
一、创建表格
1.1 创建表
#语法
CREATE TABLE 表名(
字段名1 字段范例(长度) 是不是为空,
字段名2 字段范例 是不是为空 );
#案例
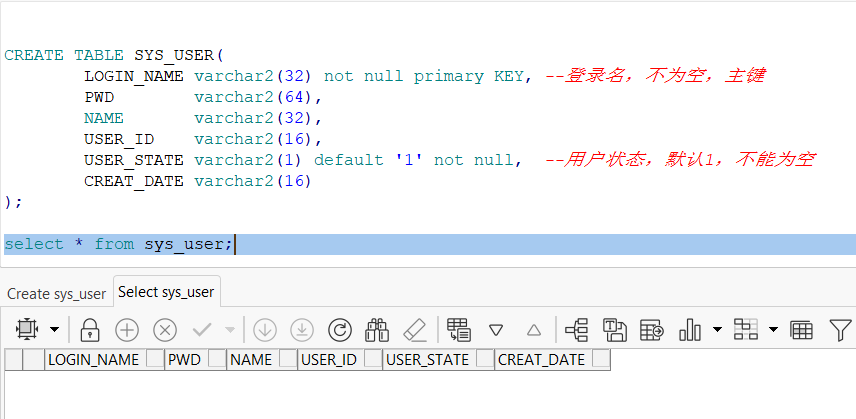
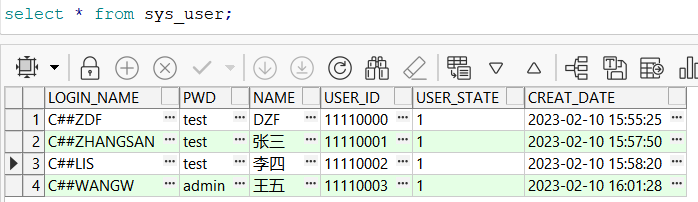
CREATE TABLE SYS_USER(
LOGIN_NAME varchar2(32) not null primary KEY, --登录名,不为空,主键
PWD varchar2(64),
NAME varchar2(32),
USER_ID varchar2(16),
USER_STATE varchar2(1) default '1' not null, --用户状态,默认1,不能为空
CREAT_DATE varchar2(16)
);
1.2 创建表时创建主外键
# 语法
create table 表名1 (
字段名1 字段范例(长度),
字段名2 字段范例,
constraint 主键名 primary key (表1字段名),
constraint 外键名 foreign key (表1字段名) references 表名2 (表2字段名)
);
#案例
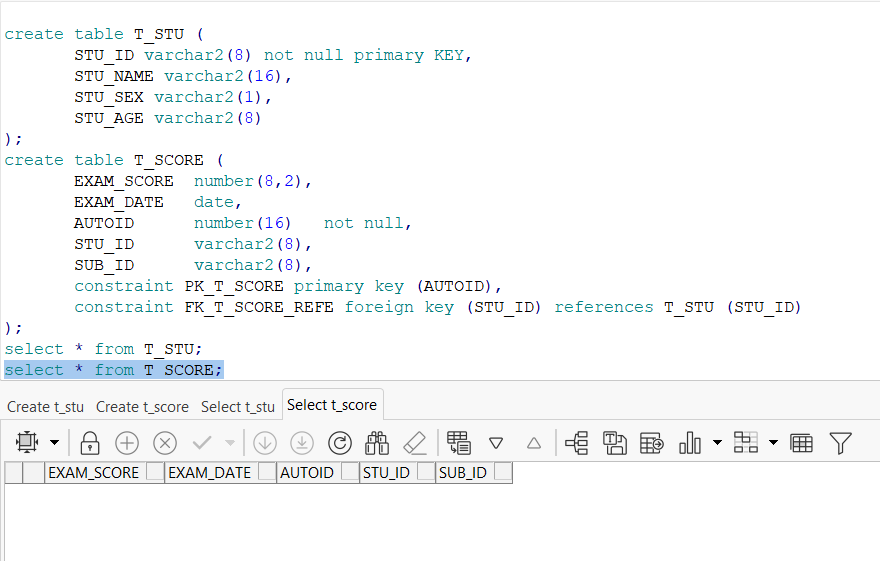
create table T_STU (
STU_ID varchar2(8) not null primary KEY,
STU_NAME varchar2(16),
STU_SEX varchar2(1),
STU_AGE varchar2(8)
);
create table T_SCORE (
EXAM_SCORE number(8,2),
EXAM_DATE date,
AUTOID number(16) not null,
STU_ID varchar2(8),
SUB_ID varchar2(8),
constraint PK_T_SCORE primary key (AUTOID),
constraint FK_T_SCORE_REFE foreign key (STU_ID) references T_STU (STU_ID)
);
二、约束
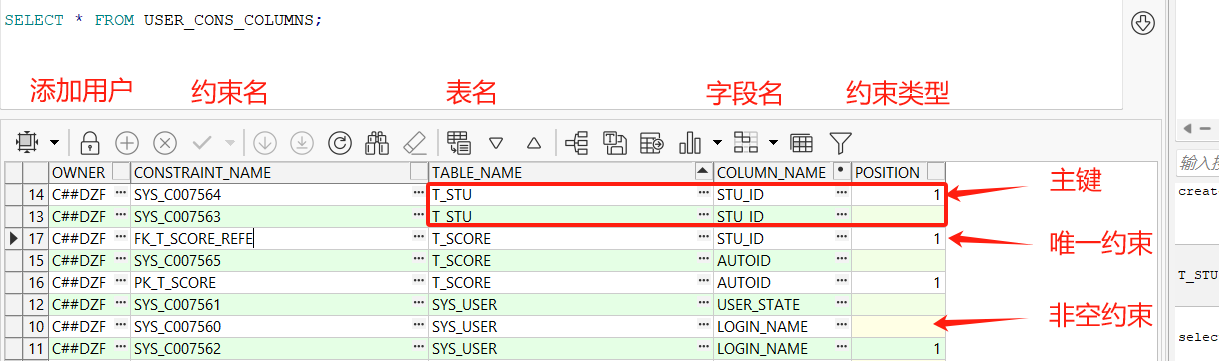
2.1 查看约束
SELECT * FROM USER_CONS_COLUMNS;
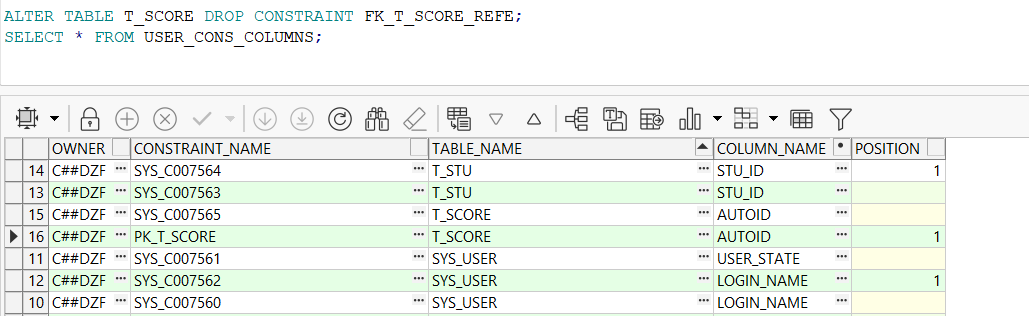
2.2 删除约束
ALTER TABLE 表名 DROP CONSTRAINT 主键名;
ALTER TABLE T_SCORE DROP CONSTRAINT FK_T_SCORE_REFE;
2.3 新增主键
ALTER TABLE 表名 ADD CONSTRAINT 主键名 PRIMARY KEY (字段名1);
2.4 新增外键
ALTER TABLE 表名 ADD CONSTRAINT 外键名 FOREIGN KEY (字段名1) REFERENCES 关联表 (字段名2);
ALTER TABLE T_SCORE ADD CONSTRAINT FK_T_SCORE_REFE FOREIGN KEY (STU_ID) REFERENCES T_STU (STU_ID);
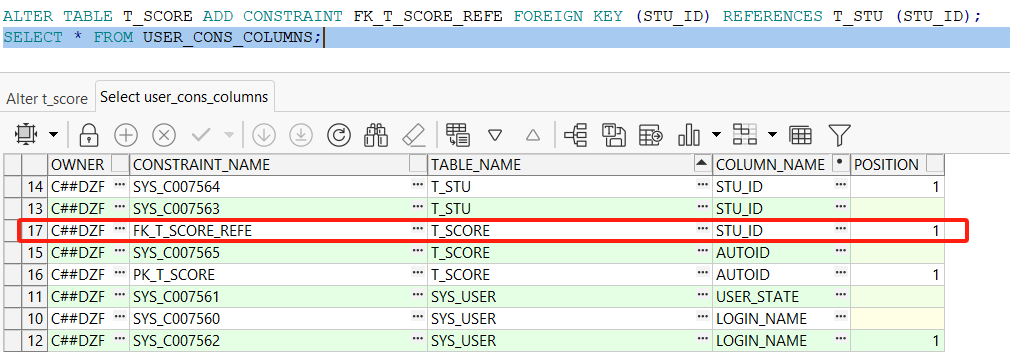
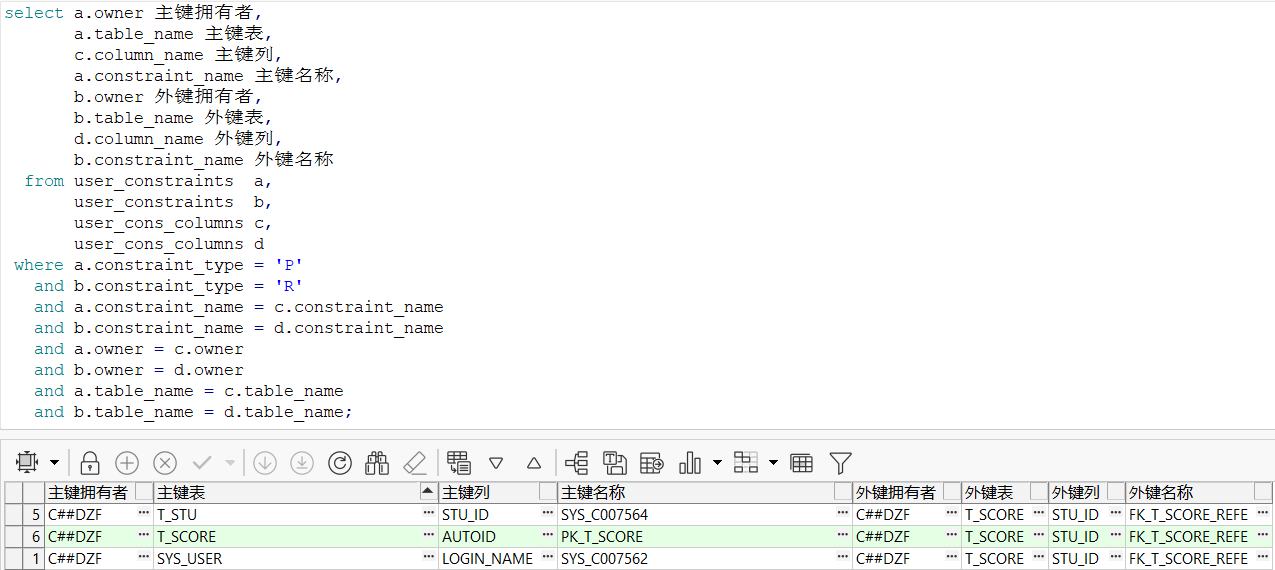
2.5 主外键关联查询
user_constraints 是表约束的视图。
user_cons_columns 是表约束字段的视图
select a.owner 主键拥有者,
a.table_name 主键表,
c.column_name 主键列,
a.constraint_name 主键名称,
b.owner 外键拥有者,
b.table_name 外键表,
d.column_name 外键列,
b.constraint_name 外键名称
from user_constraints a,
user_constraints b,
user_cons_columns c,
user_cons_columns d
where a.constraint_type = 'P'
and b.constraint_type = 'R'
and a.constraint_name = c.constraint_name
and b.constraint_name = d.constraint_name
and a.owner = c.owner
and b.owner = d.owner
and a.table_name = c.table_name
and b.table_name = d.table_name;
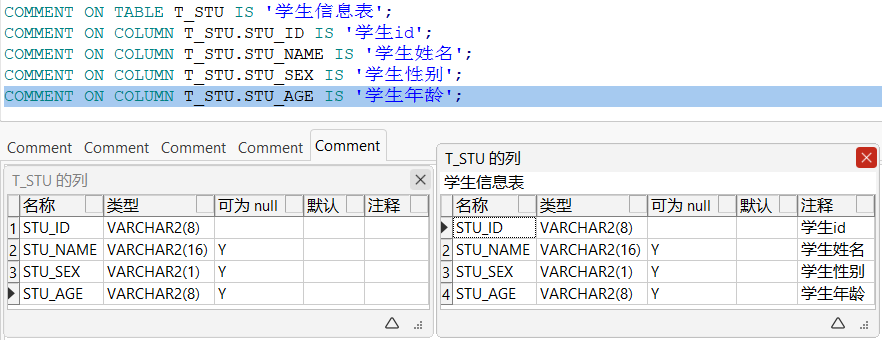
三、注释修改
3.1 表注释修改
COMMENT ON TABLE 表名 IS '注释内容';
3.2 字段注释修改
COMMENT ON COLUMN 表名.字段名 IS '注释内容';
四、删除
4.1 删除表
4.1.1 删除普通表,并未真正删除表,只是把该表放在回收站中。
drop table 表名;
4.1.2 删除带约束的表
drop table 表名 cascade constraints;
4.1.3 一次性彻底删除表
purge指示一次性彻底删除表,不把该表放入回收站
drop table 表名 purge;
五、回收站
5.1 查看回收站中的对象
select * from recyclebin;

5.2 清空回收站中的某个表
purge table "BIN$KLBHJ59VRN+7IKoh259QJw==$0";

5.3 清空回收站中的所有表
purge recyclebin;

5.4 从回收站中还原被删除的表
flashback table "BIN$IhMeNwEnREqK6Mq8FI7PaA==$0" to before drop

六、表字段
6.1 添加字段的语法
alter table 表名 add (字段名 datatype [default value][null/not null],...);
alter table SYS_USER add (PWD_STATE varchar2(1) default '0');

6.2 修改字段的语法
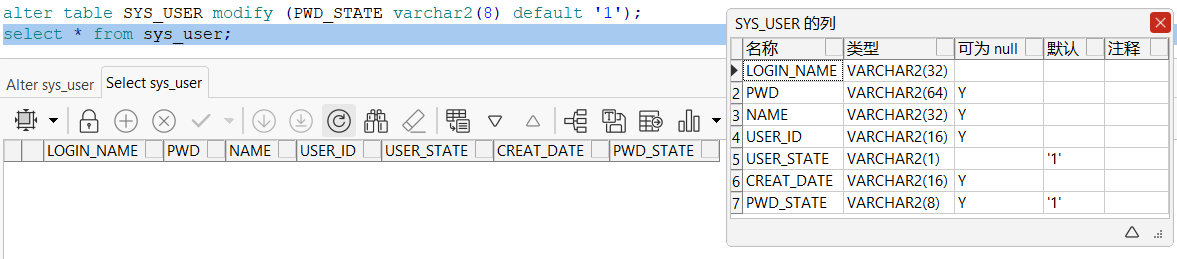
alter table 表名 modify (字段名 datatype [default value][null/not null],...);
alter table SYS_USER modify (PWD_STATE varchar2(8) default '1');
6.3 删除字段的语法
alter table 表名 drop (字段名);
七、序列
7.1 创建序列
#语法
CREATE SEQUENCE 序列名
INCREMENT BY n
START WITH n
MAXVALUE n| NOMAXVALUE
MINVALUE n| NOMAXVALUE
CYCLE|NOCYCLE
CACHE n| NOCACHE
- INCREMENT BY ⽤于定义序列的步长,如果省略,则默认为1,如果出现负值,则代表Oracle序列的值是按照此步长递减的。(每次增加或减少的值)
- START WITH 定义序列的初始值(即产⽣的第⼀个值),默认为1。
- MAXVALUE 定义序列⽣成器能产⽣的最⼤值。选项NOMAXVALUE是默认选项,代表没有最⼤值定义,这时对于递增Oracle序列,系统能够产⽣的最⼤值是10的27次⽅;对于递减序列,最⼤值是-1。
- MINVALUE 定义序列⽣成器能产⽣的最⼩值。选项NOMAXVALUE是默认选项,代表没有最⼩值定义,这时对于递减序列,系统能够产⽣的最⼩值是 10的26次⽅;对于递增序列,最⼩值是1。
- CYCLE和NOCYCLE 表⽰当序列⽣成器的值达到限制值后是否循环。CYCLE代表循环,NOCYCLE代表不循环。如果循环,则当递增序列达到最⼤值时,循环到最⼩值;对于递减序列达到最⼩值时,循环到最⼤值。如果不循环,达到限制值后,继续产⽣新值就会发⽣错误。
- CACHE(缓冲)定义存放序列的内存块的⼤⼩,默认为20。NOCACHE表⽰不对序列进⾏内存缓冲。对序列进⾏内存缓冲,可以改善序列的性能。⼤量语句发⽣请求,申请序列时,为了避免序列在运⽤层实现序列⽽引起的性能瓶颈。Oracle序列允许将序列提前⽣成 cache x个先存⼊内存,在发⽣⼤量申请序列语句时,可直接到运⾏最快的内存中去得到序列。但cache个数也不能设置太⼤,因为在数据库重启时,会清空内存信息,预存在内存中的序列会丢失,当数据库再次启动后,序列从上次内存中最⼤的序列号+1 开始存⼊cache x个。这种情况也能会在数据库关闭时也会导致序号不连续。
- NEXTVAL 返回序列中下⼀个有效的值,任何⽤户都可以引⽤。
- CURRVAL 中存放序列的当前值,NEXTVAL 应在 CURRVAL 之前指定,⼆者应同时有效。
- 案例
CREATE SEQUENCE SYS_USER_SQL
INCREMENT BY 1
START WITH 1
MINVALUE 1
MAXVALUE 999999999999;
7.2 查询序列下一个值
select SYS_USER_SQL.nextval from dual;

7.3 查询已创建的序列
SELECT * FROM USER_SEQUENCES;

表结构注释:
字段名称注释sequence_name序列名称min_value序列的最小值max_value序列的最大值increment_by序列递增的值cycle_flag序列是否在达到极限时结束?order_flag序列号是按顺序生成的吗?cache_size要缓存的序列号数(最小设置为2)last_number写入磁盘的最后序列号
八、同义词:(表名的映射)
正常查询其他用户名下的表需要用"用户名.表名"来查询,做了同义词后,可以直接用表名查询或者用"登录用户名.表名"查询。
CREATE OR REPLACE SYNONYM 表名
FOR 其他用户名.表名;
#案例
CREATE OR REPLACE SYNONYM CRM_FINAL_MEETING
FOR CRM_DM.CRM_FINAL_MEETING;
九、时间
9.1 时间字符串互相转化
- 时间格式化
to_char(SYSDATE, 'yyyy-mm-dd HH24:MI:SS')
- 字符串转时间
TO_DATE(字段名,'YYYY-MM-DD')
- 时间转字符串
TO_CHAR(TO_DATE(字段名,'YYYY-MM-DD'),'YYYYMM')
9.2 时间加减
- 加日期
TO_CHAR(SYSDATE - 1, 'YYYY-MM-DD HH24:MI:SS')
- 前一天前一小时前一分钟前一秒
TO_CHAR(SYSDATE - 1 - 1 / 24 - 1 / 24 / 60 - 1 / 24 / 60 / 60,'yyyy-mm-dd hh24:mi:ss')
- 一分钟前
TO_CHAR(SYSDATE - 1 / 24 / 60, 'yyyy-mm-dd hh24:mi:ss')
- 加月份
ADD_MONTHS(SYSDATE,-11)
- 30分钟后失效
TO_DATE(SUBSTR(T.flow_no,1,14),'YYYY-MM-DD HH24:MI:SS')+30/24/60 >= SYSDATE

十、字符串
- 字符串长度截取
SUBSTR(字段名,起始位置,截取长度)
SUBSTR(DATA_DATE,0,6)
- trim 字符串去空格
#去左面空格
ltrim(字段名)
#去右面空格
rtrim(字段名)
#去两面空格
trim(字段名)
- 字符串替换
replace(字段名,'被替换内容','替换内容')
- 字符串截取
#从左边开始截取,n是截取的长度;
LEFT(字段名, n)
#从右边开始截取,n是截取的长度;
RIGHT(字段名, n)
#返回字符串str从第n个字符截取到第m个字符;
SUBSTR(字段名 ,n ,m)
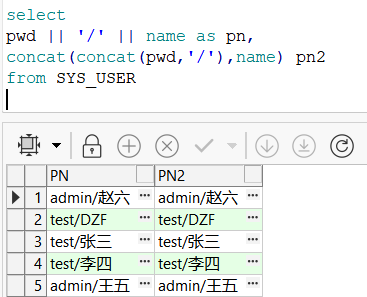
- 字段拼接
字段名1 || 字段名2
或
CONCAT(值1,值2)
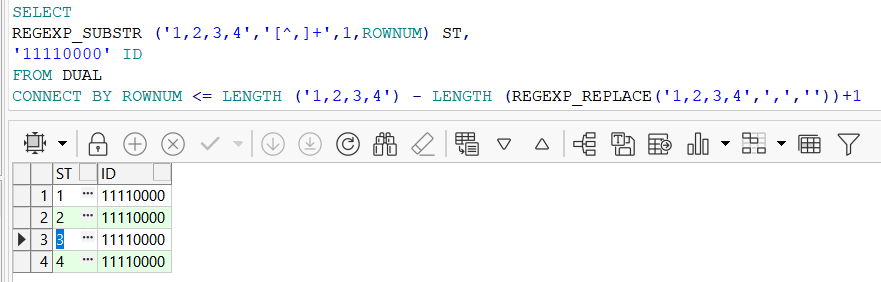
- 将以指定字符拼接的字段拆分成多行
SELECT
REGEXP_SUBSTR ('1,2,3,4','[^,]+',1,ROWNUM) ST,
'11110000' ID
FROM DUAL
CONNECT BY ROWNUM <= LENGTH ('1,2,3,4') - LENGTH (REGEXP_REPLACE('1,2,3,4',',',''))+1
- 字符串转数字
TO_NUMBER(REGEXP_SUBSTR(字段名, '[0-9]*[0-9]', 1))
或
NVL(字段名,0)/1
- 字符串大小写转换
#将字符串转成全大写
SELECT UPPER('abc') UPP FROM DUAL;
#将字符串转成全小写
SELECT LOWER('ABC') LOW FROM DUAL;
十一、保留小数点后两位
- 直接保留两位小数
#没有千位符
TO_CHAR(TRUNC(字段名/10000,2),'FM99999999999999990.00')
#有千位符
TO_CHAR(TRUNC(字段名/10000,2),'FM999,999,999,999,999,990.00')
- 四舍五入保留两位小数
ROUND(字段名/10000,2)
十二、取两个查询结果的合集或交集
- 取两个查询结果的合集
- UNION:将语句1和语句2不重复的结果查询出来,同时进行默认规则的排序。
- UNION ALL:将语句1和语句2所有的结果查询出来,重复的也查询,不进行排序。取两个查询结果的交集
- INTERSECT:将语句1和语句2相同的结果查询出来
[SQL语句1]
INTERSECT
[SQL语句2]
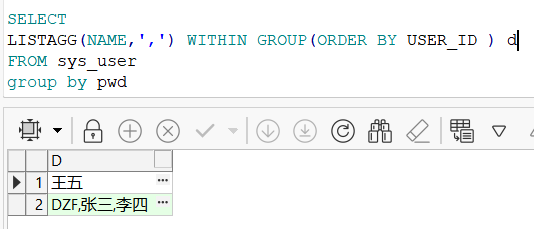
十三、查询结果合并到一行
LISTAGG(字段名,',') WITHIN GROUP(ORDER BY 字段名 )
十四、列字段排序
- 不加隔断
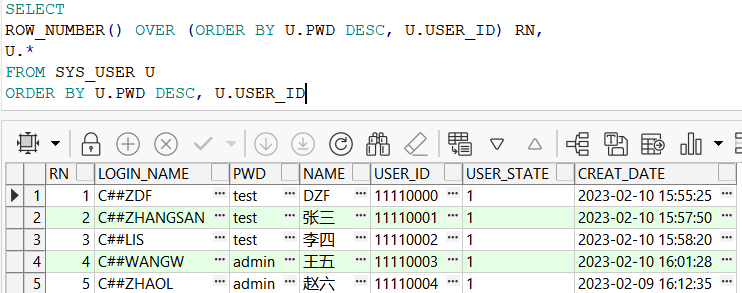
ROW_NUMBER() OVER (ORDER BY 字段名1 DESC,字段名2) RN
- 隔断排序
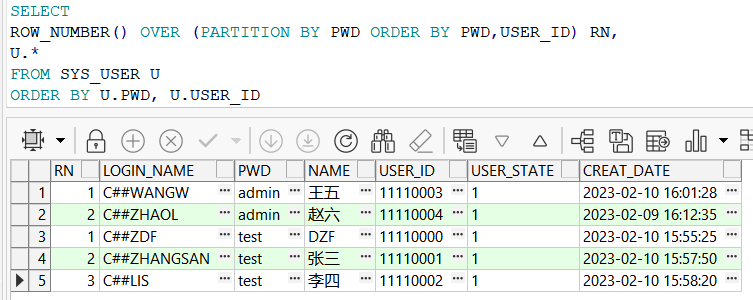
ROW_NUMBER() OVER (PARTITION BY 字段名1,字段名2 ORDER BY 字段名1 DESC,字段名2) RN
十五、行转列
PIVOT (
SUM(值字段)
FOR 列字段 IN ('值1' 字段名1,'值2' 字段名2)
)
值字段:值字段中的值 转列后为列中的值
列字段:列字段中的值 转列后为列字段名

十六、列转行
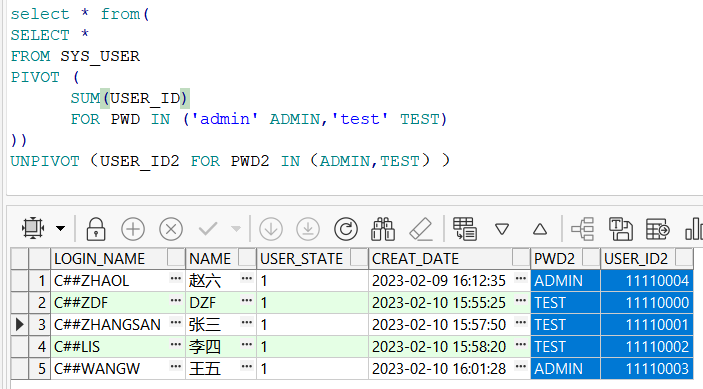
UNPIVOT(自定义列名/*列的值*/ FOR 自定义列名 IN(列名))
十七、EXISTS 和 NOT EXISTS
EXIST S (SQL 查询结果集为真返回)描述:如果在 查询条件 中指定的关键字存在,返回 True,若不存在,返回 False。
案例
select * from a where exists(select 1 from b where a.id = b.id);
a表和b表使用id关联,这条语句的含义是,当b表能够查询出结果时,exists(select * from b where a.id = b.id)子句为真,只有满足exists结果为真时,才会查询出a表的记录。
- NOT EXISTS (SQL 查询结果集为真不返回)
十八、CLOB数据格式取值
定位到想要取值的位置,将CLOB转成字符串类型并截取想要的值
- TO_CLOB(字段名):将字符串转CLOB类型
SELECT TO_CLOB('aabbccbbccdd') str FROM DUAL;
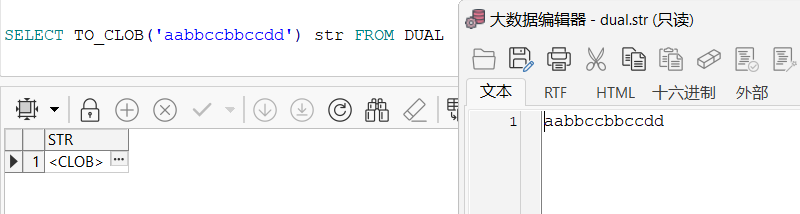
- INSTR(字段名,目标字符串,index1,index2):定位指定字符串的起始位置
- index1:开始查找位置(默认1)
- index2:目标字符串第几次出现(默认1)
SELECT
INSTR(STR,'bb') INDEX1
FROM (
SELECT TO_CLOB('aabbccbbccdd') str FROM DUAL
)

- DBMS_LOB.SUBSTR(字段名,长度,起始位置):将CLOB转成字符串类型并截取,其中字段名为必须的,截取长度以及其实位置可以根据需要使用。
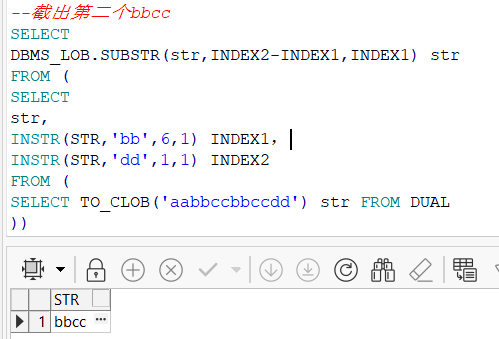
--截出第二个bbcc
SELECT
DBMS_LOB.SUBSTR(str,INDEX2-INDEX1,INDEX1) str
FROM (
SELECT
str,
INSTR(STR,'bb',6,1) INDEX1,
INSTR(STR,'dd',1,1) INDEX2
FROM (
SELECT TO_CLOB('aabbccbbccdd') str FROM DUAL
))
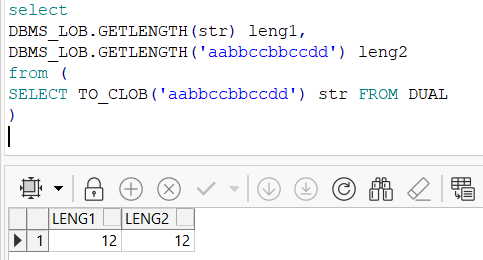
注:因为clob的字段长度最大为4GB,varchar的最大长度为4000,所以在转换的时候可能会造成数据部分丢失,因此在转换之前,建议先通过
DBMS_LOB.GETLENGTH(字段名)方法查看字段的长度后再进行转换,避免数据内容丢失。
- DBMS_LOB.GETLENGTH(字段名):查看数据长度
select
DBMS_LOB.GETLENGTH(str) leng1,
DBMS_LOB.GETLENGTH('aabbccbbccdd') leng2
from (
SELECT TO_CLOB('aabbccbbccdd') str FROM DUAL
)
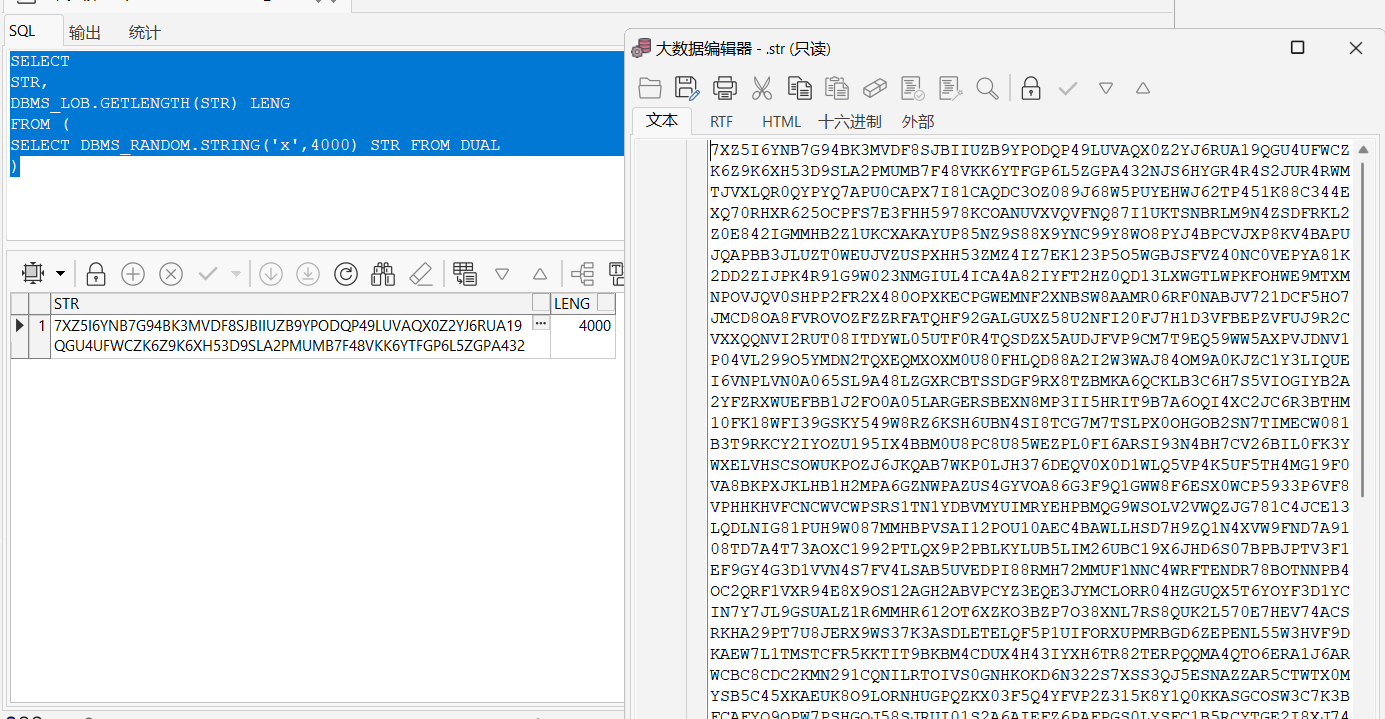
- 生成一个长度为4000的字符串,内容随机
SELECT
STR,
DBMS_LOB.GETLENGTH(STR) LENG
FROM (
SELECT DBMS_RANDOM.STRING('x',4000) STR FROM DUAL
)
标签:
oracle
本文转载自: https://blog.csdn.net/weixin_54975325/article/details/139437322
版权归原作者 0.0雨 所有, 如有侵权,请联系我们删除。
版权归原作者 0.0雨 所有, 如有侵权,请联系我们删除。