
文章目录
SparkBase环境基础
Spark学习方法:不断重复,28原则(使用80%时间完成20%重要内容)
Spark框架概述
Spark风雨十年s
- 2012年Hadoop1.x出现,里程碑意义
- 2013年Hadoop2.x出现,改进HDFS,Yarn,基于Hadoop1.x框架提出基于内存迭代式计算框架Spark
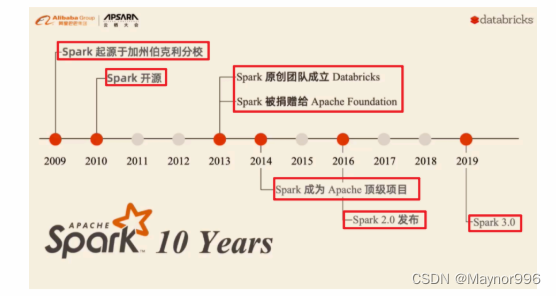
- 1-Spark全家桶,实现离线,实时,机器学习,图计算
- 2-spark版本从2.x到3.x很多优化
- 3-目前企业中最多使用Spark仍然是在离线处理部分,SparkSQL On Hive
Spark 是什么
- Spark是一个处理大规模数据的计算引擎

扩展阅读:Spark VS Hadoop
- Spark和Hadoop对比
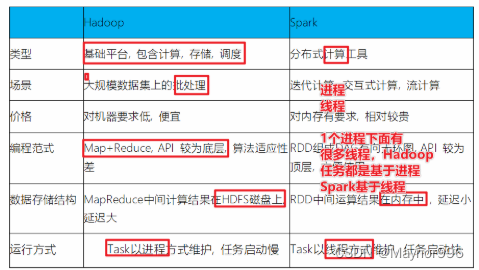
- 面试题:Hadoop的基于进程的计算和Spark基于线程方式优缺点?
答案:Hadoop中的MR中每个map/reduce task都是一个java进程方式运行,好处在于进程之间是互相独立的,每个task独享进程资源,没有互相干扰,监控方便,但是问题在于task之间不方便共享数据,执行效率比较低。比如多个map task读取不同数据源文件需要将数据源加载到每个map task中,造成重复加载和浪费内存。而基于线程的方式计算是为了数据共享和提高执行效率,Spark采用了线程的最小的执行单位,但缺点是线程之间会有资源竞争。
Spark 四大特点
1-速度快
2-非常好用
3-通用性
4-运行在很多地方


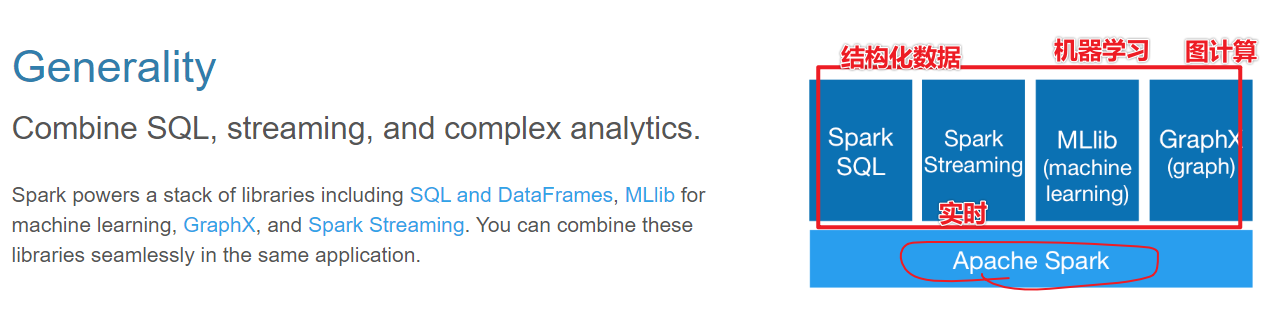
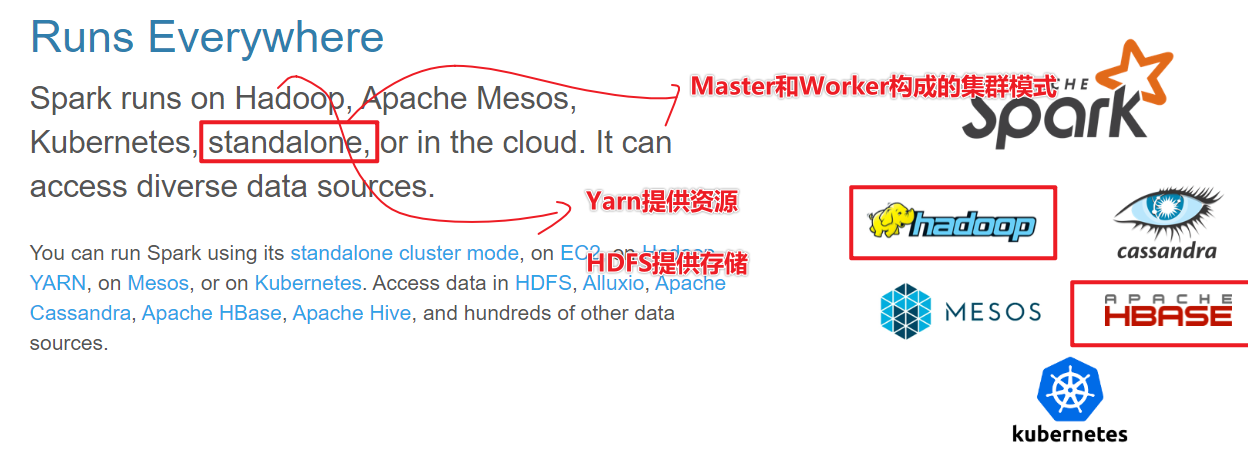
Spark 框架模块了解
- Spark框架通信使用Netty框架,通信框架
- Spark数据结构:核心数据RDD(弹性 分布式Distrubyte 数据集dataset),DataFrame
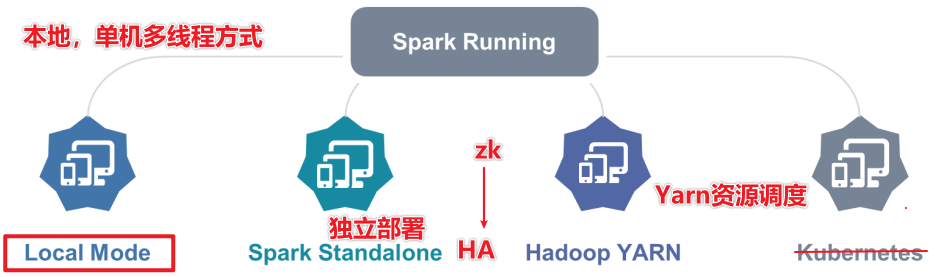
- Spark部署模式(环境搭建)
- local - local 单个线程- local[*] 本地所有线程- local【k】 k个线程- Spark的RDD有很多分区,基于线程执行分区数据计算,并行计算
- standalone
- StandaloneHA
- Yarn
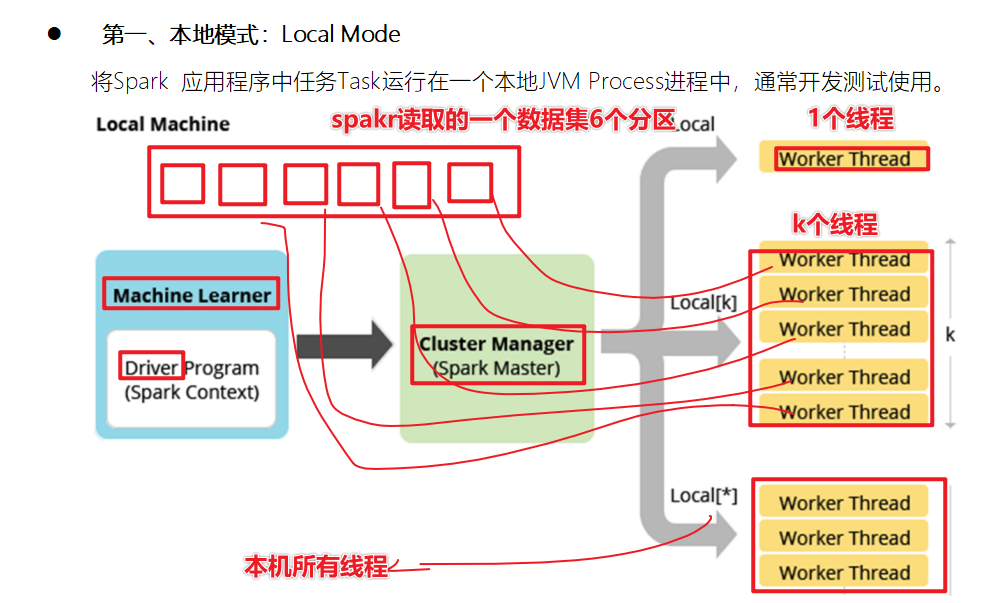
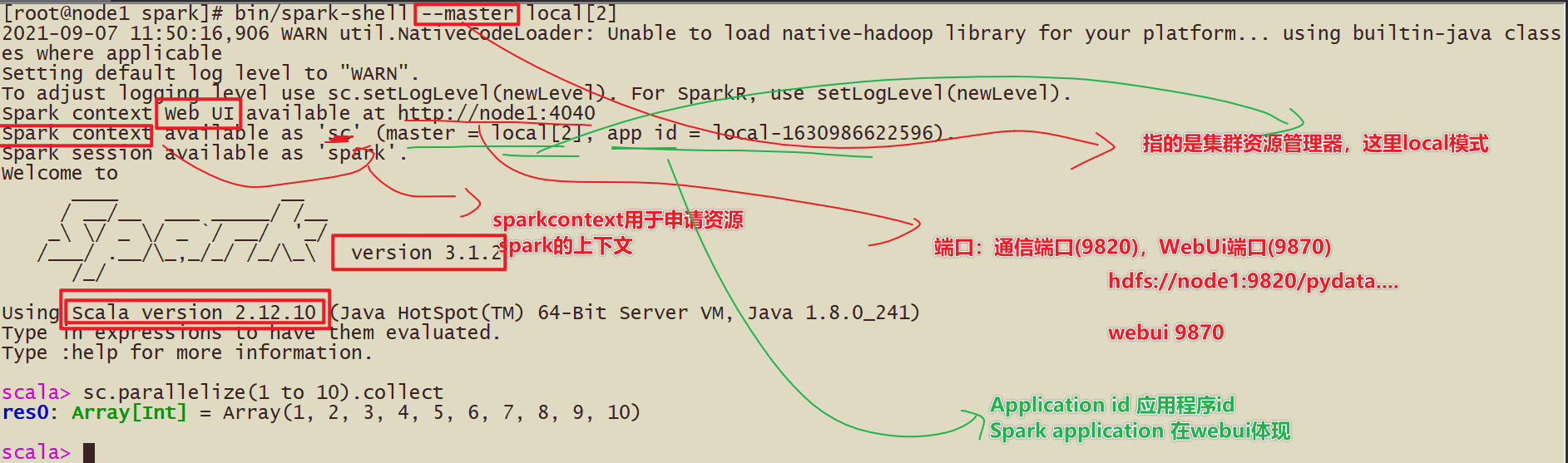
Spark环境搭建-Local
基本原理
1-Spark的Local模式使用的是单机多线程的方式模拟线程执行Spark的计算任务
2-Spark的local[1] 1个线程执行计算 local[*]本地的所有线程模拟
安装包下载
1-搞清楚版本,本机一定得搭建Hadoop集群(Hadoop3.3.0)
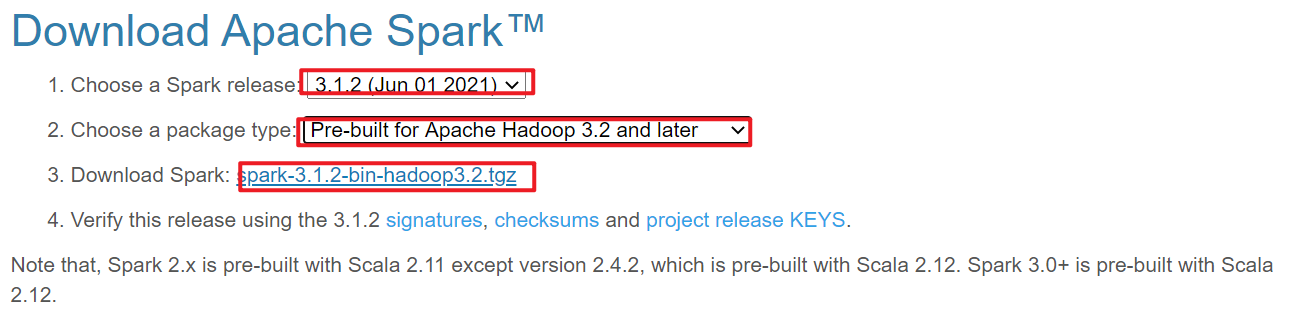
2-上传到Linux中,spark3.1.2-hadoop3.2-bin.tar.gz
3-解压Spark的压缩包
tar -zxvf xxx.tar.gz -C /export/server
ln -s spark-3.1.2-bin-hadoop3.2/ /export/server/spark
4-更改配置文件
这里对于local模式,开箱即用
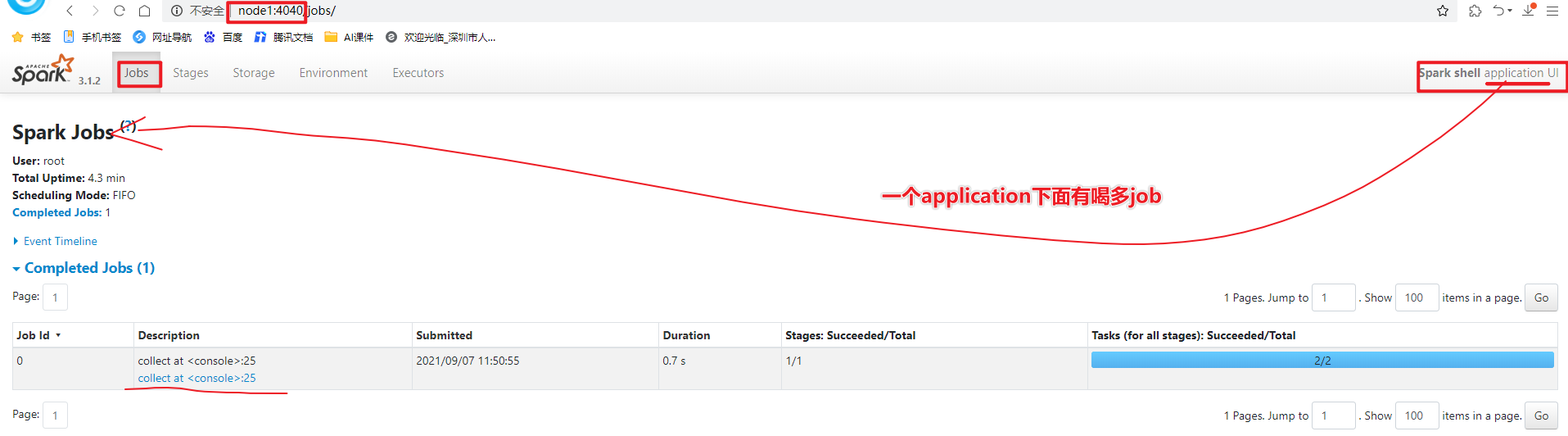
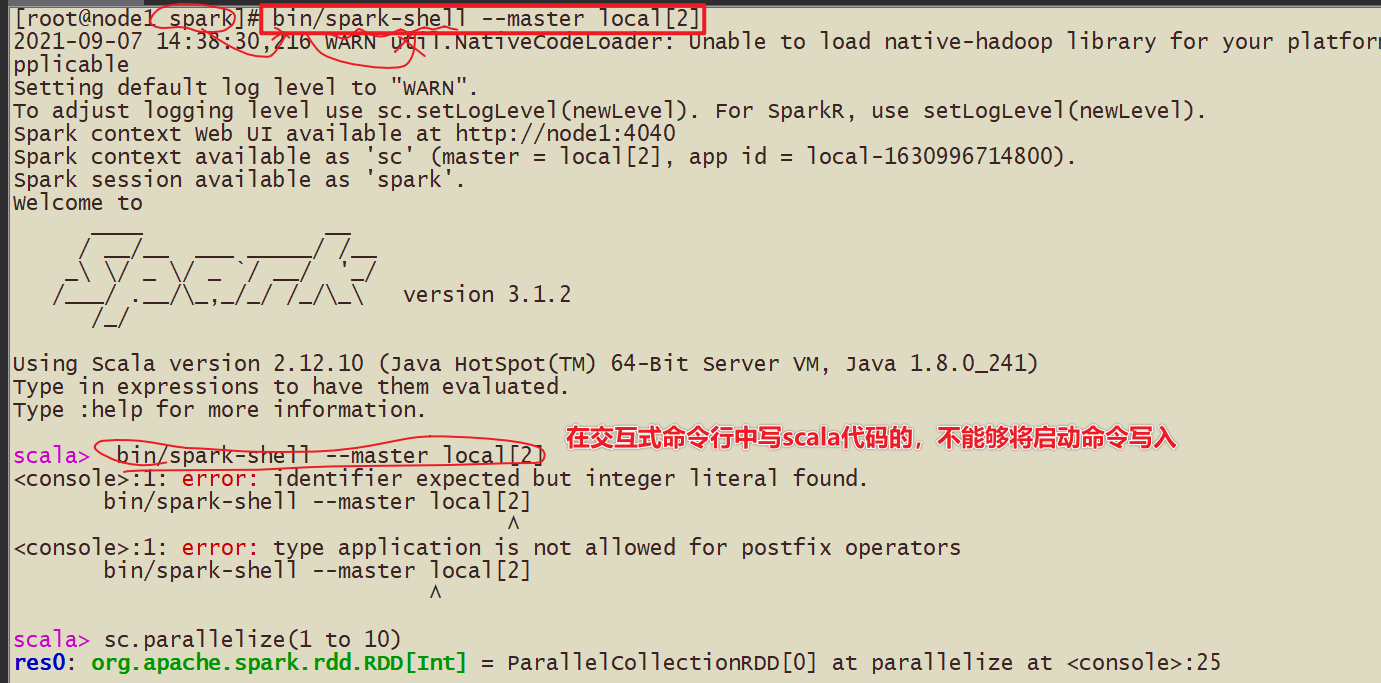
5-测试
spark-shell方式 使用scala语言
pyspark方式 使用python语言


上午回顾:
为什么要学习Spark?
- 答案:首先Spark是基于Hadoop1.x改进的大规模数据的计算引擎,Spark提供了多种模块,比如机器学习,图计算
- 数据第三代计算引擎
什么是Spark?
- Spark是处理大规模数据的计算引擎
- 1-速度快,比Hadoop块100倍(机器学习算法) 2-易用性(spark.read.json) 3-通用性 4-run anywhere
Spark有哪些组件?
- 1-SparkCore—以RDD(弹性,分布式,数据集)为数据结构
- 2-SparkSQL----以DataFrame为数据结构
- 3-SparkStreaming----以Seq[RDD],DStream离散化流构建流式应用
- 4-结构化流structuredStreaming—DataFrame
- 5-SparkMllib,机器学习,以RDD或DataFrame为例
- 6-SparkGraphX,图计算,以RDPG弹性分布式属性图
Spark有哪些部署方式?
- local模式
- standalone模式(独立部署模式)
- standaloneHA模式(高可用模式)
- Yarn模式(Hadoop中分布式资源调度框架)
注意:
后记
📢博客主页:https://manor.blog.csdn.net
📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
📢本文由 Maynor 原创,首发于 CSDN博客🙉
📢感觉这辈子,最深情绵长的注视,都给了手机⭐
📢专栏持续更新,欢迎订阅:https://blog.csdn.net/xianyu120/category_12453356.html
版权归原作者 大模型Maynor 所有, 如有侵权,请联系我们删除。