
🖥️ NodeJS专栏:Node.js从入门到精通
🖥️ 博主的前端之路:前端之行,任重道远(来自大三学长的万字自述)
🧧 个人社区:海底烧烤店ai(从前端到全栈)
🧑💼个人简介:即将大三的学生,一个不甘平庸的平凡人🍬
👉 你的一键三连是我更新的最大动力❤️!
🏆分享博主自用牛客网🏆:一个非常全面的面试刷题求职网站,真的超级好用(点击跳转)🍬

前言
最近博主一直在牛客网刷题巩固基础知识,快来和我一起冲关升级吧!点击进入牛客网
在前面我们已经学习过
Node.js
的
fs
、
path
与
http
这三个内置模块,本篇文章将结合这几个模块写一个分离HTML文件的小案例(超级简单,一看就会!),目的是巩固所学知识,加强记忆,让我们开始吧!
Node.js往期文章可查阅专栏:Node.js从入门到精通
文章目录
案例效果
有这样一个
main.html
文件:
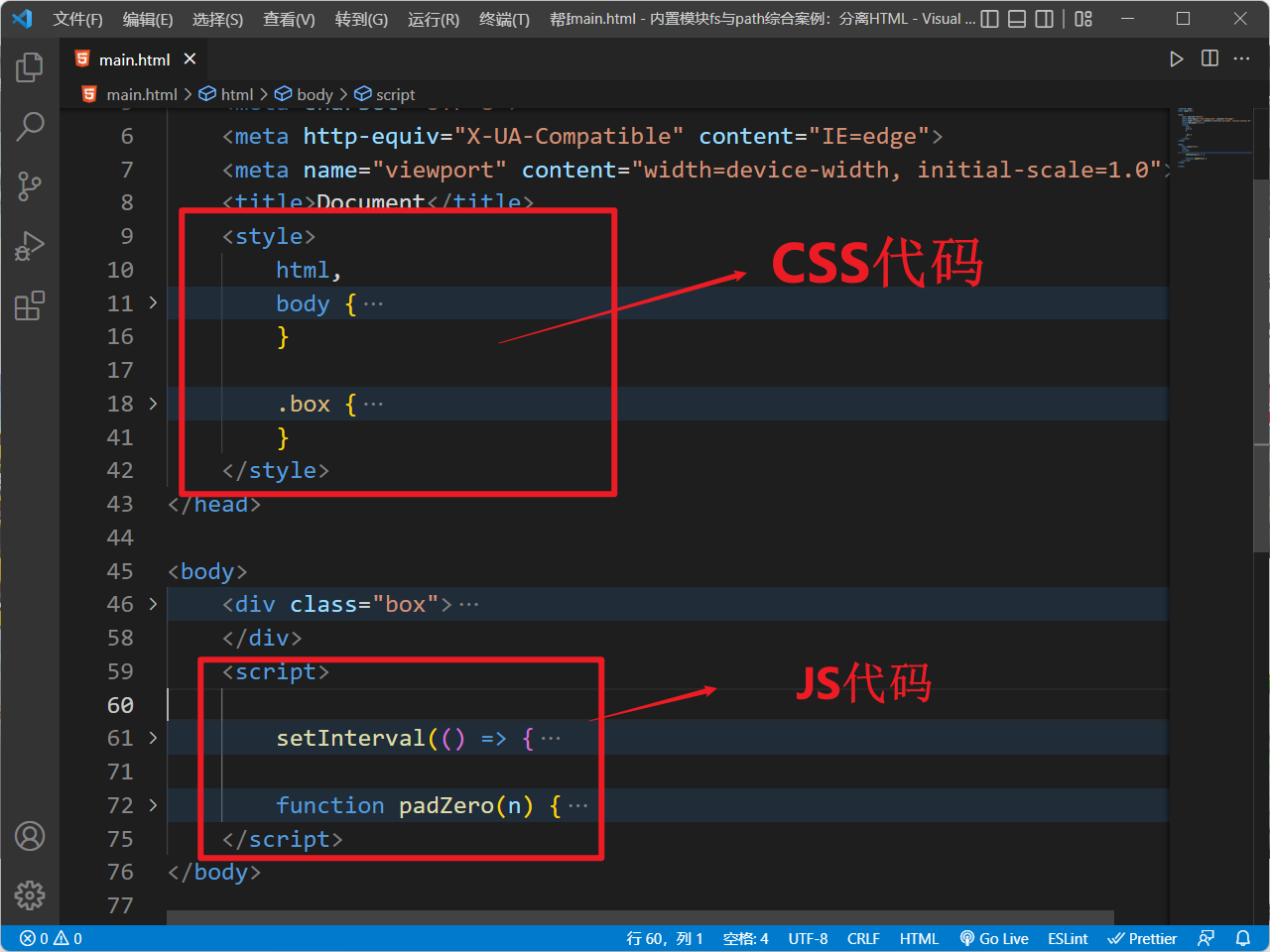
我们需要分割这个
main.html
文件,将其中的
CSS
和
JS
代码抽离到单独的
.css
和
.js
文件中,既将
main.html
文件中的
HTML
,
CSS
,
JS
代码分离到三个文件中,最终分离
HTML
后的案例目录结构如下:
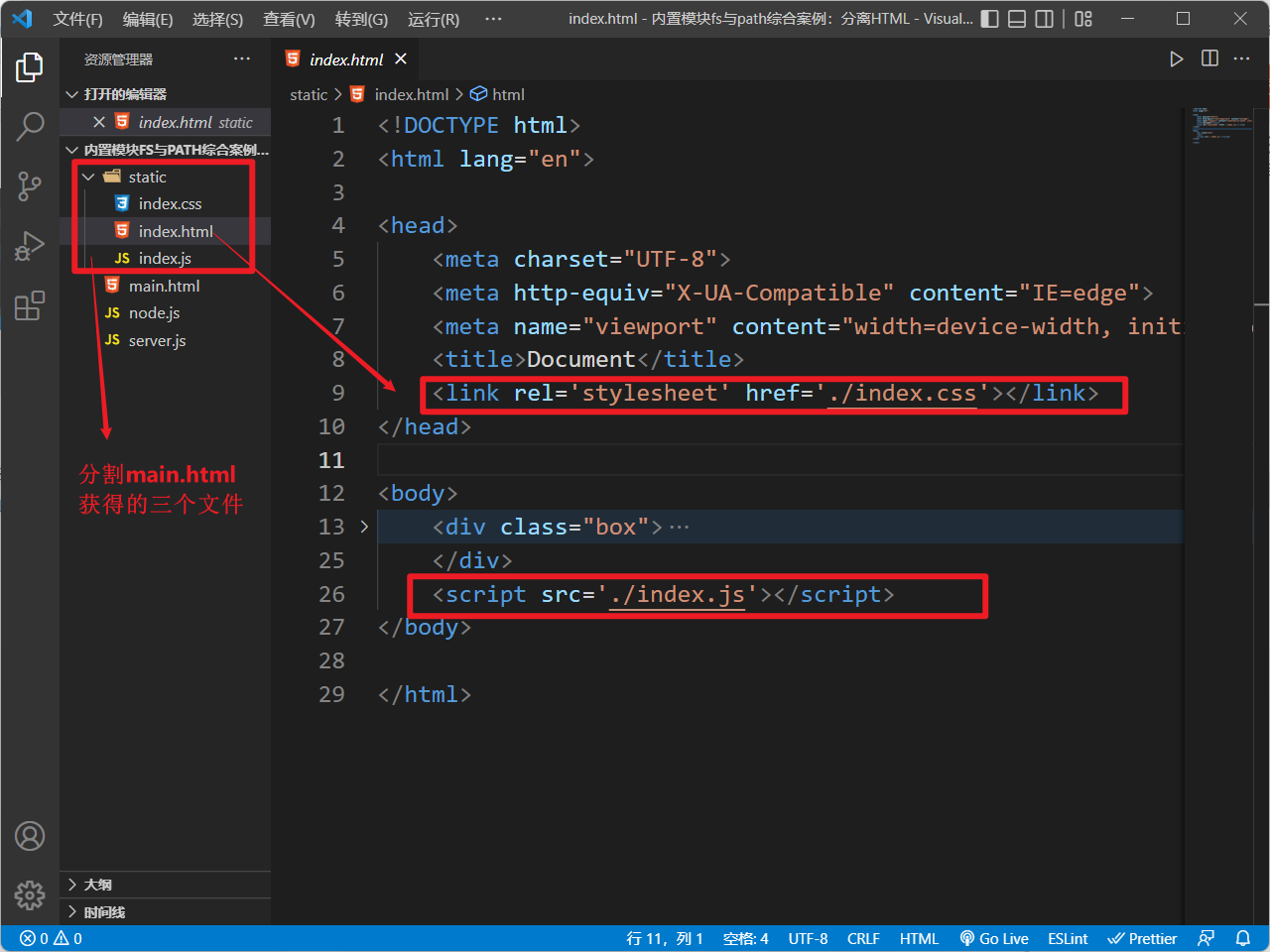
对于
main.html中的
css,
js,
html结构代码自己随便写,只要这些
css和
js代码能发挥作用,能看出效果就行
定义主函数
定义一个
createFile
函数,将其作为整个案例效果的主函数,我们只需将需要分割的
HTML
文件的地址路径作为参数传递给
createFile
函数即可实现分割该
HTML
文件的功能:
在
main.html
同级创建
node.js
文件
// node.jsconst fs =require("fs");const path =require("path");// 主函数functioncreateFile(src){// 读取文件内容
fs.readFile(path.join(__dirname, src),"utf-8",(err, data)=>{if(err){return console.log("读取main.html失败!");}// 调用处理函数createCss(data);createJs(data);createHtml(data);});}
createFile
函数的功能很简单,就是通过
fs.readFile
配合
path.join
来读取指定路径的文件内容,读取成功后分别调用:
createCss(抽离CSS的函数)createHtml(抽离HTML的函数)createJs(抽离JS的函数)
定义正则表达式
我们需要使用正则来提取
main.html
文件中的
css
和
js
代码,所以这里定义两个正则表达式:
node.js
中添加以下代码
// node.js// \s表示空白字符;\S 表示非空白字符 ;* 表示匹配任意次const regCss =/<style>[\s\S]*<\/style>/;// 用于提取cssconst regJs =/<script>[\s\S]*<\/script>/;// 用于提取js
定义抽离CSS的函数
先在
main.html
同级创建一个
static
目录,用来存放我们分离后的文件
node.js
中添加以下代码
// node.js// 抽离cssfunctioncreateCss(data){// regCss 用于匹配CSS的正则 // cssStr 匹配到的纯CSS代码字符串const cssStr = regCss
.exec(data)[0].replace("<style>","").replace("</style>","");// 将cssStr写入static目录下的index.css文件
fs.writeFile(path.join(__dirname,"/static/index.css"), cssStr,(err)=>{if(err){return console.log("抽离css失败!");}});}
exec()方法在一个指定字符串中执行一个搜索匹配。返回一个结果数组或
null
通过正则对象的
exec
方法提取数据
data
中符合
regCss
正则的字符串,因为
exec
方法匹配成功时返回的是一个数组,所以需要指定下标获取对应的元素
之后通过
replace
将获取到的字符串的前后
style
标签去除,最终获得的
cssStr
就是原数据的
CSS
代码
之后通过
fs.writeFile
配合
path.join
在
static
目录下创建
index.css
文件并将
cssStr
写入其中
定义抽离JS的函数
node.js
中添加以下代码
// node.js// 抽离js// 抽离jsfunctioncreateJs(data){// regJs 用于匹配JS的正则// jsStr 匹配到的纯JS代码字符串const jsStr = regJs
.exec(data)[0].replace("<script>","").replace("</script>","");// 将jsStr写入static目录下的index.js文件
fs.writeFile(path.join(__dirname,"/static/index.js"), jsStr,(err)=>{if(err){return console.log("抽离js失败!");}});}
createJs
函数与
createCss
函数大致相同
定义抽离HTML的文件
node.js
中添加以下代码
// node.js// 抽离htmlfunctioncreateHtml(data){// htmlStr 纯HTML代码字符串const htmlStr = data
// 替换原regCss部分.replace(regCss,"<link rel='stylesheet' href='./index.css'></link>")// 替换原regJs部分.replace(regJs,"<script src='./index.js'></script>");// 将htmlStr写入static目录下的index.html文件
fs.writeFile(path.join(__dirname,"/static/index.html"), htmlStr,(err)=>{if(err){return console.log("创建index.html失败!");}});}
replace
方法的第一个参数可以直接填正则对象,所以这里只需将
regCss
和
regJs
作为参数填入其中,就能很轻松的将原数据中的
<style> ...</style>
(内联CSS代码)和
<script>...</script>
(内联JS代码)替换成外部导入的方式
启动分离任务
调用
createFile
函数并启动
node.js
文件,开始分离
main.html
文件
node.js
中添加以下代码
// node.jscreateFile("./main.html");
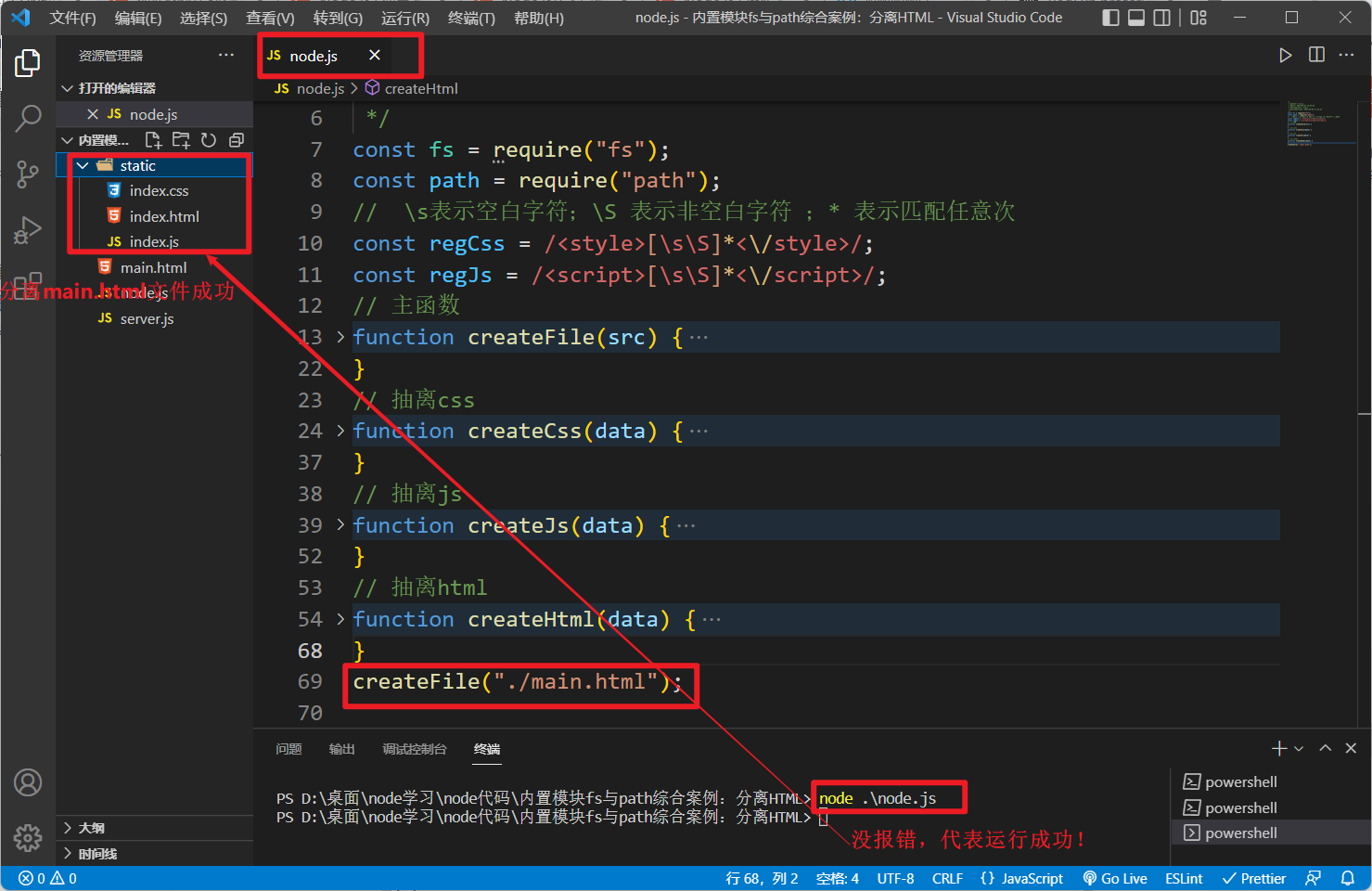
完整
node.js
文件如下:
服务端运行测试
案例根目录下创建
server.js
用于启动
node
服务器:
// server.jsconst http =require("http");const fs =require("fs");const path =require("path");const server = http.createServer();
server.on("request",(req, res)=>{// 不匹配 /favicon.icoif(req.url ==="/favicon.ico"){return;}// 根据请求路径去获取文件地址const fpath = path.join(__dirname, req.url);// 读取文件内容
fs.readFile(fpath,"utf-8",(err, data)=>{if(err){return console.log(err);}// 返回读取的内容
res.end(data);});});
server.listen(3000,()=>{
console.log("服务器启动成功!");});
此时浏览器访问
http://localhost:3000/main.html与
http://localhost:3000/static/index.html会发现展示效果一致,这就说明我们分割
main.html文件后获得的
index.html是正常的
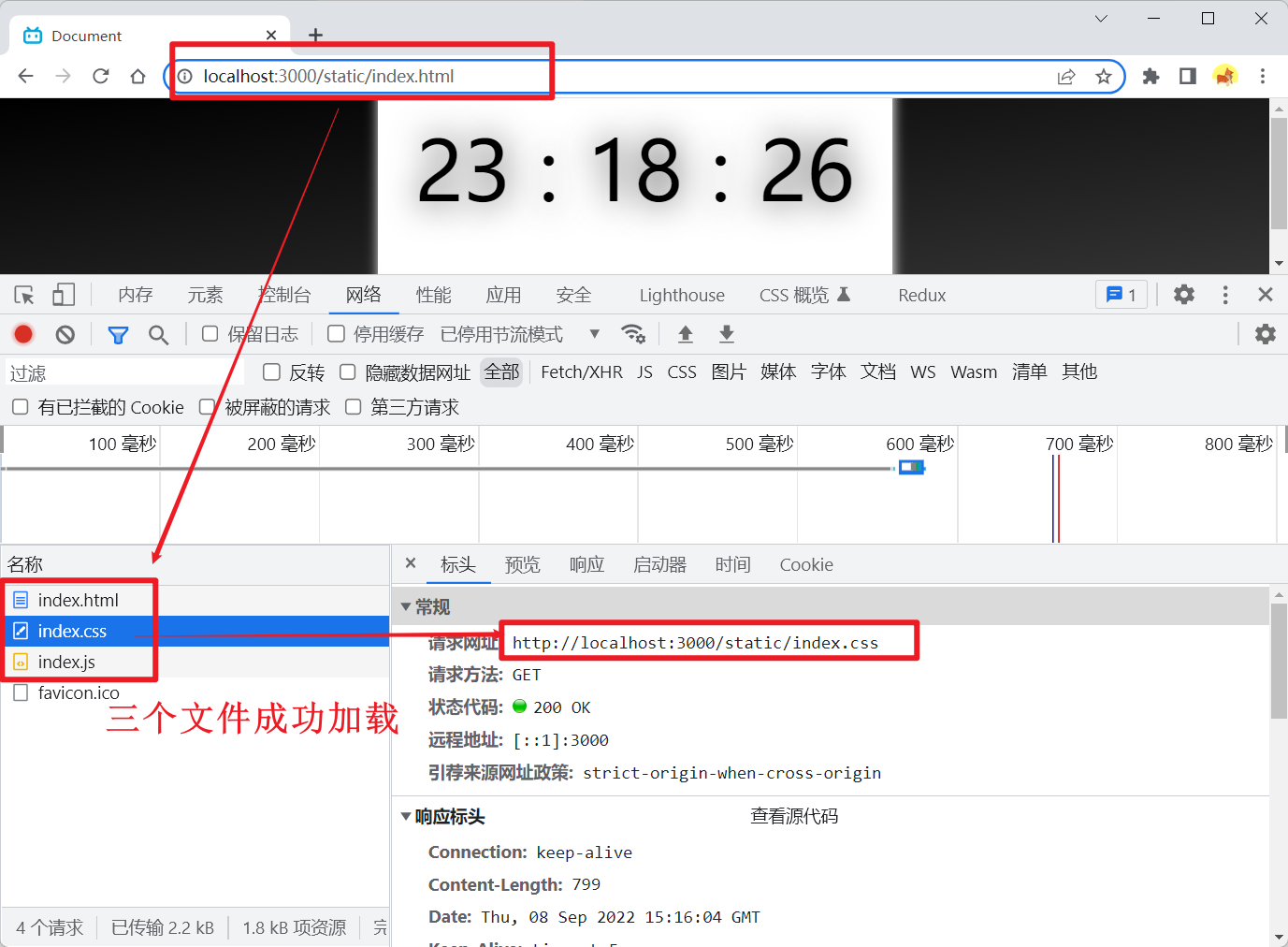
访问
http://localhost:3000/static/index.html
发现
页面
、
css
、
js
都能正常加载,
index.html
中引入
css
路径是
./index.css
,
./
代表同级,则相当于是请求了
http://localhost:3000/static/index.css
,所以通过
path.join
能正确找到该
css
路径并正确加载该
css
,加载
js
文件同理
在本地打开
main.html和
/static/index.html文件也能验证我们是否分离成功,这里使用
node服务器进行测试完全是为了**加强巩固一下
node知识**
结语
好啦,这个分离HTML的小案例到此就结束了,是不是超级简单呢,赶快动手去试试吧!
如果你在食用过程中对
fs
,
path
,
http
等这些内置模块有不熟悉的地方,可以去我的
Node.js专栏
进行学习 👉 Node.js从入门到精通
订阅专栏,关注博主,学习前端(进击全栈)不迷路!
如果本篇文章对你有所帮助,还请客官一件四连!❤️

基础不牢,地动山摇! 快来和博主一起来牛客网刷题巩固基础知识吧!
版权归原作者 海底烧烤店ai 所有, 如有侵权,请联系我们删除。