
1.HDFS基础知识
1.HDFS基础知识
2.HDFS操作
3.HDFS上传|下载流程
1.1传统文件、存储
文件系统:存储数据和管理数据的一种方式
传统存储方式:程序是程序,数据是数据,处理时将数据转移到程序中
1.2分布式文件存储的概念和现实(重点)
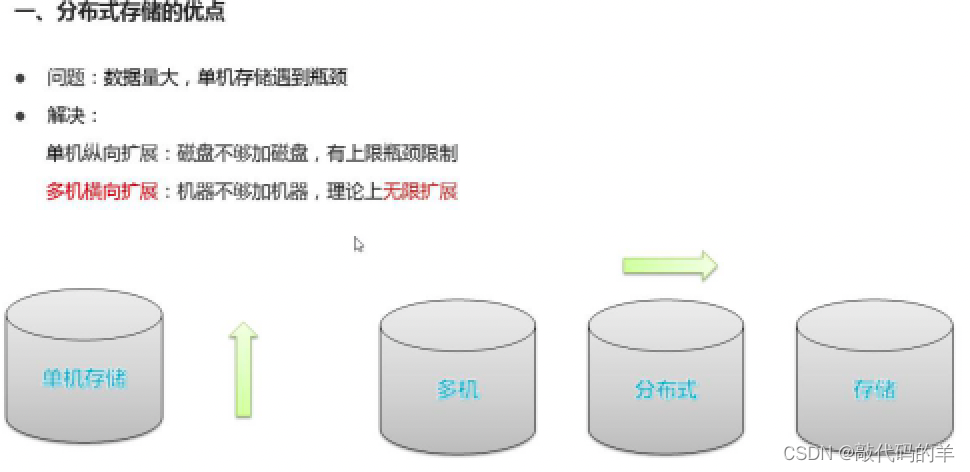
思考:如何模拟实现分布式文件存储系统? 具备哪些特性(功能、优点、作用)
(参考视频-「为什么中国网盘这么难」)
- 分布式> 分布式存储能-无限扩展-支持海量数据存储
- 分块存储
针对块并行操作,提高效率

- 副本机制
冗余存储,保障数据安全
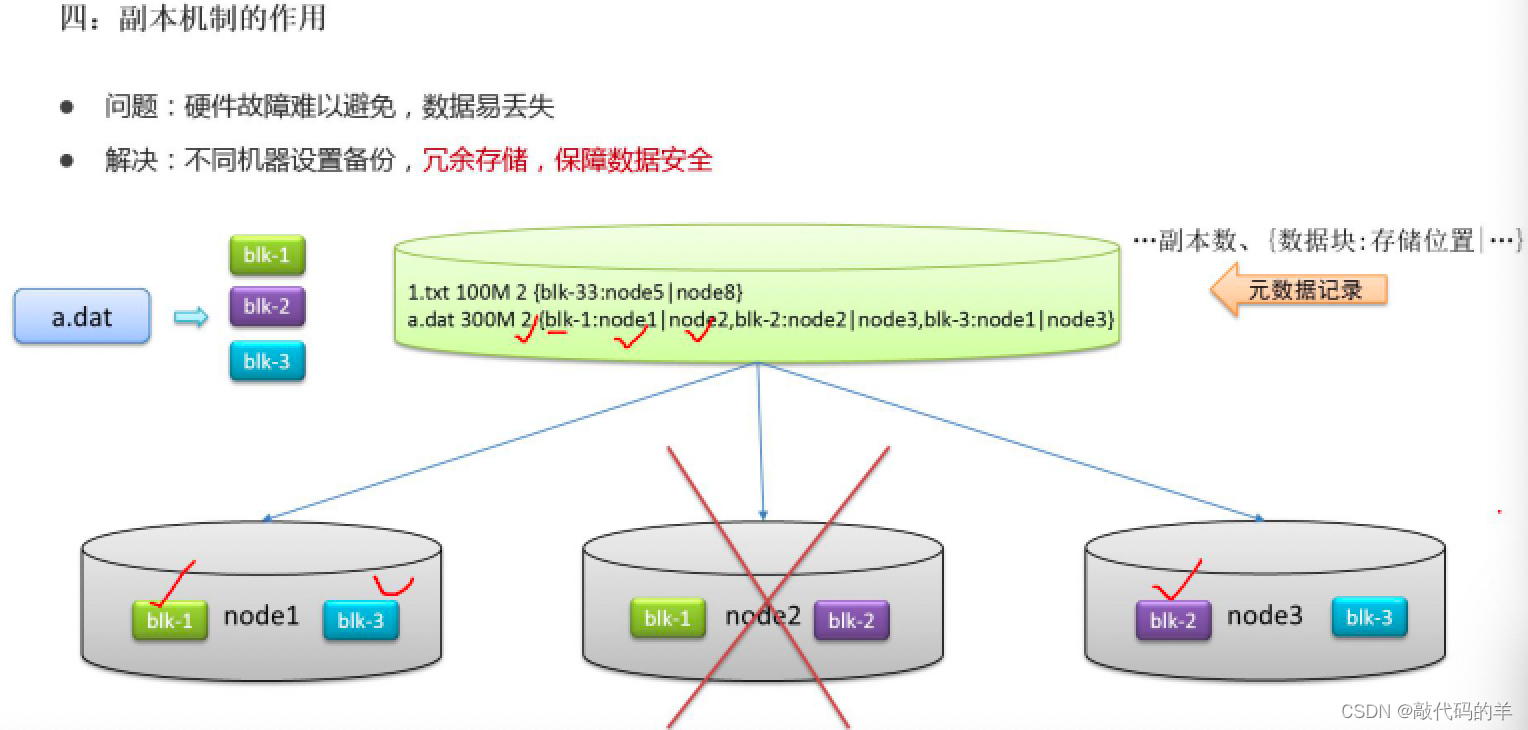
- 元数据管理
元数据作用:快速定位文件位置便于查找
1.3HDFS
HDFS(Hadoop Distributed File System)
核心架构目标:主要是解决大数据如何存储问题-通过分布式存储
分布式意味着HDFS是横跨在多台计算机上的存储系统
1.4HDFS的设计目标
设计目标:故障检测和自动、快速修复;比起速度,更注重数据访问的高吞吐量
一般的应用是流式读取数据,HDFS被设计成适合批量处理,而不是用户交互式
-用起来像单机(标准主从集群),但底层是分布式-
#思考🤔:小文件存储(上传)怎么办?(小文件存储、读取速度慢)
上传时合并
#追加内容到文件尾部 appendToFile#(>>追加,>覆盖)[root@node3 ~]# echo 1 >> 1.txt[root@node3 ~]# echo 2 >> 2.txt [root@node3 ~]# echo 3 >> 3.txt [root@node3 ~]# hadoop fs -put 1.txt /[root@node3 ~]# hadoop fs -cat /1.txt1[root@node3 ~]# hadoop fs -appendToFile 2.txt 3.txt /1.txt[root@node3 ~]# hadoop fs -cat /1.txt123[root@node3 ~]# #追加的用途:把本地的小文件-上传-中合并成为大文件 解决小文件场景的
1.5HDFS的应用场景
适合:大文件,数据流式访问,一次写入多次读取,低成本部署(廉价PC,高容错)
不适合:小文件,数据交互式访问,频繁任意修改,低延迟处理
1.6HDFS副本
分块默认128MB(134217728B),默认副本3(1+2),副本冗长(服务器只使用了3分之一储存数据,剩余3分之2用于备份,利用率低)
本文转载自: https://blog.csdn.net/iyak78/article/details/122135680
版权归原作者 敲代码的羊 所有, 如有侵权,请联系我们删除。
版权归原作者 敲代码的羊 所有, 如有侵权,请联系我们删除。