMS modifycolumn PARAM_VALUE varchar(4000)characterset utf8;#修改分区字段注解altertable PARTITION_KEYS modifycolumn PKEY_COMMENT varchar(4000)characterset utf8;altertable PARTITION_PARAMS modifycolumn PARAM_VALUE varchar(4000)characterset utf8;#修改索引注解altertable INDEX_PARAMS modifycolumn PARAM_VALUE varchar(4000)characterset utf8;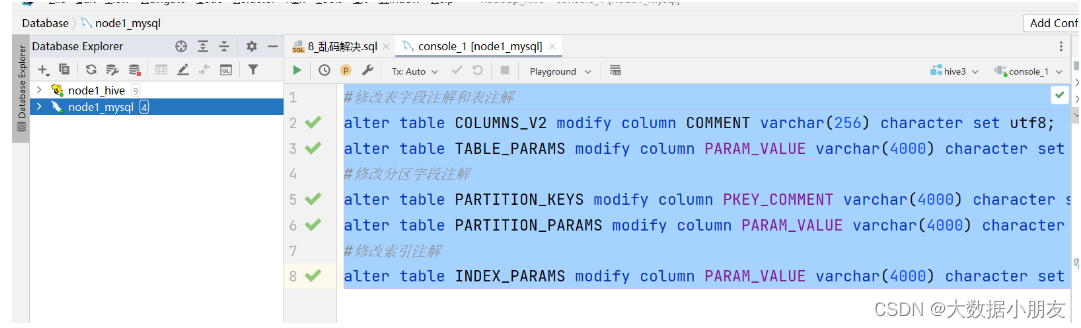
- 重启Hive的metastore进程先通过kill -9 杀死metastore进程。然后再通过 nohup hive --service metastore & 重启
- 验证
dropdatabase test1 cascade;createdatabase test1 comment"乱码测试";use test1;CREATETABLE orders ( orderId bigintCOMMENT'订单id', orderNo string COMMENT'订单编号', shopId bigintCOMMENT'门店id');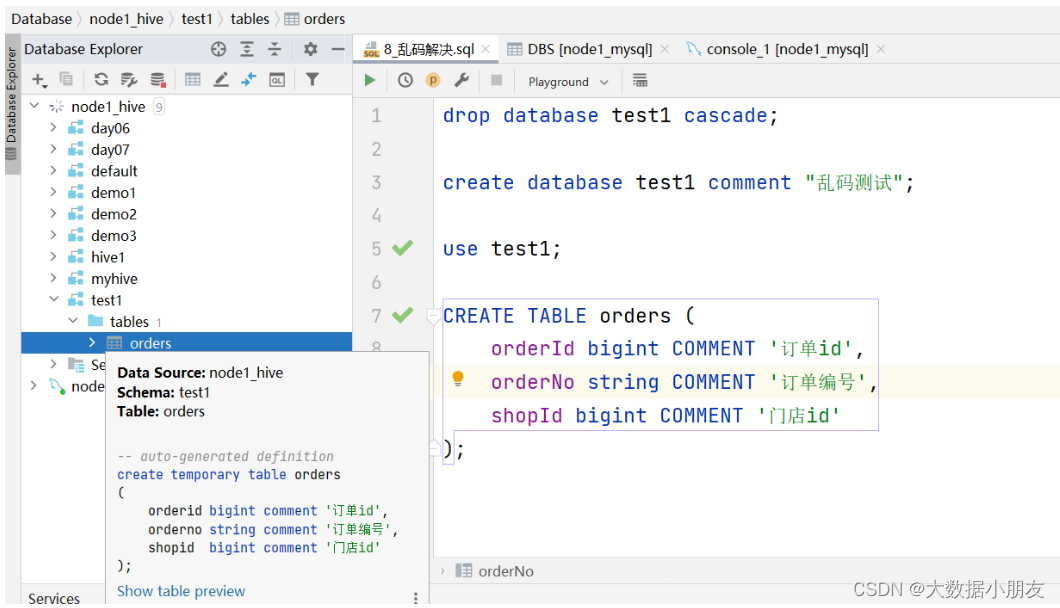
八、select查询(掌握)
1、类sql基本查询
use day07;-- 创建演示的表CREATETABLE day07.orders (
orderId bigintCOMMENT'订单id',
orderNo string COMMENT'订单编号',
shopId bigintCOMMENT'门店id',
userId bigintCOMMENT'用户id',
orderStatus tinyintCOMMENT'订单状态 -3:用户拒收 -2:未付款的订单 -1:用户取消 0:待发货 1:配送中 2:用户确认收货',
goodsMoney doubleCOMMENT'商品金额',
deliverMoney doubleCOMMENT'运费',
totalMoney doubleCOMMENT'订单金额(包括运费)',
realTotalMoney doubleCOMMENT'实际订单金额(折扣后金额)',
payType tinyintCOMMENT'支付方式,0:未知;1:支付宝,2:微信;3、现金;4、其他',
isPay tinyintCOMMENT'是否支付 0:未支付 1:已支付',
userName string COMMENT'收件人姓名',
userAddress string COMMENT'收件人地址',
userPhone string COMMENT'收件人电话',
createTime timestampCOMMENT'下单时间',
payTime timestampCOMMENT'支付时间',
totalPayFee intCOMMENT'总支付金额')ROW FORMAT DELIMITED FIELDSTERMINATEDBY'\t';-- load加载数据到表中loaddata inpath '/dir/itheima_orders.txt'intotable orders;-- 基础查询语句select*from orders;selectcount(*)as cnt from orders;-- 查询具体的字段。工作中推荐这样写,可以提升SQL运行效率,列裁剪select orderId,orderNo from orders;-- 取别名。as关键字可以省略,一般推荐加上-- 字段取别名-- 使用场景:1- 原始字段名称比较长的时候;2- 当多个表同时查询的时候,可能会出现重名select orderId as oid,orderNo ono from orders;-- 表取别名select orderId as oid,orderNo ono from orders as o;select o.orderId as oid,o.orderNo ono from orders as o;-- distinct去重selectdistinct shopId from orders;-- 演示where语句/*
比较运算符:> < >= <= != <>不等于
逻辑运算符:and并且 or或者 not取反/非
模糊查询:%匹配0到多个内容,_匹配仅且一个
空判断:为空 is null;不为空is not null
范围查询:
between 开始 and 结束
in (x,y,z)
*/-- 比较运算符select*from orders where orderId>=1and orderId<10;select*from orders where orderId<>1;-- 逻辑运算符select*from orders where orderId<1and orderId>10;select*from orders where orderId<1or orderId>10orderby orderId;select*from orders wherenot orderId<1;-- 模糊查询select*from orders where orderNo like'1%';-- % 匹配的个数 >=0select*from orders where userId like'__';-- _ 匹配的个数 ==1-- 空判断select*from orders where userId isnull;select*from orders where userId isnotnull;-- 范围查询select*from orders where userId between2and3;-- 左右都是闭区间 [2,3]。小的放前面,大的放后面select*from orders where userId between3and2;select*from orders where userId in(2,4);-- 通用函数使用-- 注意:在使用聚合函数的时候,需要把字段(维度字段)放到group by的语句-- 维度是X轴,指标是Y轴select userId,max(totalPayFee)as max_value from orders groupby userId;-- having:跟在group by的后面,对分组后的数据进行过滤select userId,max(totalPayFee)as max_value from orders groupby userId having userId=2;-- 分页-- limit x,y:注意x和y都是整数。x是从0开始,表示当页的第一条数据的索引;y每页的数据条数select*from orders orderby userId asclimit0,2;
使用聚合函数的时候容易犯的错误:
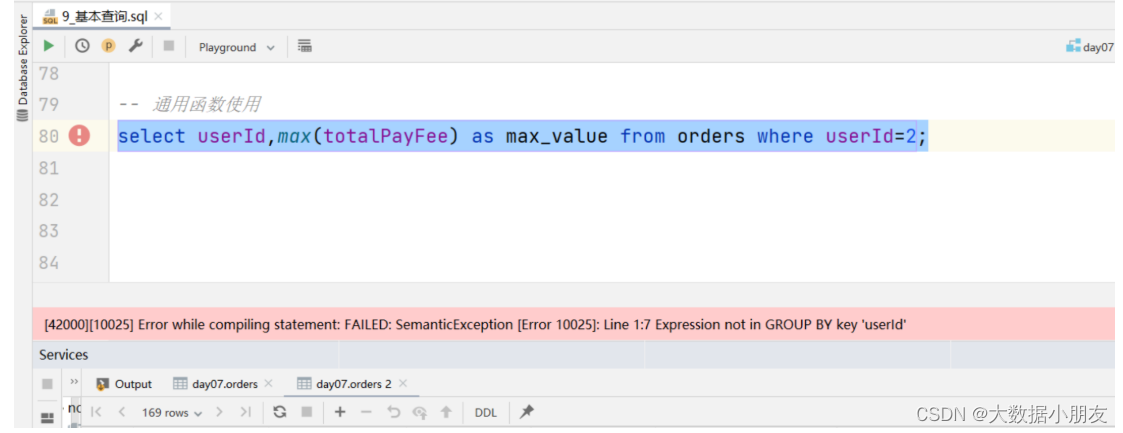
原因: 没有把字段(维度字段)放到group by的语句
2、类sql多表查询
use day07;CREATETABLE day07.users (
userId int,
loginName string,
loginSecret int,
loginPwd string,
userSex tinyint,
userName string,
trueName string,
brithday date,
userPhoto string,
userQQ string,
userPhone string,
userScore int,
userTotalScore int,
userFrom tinyint,
userMoney double,
lockMoney double,
createTime timestamp,
payPwd string,
rechargeMoney double)ROW FORMAT DELIMITED FIELDSTERMINATEDBY'\t';-- load导入数据loaddata inpath '/dir/itheima_users.txt'intotable users;-- 数据验证select*from users;-- cross join:交叉查询,会产生笛卡尔积。在工作中,要尽可能避免产生笛卡尔积select*from users crossjoin orders;selectcount(*)as cnt from users crossjoin orders;-- inner join:内连接本质是取两个表的交集select*from users as u innerjoin orders as o on u.userId=o.userId;-- left outer join:左外关联。以左边的表为主表,取匹配上的数据。差集select*from users as u leftouterjoin orders as o on u.userId=o.userId;-- right outer join:右外关联。以右边的表为主表,取匹配上的数据。差集select*from orders as o rightouterjoin users as u on u.userId=o.userId;-- 子查询-- 获得最高订单金额的用户ID-- 1- 获得最高的订单金额;2- 拿着最高金额,作为数据过滤条件,去找到对应的用户selectmax(totalMoney)as max_money from orders;select userId from orders where totalmoney=(selectmax(totalMoney)as max_money from orders);
3、hive整体语句格式
SELECT [ALL | DISTINCT]字段名称1,字段名称2, ...
FROM 表名称
[WHERE 数据过滤条件]
[GROUP BY 分组字段名称1,分组字段名称2...]
[HAVING 分组之后的数据过滤条件]
[ORDER BY 排序字段名称1,排序字段名称2...]
[CLUSTER BY 分桶排序的字段名1,分桶排序的字段名2... | [DISTRIBUTE BY 分桶字段名1,分桶字段名2...] [SORT BY 排序的字段名1,排序的字段名2...]]
[LIMIT 分页配置]
4、hive其他join操作
知识点:
在Hive中除了cross join left outer join等这些以外,还有left semi join(左半连接)、full outer join(全外连接)
全外连接: 左表 full outer join 右表 on 关联条件
左半开连接: 左表 left semi join 右表 on 关联条件
示例:
-- 全外连接:full outer join on 大白话解释:左外和右外结果合并select*from users u fullouterjoin orders o on u.userId = o.userid;-- 左半连接:left semi join onselect*from users u left semi join orders o on u.userId = o.userid;
hive中所有join的演示:
use day07;createtable tb_1(
id int,
name string
)row format delimited fieldsterminatedby',';createtable tb_2(
id int,
name string
)row format delimited fieldsterminatedby',';select*from tb_1;select*from tb_2;-- cross join:产生笛卡尔积,tb_1 * tb_2。写SQL的时候,尽可能避免select*from tb_1 crossjoin tb_2;-- left outer join:以左表为主,将左表中所有的数据都展示,只展示右表中关联上的内容select*from tb_1 leftouterjoin tb_2 on tb_1.id=tb_2.id;-- right outer join:以右表为主,将右表中所有的数据都展示,只展示左表中关联上的内容select*from tb_1 rightouterjoin tb_2 on tb_1.id=tb_2.id;-- full outer join:实际是左右join的结果合并。也就是现在没有哪个是主表,地位都是一样的select*from tb_1 fullouterjoin tb_2 on tb_1.id=tb_2.id;-- left semi join:左半连接,左右表关联,关联上了以后,只展示左表的数据,右表数据不展示。如果有数据重复,不会去重select*from tb_1 left semi join tb_2 on tb_1.id=tb_2.id;-- 没有right semi join。可以交换表的位置然后通过left semi join来实现-- select * from tb_1 right semi join tb_2 on tb_1.id=tb_2.id;select*from tb_2 left semi join tb_1 on tb_1.id=tb_2.id;

版权归原作者 大数据小朋友 所有, 如有侵权,请联系我们删除。