
参考文章:Baseline model for "GraspNet-1Billion: A Large-Scale Benchmark for General Object Grasping" (CVPR 2020).[paper] [dataset] [API] [doc]
一、下载graspnet
1、安装
获取代码
git clone https://github.com/graspnet/graspnet-baseline.git
cd graspnet-baseline
通过 Pip 安装软件包
pip install -r requirements.txt
编译并安装 pointnet2
cd pointnet2
python setup.py install
编译并安装 knn
cd knn
python setup.py install
安装graspnetAPI,将它的包文件放置在graspnet的环境中
git clone https://github.com/graspnet/graspnetAPI.git
cd graspnetAPI
pip install .
手动构建文档
cd docs
pip install -r requirements.txt
bash build_doc.sh
2、环境构建
安装需要的软件包
- Python 3
- PyTorch 1.6
- Open3d >=0.8
- TensorBoard 2.3
- NumPy
- SciPy
- Pillow
- tqdm
3、生成标签
从 Google Drive/Baidu Pan 下载
运行程序生成:
mv tolerance.tar dataset/
cd dataset
tar -xvf tolerance.tar
4、下载预权重
预训练权重可以从以下位置下载:
checkpoint-rs.tar[谷歌云端硬盘] [百度盘]checkpoint-kn.tar[谷歌云端硬盘] [百度盘]
checkpoint-rs.tar
和
checkpoint-kn.tar
是分别使用 RealSense 数据和 Kinect 数据进行训练。
二、demo复现
1、编辑配置
打开demo.py,在pycharm右上方的位置,展开,选择编辑配置
在形参那里输入预训练权重
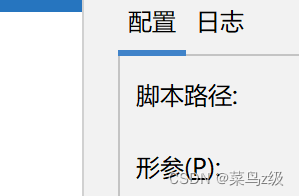
根据下载的权重输入形参,注意后面的路径要修改为自己存储文件的位置
--checkpoint_path logs/log_kn/checkpoint.tar
--dump_dir logs/dump_rs --checkpoint_path logs/log_rs/checkpoint.tar --camera realsense --dataset_root /data/Benchmark/graspnet
--log_dir logs/log_rs --batch_size 2
形参输入格式
--形参1 路径1 --形参2 路径2
2、复现演示
在graspnet-baseline/doc/example_data里可以查看输入图片

运行demo.py可以得到3D展示图,生成了6D抓取位姿
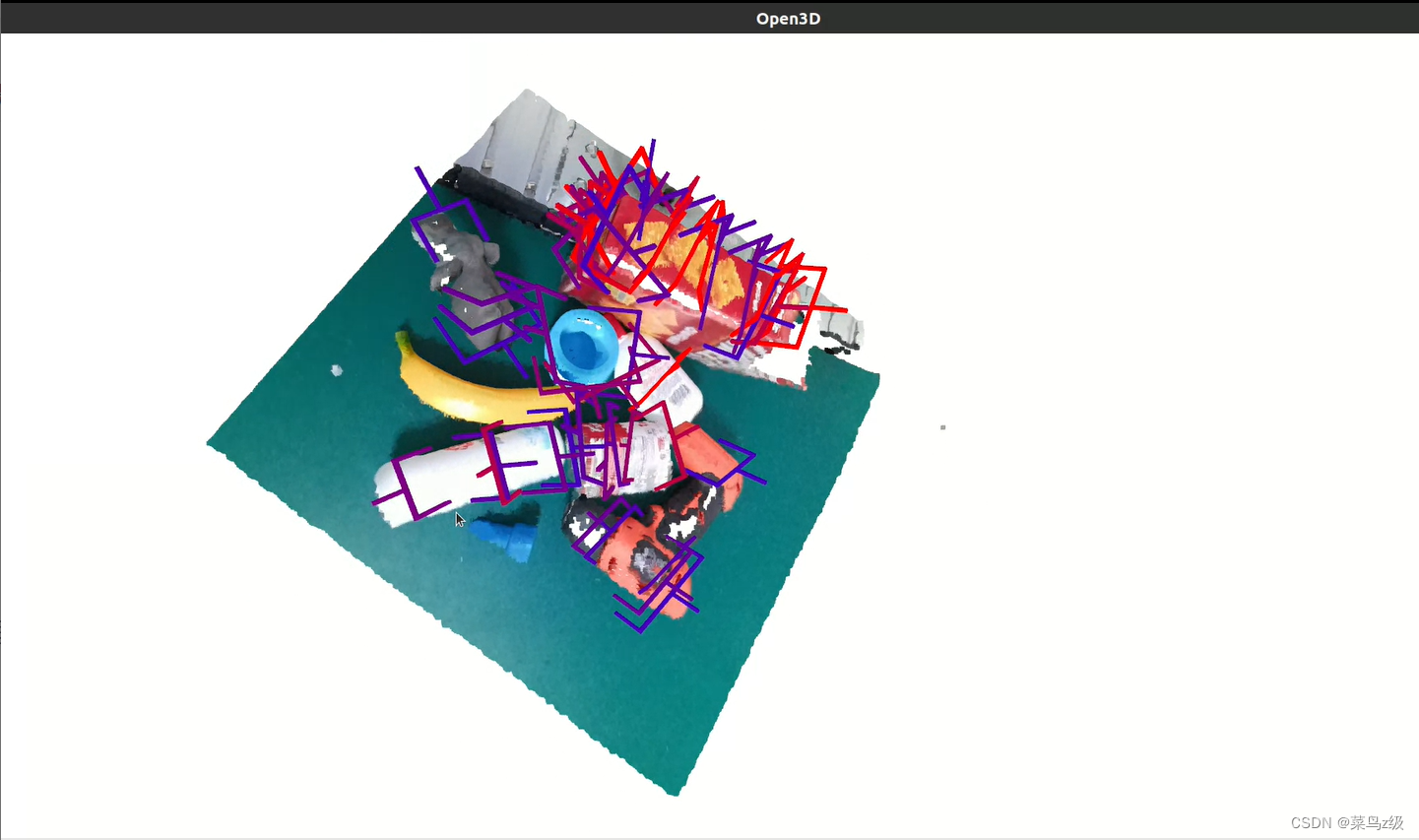
结束展示
三、采用自己的数据集实现抓取预测
1、数据介绍
使用realsensel515实感相机,使用数据线连接电脑
realsensel515相机参数
factor_depth 4000 深度转换值
intrinsic_matrix 相机内部参数
1351.720979.2601352.93556.038001
2、数据输入
软件包配置
pyrealsense2
cv2
实现实际场景的输入,成功转化为图片形式, 用于抓取输入
将depth_image与color_image对齐
修改相机内部参数(焦距、光学中心) 及深度转化值
完整代码
""" Demo to show prediction results.
Author: chenxi-wang
"""
import os
import sys
import numpy as np
import open3d as o3d
import argparse
import importlib
import scipy.io as scio
from PIL import Image
import torch
from graspnetAPI import GraspGroup
import pyrealsense2 as rs
import cv2
from matplotlib import pyplot as plt
ROOT_DIR = os.path.dirname(os.path.abspath(__file__))
sys.path.append(os.path.join(ROOT_DIR, 'models'))
sys.path.append(os.path.join(ROOT_DIR, 'dataset'))
sys.path.append(os.path.join(ROOT_DIR, 'utils'))
from models.graspnet import GraspNet, pred_decode
from graspnet_dataset import GraspNetDataset
from collision_detector import ModelFreeCollisionDetector
from data_utils import CameraInfo, create_point_cloud_from_depth_image
parser = argparse.ArgumentParser()
parser.add_argument('--checkpoint_path', required=True, help='Model checkpoint path')
parser.add_argument('--num_point', type=int, default=20000, help='Point Number [default: 20000]')
parser.add_argument('--num_view', type=int, default=300, help='View Number [default: 300]')
parser.add_argument('--collision_thresh', type=float, default=0.01, help='Collision Threshold in collision detection [default: 0.01]')
parser.add_argument('--voxel_size', type=float, default=0.01, help='Voxel Size to process point clouds before collision detection [default: 0.01]')
cfgs = parser.parse_args()
def get_net():
# Init the model
net = GraspNet(input_feature_dim=0, num_view=cfgs.num_view, num_angle=12, num_depth=4,
cylinder_radius=0.05, hmin=-0.02, hmax_list=[0.01,0.02,0.03,0.04], is_training=False)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
net.to(device)
# Load checkpoint
checkpoint = torch.load(cfgs.checkpoint_path)
net.load_state_dict(checkpoint['model_state_dict'])
start_epoch = checkpoint['epoch']
print("-> loaded checkpoint %s (epoch: %d)"%(cfgs.checkpoint_path, start_epoch))
# set model to eval mode
net.eval()
return net
def get_and_process_data(data_dir):
# load data
color = np.array(Image.open(os.path.join(data_dir, 'color.png')), dtype=np.float32) / 255.0
depth = np.array(Image.open(os.path.join(data_dir, 'depth.png')))
workspace_mask = np.array(Image.open(os.path.join(data_dir, 'workspace_mask.png')))
meta = scio.loadmat(os.path.join(data_dir, 'meta.mat'))# Resize depth to match color image resolution while preserving spatial alignment
color_height, color_width = color.shape[:2]
depth = cv2.resize(depth, (color_width, color_height), interpolation=cv2.INTER_NEAREST)
intrinsic = meta['intrinsic_matrix']
factor_depth =meta['factor_depth']
# generate cloud
camera = CameraInfo(1280.0, 720.0, intrinsic[0][0], intrinsic[1][1], intrinsic[0][2], intrinsic[1][2], factor_depth)
cloud = create_point_cloud_from_depth_image(depth, camera, organized=True)
# get valid points
mask = (workspace_mask & (depth > 0))
cloud_masked = cloud[mask]
color_masked = color[mask]
# sample points
if len(cloud_masked) >= cfgs.num_point:
idxs = np.random.choice(len(cloud_masked), cfgs.num_point, replace=False)
else:
idxs1 = np.arange(len(cloud_masked))
idxs2 = np.random.choice(len(cloud_masked), cfgs.num_point-len(cloud_masked), replace=True)
idxs = np.concatenate([idxs1, idxs2], axis=0)
cloud_sampled = cloud_masked[idxs]
color_sampled = color_masked[idxs]
# convert data
cloud = o3d.geometry.PointCloud()
cloud.points = o3d.utility.Vector3dVector(cloud_masked.astype(np.float32))
cloud.colors = o3d.utility.Vector3dVector(color_masked.astype(np.float32))
end_points = dict()
cloud_sampled = torch.from_numpy(cloud_sampled[np.newaxis].astype(np.float32))
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
cloud_sampled = cloud_sampled.to(device)
end_points['point_clouds'] = cloud_sampled
end_points['cloud_colors'] = color_sampled
return end_points, cloud
def get_grasps(net, end_points):
# Forward pass
with torch.no_grad():
end_points = net(end_points)
grasp_preds = pred_decode(end_points)
gg_array = grasp_preds[0].detach().cpu().numpy()
gg = GraspGroup(gg_array)
return gg
def collision_detection(gg, cloud):
mfcdetector = ModelFreeCollisionDetector(cloud, voxel_size=cfgs.voxel_size)
collision_mask = mfcdetector.detect(gg, approach_dist=0.05, collision_thresh=cfgs.collision_thresh)
gg = gg[~collision_mask]
return gg
def vis_grasps(gg, cloud):
gg.nms()
gg.sort_by_score()
gg = gg[:50]
grippers = gg.to_open3d_geometry_list()
o3d.visualization.draw_geometries([cloud, *grippers])
def demo(data_dir):
net = get_net()
end_points, cloud = get_and_process_data(data_dir)
gg = get_grasps(net, end_points)
if cfgs.collision_thresh > 0:
gg = collision_detection(gg, np.array(cloud.points))
vis_grasps(gg, cloud)
def input1():
# Create a pipeline
pipeline = rs.pipeline()
# Create a config object to configure the pipeline
config = rs.config()
config.enable_stream(rs.stream.depth, 1024, 768, rs.format.z16, 30)
config.enable_stream(rs.stream.color, 1280, 720, rs.format.bgr8, 30)
# Start the pipeline
pipeline.start(config)
align = rs.align(rs.stream.color) # Create align object for depth-color alignment
try:
while True:
# Wait for a coherent pair of frames: color and depth
frames = pipeline.wait_for_frames()
aligned_frames = align.process(frames)
if not aligned_frames:
continue # If alignment fails, go back to the beginning of the loop
color_frame = aligned_frames.get_color_frame()
aligned_depth_frame = aligned_frames.get_depth_frame()
if not color_frame or not aligned_depth_frame:
continue
# Convert aligned_depth_frame and color_frame to numpy arrays
aligned_depth_image = np.asanyarray(aligned_depth_frame.get_data())
color_image = np.asanyarray(color_frame.get_data())
# Display the aligned depth image
aligned_depth_colormap = cv2.applyColorMap(cv2.convertScaleAbs(aligned_depth_image, alpha=0.03),
cv2.COLORMAP_JET)
cv2.imshow("Aligned Depth colormap", aligned_depth_colormap)
cv2.imshow("Aligned Depth Image", aligned_depth_image)
cv2.imwrite('./data1/depth.png', aligned_depth_image)
# Display the color image
cv2.imshow("Color Image", color_image)
cv2.imwrite('./data1/color.png', color_image)
# Press 'q' to quit
if cv2.waitKey(1) & 0xFF == ord('q'):
break
finally:
# Stop the pipeline and close all windows
pipeline.stop()
cv2.destroyAllWindows()
if __name__=='__main__':
input1()
data_dir = 'data1'
demo(data_dir)
其中dada1为自己的数据文件,里面包含
color.png 自己相机生成的彩色图
depth.png 与彩色图对齐后的深度图
workspace.png 从demo数据文件中直接复制过来
meta.mat 复制demo数据文件的meta.mat,将里面的参数修改为自己相机的参数
记得权重赋予与demo.py一致
3、结果展示
彩色图 RGB

深度图

生成6d抓取位姿及3d图

4、只保留最优抓取位姿
修改部分代码
def vis_grasps(gg, cloud, num_top_grasps=10):
gg.nms()
gg.sort_by_score(reverse=True) # Sort the grasps in descending order of scores
gg = gg[:num_top_grasps] # Keep only the top num_top_grasps grasps
grippers = gg.to_open3d_geometry_list()
o3d.visualization.draw_geometries([cloud, *grippers])
运行程序

实验结束
版权归原作者 菜鸟z级 所有, 如有侵权,请联系我们删除。