
HDFS定义:Hadoop体系下的一个分布式文件系统。
提供容错机制,且数据不允许修改以保证数据一致性【作为底层组件,确保数据一致性和完全准确性即可,对数据多样性没有要求】。
基本概念:
1、NameNode分类:AN (Active NameNode)和SN (Standby NameNode)。注:在HDFS中,默认每个文件3个副本来保存。且处理客户端读写请求,为DataNode分配任务。
2、Standby NameNode(SN)在Hadoop 2.X只有一个,只能是一主一备;在Hadoop 3.0及其之后允许配置多个热备。
3、Edits和fsimage的作用:做元数据信息持久化,NameNode恢复元数据信息的思路是恢复fsimage信息,当fsimage信息恢复到内存中,通过其他关键字发现该关键字信息中记录的宕机信息时间比宕机时间点早(即fsimage是旧版本元数据信息),再看Edits,通过Edits编辑日志的功能,将fsimage文件再更新一段时间,直到数据更新,实现数据恢复——NameNode在未更新完元数据之前对外是不提供服务的,Standby NameNode在检查点定期将内存中的元数据保存到fsimage文件中,这样就保证了元数据更新的时间,以及Standby NameNode冷启动的时间。
4、Block默认128MB,存储的是业务数据,元数据存储的是数据管理信息。Block存储于DataNode,元数据存储于NameNode,以免互相干扰。
HDFS集群大类中有两层角色:
第一类是管理节点(即NameNode-作用1:管理数据存储信息;作用2:对外提供服务,通过客户端Client访问HDFS文件系统的话,首先是由NameNode进行访问对接;作用3:除了管理数据存储信息外,还要管理DateNode节点的情况-上下行信息、存储大小等)、【NameNode Active和NameNode Standby是高可用架构的一种实现方式】
NameNode Active在集群中的某一时刻只有一个,做管理集群以及对外访问服务;NameNode Standby作为NameNode Active的备份节点,时刻准备替换成Active状态并管理整个集群。而HDFS对外所展现的一直是高可用状态。
****第二类是从节点(又叫存储节点)(DateNode)****,实现数据的存储和读写,多个DateNode实现分布式存储。
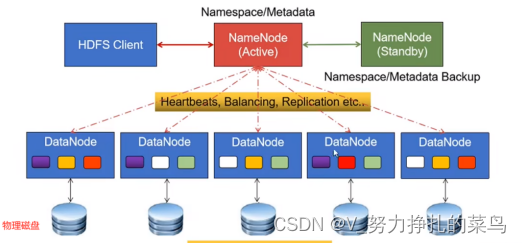
DateNode作用1:存储。实现存储的过程——不同色块被称为副本,分布在不同存储节点内,且副本没有主从之分。这些副本都可以在数据读取时提供读取服务,具体读取时,哪个存储节点里的块对外读取时占用的IO占用最低读哪个,这样保证IO均衡。最后所有读取的数据块通过linux文件系统将数据块落在物理磁盘之上。
DateNode作用2:提供数据读写——客户端Client访问NameNode Active时,由NameNode Active识别低IO,存储空间更剩余的存储节点DateNode,在明确具体是哪个存储节点DateNode后,由NameNode Active告知客户端Client具体是哪一个存储节点DateNode,后由客户端Client直接和该存储节点DateNode进行交互,这样的话带来的好处是:1、数据不通过NameNode ,这样的话NameNode Active这个单节点的IO不会成为整个集群的IO瓶颈,2、并且可以并发的对不同DateNode进行数据使用,以此提高整个集群的数据使用效率。 但是写,某一时间只支持一个写入,所以不支持并发文件的并发写入,但支持并发文件的并发读取【并发读取-即Client1访问DateNode2的白色块文件的同时,Client2访问DateNode3的白色块文件】。****
NameNode和DateNode之间的交互过程有一个机制:叫做心跳机制。NameNode和DateNode之间固定每3秒进行一次交互。NameNode无论是和DateNode还是Client进行交互,NameNode主动发出请求的次数远远小于接受的次数。
HDFS进行存储时有两类数据是关键,业务数据、描述业务数据的数据(即源数据信息)。如图所示:首先HDFS会将数据文件当中的数据切成等大(128MB 兆)的块(block)均匀存储在整个集群中。
关于block块以及对应数据文件,NameNode会存储一个源数据信息:file1:block1,block2...、block1:node01,node02,node03。当客户端Client对10G文件发出读取数据请求时,NameNode可以直接将源数据表单(如Master)返回给Client,NameNode通过这种方式间接管理数据文件。
版权归原作者 V_努力挣扎的菜鸟 所有, 如有侵权,请联系我们删除。