
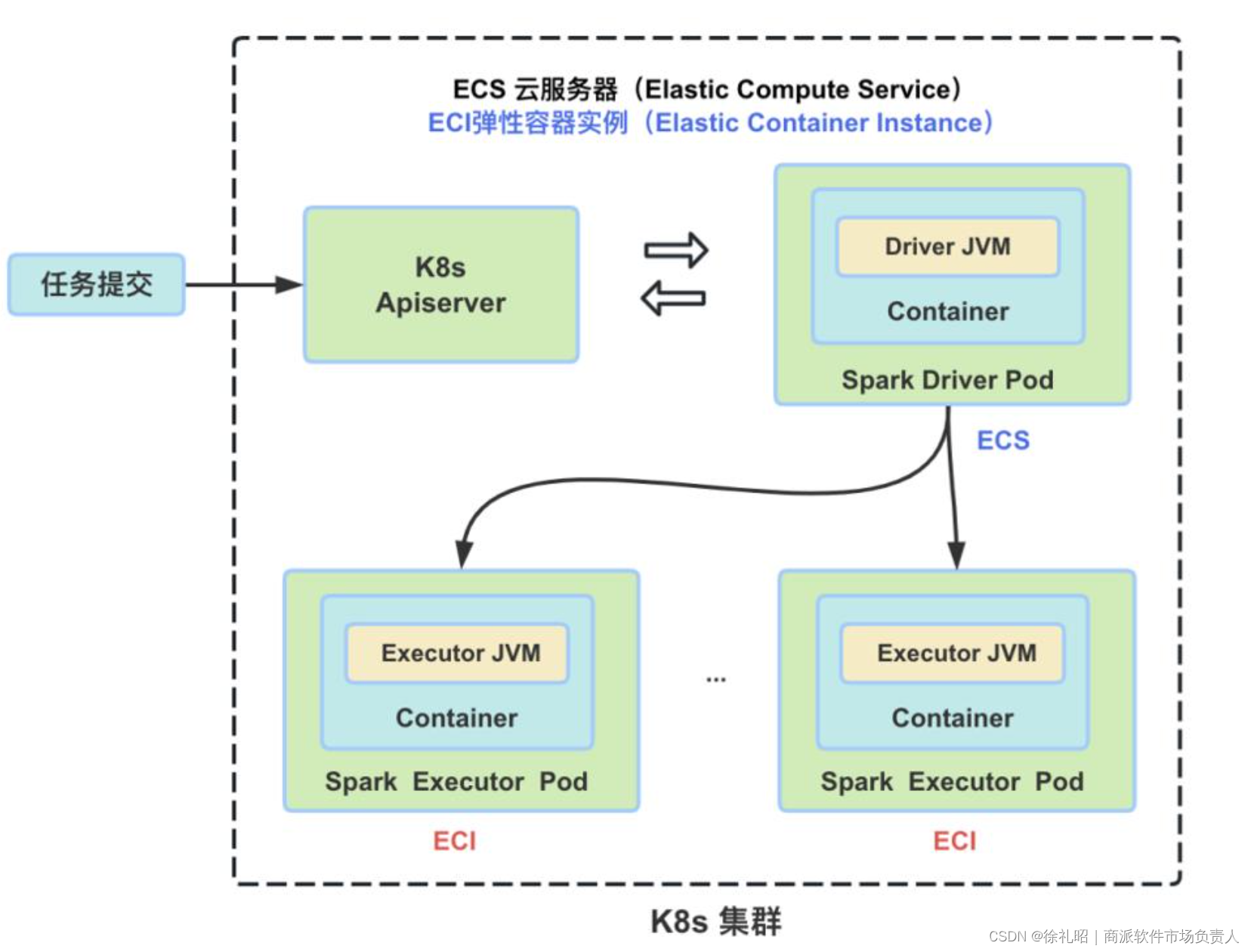
在 Kubernetes(K8s)中,Pod 是最小的可调度单元。当 Spark 任务运行在 K8s 上时,无论是 Driver 还是 Executor 都由一个单独的 Pod 来表示。每个 Pod 都被分配了一个唯一的 IP 地址,并且可以包含一个或多个容器(Container)。Driver 和 Executor 的 JVM 进程都是在这些 Container 中启动、运行和销毁的。
当一个 Spark 作业被提交到 K8s 集群后,首先会被启动的是 Driver Pod。然后,Driver 负责按需向 Apiserver 请求创建 Executor Pods。Executor 负责执行具体的 Task。一旦作业完成,Driver 将负责清理所有已创建的 Executor Pods。以下是一个简要的关系示意图:
- 用户通过
spark-submit向 K8s 集群提交 Spark 作业。 - K8s 集群中的 Master Node 接收请求并创建 Driver Pod。
- Driver Pod 内部启动 Driver JVM 进程。
- Driver JVM 进程根据作业需求向 Apiserver 请求创建 Executor Pods。
- Apiserver 分配资源并创建 Executor Pods。
- Executor Pods 内部启动 Executor JVM 进程。
- Executor JVM 进程执行具体的 Task。
- 作业完成后,Driver JVM 进程通知 Apiserver 清理所有的 Executor Pods。
- Apiserver 确认并释放 Executor Pods 所占用的资源。
- Driver Pod 完成其使命后,也会被清理。
这种设计使得 Spark 可以无缝地集成到 K8s 环境中,利用 K8s 的弹性伸缩和资源管理能力来高效地运行大数据处理作业。
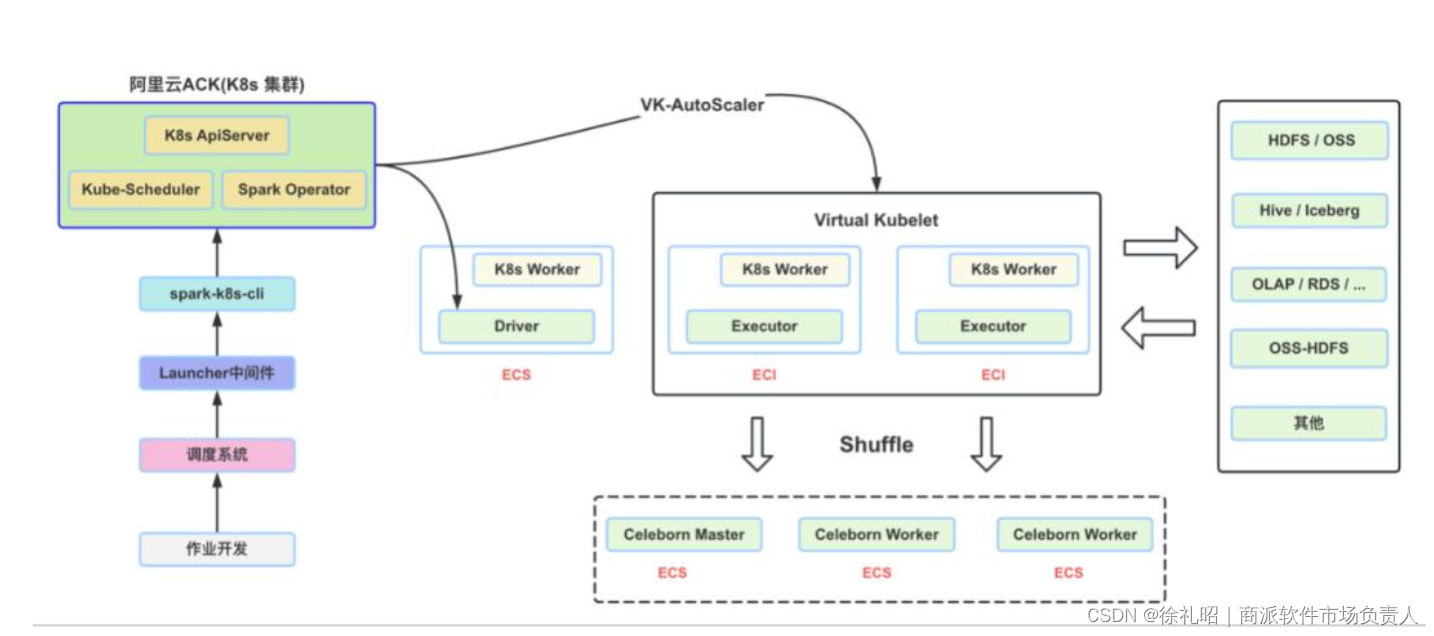
下图描绘了完整的作业执行流程。当用户完成 Spark 作业开发后,他们会将任务发布到调度系统,并配置相关的运行参数。调度系统会按照设定的时间间隔将任务提交到自研的 Launcher 中间件。这个中间件负责调用 spark-k8s-cli 工具,最终由该工具将任务提交到 K8s 集群上。
在 Executor 执行具体的 Task 过程中,它们需要与外部的各种大数据组件进行数据访问和交互,包括 Hive、Iceberg、OLAP 数据库以及 OSS-HDFS 等。而 Spark Executor 之间的数据 Shuffle 操作则是由 CeleBorn 来实现的。
整个过程可以总结如下:
- 用户开发并配置 Spark 作业。
- 将作业发布到调度系统,并设置运行参数。
- 调度系统按计划将作业提交到 Launcher 中间件。
- Launcher 中间件调用 spark-k8s-cli 将作业提交到 K8s 集群。
- 在 K8s 集群上启动 Driver 和 Executor Pods。
- Executor 执行 Task 并与外部大数据组件进行数据交互。
- CeleBorn 实现 Executor 之间的数据 Shuffle。
通过这种架构设计,Spark 作业能够充分利用 K8s 的资源管理和弹性伸缩能力,同时与其他大数据组件无缝集成,以高效地处理大规模的数据处理任务。
在将 Spark 任务提交到 K8s 集群上时,不同的公司可能会采取不同的方法。以下是目前常见的几种做法以及我们在线上所采用的任务提交和管理方式。
- 使用原生 spark-submit 原生的 spark-submit 命令可以直接提交作业,集成起来简单且符合用户习惯。然而,这种方法不便于作业状态跟踪和管理,无法自动配置 Spark UI 的 Service 和 Ingress,并且在任务结束后不能自动清理资源。因此,在生产环境中并不适合使用这种方式。
- 使用 spark-on-k8s-operator 这是目前较常用的一种提交作业方式,需要先在 K8s 集群中安装 spark-operator。客户端通过 kubectl 提交 yaml 文件来运行 Spark 作业。本质上,这是对原生方式的扩展,提供了作业管理、Service/Ingress 创建与清理、任务监控、Pod 增强等功能。尽管此方法可在生产环境中使用,但它与大数据调度平台的集成性较差,对于不熟悉 K8s 的用户来说,学习曲线较为陡峭。
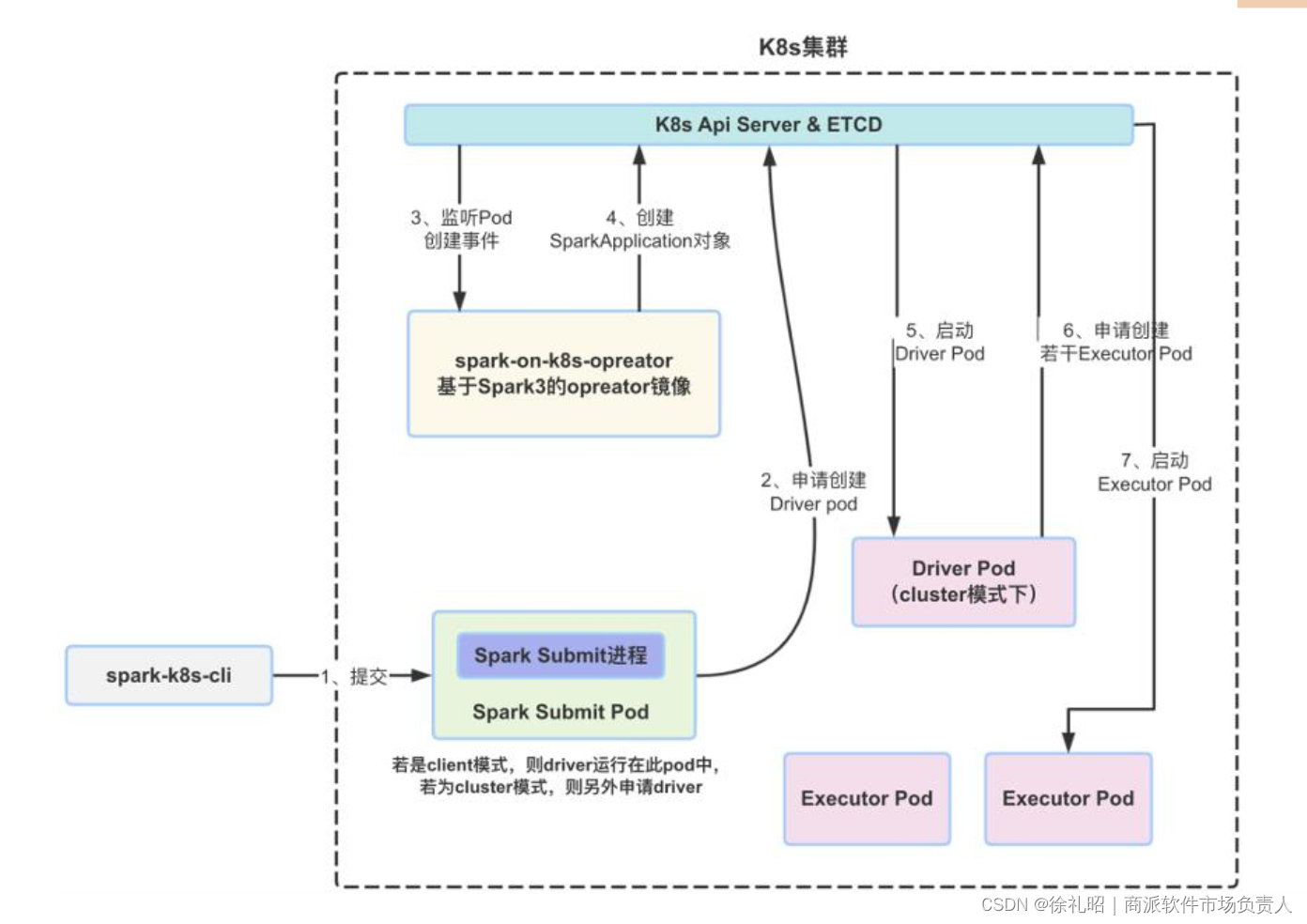
- 使用 spark-k8s-cli 在我们的生产环境中,我们使用 spark-k8s-cli 来提交任务。spark-k8s-cli 是一个可执行文件,基于阿里云 emr-spark-ack 提交工具进行了重构、功能增强和深度定制。它融合了 spark-submit 和 spark-operator 两种作业提交方式的优点,所有作业都能通过 spark-operator 管理,并支持交互式 spark-shell 和本地依赖的提交。同时,它的使用方式与原生 spark-submit 完全一致。
起初,我们所有的 Spark Submit JVM 进程都启动在 Gateway Pod 中。但在使用一段时间后,我们发现这种稳定性不足,一旦 Gateway Pod 异常,所有正在进行的 Spark 任务都会失败。此外,Spark 任务的日志输出也难以管理。因此,我们将 spark-k8s-cli 改为每个任务使用单独的 Submit Pod 方式。Submit Pod 会申请启动任务的 Driver,Submit Pod 和 Driver Pod 都运行在固定的 ECS 节点上。Submit Pod 之间完全独立,任务结束后,Submit Pod 也会自动释放。下图展示了 spark-k8s-cli 的提交和运行原理。
关于 spark-k8s-cli,除了基本的任务提交功能外,我们还实施了其他一些增强和定制化功能。
- 支持多集群任务提交:spark-k8s-cli 支持将任务提交到同地域内的多个不同的 K8s 集群上。这实现了集群之间的负载均衡和故障转移切换,增强了系统的可用性和稳定性。
- 资源不足时的自动排队等待:我们实现了类似 Yarn 资源不足时的自动排队等待功能。当 K8s 设置了资源 Quota,并且 Quota 达到上限时,任务会直接失败。我们的解决方案可以确保在资源有限的情况下,任务能够有序地进行。
- 异常处理与容错:增加了对 K8s 网络通信等异常的处理、创建或启动失败后的重试机制。这些功能对于偶发的集群抖动和网络异常提供了容错能力,保证了系统的可靠性。
- 大规模补数任务限流与管控:支持按照不同部门或业务线,对大规模补数任务进行限流和管控。这样可以有效地管理和优化系统资源使用,防止某些任务过度消耗资源,影响整体性能。
- 内置告警功能:内嵌了任务提交失败、容器创建或启动失败以及运行超时等告警功能。这有助于及时发现并解决问题,提高运维效率。
通过这些增强和定制化功能,spark-k8s-cli 不仅提高了 Spark 作业在 K8s 上的运行效率,也提升了整个系统的稳定性和可管理性。
版权归原作者 徐礼昭|商派软件市场负责人 所有, 如有侵权,请联系我们删除。