
项目场景:
项目场景:目前项目使用了4台机器搭建了hbase集群及hadoop集群,目前需要进行降配,将hbase集群降配置单节点进行使用(虽然基本没有项目这么使用hbase的情况,还有诸多不合理的地方,此篇文章不予讨论)此篇只用于记录hbase的数据如何进行数据跨集群迁移案例。
数据迁移方案
1.为了降低迁移的复杂度,我所准备的hbase单节点服务器上所安装的hbase和hadoop与原集群中的版本选择为一致的
2.hbase的数据迁移方案主要有四类,Hadoop层有一类,HBase层有三类。我选用的是通过hadoop这层进行数据迁移通过hadoop的分布式拷贝将数据迁移至目标机器
hbase和hadoop相关命令
介绍方案之前先记录一些hbase的常用命令
// 进入hbase
/[hbasePath]/bin/hbase shell
// 或者在hbase的安装目录执行
bin/hbase shell
// 查看hbase中的所有表
hbase(main):002:0> list
// HBASE中查询表的列族信息,表结构
hbase(main):002:0> describe '[tableName]'
// 创建命名空间及创建表
hbase(main):002:0> create_namespace 'test'
hbase(main):002:0> create '[tableName]', '[columnName]'
// 创建hbase_goods表 并有一个info列 并通过key1,key2,key3对表进行分区
hbase(main):002:0> create 'hub:hbase_goods', 'info', SPLITS => ['key1', 'key2', 'key3']
// 创建hbase_goods表有info和supper两个列,切两个列最大版本都为1,压缩方式都为GZ
hbase(main):002:0> create 'hub:hbase_goods', {NAME => 'info', VERSIONS => 1, COMPRESSION => 'GZ'}, {NAME => 'supper', VERSIONS => 1, COMPRESSION => 'GZ'}, SPLITS => ['key1', 'key2', 'key3']
// 禁用表
hbase(main):002:0> disable 'hub:hbase_goods'
// 启用表
hbase(main):005:0> enable 'hub:hbase_goods'
// 删除表
hbase(main):002:0> drop 'hub:hbase_goods'
// 查看表中数据
// 从row3到最后
hbase(main):002:0> scan '[tableName]',{STARTROW=>'row3'}
// 从row3到row4
hbase(main):002:0> scan '[tableName]',{STARTROW=>'row3',ENDROW=>'row4'}
// 从开始一直到row2
hbase(main):002:0> scan '[tableName]',{ENDROW=>'row2'}
// 查询meta表元数据 信息
hbase(main):002:0> scan 'hbase:meta',{FILTER=>"PrefixFilter('hub:hbase_goods_img,') "}
// 修改表的定义
// 修改表中列族的压缩方式
hbase(main):002:0> alter 'hub:hbase_goods', {NAME => 'info', COMPRESSION => 'GZ'}, {NAME => 'supper', COMPRESSION => 'GZ'}
// 设置hbase协处理器
// 表级别设置协处理器
hbase(main):001:0> alter 'table_name', METHOD => 'table_att', 'coprocessor'=>'hdfs://path/to/coprocessor.jar|com.example.MyCoprocessor|1001|arg1=foo,arg2=bar'
// 列族级别设置协处理器
hbase(main):002:0> alter 'table_name', {NAME=>'column_family', METHOD => 'table_att', 'coprocessor'=>'hdfs://path/to/coprocessor.jar|com.example.MyCoprocessor|1001|arg1=foo,arg2=bar'}
/** table_name是HBase表的名称,column_family是列族的名称,hdfs://path/to/coprocessor.jar是
协处理器代码的路径,com.example.MyCoprocessor是协处理器类的完全限定名,1001是协处理器优先级,
arg1=foo,arg2=bar是传递给协处理器的参数。*/
// hbase 自带mapreduce 导出; 后面的地址为文件在hadoop中hdfs中的地址
/[hbasePath]bin/hbase org.apache.hadoop.hbase.mapreduce.Driver export test:hbase_demo /hbase/data/bak
// hbase 自带mapreduce 导入数据到hbase表中; 后面的地址为文件在hadoop中hdfs中的地址
/[hbasePath]bin/hbase org.apache.hadoop.hbase.mapreduce.Driver import test:hbase_demo /hbase/data/test
hbase中可以自行创建命名空间

hadoop常用命令
-- hadoop distcp命令用于将源HDFS集群中的table_name表的数据复制到目标HDFS集群中的相同位置。
-- hdfs://src-hadoop-address:9000 是源HDFS集群的地址,包括主机名和端口号。
-- hdfs://dst-hadoop-address:9000 是目标HDFS集群的地址,包括主机名和端口号。
-- table_name 是要复制的表的路径。
hadoop distcp hdfs://src-hadoop-address:9000/table_name hdfs://dst-hadoop-address:9000/table_name
-- 查看hdfs下文件夹目录
hdfs dfs -ls /hbase/data/test
-- 删除hdfs中的文件或文件夹数据
hdfs dfs -rm /hbase/data/tmp/xxxx
hdfs dfs -rm -r /hbase/data/tmp
-- 查看hdfs中的文件
hdfs dfs -cat /hbase/data/tmp/xxxx
-- 将hdfs中的文件复制到linux本机
hadoop fs -get <HDFS文件路径> <本地文件路径>
hadoop fs -get /hbase/data/tmp/hbase_demo /usr/local/share/hadoop-2.8.5
-- 将本机文件上传到HDFS
hadoop fs -put <本地文件路径> <目标HDFS路径>
hadoop fs -put /usr/local/share/file.txt /hbase/data/tmp/hbase_demo
-- 查看磁盘使用情况
hadoop dfsadmin -report
-- 查看当前 HDFS 节点是备用(Standby)还是活动(Active)
hdfs haadmin -getServiceState <nameserviceId>
-- -Dhbase.mapreduce.hfileoutputformat.skip.timestamp.maxvalue=true 用于在导入数据到 HBase 表时,只导入最新版本的数据,而跳过旧版本的数据。(似乎没用--大家可以自行尝试)
-- 参数-Dhbase.mapreduce.bulkload.max.hfiles.perRegion.perFamily, 这个表示在bulkload过程中,每个region列族的HFile数的上限,这里我们是限定了1024,也可以指定更少,根据实际需求来定。
-- bulk load 加载hdfs中 Hfiles的文件 这种方式适用于大量数据情况下
hbase org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles -Dhbase.mapreduce.bulkload.max.hfiles.perRegion.perFamily=1024 -Dhbase.mapreduce.hfileoutputformat.skip.timestamp.maxvalue=true hdfs://dst-hadoop-address:9000/hbase/data/tmp/8bb6022f45be3f5cb41e7cb972befbf6/ table_name
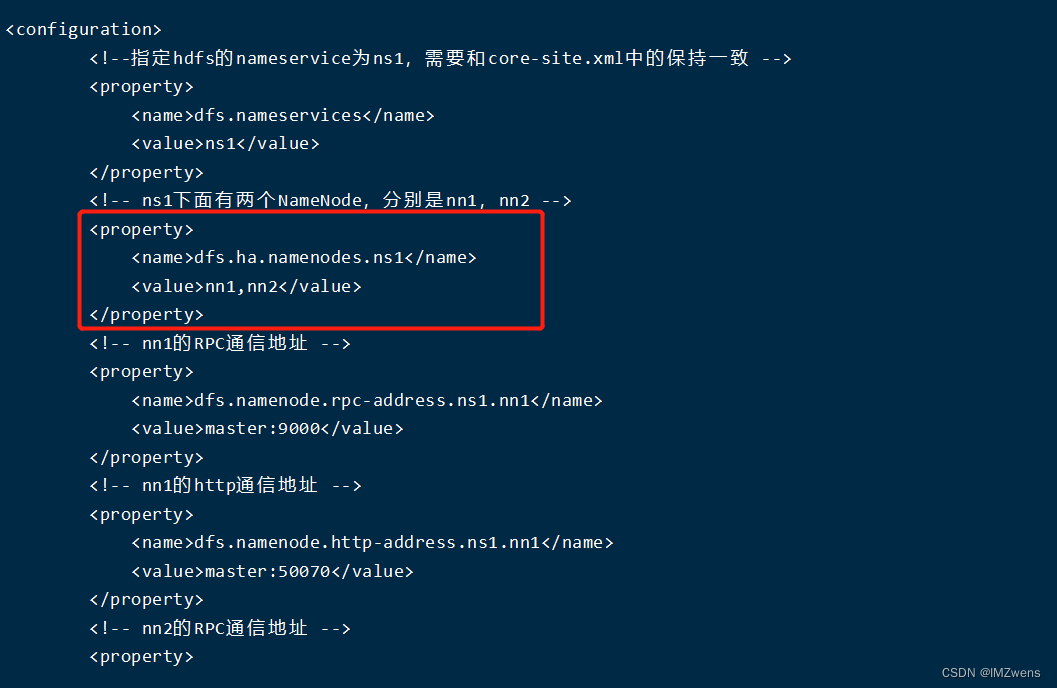
上面提到的 hdfs的 <nameserviceId> 可以在 /[hadoopHomePath]/etc/hadoop/hdfs-site.xml文件中查看到
方案介绍
Hadoop层的数据迁移主要用到DistCp(Distributed Copy), 官方描述是:DistCp(分布式拷贝)是用于大规模集群内部和集群之间拷贝的工具。 它使用Map/Reduce实现文件分发,错误处理和恢复,以及报告生成。 它把文件和目录的列表作为map任务的输入,每个任务会完成源列表中部分文件的拷贝。
我们知道MR程序适合用来处理大批量数据, 其拷贝本质过程是启动一个MR作业,不过DisctCp只有map,没有reducer。在拷贝时,由于要保证文件块的有序性,转换的最小粒度是一个文件,而不像其它MR作业一样可以把文件拆分成多个块启动多个map并行处理。如果同时要拷贝多个文件,DisctCp会将文件分配给多个map,每个文件单独一个map任务。我们可以在执行同步时指定
-m
参数来设定要跑的map数量,默认设置是20。如果是集群间的数据同步,还需要考虑带宽问题,所以在跑任务时还需要设定
bandwitdh
参数,以防止一次同步过多的文件造成带宽过高影响其它业务。同时,由于我们HBase集群一般是不会开MR调度的,所以这里还需要用到单独的MR集群来作主备数据同步,即在跑任务时还需要指定mapreduce相关参数。
简单的distcp参数形式如下:
hadoop distcp hdfs://src-hadoop-address:9000/table_name hdfs://dst-hadoop-address:9000/hbase/data/table_name
需要注意的是将源集群表在hdfs中的文件复制到目标hdfs中时需要先放到临时目录 例如 hdfs://dst-hadoop-address:9000/hbase/data/tmp 因为数据过来后还需要进行blukload才能加载到表中,bulkload会自动在hdfs中创建hbase表所对应的文件夹
DistCp分布式拷贝方案实施
迁移方法如下:
第一步, 需要先停止所迁移表的写入
第二步, flush表,在进入hbase客户端后执行
hbase(main):002:0> flush 'test'
第三步,执行如下带MR参数的命令 ** 将原表储存在hdfs中文件拷贝到新节点的hdfs中临时目录中**
-- -bandwidth 20 设置带宽为20m/s
-- -m 20 设置map任务数为20
-- 使用过程中将hdfs地址更换为自己的hdfs原地址和目标地址
hadoop distcp -p -bandwidth 20 -m 20 hdfs://worker1:9000/hbase/data/hub/hbase_goods hdfs://10.10.xx.xx:xxxx/hbase/data/tmp/
-- 如果你的hbase集群定义了协处理器 也需要在这一步一同拷贝到目标新节点。
-- 协处理器是一个jar包,可运行的代码,不是需要bulkload的表数据,所以可以放在原集群相同目录下
hadoop distcp -p -bandwidth 20 -m 20 hdfs://worker1:9000/usr/local/share/lib/20220903 hdfs://10.10.xx.xx:xxxx/usr/local/share/lib/20220903
第四步, 在目标新节点hbase中创建与原集群表结构相同的表,并定义其协处理器
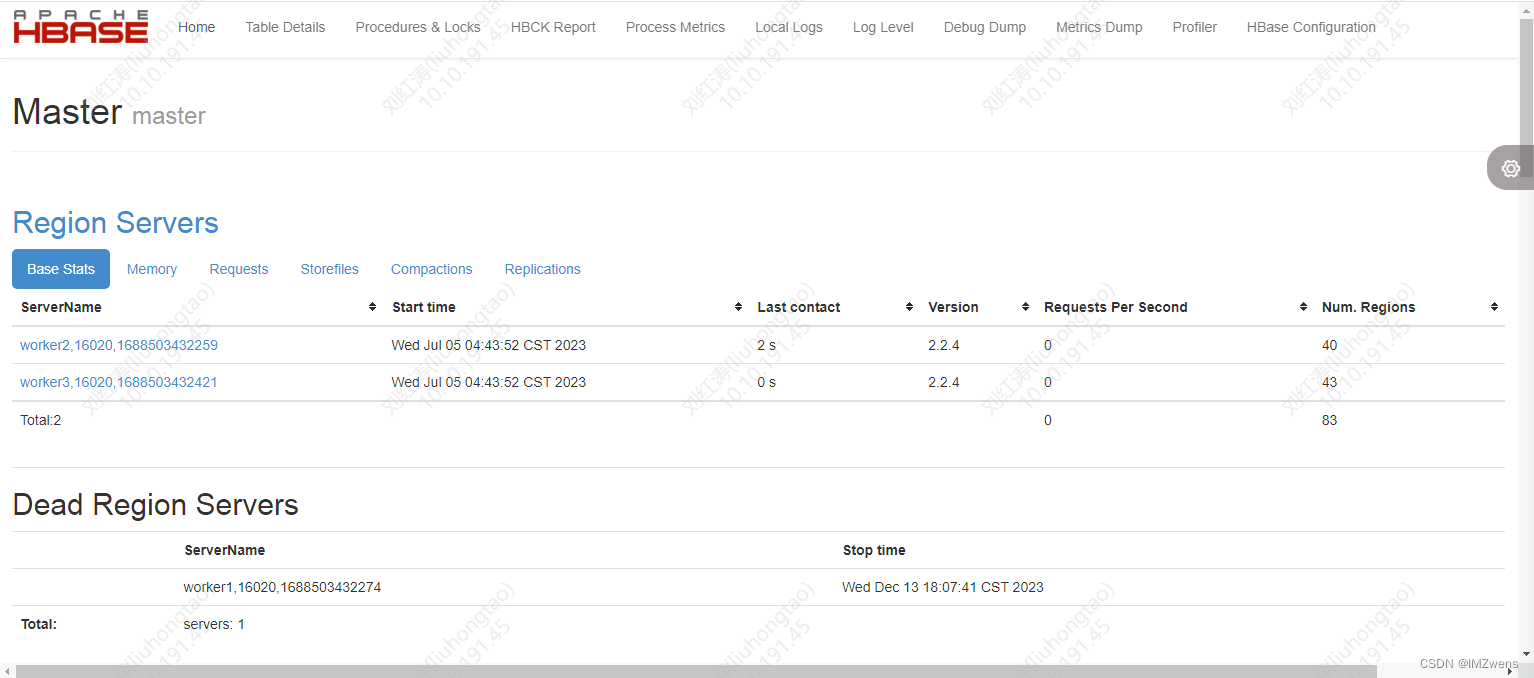
表的配置我们也可以在hbase master节点的管理页面上查看到http://xx.xx.xx.xx:16010/master-status 16010端口是hbase master web UI的接口,可以访问查看hbase相关的配置

-- 根据自己表的情况将表的结构也需要迁移,同样还有表的分区定义需要一并迁移
-- SPLITS的值为原集群表每个分区的end key
create 'hub:hbase_goods', {NAME => 'info', VERSIONS => 1, COMPRESSION => 'GZ'}, {NAME => 'supper', VERSIONS => 1, COMPRESSION => 'GZ'}, SPLITS => ['017988830001000101', '035910140001000101', '053902900001000101', '071915240001000101', '089786800000000101', '106632260001000101', '12191295', '137182210001000101', '152492650001000101', '167816050001000101', '183158250001000101', '198506540001000101', '216367450001000101', '234506330001000101', '252583730001000101', '270651040001000101', '287454250001000101', '303705050001000101', '318042450001000101', '332374640001000101', '346747950001000101', '361100050001000101', '375432230001000101', '389765840001000101', '405877840001000101', '423536440001000101', '441153940001000101', '458808859660010101', '476355830001000101', '493919640001000101', '509856840001000101', '524966320001000101', '539065220001000101', '553109230001000101', '567149350001000101', '581179610001000101', '595354550001000101', '610951940001000101', '627392340001000101', '643818250001000101','660288810001000101', '676749440001000101', '693162010001000101', '708249840001000101', '722387230001000101', '736495650001000101','750634410001000101', '764770900001000101', '778687160001000101', '792548830001000101', '807490840001000101', '823587250001000101', '839753110000000101', '855937930001000101', '872066650001000101', '888146840001000101', '903586550001000101', '917301550001000101', '931063260001000101', '94480694', '958576140001000101', '9723531', '986199950001000101']
-- 设置表的协处理器
hbase(main):001:0> alter 'hub:hbase_goods', METHOD => 'table_att', 'coprocessor$1' => 'hdfs:///usr/local/share/lib/20220903/observer-goods.jar|com.spider.yn.observer.HBaseDataSyncEsObserver|1001|indexName=hbase_goods,indexType=goods'
第五步, 在目标新节点上bulkload数据
对于我们来说,因我们先把文件同步到了临时目录,并不在原表目录,所以我们采用的另一种形式的load,即以region的维度来Load数据到线上表,怎么做呢,这里用到的是org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles这个类,即以bulkload的形式来load数据。上面同步时我们将文件同步到了目的集群的/tmp/region-hdfs-path目录,那么我们在Load时,可以用如下命令来Load region文件:
这里需要一个分区文件执行一次
-- 参数-Dhbase.mapreduce.bulkload.max.hfiles.perRegion.perFamily, 这个表示在bulkload过程中,每个region列族的HFile数的上限,这里我们是限定了1024,也可以指定更少,根据实际需求来定。
-- -Dhbase.mapreduce.hfileoutputformat.skip.timestamp.maxvalue=true 用于在导入数据到 HBase 表时,只导入最新版本的数据,而跳过旧版本的数据。(似乎没用--大家可以自行尝试)
hbase org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles -Dhbase.mapreduce.bulkload.max.hfiles.perRegion.perFamily=1024 -Dhbase.mapreduce.hfileoutputformat.skip.timestamp.maxvalue=true hdfs://xx.xx.xx.xx:xxxx/hbase/data/tmp/06d4ad1c27100961a9df292bab55388b/ hub:hbase_goods
第六步, 检查表数据是否OK,看bulkload过程是否有报错;可以通过hbase的count命令对原集群表和目标新节点load后的表进行计数对比是否一致
迁移过程中遇到的一些问题
原集群的是3个节点的磁盘均为1T大小,目标新集群的磁盘只有300GB;所以我们需要先把原集群数据合并之后才能进行迁移。
1.我在原集群先拷贝协处理器到目标新节点过程中出现了如下的情况,hdfs的map任务一直处于卡住状态,通过页面前两行看到hadoop集群没有资源, 有3个节点处于不健康的状态
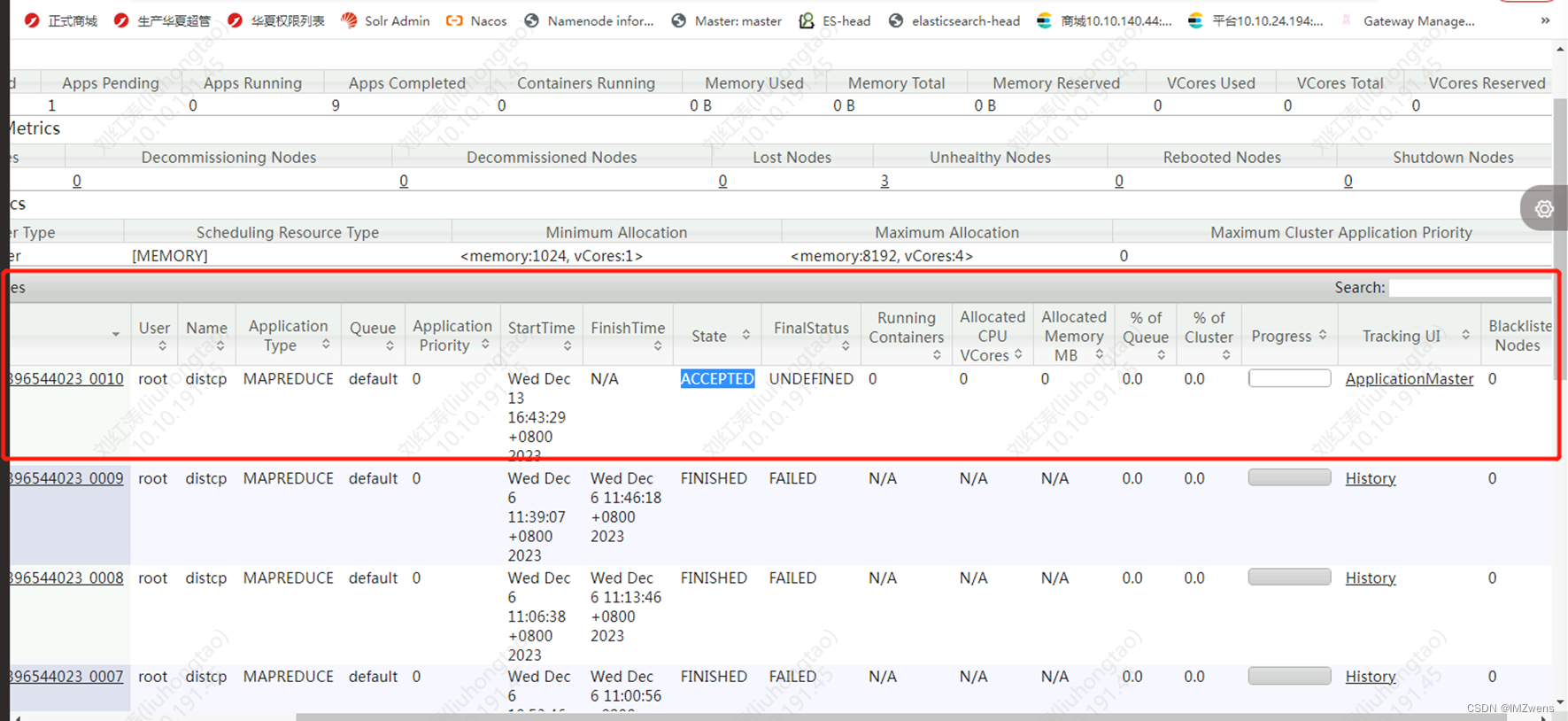
http://xx.xx.xx.xx:8088/ 是hadoop的集群节点活动面板 webUI (上图就是此地址页面)
http://xx.xx.xx.xx:50070/ Web UI地址,用于访问Hadoop集群中的NameNode服务。
http://xx.xx.xx.xx:8088/通过查看nodemanager日志分析得出,是由于磁盘资源的使用超过了90%导致,这个阈值可以在yarn的配置文件中进行修改

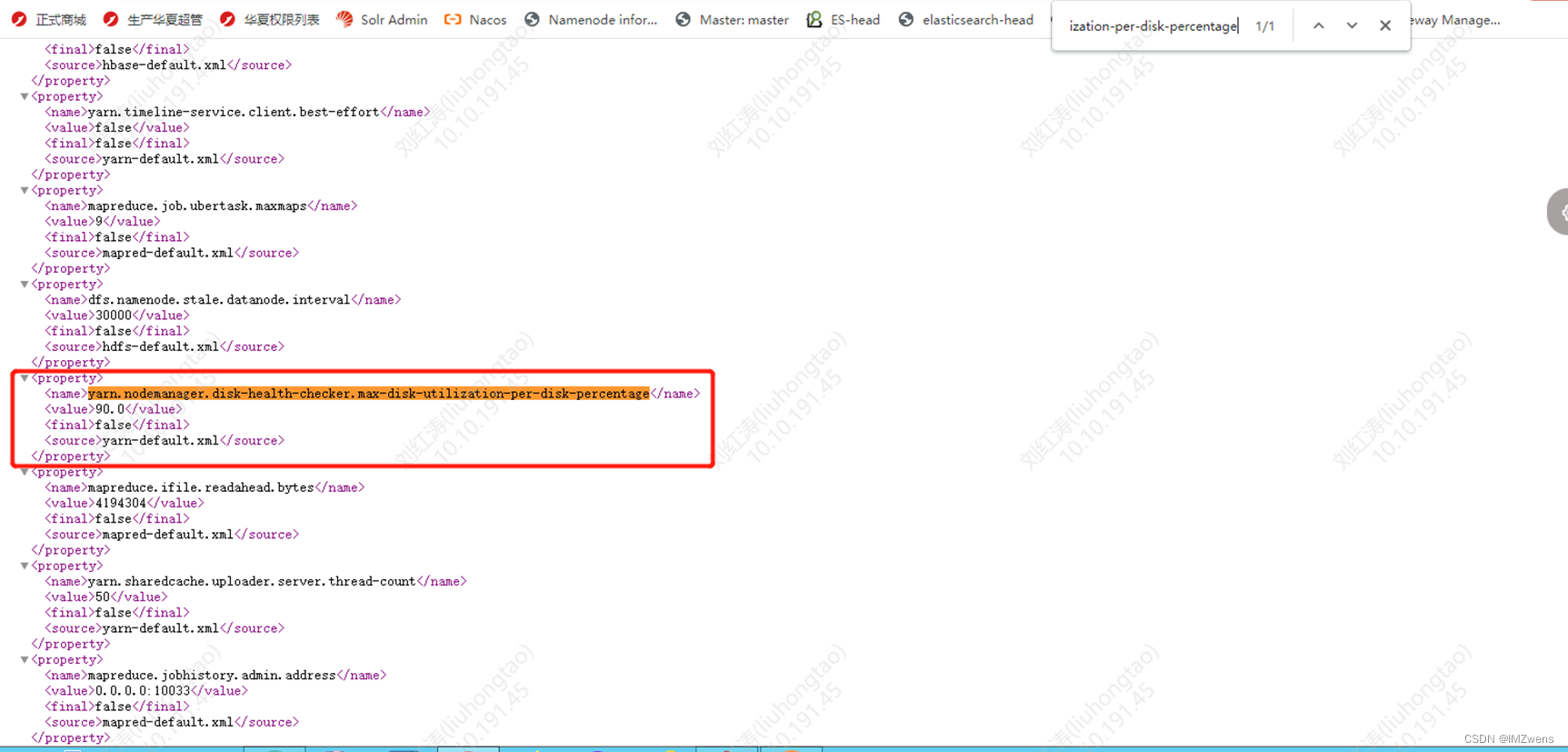
处理方式:我的处理方式比较粗暴 直接删除了一些数据让阈值降低到90%以下我再原集群进行其他操作
Hadoop集群nodes unhealthy解决方法-CSDN博客 也可参考此文章
2. 因为准备的目标新节点磁盘远小于原集群,所以需要先将原集群数据进行合并
-- 关闭region
balance_switch false
-- 合并某个表
major_compact 't1'
-- 合并表中某个列族
-- major_compact 'r1', 'c1'
-- major_compact 't1', 'c1'
-- 开启region
balance_switch true
此过程非常消耗磁盘读写性能,内存及占用带宽,所以需要慎操作; 由于我在操作之前并没有检查原集群是否给每个表设置COMPRESSION属性的值(也就是压缩方式)直接进行了大合并,整个高占用过程持续了3个小时,且磁盘占用并未减少。
处理方式:给原集群每个表设置**COMPRESSION => GZ **的压缩方式再次进行大合并,合并后数据只有100GB,目标新节点磁盘300GB可以满足
major合并(大合并)
HBase的大合并,不是轻量化的操作,有很大的I/O消耗
所谓的大合并,就是将一个Region下的所有StoreFile合并成一个StoreFile文件,在大合并的过程中,之前删除的行和过期的版本都会被删除,拆分的母Region的数据也会迁移到拆分后的子Region上。大合并一般一周做一次,控制参数为hbase.hregion.majorcompaction。大合并的影响一般比较大,尽量避免统一时间多个Region进行合并,因此Hbase通过一些参数来进行控制,用于防止多个Region同时进行大合并。该参数为:hbase.hregion.majorcompaction.jitter 具体算法为:
hbase.hregion.majorcompaction参数的值乘于一个随机分数,这个随机分数不能超过hbase.hregion.majorcompaction.jitter的值。hbase.hregion.majorcompaction.jitter的值默认为0.5。 通过hbase.hregion.majorcompaction参数的值加上或减去hbase.hregion.majorcompaction参数的值乘于一个随机分数的值就确定下一次大合并的时间区间。
用户如果想禁用major compaction,只需要将参数hbase.hregion.majorcompaction设为0。建议禁用。
大合并自动执行:默认7天来一次
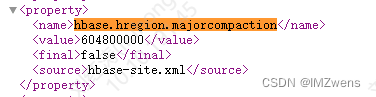
hbase.hregion.majorcompaction
默认7天
3. HDFS问题,Operation category READ is not supported in state standby
在使用distcp进行拷贝时出现日错误,这是由于我在原集群的hdfs的备用节点进行的操作 ,备用节点是不支持读取操作的
于是使用如下命令进行查看当前节点状态确实为 standby节点
hdfs haadmin -getServiceState <nameserviceId>
查看hdfs-site.xml文件中对应的namenode(也就是上文nameserviceId)有哪些节点,所登录的机器确实在standby状态的节点下,于是更换在active节点下的机器进行操作
4. Call to localhost/127.0.0.1:16020 failed on connection exception: org.apache.hbase.thirdparty.io.netty.channel.AbstractChannel$AnnotatedConnectException: Connection refused: localhost/127.0.0.1:1602
数据拷贝且bulkload后更换代码中Hbase相关的配置进行测试 发现报错此错误;当在访问regionservice的时候,默认是localhost/127.0.0.1:16020
处理方式:修改linux服务器的名称映射,及需要使用hbase的服务所部署的linux机器也需要进行名称映射处理
-- 修改服务器名称及 映射
--1.配置hadoop服务器的hostname
vi /etc/sysconfig/network
****************** 文件内容******************
NETWORKING=yes
HOSTNAME=hadoop1 // 设置服务器名称
****************** 文件内容******************
-- 执行以下命令以使主机名更改立即生效
hostnamectl set-hostname new_hostname
--2.配置hostname文件
vi /etc/hostname
****************** 文件内容******************
hadoop1 // 设置服务器名称
****************** 文件内容******************
--3.配置hosts文件
vi /etc/hosts
****************** 文件内容******************
xx.xx.xx.xx hadoop1
****************** 文件内容******************
-- 执行以下命令以刷新 DNS 缓存,使新的主机名配置生效(否则需要重启)
systemctl restart network
--4. 重启habse
[hbasehome]/bin/stop-hbase.sh
[hbasehome]/bin/start-hbase.sh
--5. 需用到hbase 的服务所在的机器 也需要设置hosts文件
vi /etc/hosts
****************** 文件内容******************
xx.xx.xx.xx hadoop1 // 需要访问的hbase的地址及名称
****************** 文件内容******************
版权归原作者 IMZwens 所有, 如有侵权,请联系我们删除。