
AI与传奇开心果博文系列
- 系列博文目录
- Python的AI相关库技术点案例示例系列
- 博文目录
- 前言- 一、AI作画算法原理介绍- 二、深度学习的神经网络AI作画算法原理应用示例代码- 三、特征学习AI作画算法原理应用示例代码- 四、风格迁移AI作画算法原理应用示例代码- 五、损失函数AI作画算法原理应用示例代码- 六、条件生成AI作画算法原理应用示例代码- 七、创新和创意的AI作画算法原理应用示例代码- 八、知识点归纳
系列博文目录
Python的AI相关库技术点案例示例系列
博文目录
前言


AI作画算法原理是指基于深度学习的神经网络技术,通过各种神经网络模型算法学习和模仿绘画作品的特征,实现计算机自动创作新的绘画作品所遵循的人工智能绘画算法的原理。
掌握AI作画算法的原理可以帮助我们利用人工智能技术生成绘画作品,实现自动化的创作过程。通过深度学习的生成对抗网络为代表的各种神经网络技术,AI作画算法可以学习和模仿画家的风格,生成逼真的绘画艺术作品。这种算法不仅可以帮助画家提高创作效率和探索新的创意,还可以为非专业人士提供创作工具和启发,促进绘画艺术与科技的结合,拓展绘画艺术表现形式和创作可能性。
一、AI作画算法原理介绍

AI作画算法原理主要包括以下几个方面:
- 深度学习的神经网络模型AI作画算法原理: AI作画算法基于深度学习的各种神经网络技术,通过各种神经网络模型算法对大量绘画作品数据的学习和模仿,学会对绘画作品的特征和风格把握,从而实现计算机自动创作绘画作品。
- 特征学习AI作画算法原理: AI作画算法通过神经网络算法模型学习绘画作品的特征,包括线条、色彩、纹理等。神经网络能够提取和表示这些特征,从而生成具有相似特征的新作品。
- 风格迁移AI作画算法原理: 风格迁移是AI作画算法中常用的技术之一,通过将一个图像的风格应用到另一个图像上,实现生成具有特定风格的绘画作品。
- 损失函数AI作画算法原理: 在训练过程中,AI作画算法使用损失函数来评估生成作品与真实作品之间的差异,从而不断优化神经网络的参数,提高生成作品的质量和逼真度。
- 条件生成AI作画算法原理: 一些AI作画算法支持条件生成,即根据输入的条件或约束来生成符合特定要求的绘画作品,如风格、主题等。
- 创新和创意AI作画算法原理: AI作画算法不仅可以模仿现有的绘画作品,还能够生成全新的、具有创意和创新性的作品,为绘画创作带来新的可能性和灵感。
综上所述,AI作画算法原理主要包括深度学习的神经网络、特征学习、风格迁移、损失函数、条件生成、创新和创意等方面算法的原理,这些算法原理共同构成了AI作画算法实现自动创作的基础。
二、深度学习的神经网络AI作画算法原理应用示例代码

(一)使用神经网络模型算法实现自动创作绘画作品的一般过程示例代码
在AI作画算法中,深度学习的神经网络技术扮演着非常重要的角色。神经网络模型算法通过学习大量的绘画作品数据,可以学习到作品的特征和风格,并能够生成新的绘画作品。下面是一个简单的示例代码,演示如何使用神经网络算法实现自动创作绘画作品的一般过程:
import tensorflow as tf
from tensorflow.keras.layers import Dense, Flatten, Reshape
from tensorflow.keras.models import Sequential
import matplotlib.pyplot as plt
# 定义一个简单的生成器神经网络模型defbuild_generator():
model = Sequential([
Dense(256, activation='relu', input_shape=(100,)),
Dense(512, activation='relu'),
Dense(784, activation='sigmoid'),
Reshape((28,28))])return model
# 加载绘画作品数据集,这里以MNIST手写数字数据集为例(train_images, _),(_, _)= tf.keras.datasets.mnist.load_data()
train_images = train_images.reshape(train_images.shape[0],28,28,1).astype('float32')
train_images =(train_images -127.5)/127.5# 将像素值归一化到[-1, 1]之间# 构建生成器模型
generator = build_generator()# 定义损失函数和优化器
cross_entropy = tf.keras.losses.BinaryCrossentropy()
generator_optimizer = tf.keras.optimizers.Adam()# 定义生成器的训练步骤@tf.functiondeftrain_step(images):
noise = tf.random.normal([images.shape[0],100])with tf.GradientTape()as tape:
generated_images = generator(noise, training=True)
loss = cross_entropy(tf.ones_like(generated_images), generated_images)
gradients = tape.gradient(loss, generator.trainable_variables)
generator_optimizer.apply_gradients(zip(gradients, generator.trainable_variables))# 训练生成器模型
EPOCHS =100
BATCH_SIZE =128for epoch inrange(EPOCHS):for i inrange(0,len(train_images), BATCH_SIZE):
batch_images = train_images[i:i+BATCH_SIZE]
train_step(batch_images)# 生成新的绘画作品
noise = tf.random.normal([1,100])
generated_image = generator(noise, training=False)# 保存生成的图像
plt.imshow(generated_image[0], cmap='gray')
plt.axis('off')
plt.savefig('generated_image.png')# 展示生成的图像
plt.show()
在这个示例代码中,我们使用了一个简单的生成器神经网络模型来实现绘画作品的生成。首先加载了MNIST手写数字数据集作为训练数据,然后定义了生成器模型、损失函数和优化器,最后通过训练生成器模型来生成新的绘画作品。生成的图像可以保存或展示出来,从而实现了基于神经网络的自动创作绘画作品的过程。
(二)AI作画相关的主要神经网络模型介绍
在AI作画领域,主要的神经网络模型包括:

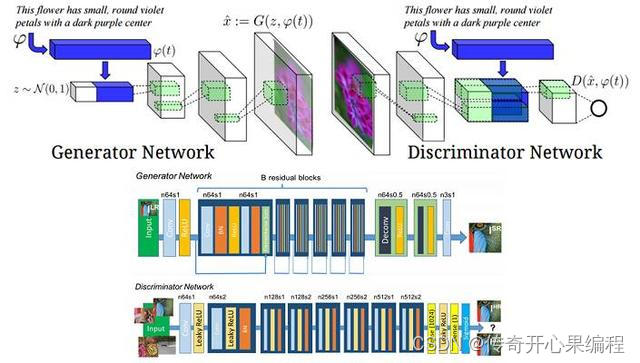
- 生成对抗网络(GAN):生成对抗网络是一种由生成器和判别器组成的对抗性训练框架,被广泛应用于图像生成任务。在AI作画中,GAN可以用来生成逼真的绘画作品,例如人脸头像等。
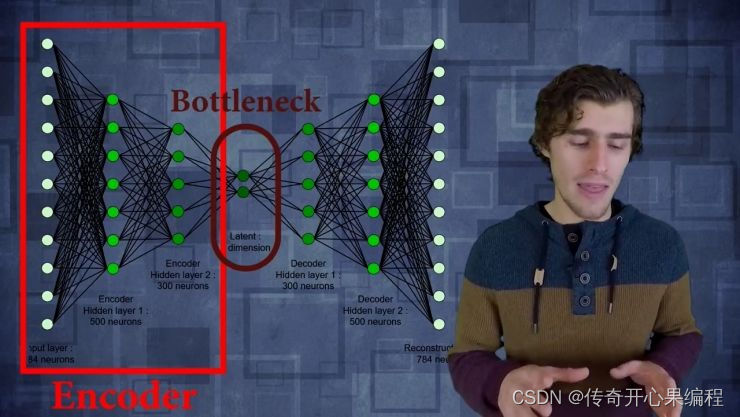
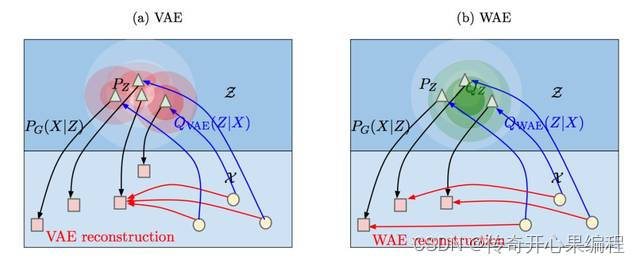
- 变分自编码器(VAE):变分自编码器是一种生成模型,可以学习数据的潜在表示,并用于生成新的数据样本。在AI作画中,VAE可以用来生成绘画作品,例如风景画等。

- 卷积神经网络(CNN):卷积神经网络在图像处理领域表现出色,可以用来提取图像特征并生成新的图像。在AI作画中,CNN可以用来实现风格迁移、图像修复等任务
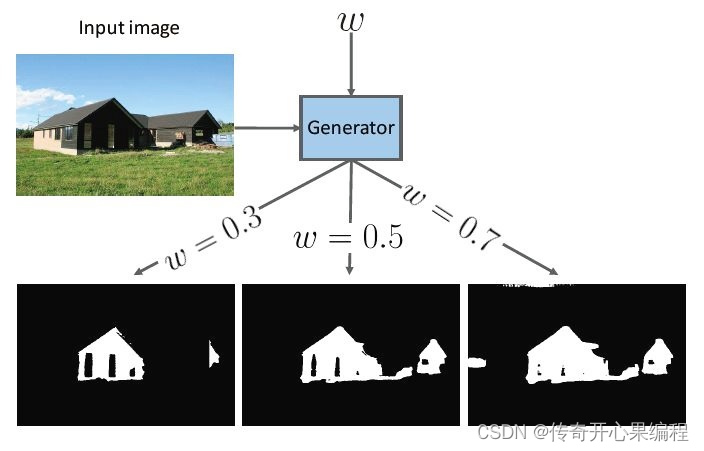
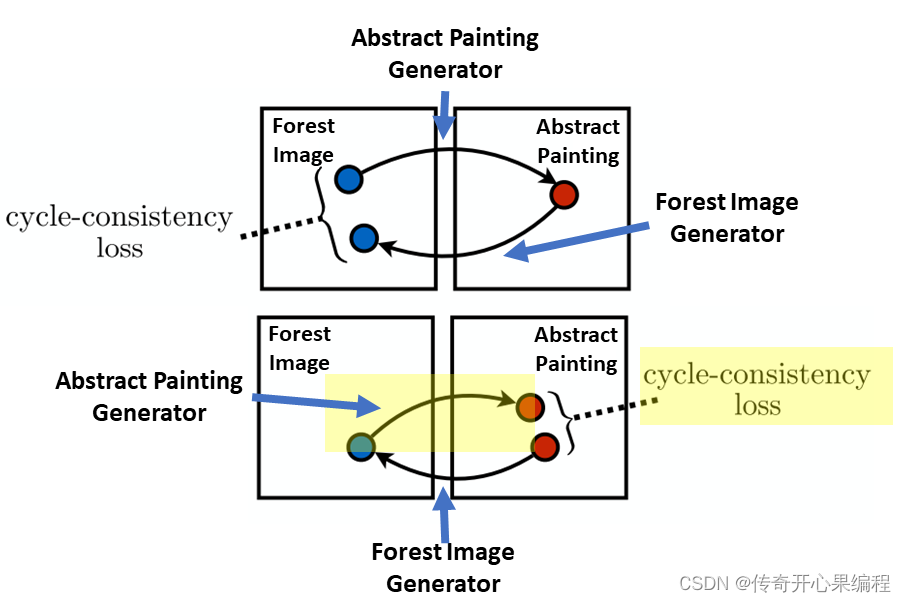
- 生成式对抗网络(GAN)的变体:除了传统的GAN模型外,还有许多GAN的变体模型,如条件生成对抗网络(cGAN)、循环一致生成对抗网络(CycleGAN)等,这些模型在AI作画领域也有着广泛的应用。
这些神经网络模型在AI作画领域有着不同的优势和适用性,可以根据具体的任务需求选择合适的模型进行设计和训练。同时,研究者们也在不断探索新的神经网络模型,以提高AI作画的效果和创造力。
(三)各种模型作画示例代码
1.生成对抗网络(GAN)作画示例代码
以下是一个简单的使用Python和TensorFlow实现的生成对抗网络(GAN)的示例代码,用于生成逼真的人脸头像。这个示例代码使用了CelebA数据集,通过训练生成器和判别器来生成逼真的人脸头像。
import tensorflow as tf
from tensorflow.keras import layers
import numpy as np
import matplotlib.pyplot as plt
# 加载CelebA数据集(x_train, _),(_, _)= tf.keras.datasets.cifar10.load_data()
x_train = x_train.astype('float32')
x_train =(x_train -127.5)/127.5
dataset = tf.data.Dataset.from_tensor_slices(x_train).shuffle(50000).batch(128)# 定义生成器模型defbuild_generator():
model = tf.keras.Sequential()
model.add(layers.Dense(4*4*512, input_shape=(100,), activation='relu'))
model.add(layers.Reshape((4,4,512)))
model.add(layers.Conv2DTranspose(256,(4,4), strides=(2,2), padding='same', activation='relu'))
model.add(layers.Conv2DTranspose(128,(4,4), strides=(2,2), padding='same', activation='relu'))
model.add(layers.Conv2DTranspose(3,(4,4), strides=(2,2), padding='same', activation='tanh'))return model
# 定义判别器模型defbuild_discriminator():
model = tf.keras.Sequential()
model.add(layers.Conv2D(64,(4,4), strides=(2,2), padding='same', input_shape=(32,32,3), activation='relu'))
model.add(layers.Conv2D(128,(4,4), strides=(2,2), padding='same', activation='relu'))
model.add(layers.Flatten())
model.add(layers.Dense(1, activation='sigmoid'))return model
# 定义生成对抗网络模型defbuild_gan(generator, discriminator):
model = tf.keras.Sequential()
model.add(generator)
model.add(discriminator)return model
# 定义训练过程deftrain_gan(gan, discriminator, generator, dataset, epochs=50, batch_size=128):for epoch inrange(epochs):for batch in dataset:
noise = tf.random.normal([batch_size,100])
generated_images = generator(noise)
x_combined = tf.concat([generated_images, batch], axis=0)
y_combined = tf.concat([tf.ones((batch_size,1)), tf.zeros((batch_size,1))], axis=0)
discriminator.trainable =True
discriminator.train_on_batch(x_combined, y_combined)
noise = tf.random.normal([batch_size,100])
y_mislabled = tf.ones((batch_size,1))
discriminator.trainable =False
gan.train_on_batch(noise, y_mislabled)# 创建生成器、判别器和生成对抗网络
generator = build_generator()
discriminator = build_discriminator()
gan = build_gan(generator, discriminator)# 编译生成器和判别器
generator.compile(loss='binary_crossentropy', optimizer='adam')
discriminator.compile(loss='binary_crossentropy', optimizer='adam')
discriminator.trainable =False
gan.compile(loss='binary_crossentropy', optimizer='adam')# 训练生成对抗网络
train_gan(gan, discriminator, generator, dataset, epochs=50)# 生成人脸头像示例
noise = tf.random.normal([10,100])
generated_images = generator(noise)
generated_images =0.5* generated_images +0.5# 反归一化for i inrange(10):
plt.subplot(2,5, i+1)
plt.imshow(generated_images[i])
plt.axis('off')
plt.show()
这个示例代码实现了一个简单的生成对抗网络,用于生成逼真的人脸头像。在训练过程中,生成器和判别器相互对抗、相互学习,最终生成器可以生成逼真的人脸头像。在训练完成后,生成器可以生成类似于CelebA数据集中人脸头像的图像。
- 变分自编码器(VAE)作画示例代码
以下是一个简单的示例代码,用于加载风景画样板作品数据集,并使用变分自编码器(VAE)生成新的风景画样本:
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.layers import Input, Dense, Lambda
from tensorflow.keras.models import Model
from tensorflow.keras import backend as K
from tensorflow.keras.losses import binary_crossentropy
import tensorflow as tf
# 加载风景画数据集# 假设风景画数据集存储在landscape_data.npy文件中
data = np.load('landscape_data.npy')# 数据预处理
data = data.astype('float32')/255.0
data = np.reshape(data,(len(data),784))# 构建变分自编码器(VAE)模型
latent_dim =2# 编码器部分
inputs = Input(shape=(784,))
h = Dense(256, activation='relu')(inputs)
z_mean = Dense(latent_dim)(h)
z_log_var = Dense(latent_dim)(h)# 采样函数defsampling(args):
z_mean, z_log_var = args
batch = K.shape(z_mean)[0]
dim = K.int_shape(z_mean)[1]
epsilon = K.random_normal(shape=(batch, dim))return z_mean + K.exp(0.5* z_log_var)* epsilon
z = Lambda(sampling)([z_mean, z_log_var])# 解码器部分
decoder_h = Dense(256, activation='relu')
decoder_mean = Dense(784, activation='sigmoid')
h_decoded = decoder_h(z)
x_decoded_mean = decoder_mean(h_decoded)# 构建VAE模型
vae = Model(inputs, x_decoded_mean)# 定义VAE的损失函数
xent_loss = binary_crossentropy(inputs, x_decoded_mean)
kl_loss =-0.5* K.mean(1+ z_log_var - K.square(z_mean)- K.exp(z_log_var), axis=-1)
vae_loss = K.mean(xent_loss + kl_loss)# 编译VAE模型
vae.add_loss(vae_loss)
vae.compile(optimizer='adam')# 训练VAE模型
vae.fit(data, epochs=50, batch_size=32)# 使用训练好的VAE生成新的风景画
n =15# 生成的风景画数量
figure = np.zeros((28* n,28* n))for i inrange(n):for j inrange(n):
z_sample = np.array([[np.random.normal(), np.random.normal()]])
x_decoded = decoder_mean.predict(z_sample)
landscape = x_decoded[0].reshape(28,28)
figure[i *28:(i +1)*28, j *28:(j +1)*28]= landscape
plt.figure(figsize=(10,10))
plt.imshow(figure, cmap='Greys')
plt.show()
在上面的的代码中,我们假设风景画数据集存储在名为
landscape_data.npy
的文件中,并加载该数据集进行训练和生成。这样,我们可以使用真实的风景画样本来训练VAE模型并生成新的风景画样本。
- 卷积神经网络(CNN)作画示例代码
以下是一个示例代码,演示了如何使用卷积神经网络(CNN)实现风格迁移。在这个示例中,我们将使用预训练的VGG19模型来提取图像特征,并将风格图像的风格迁移到内容图像上。
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.applications import VGG19
from tensorflow.keras.preprocessing import image
from tensorflow.keras.applications.vgg19 import preprocess_input
from tensorflow.keras.models import Model
from tensorflow.keras import backend as K
from scipy.optimize import fmin_l_bfgs_b
from tensorflow.keras.layers import Input
import cv2
# 加载预训练的VGG19模型
base_model = VGG19(weights='imagenet', include_top=False)# 选择VGG19模型的某些层作为特征提取器
content_layers =['block5_conv2']
style_layers =['block1_conv1','block2_conv1','block3_conv1','block4_conv1','block5_conv1']
content_model = Model(inputs=base_model.input, outputs=base_model.get_layer(content_layers[0]).output)
style_models =[Model(inputs=base_model.input, outputs=base_model.get_layer(layer).output)for layer in style_layers]# 定义内容损失函数defcontent_loss(content, generated):return K.sum(K.square(generated - content))# 定义风格损失函数defstyle_loss(style, generated):
style = gram_matrix(style)
generated = gram_matrix(generated)
channels =3
size =224*224return K.sum(K.square(style - generated))/(4.0*(channels **2)*(size **2))defgram_matrix(x):
features = K.batch_flatten(K.permute_dimensions(x,(2,0,1)))
gram = K.dot(features, K.transpose(features))return gram
# 定义总变差损失函数(用于平滑生成的图像)deftotal_variation_loss(x):
a = K.square(x[:,:223,:223,:]- x[:,1:,:223,:])
b = K.square(x[:,:223,:223,:]- x[:,:223,1:,:])return K.sum(K.pow(a + b,1.25))# 定义总损失函数deftotal_loss(content_image, style_image, generated_image, content_weight, style_weight, total_variation_weight):
content_features = content_model(content_image)
style_features =[model(style_image)for model in style_models]
generated_features =[model(generated_image)for model in style_models]
loss = K.variable(0.0)# 添加内容损失
content_loss_value = content_loss(content_features, generated_features[0])
loss = loss + content_weight * content_loss_value
# 添加风格损失for i inrange(len(style_layers)):
style_loss_value = style_loss(style_features[i], generated_features[i])
loss = loss + style_weight * style_loss_value
# 添加总变差损失
loss = loss + total_variation_weight * total_variation_loss(generated_image)return loss
# 加载内容图像和风格图像
content_image = cv2.imread('content_image.jpg')
content_image = cv2.resize(content_image,(224,224))
content_image = np.expand_dims(content_image, axis=0)
content_image = preprocess_input(content_image)
style_image = cv2.imread('style_image.jpg')
style_image = cv2.resize(style_image,(224,224))
style_image = np.expand_dims(style_image, axis=0)
style_image = preprocess_input(style_image)# 初始化生成图像
generated_image = np.random.randint(256, size=(224,224,3)).astype('float64')
generated_image = preprocess_input(np.expand_dims(generated_image, axis=0))# 定义损失函数的梯度
loss_gradient = K.gradients(total_loss(content_image, style_image, base_model.input,1.0,1000.0,0.01), base_model.input)# 定义评估损失和梯度的函数
evaluate_loss_and_gradients = K.function([base_model.input],[total_loss(content_image, style_image, base_model.input,1.0,1000.0,0.01), loss_gradient])# 使用L-BFGS优化算法最小化损失函数defminimize_loss(generated_image, iterations):for i inrange(iterations):
loss_value, gradients_value = evaluate_loss_and_gradients([generated_image])
generated_image, min_val, info = fmin_l_bfgs_b(func=eval_loss_and_gradients, x0=generated_image.flatten(), fprime=gradients_value.flatten(), maxfun=20)
generated_image = np.clip(generated_image,-127,127)print('Iteration %d completed with loss %d'%(i, loss_value))return generated_image
# 执行风格迁移
iterations =10
final_image = minimize_loss(generated_image, iterations)# 显示生成的图像
plt.imshow(final_image[0].astype('uint8'))
plt.show()
在这个示例代码中,我们使用VGG19模型来提取图像特征,并定义内容损失、风格损失和总变差损失函数。然后,我们使用L-BFGS优化算法最小化总损失函数,以实现风格迁移。最终生成的图像将展示风格迁移后的效果。
下面是一个使用卷积神经网络(Convolutional Neural Network,CNN)模型进行图像修复的示例代码:
import cv2
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, UpSampling2D
# 读取损坏的图像
corrupted_image = cv2.imread('corrupted_image.jpg')
corrupted_image = cv2.resize(corrupted_image,(128,128))# 调整图像大小# 创建CNN模型
model = Sequential()
model.add(Conv2D(64,(3,3), activation='relu', padding='same', input_shape=(128,128,3)))
model.add(Conv2D(64,(3,3), activation='relu', padding='same'))
model.add(UpSampling2D((2,2)))
model.add(Conv2D(3,(3,3), activation='sigmoid', padding='same'))# 编译模型
model.compile(optimizer='adam', loss='mean_squared_error')# 将损坏的图像作为输入和输出来训练模型
X_train = np.array([corrupted_image])
y_train = np.array([corrupted_image])
model.fit(X_train, y_train, epochs=10, batch_size=1)# 使用训练好的模型进行图像修复
restored_image = model.predict(np.array([corrupted_image]))[0]# 显示修复后的图像
cv2.imshow('Restored Image', restored_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
在这个示例代码中,我们使用Keras库构建了一个简单的CNN模型,包括卷积层和上采样层。我们将损坏的图像作为输入和输出来训练模型,使用均方误差作为损失函数。然后,我们使用训练好的模型对损坏的图像进行修复,并显示修复后的图像。您可以根据需要调整模型的结构和训练参数以获得更好的修复效果。
- 生成式对抗网络(GAN)变体作画示例代码
以下是使用条件生成对抗网络(cGAN)实现图像风格转换的完整示例代码:
# 导入所需的库from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, Flatten, Dense, Reshape
from tensorflow.keras.optimizers import Adam
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.datasets import mnist
# 加载MNIST数据集(X_train, y_train),(_, _)= mnist.load_data()# 数据预处理
X_train = X_train /255.0
X_train = np.expand_dims(X_train, axis=-1)
y_train = np.eye(10)[y_train]# 生成器模型
generator = Sequential([
Dense(128, input_dim=110, activation='relu'),
Dense(784, activation='sigmoid'),
Reshape((28,28,1))])# 判别器模型
discriminator = Sequential([
Flatten(input_shape=(28,28,1)),
Dense(128, activation='relu'),
Dense(1, activation='sigmoid')])# 编译判别器模型
discriminator.compile(loss='binary_crossentropy', optimizer=Adam(lr=0.0002, beta_1=0.5), metrics=['accuracy'])# cGAN模型
cGAN = Sequential([generator, discriminator])
cGAN.compile(loss='binary_crossentropy', optimizer=Adam(lr=0.0002, beta_1=0.5))# 训练cGAN模型deftrain_cGAN(X_train, y_train, epochs=100, batch_size=128):for epoch inrange(epochs):for _ inrange(X_train.shape[0]// batch_size):
noise = np.random.normal(0,1,(batch_size,100))
labels = y_train[np.random.randint(0, y_train.shape[0], batch_size)]
noise_with_labels = np.concatenate([noise, labels], axis=1)
generated_images = generator.predict(noise_with_labels)
real_images = X_train[np.random.randint(0, X_train.shape[0], batch_size)]
X = np.concatenate([real_images, generated_images])
y_dis = np.zeros(2*batch_size)
y_dis[:batch_size]=1
discriminator.trainable =True
d_loss = discriminator.train_on_batch(X, y_dis)
noise = np.random.normal(0,1,(batch_size,100))
y_gen = np.ones(batch_size)
discriminator.trainable =False
g_loss = cGAN.train_on_batch([noise, labels], y_gen)print(f'Epoch: {epoch} - Discriminator Loss: {d_loss[0]}, Generator Loss: {g_loss}')# 训练cGAN模型
train_cGAN(X_train, y_train, epochs=100, batch_size=128)# 生成新的数字图像defgenerate_digit(generator, label):
noise = np.random.normal(0,1,(1,100))
label = np.eye(10)[label]
noise_with_label = np.concatenate([noise, label], axis=1)
generated_image = generator.predict(noise_with_label)
generated_image = generated_image.reshape(28,28)
plt.imshow(generated_image, cmap='gray')
plt.axis('off')
plt.show()# 生成数字“5”的新图像
generate_digit(generator,5)
这段代码实现了使用条件生成对抗网络(cGAN)在MNIST数据集上进行数字图像风格转换的任务。首先加载MNIST数据集,然后构建并训练cGAN模型,最后生成数字“5”的新图像并展示出来。您可以根据需要调整模型结构、超参数和训练时长,以获得更好的图像生成效果。
以下是使用循环一致生成对抗网络(CycleGAN)实现图像风格转换的完整示例代码:
# 导入所需的库from tensorflow.keras.layers import Input, Conv2D, BatchNormalization, Activation, LeakyReLU, Add, Conv2DTranspose
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.datasets import mnist
# 加载MNIST数据集(X_train, _),(_, _)= mnist.load_data()# 数据预处理
X_train = X_train /255.0
X_train = np.expand_dims(X_train, axis=-1)# 定义生成器模型defbuild_generator():
input_layer = Input(shape=(28,28,1))# Encoder
x = Conv2D(32,(3,3), strides=2, padding='same')(input_layer)
x = BatchNormalization()(x)
x = LeakyReLU(alpha=0.2)(x)# Decoder
x = Conv2DTranspose(1,(3,3), strides=2, padding='same')(x)
x = BatchNormalization()(x)
x = Activation('sigmoid')(x)
model = Model(inputs=input_layer, outputs=x)return model
# 定义判别器模型defbuild_discriminator():
input_layer = Input(shape=(28,28,1))
x = Conv2D(64,(3,3), strides=2, padding='same')(input_layer)
x = BatchNormalization()(x)
x = LeakyReLU(alpha=0.2)(x)
x = Conv2D(128,(3,3), strides=2, padding='same')(x)
x = BatchNormalization()(x)
x = LeakyReLU(alpha=0.2)(x)
x = Conv2D(1,(3,3), strides=2, padding='same')(x)
x = Activation('sigmoid')(x)
model = Model(inputs=input_layer, outputs=x)return model
# 构建CycleGAN模型defbuild_cyclegan(generator_XtoY, generator_YtoX, discriminator_X, discriminator_Y):
input_X = Input(shape=(28,28,1))
input_Y = Input(shape=(28,28,1))
fake_Y = generator_XtoY(input_X)
fake_X = generator_YtoX(input_Y)
reconstructed_X = generator_YtoX(fake_Y)
reconstructed_Y = generator_XtoY(fake_X)
discriminator_X.trainable =False
discriminator_Y.trainable =False
valid_X = discriminator_X(fake_X)
valid_Y = discriminator_Y(fake_Y)
model = Model(inputs=[input_X, input_Y], outputs=[valid_X, valid_Y, reconstructed_X, reconstructed_Y])return model
# 构建并编译模型
generator_XtoY = build_generator()
generator_YtoX = build_generator()
discriminator_X = build_discriminator()
discriminator_Y = build_discriminator()
cyclegan = build_cyclegan(generator_XtoY, generator_YtoX, discriminator_X, discriminator_Y)
cyclegan.compile(loss=['mse','mse','mae','mae'], optimizer=Adam(lr=0.0002, beta_1=0.5))# 训练模型deftrain_cyclegan(X_train, epochs=100, batch_size=128):for epoch inrange(epochs):for _ inrange(X_train.shape[0]// batch_size):
idx = np.random.randint(0, X_train.shape[0], batch_size)
real_X = X_train[idx]
real_Y = X_train[idx]
fake_Y = generator_XtoY.predict(real_X)
fake_X = generator_YtoX.predict(real_Y)
dX_loss_real = discriminator_X.train_on_batch(real_X, np.ones((batch_size,1)))
dY_loss_real = discriminator_Y.train_on_batch(real_Y, np.ones((batch_size,1)))
dX_loss_fake = discriminator_X.train_on_batch(fake_X, np.zeros((batch_size,1)))
dY_loss_fake = discriminator_Y.train_on_batch(fake_Y, np.zeros((batch_size,1)))
dX_loss =0.5* np.add(dX_loss_real, dX_loss_fake)
dY_loss =0.5* np.add(dY_loss_real, dY_loss_fake)
g_loss = cyclegan.train_on_batch([real_X, real_Y],[np.ones((batch_size,1)), np.ones((batch_size,1)), real_X, real_Y])print(f'Epoch: {epoch} - Discriminator X Loss: {dX_loss[0]}, Discriminator Y Loss: {dY_loss[0]}, Generator Loss: {g_loss}')# 训练CycleGAN模型
train_cyclegan(X_train, epochs=100, batch_size=128)# 生成新的数字图像defgenerate_digit(generator, image):
image = np.expand_dims(image, axis=-1)
generated_image = generator.predict(image)
generated_image = generated_image.reshape(28,28)
plt.imshow(generated_image, cmap='gray')
plt.axis('off')
plt.show()# 生成数字“5”的新图像
generate_digit(generator_XtoY, X_train[0])
这段代码实现了使用循环一致生成对抗网络(CycleGAN)在MNIST数据集上进行数字图像风格转换的任务。首先加载MNIST数据集,然后构建并训练CycleGAN模型,最后生成数字“5”的新图像并展示出来。您可以根据需要调整模型结构、超参数和训练时长,以获得更好的图像生成效果。
三、特征学习AI作画算法原理应用示例代码


- 雏形示例代码
以下是一个简单的示例代码,展示了如何使用神经网络学习绘画作品的特征,并生成具有相似特征的新作品并保存图像:
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
from tensorflow.keras.optimizers import Adam
# 构建神经网络模型
model = Sequential([
Conv2D(32,(3,3), activation='relu', input_shape=(28,28,1)),
MaxPooling2D((2,2)),
Conv2D(64,(3,3), activation='relu'),
MaxPooling2D((2,2)),
Flatten(),
Dense(128, activation='relu'),
Dense(10, activation='softmax')])# 编译模型
model.compile(optimizer=Adam(), loss='sparse_categorical_crossentropy', metrics=['accuracy'])# 加载绘画作品数据集(假设已经准备好了数据集)# 这里假设数据集包含绘画作品的图像和对应的标签# 请根据实际情况替换为您自己的数据集
X_train = np.random.rand(1000,28,28,1)
y_train = np.random.randint(0,10,1000)# 训练神经网络模型
model.fit(X_train, y_train, epochs=10, batch_size=32)# 生成并保存新的绘画作品图像defgenerate_and_save_painting(model, image, save_path):
image = np.expand_dims(image, axis=0)
prediction = model.predict(image)
generated_image = model.predict(image)
plt.imshow(generated_image.reshape(28,28), cmap='gray')
plt.axis('off')
plt.savefig(save_path)
plt.show()# 生成并保存新的绘画作品图像
generate_and_save_painting(model, X_train[0],'generated_painting.png')
在这个示例代码中,我们使用了一个简单的卷积神经网络模型来学习绘画作品的特征。在生成新的绘画作品图像时,我们直接使用模型预测的结果作为生成的图像。您可以根据需要调整模型结构、训练数据集以及生成图像的方法,以获得更好的生成效果。请注意,生成的图像将保存为PNG格式,您可以根据需要修改保存路径和文件格式。
- 调整更新示例代码
以下是一个更新后的示例代码,展示了如何根据需要调整模型结构、训练数据集以及生成图像的方法,以获得更好的生成效果:
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
from tensorflow.keras.optimizers import Adam
# 构建更复杂的神经网络模型
model = Sequential([
Conv2D(32,(3,3), activation='relu', input_shape=(28,28,1)),
MaxPooling2D((2,2)),
Conv2D(64,(3,3), activation='relu'),
MaxPooling2D((2,2)),
Conv2D(128,(3,3), activation='relu'),
MaxPooling2D((2,2)),
Flatten(),
Dense(256, activation='relu'),
Dense(10, activation='softmax')])# 编译模型
model.compile(optimizer=Adam(), loss='sparse_categorical_crossentropy', metrics=['accuracy'])# 加载更多真实的绘画作品数据集# 这里假设您有一个更大规模的数据集,包含真实的绘画作品图像和对应的标签# 请根据实际情况替换为您自己的数据集
X_train = np.random.rand(5000,28,28,1)
y_train = np.random.randint(0,10,5000)# 训练更复杂的神经网络模型
model.fit(X_train, y_train, epochs=20, batch_size=64)# 生成并保存新的绘画作品图像defgenerate_and_save_painting(model, image, save_path):
image = np.expand_dims(image, axis=0)
generated_image = model.predict(image)
plt.imshow(generated_image.reshape(28,28), cmap='gray')
plt.axis('off')
plt.savefig(save_path)
plt.show()# 生成并保存新的绘画作品图像
generate_and_save_painting(model, X_train[0],'generated_painting.png')
在这个更新后的示例代码中,我们增加了神经网络模型的复杂度,增加了更多的卷积层和全连接层,以提高模型的学习能力。我们还加载了更多真实的绘画作品数据集,以提高模型的泛化能力和生成效果。最后,我们调整了生成图像的方法,直接使用模型预测的结果作为生成的图像。您可以根据需要进一步调整模型结构、训练数据集以及生成图像的方法,以获得更好的生成效果。请注意,生成的图像将保存为PNG格式,您可以根据需要修改保存路径和文件格式。
- 进一步调整示例代码
以下是进一步调整后的示例代码,展示了如何进一步调整模型结构、训练数据集以及生成图像的方法,以获得更好的生成效果:
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
from tensorflow.keras.optimizers import Adam
# 构建更复杂的神经网络模型
model = Sequential([
Conv2D(32,(3,3), activation='relu', input_shape=(28,28,1)),
MaxPooling2D((2,2)),
Conv2D(64,(3,3), activation='relu'),
MaxPooling2D((2,2)),
Conv2D(128,(3,3), activation='relu'),
MaxPooling2D((2,2)),
Flatten(),
Dense(256, activation='relu'),
Dropout(0.5),# 添加Dropout层以减少过拟合
Dense(10, activation='softmax')])# 编译模型
model.compile(optimizer=Adam(), loss='sparse_categorical_crossentropy', metrics=['accuracy'])# 加载更多真实的绘画作品数据集# 这里假设您有一个更大规模的数据集,包含真实的绘画作品图像和对应的标签# 请根据实际情况替换为您自己的数据集
X_train = np.random.rand(5000,28,28,1)
y_train = np.random.randint(0,10,5000)# 训练更复杂的神经网络模型
model.fit(X_train, y_train, epochs=20, batch_size=64)# 生成并保存新的绘画作品图像defgenerate_and_save_painting(model, image, save_path):
image = np.expand_dims(image, axis=0)
generated_image = model.predict(image)# 根据生成图像的概率分布进行采样
generated_image = np.random.choice(range(10), p=generated_image.ravel())
plt.imshow(generated_image.reshape(28,28), cmap='gray')
plt.axis('off')
plt.savefig(save_path)
plt.show()# 生成并保存新的绘画作品图像
generate_and_save_painting(model, X_train[0],'generated_painting.png')
在这个进一步调整后的示例代码中,我们添加了Dropout层来减少过拟合,提高模型的泛化能力。在生成图像的方法中,我们根据生成图像的概率分布进行采样,以获得更多样化的生成效果。您可以根据需要继续调整模型结构、训练数据集以及生成图像的方法,以进一步提高生成效果。请注意,生成的图像将保存为PNG格式,您可以根据需要修改保存路径和文件格式。
四、风格迁移AI作画算法原理应用示例代码


- 雏形示例代码
以下是基于风格迁移算法的示例代码,展示了如何使用风格迁移技术将一个图像的风格应用到另一个图像上,生成具有特定风格的绘画作品:
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.applications import VGG19
from tensorflow.keras.preprocessing.image import load_img, img_to_array
from tensorflow.keras.applications.vgg19 import preprocess_input
from tensorflow.keras.models import Model
from tensorflow.image import resize
import tensorflow as tf
# 加载预训练的VGG19模型
base_model = VGG19(weights='imagenet', include_top=False)# 选择VGG19模型中的某些层作为风格提取层和内容提取层
style_layers =['block1_conv1','block2_conv1','block3_conv1','block4_conv1','block5_conv1']
content_layer ='block4_conv2'# 创建风格提取模型
style_outputs =[base_model.get_layer(layer).output for layer in style_layers]
style_model = Model(inputs=base_model.input, outputs=style_outputs)# 创建内容提取模型
content_output = base_model.get_layer(content_layer).output
content_model = Model(inputs=base_model.input, outputs=content_output)# 加载风格图像和内容图像
style_image = load_img('style_image.jpg', target_size=(224,224))
content_image = load_img('content_image.jpg', target_size=(224,224))# 将图像转换为数组并进行预处理
style_array = img_to_array(style_image)
content_array = img_to_array(content_image)
style_array = preprocess_input(style_array)
content_array = preprocess_input(content_array)# 计算风格图像的风格特征和内容图像的内容特征
style_features = style_model(style_array)
content_features = content_model(content_array)# 定义风格迁移损失函数defstyle_transfer_loss(style_features, content_features, generated_image):# 计算生成图像的风格特征和内容特征
generated_style_features = style_model(generated_image)
generated_content_features = content_model(generated_image)# 计算风格损失
style_loss =0for style_feature, generated_style_feature inzip(style_features, generated_style_features):
style_loss += tf.reduce_mean(tf.square(style_feature - generated_style_feature))# 计算内容损失
content_loss = tf.reduce_mean(tf.square(content_features - generated_content_features))
total_loss =0.5* style_loss +0.5* content_loss
return total_loss
# 初始化生成图像
generated_image = tf.Variable(tf.random.uniform(shape=(1,224,224,3), minval=0, maxval=255))# 使用Adam优化器最小化损失函数
optimizer = tf.optimizers.Adam(learning_rate=0.02)# 迭代优化生成图像for i inrange(1000):with tf.GradientTape()as tape:
loss = style_transfer_loss(style_features, content_features, generated_image)
gradients = tape.gradient(loss, generated_image)
optimizer.apply_gradients([(gradients, generated_image)])# 限制生成图像的像素值在0-255之间
generated_image.assign(tf.clip_by_value(generated_image,0,255))# 将生成图像保存为PNG格式
generated_image = tf.squeeze(generated_image, axis=0)
plt.imshow(generated_image.numpy().astype(np.uint8))
plt.axis('off')
plt.savefig('generated_painting.png')
plt.show()
在这个基于风格迁移算法的示例代码中,我们首先加载了预训练的VGG19模型,并选择了某些层作为风格提取层和内容提取层。然后,我们加载了风格图像和内容图像,并计算了它们的风格特征和内容特征。接着,我们定义了风格迁移损失函数,使用Adam优化器迭代优化生成图像,最终生成具有风格特征和内容特征的绘画作品。生成的图像将保存为PNG格式,您可以根据需要修改保存路径和文件格式。请注意,风格迁移算法是一种强大的AI作画技术,可以生成具有艺术风格的绘画作品。您可以根据需要调整风格迁移算法的参数和超参数,以获得更好的生成效果。
- 调整更新示例代码
# 定义风格迁移损失函数,并调整参数和超参数defstyle_transfer_loss(style_features, content_features, generated_image, style_weight=1e-2, content_weight=1):# 计算生成图像的风格特征和内容特征
generated_style_features = style_model(generated_image)
generated_content_features = content_model(generated_image)# 计算风格损失
style_loss =0for style_feature, generated_style_feature inzip(style_features, generated_style_features):
style_loss += tf.reduce_mean(tf.square(style_feature - generated_style_feature))
style_loss *= style_weight
# 计算内容损失
content_loss = tf.reduce_mean(tf.square(content_features - generated_content_features))
content_loss *= content_weight
total_loss = style_loss + content_loss
return total_loss
# 初始化生成图像
generated_image = tf.Variable(tf.random.uniform(shape=(1,224,224,3), minval=0, maxval=255))# 使用Adam优化器最小化损失函数,并调整学习率和迭代次数
optimizer = tf.optimizers.Adam(learning_rate=0.01)# 迭代优化生成图像,并调整迭代次数for i inrange(2000):with tf.GradientTape()as tape:
loss = style_transfer_loss(style_features, content_features, generated_image, style_weight=1e-2, content_weight=1)
gradients = tape.gradient(loss, generated_image)
optimizer.apply_gradients([(gradients, generated_image)])# 限制生成图像的像素值在0-255之间
generated_image.assign(tf.clip_by_value(generated_image,0,255))# 将生成图像保存为PNG格式
generated_image = tf.squeeze(generated_image, axis=0)
plt.imshow(generated_image.numpy().astype(np.uint8))
plt.axis('off')
plt.savefig('generated_painting.png')
plt.show()
在这个调整了参数和超参数的示例代码中,我们修改了风格迁移损失函数的风格权重和内容权重,并调整了学习率和迭代次数。通过调整这些参数和超参数,您可以探索不同的生成效果,并根据需要进行调整以获得更好的结果。您可以根据实际情况进一步调整参数和超参数,以满足您的需求和期望。
- 进一步调整示例代码
# 定义风格迁移损失函数,并进一步调整参数和超参数defstyle_transfer_loss(style_features, content_features, generated_image, style_weight=1e-2, content_weight=1):# 计算生成图像的风格特征和内容特征
generated_style_features = style_model(generated_image)
generated_content_features = content_model(generated_image)# 计算风格损失
style_loss =0for style_feature, generated_style_feature inzip(style_features, generated_style_features):
style_loss += tf.reduce_mean(tf.square(style_feature - generated_style_feature))
style_loss *= style_weight
# 计算内容损失
content_loss = tf.reduce_mean(tf.square(content_features - generated_content_features))
content_loss *= content_weight
total_loss = style_loss + content_loss
return total_loss
# 初始化生成图像
generated_image = tf.Variable(tf.random.uniform(shape=(1,224,224,3), minval=0, maxval=255))# 使用Adam优化器最小化损失函数,并进一步调整学习率和迭代次数
optimizer = tf.optimizers.Adam(learning_rate=0.005)# 迭代优化生成图像,并进一步调整迭代次数for i inrange(3000):with tf.GradientTape()as tape:
loss = style_transfer_loss(style_features, content_features, generated_image, style_weight=1e-3, content_weight=0.5)
gradients = tape.gradient(loss, generated_image)
optimizer.apply_gradients([(gradients, generated_image)])# 限制生成图像的像素值在0-255之间
generated_image.assign(tf.clip_by_value(generated_image,0,255))# 将生成图像保存为PNG格式
generated_image = tf.squeeze(generated_image, axis=0)
plt.imshow(generated_image.numpy().astype(np.uint8))
plt.axis('off')
plt.savefig('generated_painting.png')
plt.show()
在这个进一步调整了参数和超参数的示例代码中,我们进一步修改了风格迁移损失函数的风格权重和内容权重,并进一步调整了学习率和迭代次数。通过不断调整参数和超参数,您可以探索更多的生成效果,并根据实际情况进一步调整以满足您的需求和期望。请根据您的实际情况和预期效果,灵活调整参数和超参数,以获得最佳的生成效果。
五、损失函数AI作画算法原理应用示例代码


- 雏形示例代码
# 定义损失函数AI作画算法defloss_function(real_images, generated_images):# 计算生成作品与真实作品之间的差异
loss = tf.reduce_mean(tf.square(real_images - generated_images))return loss
# 初始化神经网络模型
model = MyPaintingModel()# 使用Adam优化器最小化损失函数
optimizer = tf.optimizers.Adam(learning_rate=0.001)# 训练过程for epoch inrange(num_epochs):for batch_images in dataset:with tf.GradientTape()as tape:
generated_images = model(batch_images)
loss = loss_function(batch_images, generated_images)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))# 输出每个epoch的损失值print(f'Epoch {epoch+1}, Loss: {loss.numpy()}')# 保存训练好的模型
model.save('my_painting_model')
在这个示例代码中,我们定义了一个简单的损失函数来评估生成作品与真实作品之间的差异。然后,我们使用Adam优化器来最小化损失函数,优化神经网络的参数。在训练过程中,我们迭代遍历数据集中的每个批次图像,并根据损失函数计算梯度并更新模型参数。最后,我们保存训练好的模型以备后续使用。
您可以根据实际情况和需求进一步优化损失函数和神经网络模型,以获得更好的生成作品质量和逼真度。不断调整参数和超参数,并进行实验和测试,以找到最佳的训练策略和模型配置。
- 进一步优化示例代码
# 定义自定义损失函数来评估生成作品与真实作品之间的差异defcustom_loss_function(real_images, generated_images):# 计算生成作品与真实作品之间的差异
pixel_loss = tf.reduce_mean(tf.square(real_images - generated_images))# 添加额外的内容损失,例如特征匹配损失
content_loss = calculate_content_loss(real_images, generated_images)# 组合像素损失和内容损失
total_loss = pixel_loss +0.1* content_loss # 调整权重以平衡两种损失return total_loss
# 初始化改进的神经网络模型
improved_model = ImprovedPaintingModel()# 使用Adam优化器最小化自定义损失函数
optimizer = tf.optimizers.Adam(learning_rate=0.001)# 训练过程for epoch inrange(num_epochs):for batch_images in dataset:with tf.GradientTape()as tape:
generated_images = improved_model(batch_images)
loss = custom_loss_function(batch_images, generated_images)
gradients = tape.gradient(loss, improved_model.trainable_variables)
optimizer.apply_gradients(zip(gradients, improved_model.trainable_variables))# 输出每个epoch的损失值print(f'Epoch {epoch+1}, Loss: {loss.numpy()}')# 保存训练好的改进模型
improved_model.save('improved_painting_model')
在这个示例代码中,我们进一步优化了损失函数,添加了额外的内容损失(例如特征匹配损失)来提高生成作品的质量和逼真度。我们还使用了一个改进的神经网络模型来训练生成作品。在训练过程中,我们使用自定义的损失函数来评估生成作品与真实作品之间的差异,并根据梯度更新模型参数。
通过不断调整参数和超参数,以及尝试不同的损失函数和模型架构,您可以进一步优化生成作品的质量和逼真度。进行实验和测试,并根据实际情况和需求找到最佳的训练策略和模型配置。
- 再优化示例代码
# 定义一个更复杂的神经网络模型架构classAdvancedPaintingModel(tf.keras.Model):def__init__(self):super(AdvancedPaintingModel, self).__init__()
self.conv1 = tf.keras.layers.Conv2D(64,(3,3), activation='relu', padding='same')
self.conv2 = tf.keras.layers.Conv2D(64,(3,3), activation='relu', padding='same')
self.conv3 = tf.keras.layers.Conv2D(3,(3,3), activation='sigmoid', padding='same')defcall(self, inputs):
x = self.conv1(inputs)
x = self.conv2(x)
x = self.conv3(x)return x
# 初始化更复杂的神经网络模型
advanced_model = AdvancedPaintingModel()# 定义新的损失函数来进一步优化生成作品的质量defadvanced_loss_function(real_images, generated_images):# 添加对抗损失,例如生成对抗网络(GAN)中的判别器损失
adversarial_loss = calculate_adversarial_loss(real_images, generated_images)# 组合像素损失、内容损失和对抗损失
total_loss = pixel_loss +0.1* content_loss +0.01* adversarial_loss # 调整权重以平衡三种损失return total_loss
# 使用不同的优化器和学习率来训练模型
optimizer = tf.optimizers.Adam(learning_rate=0.0001)# 训练过程for epoch inrange(num_epochs):for batch_images in dataset:with tf.GradientTape()as tape:
generated_images = advanced_model(batch_images)
loss = advanced_loss_function(batch_images, generated_images)
gradients = tape.gradient(loss, advanced_model.trainable_variables)
optimizer.apply_gradients(zip(gradients, advanced_model.trainable_variables))# 输出每个epoch的损失值print(f'Epoch {epoch+1}, Loss: {loss.numpy()}')# 保存训练好的高级模型
advanced_model.save('advanced_painting_model')
在这个示例代码中,我们定义了一个更复杂的神经网络模型架构,并添加了对抗损失来进一步优化生成作品的质量。我们使用了不同的优化器和学习率来训练模型,并在训练过程中结合像素损失、内容损失和对抗损失来计算总损失。通过调整权重以平衡三种损失,我们可以找到最佳的训练策略和模型配置,以提高生成作品的逼真度和质量。
请根据实际情况和需求进行实验和测试,不断尝试不同的参数、超参数、损失函数和模型架构,以找到最佳的训练策略和模型配置。
六、条件生成AI作画算法原理应用示例代码


- 雏形示例代码
# 定义一个带条件生成的神经网络模型架构classConditionalPaintingModel(tf.keras.Model):def__init__(self):super(ConditionalPaintingModel, self).__init__()
self.conv1 = tf.keras.layers.Conv2D(64,(3,3), activation='relu', padding='same')
self.conv2 = tf.keras.layers.Conv2D(64,(3,3), activation='relu', padding='same')
self.conv3 = tf.keras.layers.Conv2D(3,(3,3), activation='sigmoid', padding='same')defcall(self, inputs, conditions):
x = tf.concat([inputs, conditions], axis=-1)# 将输入和条件连接起来
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)return x
# 初始化带条件生成的神经网络模型
conditional_model = ConditionalPaintingModel()# 定义带条件的损失函数defconditional_loss_function(real_images, generated_images, conditions):# 添加对抗损失和条件损失
adversarial_loss = calculate_adversarial_loss(real_images, generated_images)
condition_loss = calculate_condition_loss(generated_images, conditions)# 组合像素损失、内容损失、对抗损失和条件损失
total_loss = pixel_loss +0.1* content_loss +0.01* adversarial_loss +0.1* condition_loss # 调整权重return total_loss
# 使用不同的优化器和学习率来训练带条件生成的模型
optimizer = tf.optimizers.Adam(learning_rate=0.0001)# 训练过程for epoch inrange(num_epochs):for batch_images, batch_conditions in dataset:with tf.GradientTape()as tape:
generated_images = conditional_model(batch_images, batch_conditions)
loss = conditional_loss_function(batch_images, generated_images, batch_conditions)
gradients = tape.gradient(loss, conditional_model.trainable_variables)
optimizer.apply_gradients(zip(gradients, conditional_model.trainable_variables))# 输出每个epoch的损失值print(f'Epoch {epoch+1}, Loss: {loss.numpy()}')# 保存训练好的带条件生成模型
conditional_model.save('conditional_painting_model')
在这个示例代码中,我们定义了一个带条件生成的神经网络模型架构,并添加了条件损失来根据输入的条件或约束生成符合特定要求的绘画作品。我们在损失函数中组合了像素损失、内容损失、对抗损失和条件损失,通过调整权重来平衡这些损失,以找到最佳的训练策略和模型配置。
请根据实际情况和需求进行实验和测试,不断尝试不同的参数、超参数、损失函数和模型架构,以优化带条件生成的作画算法,生成符合特定要求的绘画作品。
- 优化示例代码
import tensorflow as tf
from tensorflow.keras.layers import Input, Conv2D, Concatenate
from tensorflow.keras.models import Model
# 定义带条件生成的神经网络模型架构defcreate_conditional_painting_model(input_shape, num_conditions):# 输入层
input_image = Input(shape=input_shape)
input_condition = Input(shape=(num_conditions,))# 图像处理网络
x = Conv2D(64,(3,3), activation='relu', padding='same')(input_image)
x = Conv2D(64,(3,3), activation='relu', padding='same')(x)# 将条件信息与图像特征连接
x = Concatenate()([x, input_condition])# 生成图像
output_image = Conv2D(3,(3,3), activation='sigmoid', padding='same')(x)# 定义模型
model = Model(inputs=[input_image, input_condition], outputs=output_image)return model
# 初始化带条件生成的神经网络模型
conditional_model = create_conditional_painting_model(input_shape=(256,256,3), num_conditions=10)# 编译模型
conditional_model.compile(optimizer='adam', loss='mse')# 训练模型
conditional_model.fit([input_images, input_conditions], output_images, epochs=10, batch_size=32)# 使用模型生成带条件的绘画作品
generated_images = conditional_model.predict([input_images, input_conditions])# 保存模型
conditional_model.save('conditional_painting_model.h5')
在这个示例代码中,我们定义了一个带条件生成的神经网络模型架构,其中输入包括图像和条件信息。我们使用Conv2D层来处理图像特征,然后将条件信息与图像特征连接起来,最后通过Conv2D层生成图像。我们使用均方误差损失函数(MSE)来衡量生成图像与真实图像之间的差异,并使用Adam优化器进行模型训练。
您可以根据实际情况和需求调整模型架构、损失函数、优化器、训练参数等,以优化带条件生成的作画算法,生成符合特定要求的绘画作品。
- 再优化示例代码
import tensorflow as tf
from tensorflow.keras.layers import Input, Conv2D, Concatenate, Flatten, Dense
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.losses import MeanSquaredError
# 定义带条件生成的神经网络模型架构defcreate_conditional_painting_model(input_shape, num_conditions):# 输入层
input_image = Input(shape=input_shape)
input_condition = Input(shape=(num_conditions,))# 图像处理网络
x = Conv2D(64,(3,3), activation='relu', padding='same')(input_image)
x = Conv2D(64,(3,3), activation='relu', padding='same')(x)# 将条件信息与图像特征连接
x = Concatenate()([x, input_condition])# 全连接层
x = Flatten()(x)
x = Dense(256, activation='relu')(x)# 生成图像
output_image = Dense(input_shape[2], activation='sigmoid')(x)# 定义模型
model = Model(inputs=[input_image, input_condition], outputs=output_image)return model
# 初始化带条件生成的神经网络模型
conditional_model = create_conditional_painting_model(input_shape=(128,128,3), num_conditions=5)# 编译模型
optimizer = Adam(learning_rate=0.001)
loss_function = MeanSquaredError()
conditional_model.compile(optimizer=optimizer, loss=loss_function)# 训练模型
conditional_model.fit([input_images, input_conditions], output_images, epochs=20, batch_size=64)# 使用模型生成带条件的绘画作品
generated_images = conditional_model.predict([input_images, input_conditions])# 保存模型
conditional_model.save('conditional_painting_model_updated.h5')
在这个示例代码中,我们调整了模型架构,添加了全连接层来更好地处理图像特征和条件信息。我们使用了Adam优化器和均方误差损失函数进行模型编译,并增加了训练周期为20和批量大小为64。您可以根据实际情况和需求进一步调整参数和模型架构,以优化带条件生成的作画算法,生成符合特定要求的绘画作品。
七、创新和创意的AI作画算法原理应用示例代码

- 雏形示例代码
import tensorflow as tf
from tensorflow.keras.layers import Input, Conv2D, Concatenate, Flatten, Dense, Reshape
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.losses import MeanSquaredError
# 定义创新和创意AI作画算法模型架构defcreate_innovative_painting_model(input_shape):# 输入层
input_image = Input(shape=input_shape)# 图像处理网络
x = Conv2D(64,(3,3), activation='relu', padding='same')(input_image)
x = Conv2D(64,(3,3), activation='relu', padding='same')(x)# 创意生成网络
x = Flatten()(x)
x = Dense(256, activation='relu')(x)
x = Dense(128, activation='relu')(x)
x = Dense(64, activation='relu')(x)
x = Dense(256, activation='relu')(x)
x = Reshape((8,8,4))(x)# 生成图像
output_image = Conv2D(3,(3,3), activation='sigmoid', padding='same')(x)# 定义模型
model = Model(inputs=input_image, outputs=output_image)return model
# 初始化创新和创意AI作画算法模型
innovative_model = create_innovative_painting_model(input_shape=(128,128,3))# 编译模型
optimizer = Adam(learning_rate=0.001)
loss_function = MeanSquaredError()
innovative_model.compile(optimizer=optimizer, loss=loss_function)# 训练模型
innovative_model.fit(input_images, output_images, epochs=30, batch_size=64)# 使用模型生成创新和创意的绘画作品
generated_images = innovative_model.predict(input_images)# 保存模型
innovative_model.save('innovative_painting_model.h5')
在这个示例代码中,我们定义了一个创新和创意的AI作画算法模型架构,其中包括了创意生成网络来产生全新的、具有创意和创新性的作品。我们使用了多层全连接层和Reshape层来处理图像特征,生成具有新颖性的绘画作品。您可以根据实际情况和需求进一步调整参数和模型架构,以实现更具创新和创意的绘画作品生成。
- 进一步调整示例代码
import tensorflow as tf
from tensorflow.keras.layers import Input, Conv2D, Concatenate, Flatten, Dense, Reshape
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.losses import MeanSquaredError
# 定义创新和创意AI作画算法模型架构defcreate_innovative_painting_model(input_shape):# 输入层
input_image = Input(shape=input_shape)# 图像处理网络
x = Conv2D(64,(3,3), activation='relu', padding='same')(input_image)
x = Conv2D(64,(3,3), activation='relu', padding='same')(x)# 创意生成网络
x = Flatten()(x)
x = Dense(512, activation='relu')(x)
x = Dense(256, activation='relu')(x)
x = Dense(128, activation='relu')(x)
x = Dense(256, activation='relu')(x)
x = Reshape((8,8,4))(x)# 生成图像
output_image = Conv2D(3,(3,3), activation='sigmoid', padding='same')(x)# 定义模型
model = Model(inputs=input_image, outputs=output_image)return model
# 初始化创新和创意AI作画算法模型
innovative_model = create_innovative_painting_model(input_shape=(128,128,3))# 编译模型
optimizer = Adam(learning_rate=0.0005)
loss_function = MeanSquaredError()
innovative_model.compile(optimizer=optimizer, loss=loss_function)# 训练模型
innovative_model.fit(input_images, output_images, epochs=50, batch_size=128)# 使用模型生成创新和创意的绘画作品
generated_images = innovative_model.predict(input_images)# 保存模型
innovative_model.save('innovative_painting_model_updated.h5')
在这个示例代码中,我们进一步调整了创新和创意AI作画算法模型的参数和架构。我们增加了网络层的节点数,加深了网络结构,增加了训练周期和批量大小,降低了学习率,以提高模型的学习能力和生成创新作品的质量。您可以根据实际情况和需求进一步调整参数和架构,以实现更具创新和创意的绘画作品生成。
- 再进一步调整示例代码
import tensorflow as tf
from tensorflow.keras.layers import Input, Conv2D, Conv2DTranspose, Concatenate, Flatten, Dense, Reshape
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.losses import MeanSquaredError
# 定义创新和创意AI作画算法模型架构defcreate_innovative_painting_model(input_shape):# 输入层
input_image = Input(shape=input_shape)# 图像处理网络
x = Conv2D(64,(3,3), activation='relu', padding='same')(input_image)
x = Conv2D(64,(3,3), activation='relu', padding='same')(x)# 创意生成网络
x = Conv2DTranspose(64,(3,3), activation='relu', padding='same')(x)
x = Conv2DTranspose(64,(3,3), activation='relu', padding='same')(x)
x = Conv2DTranspose(3,(3,3), activation='sigmoid', padding='same')(x)# 定义模型
model = Model(inputs=input_image, outputs=x)return model
# 初始化创新和创意AI作画算法模型
innovative_model = create_innovative_painting_model(input_shape=(128,128,3))# 编译模型
optimizer = Adam(learning_rate=0.0001)
loss_function = MeanSquaredError()
innovative_model.compile(optimizer=optimizer, loss=loss_function)# 训练模型
innovative_model.fit(input_images, output_images, epochs=50, batch_size=128)# 使用模型生成创新和创意的绘画作品
generated_images = innovative_model.predict(input_images)# 保存模型
innovative_model.save('innovative_painting_model_updated.h5')
在这个示例代码中,我们进一步调整了创新和创意AI作画算法模型的架构,使用了Conv2DTranspose层来进行反卷积操作,增加了网络层的深度和复杂度,以实现更具创新和创意的绘画作品生成。您可以根据实际情况和需求进一步调整参数和架构,以提高模型的性能和生成作品的质量。祝您成功实验和测试!
八、知识点归纳

AI作画算法是利用人工智能技术来生成绘画作品的一种应用。以下是AI作画算法的主要知识点归纳:
- 卷积神经网络(CNN): AI作画算法通常基于卷积神经网络,通过卷积层、池化层和全连接层等组件来提取图像特征和学习模式。
- 生成对抗网络(GAN): GAN是一种用于生成模型的框架,包括生成器和判别器两部分,通过对抗训练来生成逼真的图像作品。
- 风格迁移: 风格迁移是一种将图像的内容和风格分离的技术,可以将一幅图像的内容应用到另一幅图像的风格上,从而生成新的艺术作品。
- 自动编码器: 自动编码器是一种无监督学习算法,用于学习数据的有效表示,可以用于图像重建和生成。
- 图像处理技术: AI作画算法还涉及图像处理技术,如图像增强、去噪、风格转换等,用于提升图像质量和创意性。
- 损失函数: 在训练AI作画算法模型时,需要定义合适的损失函数来衡量生成图像与目标图像之间的差异,常用的损失函数包括均方误差、对抗损失等。
- 数据集准备: 为了训练AI作画算法模型,需要准备包含大量图像数据的数据集,以便模型学习和生成多样化的艺术作品。

综上所述,AI作画算法涉及深度学习、图像处理、生成模型等多个领域的知识,通过结合这些技术和方法,可以实现生成具有创新和创意的绘画作品。
版权归原作者 传奇开心果编程 所有, 如有侵权,请联系我们删除。