
IDS的简介、分类与发展
1.Intrusion Detection System
入侵检测技术是软件和硬件的结合,用于监控网络或系统以识别恶意活动并立即发出警报,从而保护系统资源的完整性、私密性和可用性。入侵检测技术与其 他安全技术不同,它是一种积极主动的防御技术,可以有效防止未知攻击。可以如此形容入侵检测系统——假如防火墙为一幢大厦的门锁,那么入侵检测系统 就是这幢大厦里的监控系统,一旦小偷进入了大厦,或内部人员有越界的行为,监控系统能够立即发出警报。 因此,入侵检测系统应当“放置”在所关注流量数据必经 的链路上。入侵检测系统的架构如图1所示事件产生器是从整个网络中获取事件,并将获取的事件提供给系统的其他部分;事件分析器是分析获取的事件,若发现异常,则通知响应单元;响应单元是对分析的结果做出相应的反应;事件数据库中存放过程数据。
 2.IDS的分类
2.IDS的分类
入侵检测系统按照数据源、检测方法、工作方式和体系结构进行分类。其具体分类如下图所示:

3.发展应用趋势
机器学习(深度学习、强化学习、联邦学习)等技术的使用、分布式入侵检测(DIDS)
4.IDS的局限性
- ·对用户知识要求较高,配置、操作和管理使用较为复杂
- ·网络发展迅速,对入侵检测系统的处理性能要求越来越高,现有技术难以满足实际需要
- ·高虚警率,用户处理的负担重
- ·由于警告信息记录的不完整,许多警告信息可能无法与入侵行为相关联,难以得到有用的结果
- ·在应对自身的攻击时,对其他数据的检测也可能会被抑制或受到影响
5.IDS与WAF的区别
IDS(入侵检测系统)是IPS的前身,本质上是被动的。该设备未与流量串联插入,而是并行(带外放置)。通过交换机的流量也同时发送到IDS进行检查。如果在网络流量中检测到安全异常,则IDS只会向管理员发出警报,但无法阻止流量。与IPS相似,IDS设备还主要使用已知安全攻击和漏洞利用的特征来检测入侵企图。为了将流量发送到IDS,交换设备必须配置一个SPAN端口,以便复制流量并将其发送到IDS节点。尽管IDS在网络中是被动的(即它不能主动阻止流量),但是有些模型可以与防火墙配合使用以阻止安全攻击。例如,如果IDS检测到攻击,则IDS可以向防火墙发送命令以阻止特定的数据包
WAF(Web应用程序防火墙)专注于保护网站(或通常的Web应用程序)。它在应用程序层工作以检查HTTP Web流量,以检测针对网站的恶意攻击。例如,WAF将检测SQL注入攻击,跨站点脚本,Javascript攻击,RFI / LFI攻击等。由于当今大多数网站都使用SSL(HTTP),因此WAF还可以通过终止SSL会话并在WAF本身上检查连接内部的流量来提供SSL加速和SSL检查。如上图所示(带有WAF的防火墙),它被放置在网站的前面(通常)在防火墙的DMZ区域中。有了WAF,管理员可以灵活地限制对网站特定部分的Web访问,提供强身份验证,检查或限制文件上传到网站等。
开源IDS—Snort的简介
SNORT是一个强大的轻量级的网络入侵检测系统,它具有实时数据流量分析和日志IP网络数据包的能力,能够进行协议分析,对内容搜索或者匹配。它是一个基于特征检测的入侵检测系统。
官网链接:Snort - Network Intrusion Detection & Prevention System
snort有三种工作模式:嗅探器、数据包记录器、网络入侵检测系统。嗅探器模式仅仅是从网络上读取数据包并作为连续不断的流显示在终端上。数据包记录器模式把数据包记录到硬盘上。网路入侵检测模式是最复杂的,而且是可配置的。我们可以让snort分析网络数据流以匹配用户定义的一些规则,并根据检测结果采取一定的动作。
一些开源的IDS:

Snort的安装与部署
虚拟机的使用
使用VMware创建linux虚拟机
预装daq所需程序(snort的组件)
输入命令
yum install -y gcc flex bison zlib libpcap pcre libdnet tcpdump
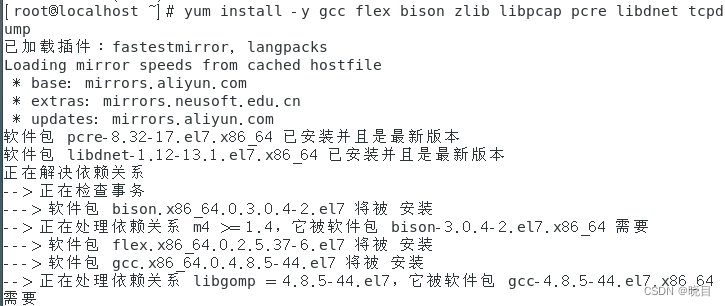
输入命令下载依赖工具
yum install -y zlib-devel libpcap-devel pcre-devel libdnet-devel openssl-devel libnghttp2-devel luajit-devel

输入命令下载daq包 - wget https://www.snort.org/downloads/snort/daq-2.0.7.tar.gz
(注意这里软件包下载的路径)

输入命令解压tar包 tar -xzvf daq-2.0.7.tar.gz
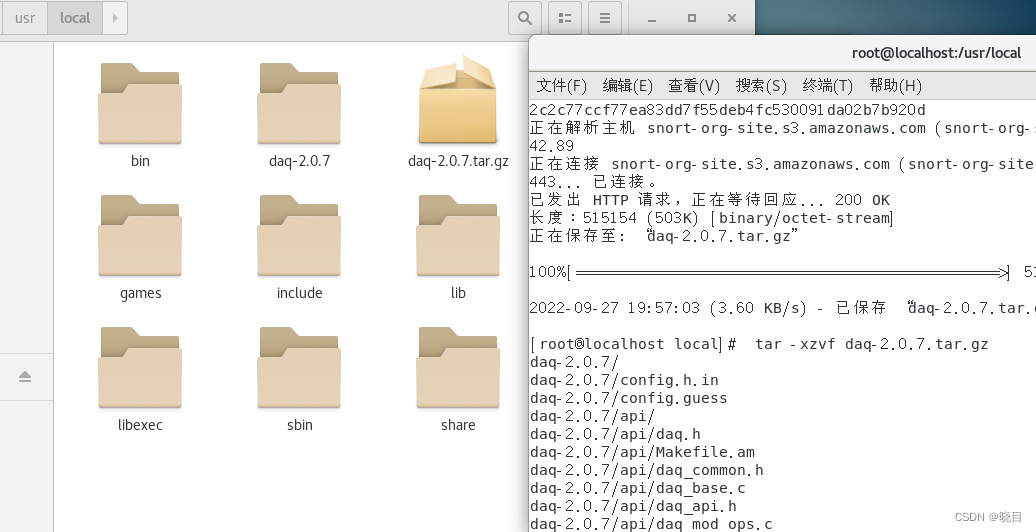
输入命令进入文件夹-cd /daq-2.0.7
依次输入命令编译安装-./configure --disable-open-appid
make
make install



 安装完成
安装完成
安装Snort
在官网下载Snort-2.9.9.0,移动到/usr/local目录下(百度网盘我的资源>安装包>snort-2.9.9.0.tar.gz)
输入命令 tar -xzvf snort-2.9.9.0.tar.gz

输入命令进入目录 -cd snort-2.9.9.0/
依次输入命令编译安装snort -./configure
make
make install



安装成功
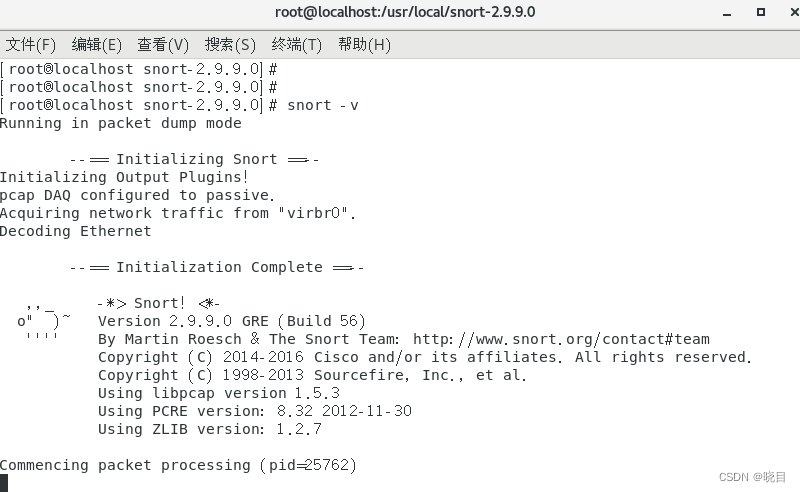
此时输入命令 -snort -v出现以下内容即安装成功(一只小猪)
Snort 的配置
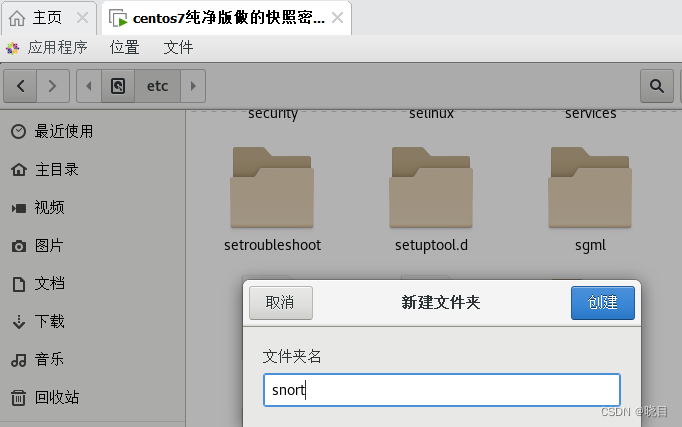
创建snort配置(及规则)目录,创建运行需要目录
mkdir -p /etc/snort/rules
在/etc下创建一个snort文件夹

mkdir /usr/local/lib/snort_dynamicrules

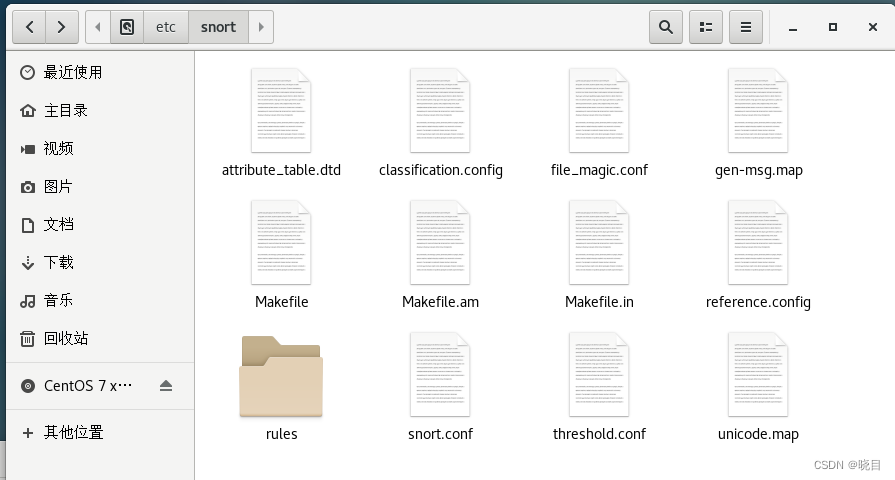
首先将解压出来的usr/local/snort-2.9.9.0/etc下的默认配置文件复制到etc/snort配置目录下,可通过命令行或直接复制粘贴的形式进行。
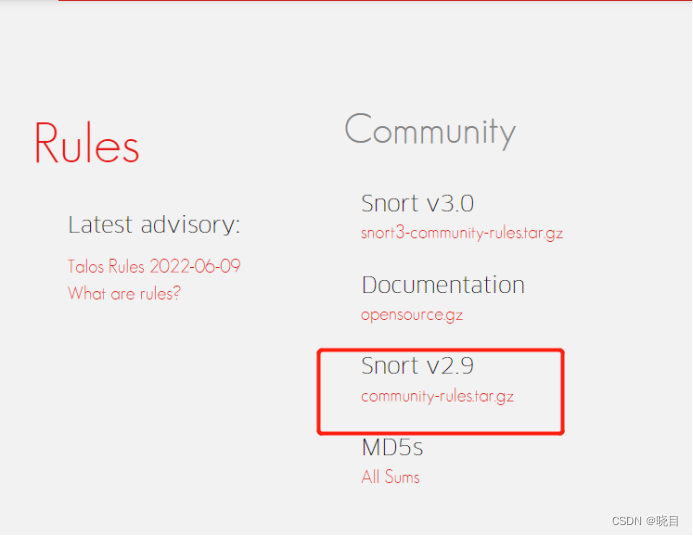
下载社区规则并解压到规则目录
https://www.snort.org/downloads
在火狐下载文件中
把文件移动到usr/local
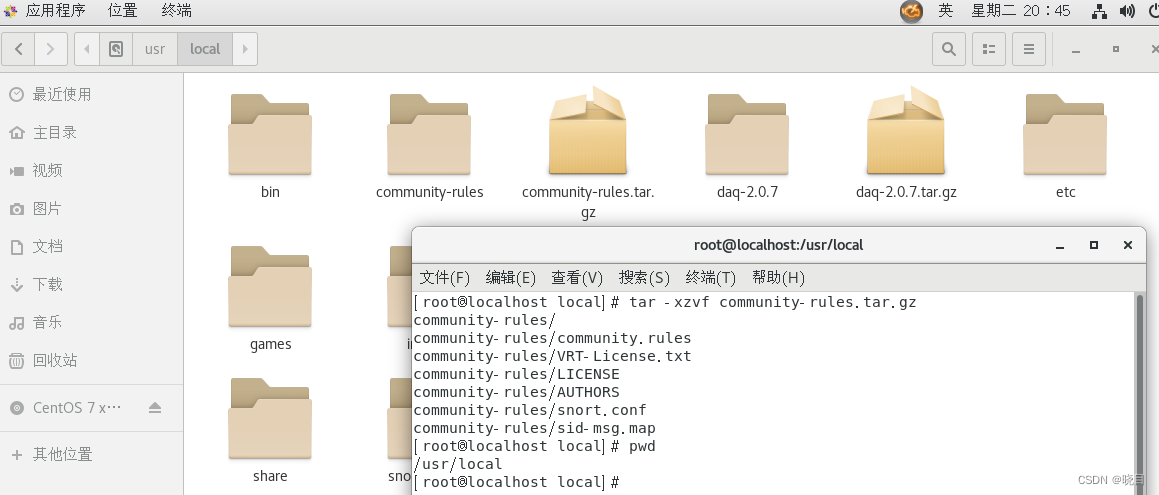
 把文件解压 tar -xzvf community-rules.tar.gz
把文件解压 tar -xzvf community-rules.tar.gz
把解压出来的文件放到/etc/snort/rules文件夹下
/usr/local/community-rules路径下
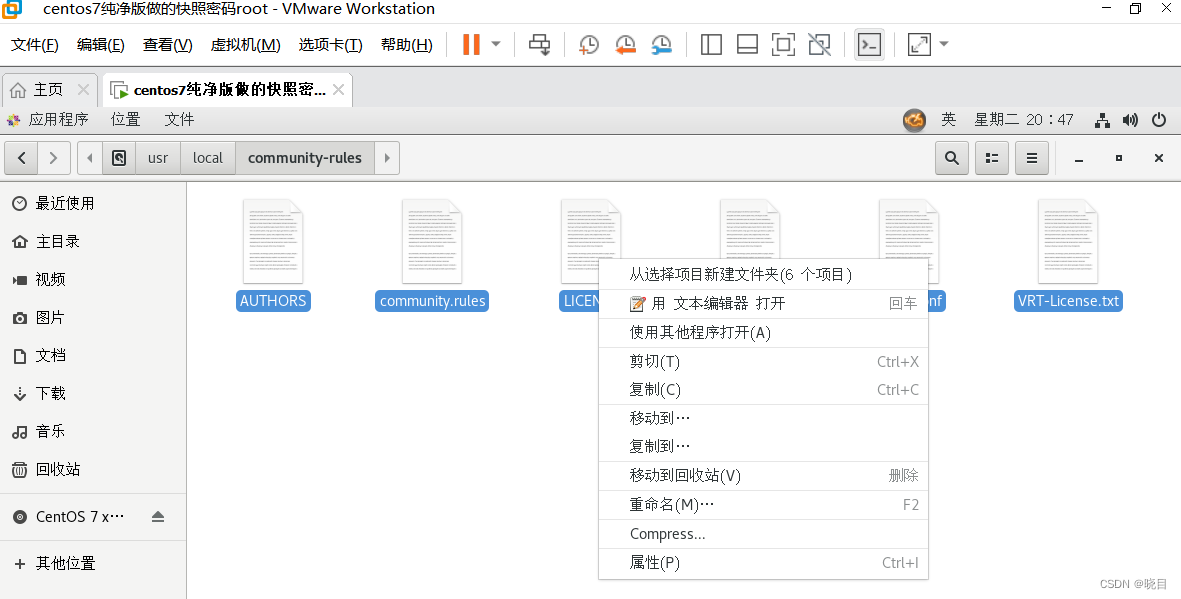
/etc/snort/rules文件夹
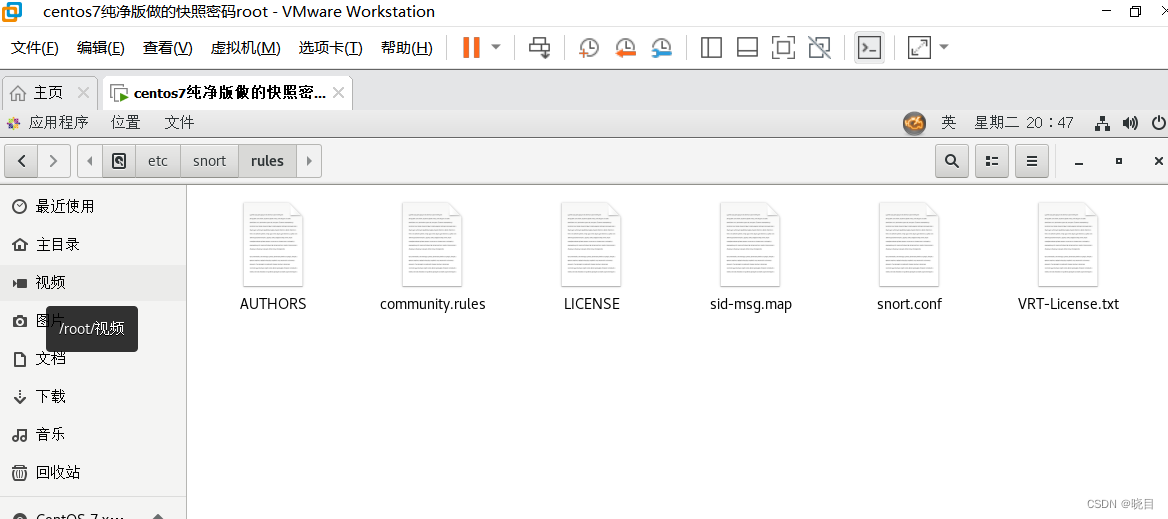
打开终端依次输入命令启用社区规则文件
echo '' >> /etc/snort/snort.conf
echo '# enable community rule' >> /etc/snort/snort.conf

echo 'include $RULE_PATH/community-rules/community.rules' >> /etc/snort/snort.conf
sed -i 's/var RULE_PATH ../rules/var RULE_PATH ./rules/' /etc/snort/snort.conf

sed -i 's/var WHITE_LIST_PATH ../rules/var WHITE_LIST_PATH ./rules/' /etc/snort/snort.conf
sed -i 's/var BLACK_LIST_PATH ../rules/var BLACK_LIST_PATH ./rules/' /etc/snort/snort.conf
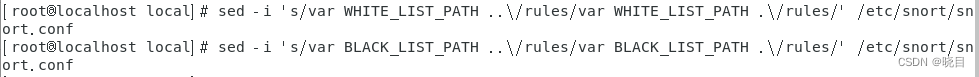
创建默认使用的白名单文件
touch /etc/snort/rules/white_list.rules

创建默认的黑名单文件
touch /etc/snort/rules/black_list.rules
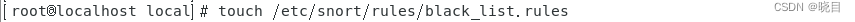
创建默认自己设置的规则文件(之后自己创建的规则都写到这个规则集里)
touch /etc/snort/rules/local.rules

注释掉所有默认要加载的规则文件
sed -i 's/include $RULE_PATH/#include $RULE_PATH/' /etc/snort/snort.conf

测试配置文件是否有误,用命令snort -T -c /etc/snort/snort.conf

这个界面表示没有问题(如果有问题检查自己写的规则rules)
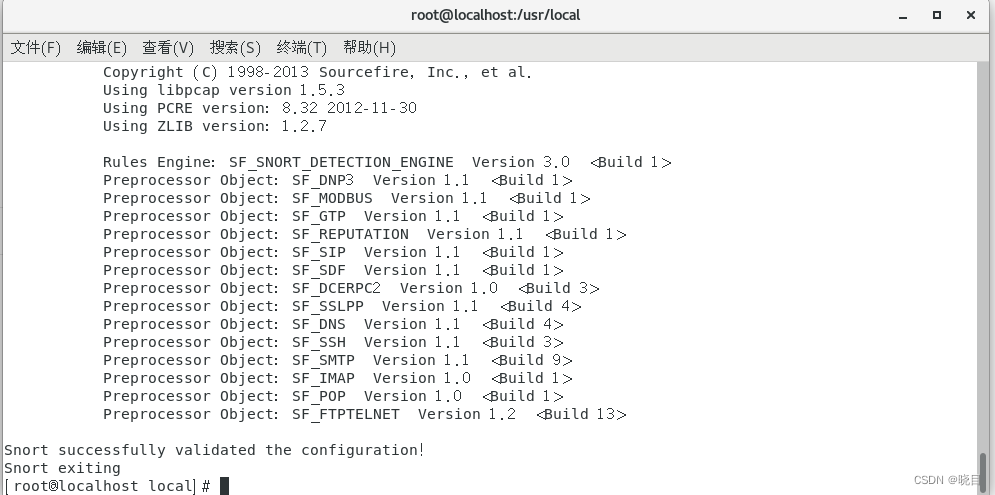
配置完成
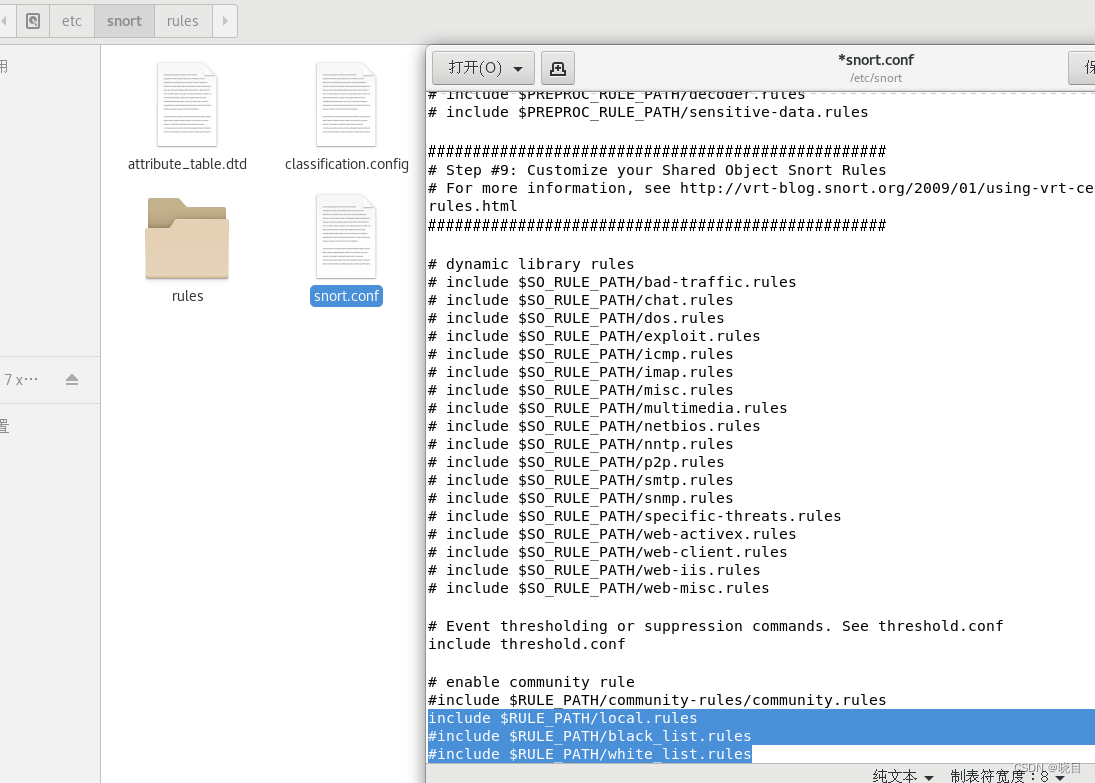
在/etc/snort/snort.conf文件中加入新建的规则集文件路径
include $RULE_PATH/local.rules
#include $RULE_PATH/black_list.rules
#include $RULE_PATH/white_list.rules
安装xampp
输入命令下载xampp-wget https://www.apachefriends.org/xampp-files/8.1.6/xampp-linux-x64-8.1.6-0-installer.run --no-check-certificate
输入命令 chmod 777 xampp-linux-x64-8.1.6-0-installer.run
输入命令安装 ./xampp-linux-x64-8.1.6-0-installer.run
官网下载太慢了所以我直接找的安装包下载的(百度网盘>我的资源>安装包>xampp>xampp-linux-x64-8.1.6-0-installer.run),我把安装包放在/usr/local/目录下
一直点击next
打开xampp,默认安装路径在/opt/lampp/,运行manager-linux-x64.run,下次启动xampp可以找到下载路径然后双击
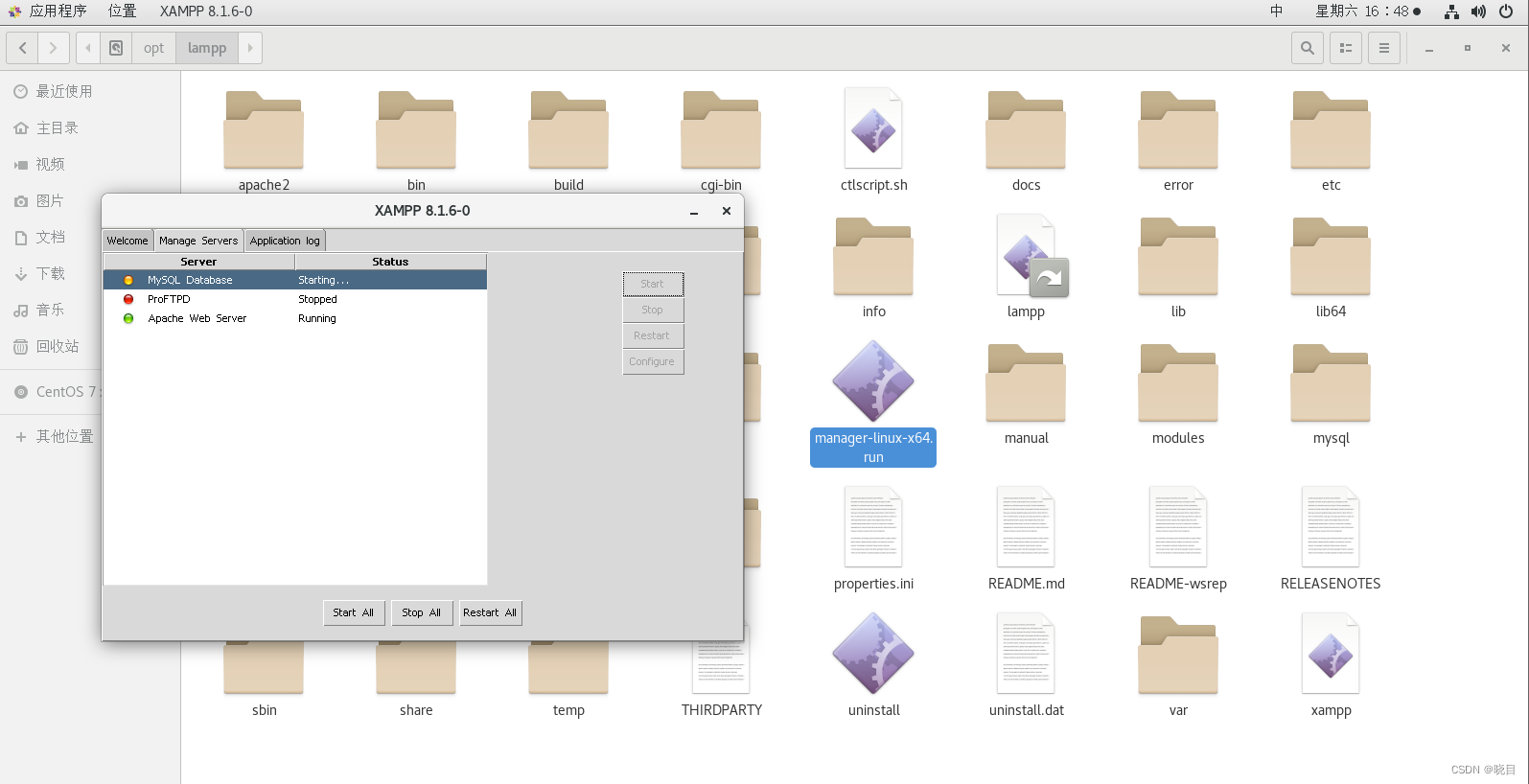
启动mysql database和apache web server
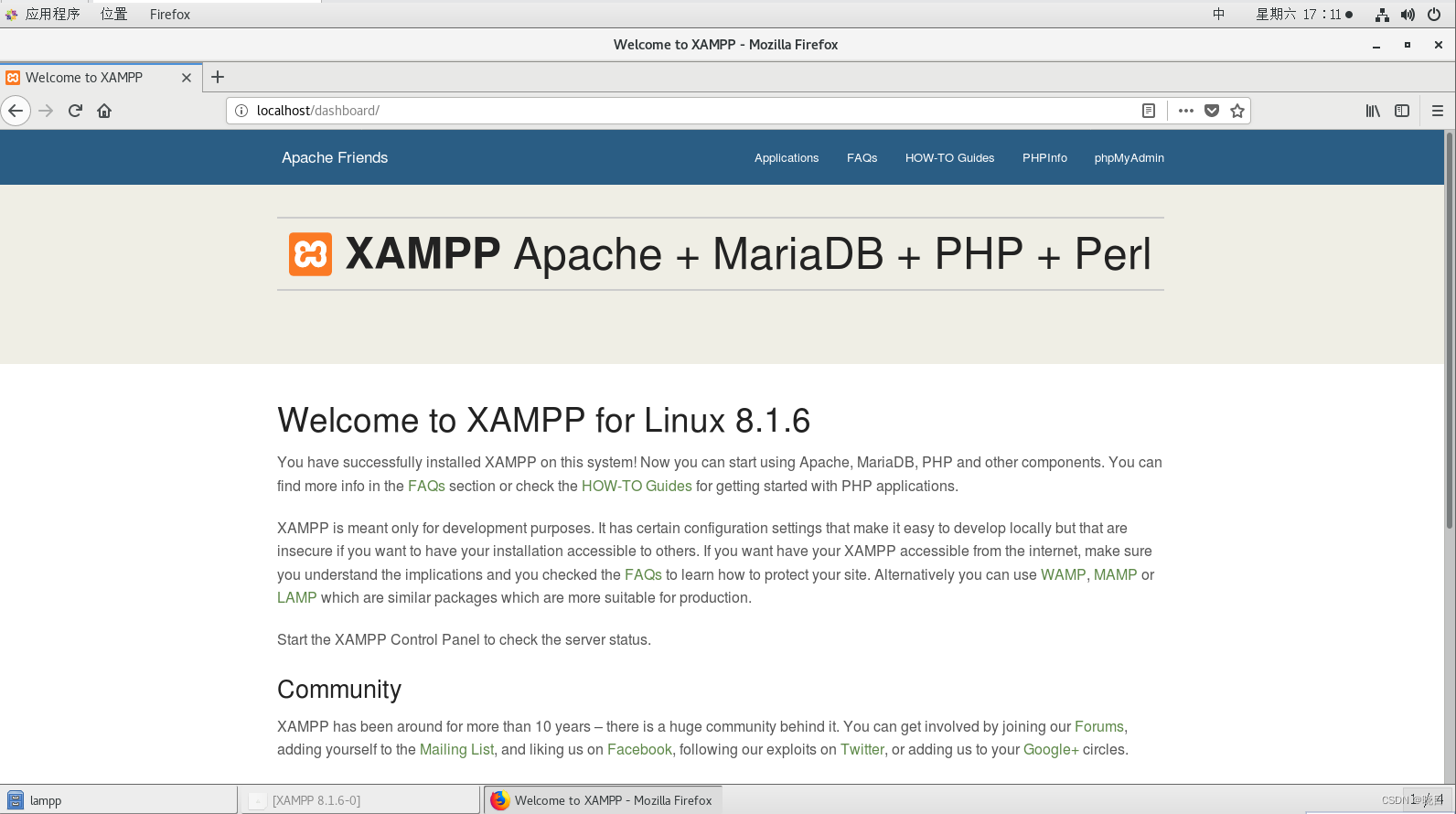
打开浏览器输入localhost,看到如下页面即开启成功
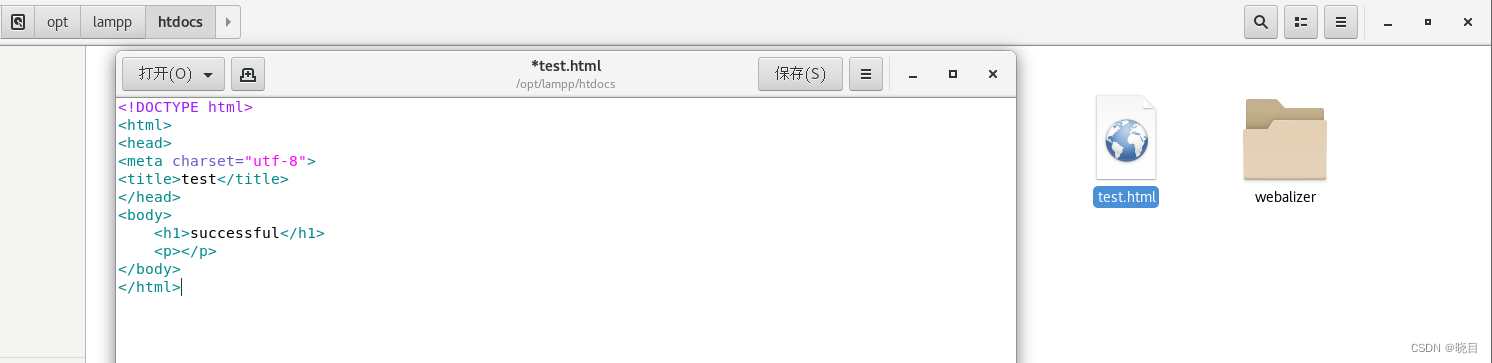
建立一个测试网页
在/opt/lampp/htdocs目录下创建一个名为test.html的文档

用记事本打开,输入:
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>test</title> </head> <body><h1>successful</h1>
<p></p>
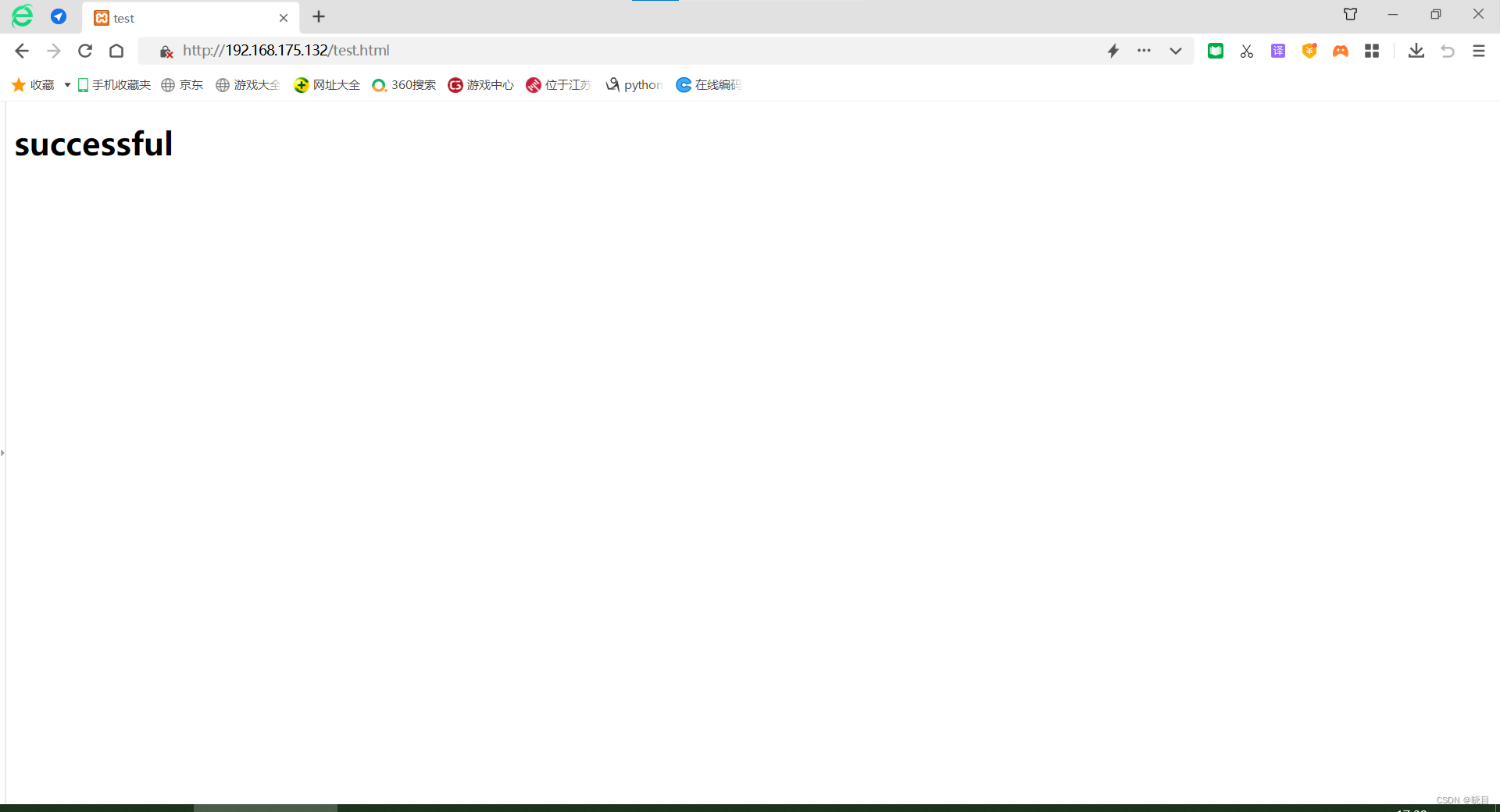
在终端中将centos虚拟机的防火墙关闭,并且将虚拟机的网络设置为桥接模式。
输入命令 systemctl stop firewalld.service
这样既可在实体机中访问虚拟机的网页
输入host:80/test.html
我的虚拟机ip为192.168.175.132
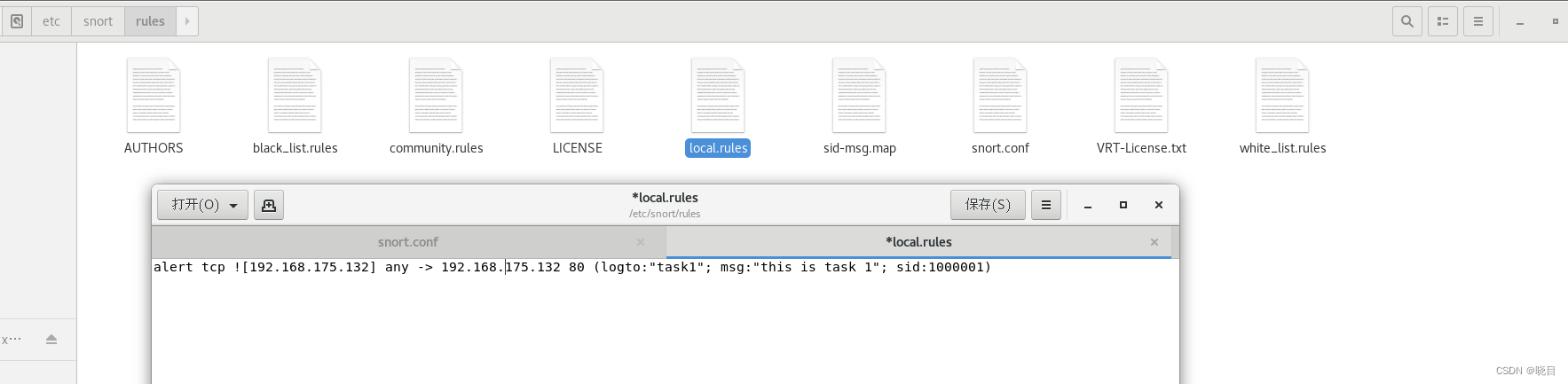
编写规则
打开/etc/snort/rules/local.rules文件,输入
alert tcp ![192.168.175.132] any -> 192.168.175.132 80(logto:"task1"; msg:"this is task 1"; sid:1000001)
(1)alert 表示这是一个警告。
(2)tcp表示要检测所有使用tcp协议的包,因为http协议是tcp/ip协议的一部分。
(3)接下来的一部分表示源IP地址,其中“!”表示除了后面IP的所有IP,因此![192.168.43.73]表示的就是除了本机之外的所有主机。
(4)再后面的一个表示端口,any表示源IP地址任何一个端口,也就是说源IP地址的主机不管哪个端口发送的包都会被检测。->表示检测的包的传送方向,表示从源IP传向目的IP。下面的一个字段表示目的IP,在这里表示主机。后面的字段表示端口号。
(5)括号中的规则选项部分,logto表示将产生的信息记录到文件,msg表示在屏幕上打印一个信息,sid表示一个规则编号,如果不在规则中编写这个编号,则执行过程中会出错,而且这个编号是唯一的能够标识一个规则的凭证,1000000以上用于用户自行编写的规则。
在/var/log/下生成snort文件
输入命令:
snort -dev -l /var/log/snort -h 192.168.175.132 -i ens33 -c /etc/snort/snort.conf
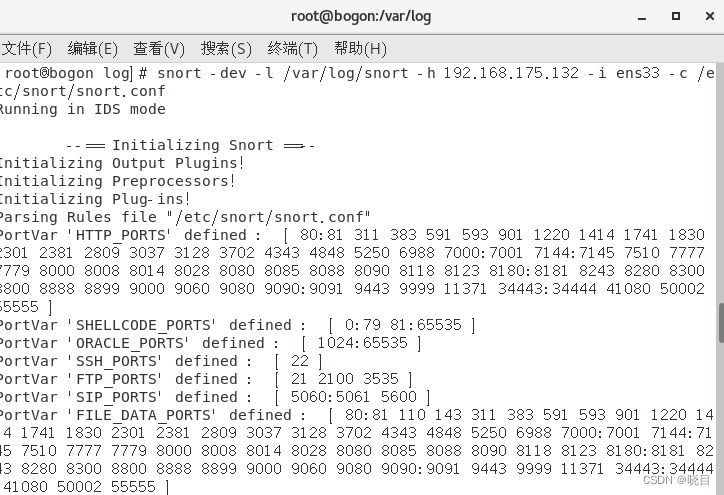
其中/var/log/snort为警报日志生成的位置。

再次通过windows访问test.html网页,点击刷新

我们即可在/var/log/snort目录下找到alert日志,其中包含了source ip等信息。
使用wireshark查看抓取包
想用wireshark查看抓取包的情况
虚拟机使用yum下载wireshark很简单两步完成
yum install -y wireshark
yum install -y wireshark-gnome
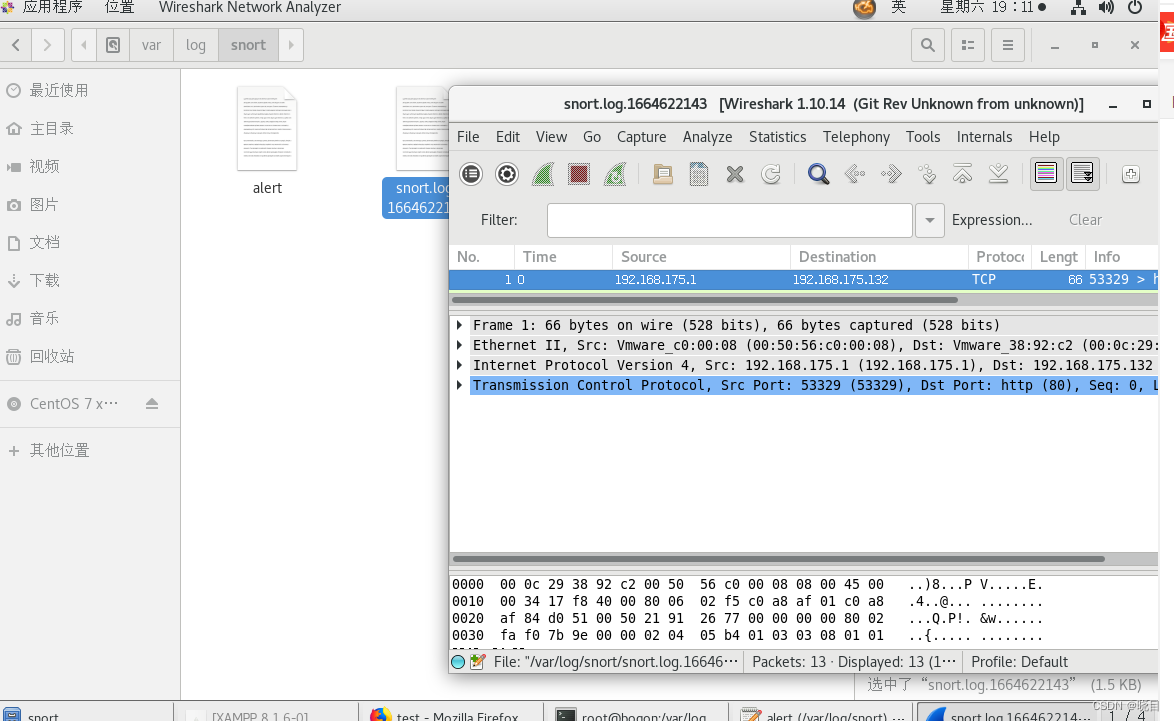
这样就可以更加直观的查看抓取到的数据包啦
也可以用命令行打开wireshark查看数据包
wireshark /var/log/snort/snort.log.1664622143
Snort rules概述
Snort规则被分成两个逻辑部分:规则头和规则选项。规则头包含规则的动作,协议,源和目标ip地址与网络掩码,以及源和目标端口信息;规则选项部分包含报警消息内容和要检查的包的具体部分。
- 规则头:
规则动作:
在snort中有五种动作:alert、log、pass、activate和dynamic.
1、Alert-使用选择的报警方法生成一个警报,然后记录(log)这个包。
2、Log-记录这个包。
3、Pass-丢弃(忽略)这个包。
4、activate-报警并且激活另一条dynamic规则。
5、dynamic-保持空闲直到被一条activate规则激活,被激活后就作为一条log规则执行。
协议类型:
Snort当前分析可疑包的ip协议有四种:tcp 、udp、icmp和ip。将来可能会更多,例如ARP、IGRP、GRE、OSPF、RIP、IPX等。
地址:
关键字"any"可以被用来定义任何地址。地址就是由直接的数字型ip地址和一个cidr块组成的。cidr块指示作用在规则地址和需要检查的进入的任何包的网络掩码。/24表示c类网络, /16表示b类网络,/32表示一个特定的机器的地址。
Ps: CIDR:无间域路由 将 IP 地址分为 A 类、B 类、C 类后,会造成 IP 地址的部分浪费。例如,一些连续的 IP 地址,一部分属于 A 类地址,另一部分属于 B 类地址。为了使这些地址聚合以方便管理,出现了 CIDR(无类域间路由)。
无类域间路由(Classless Inter-Domain Routing,CIDR)可以将路由集中起来,在路由表中更灵活地定义地址。它不区分 A 类、B 类、C 类地址,而是使用 CIDR 前缀的值指定地址中作为网络 ID 的位数。
这个前缀可以位于地址空间的任何位置,让管理者能够以更灵活的方式定义子网,以简便的形式指定地址中网络 ID 部分和主机 ID 部分。
CIDR 标记使用一个斜线/分隔符,后面跟一个十进制数值表示地址中网络部分所占的位数。例如,205.123.196.183/25 中的 25 表示地址中 25 位用于网络 ID,相应的掩码为 255.255.255.128。
否定操作符用"!"表示。
你也可以指定ip地址列表,一个ip地址列表由逗号分割的ip地址和CIDR块组成,并且要放在方括号内“[”,“]”。此时,ip列表可以不包含空格在ip地址之间。
例如:
alert tcp ![192.168.1.0/24,10.1.1.0/24] any -> [192.168.1.0/24,10.1.1.0/24] 111 (content: "|00 01 86 a5|"; msg: "external mountd access";)
变量定义:
var MY_NET 192.168.1.0/24
alert tcp any any -> $MY_NET any (flags: S; msg: "SYN packet";)
注:"$" 操作符之后定义变量;
"?" 和 "-"可用于变量修改操作符;
$var - 定义变量。
$(var) - 用变量"var"的值替换。
$(var:-default) - 用变量"var"的值替换,如果"var"没有定义用"default"替换。
$(var:?message) - 用变量"var"的值替换或打印出错误消息"message"然后退出。
例如:
var MY_NET $(MY_NET:-192.168.1.0/24)
log tcp any any -> $(MY_NET:?MY_NET is undefined!) 23
端口号:
端口号可以用几种方法表示,包括"any"端口、静态端口定义、范围、以及通过否定操作符。
静态端口定义表示一个单个端口号,例如111表示portmapper,23表示telnet,80表示http等等。端口范围用范围操作符":"表示。范围操作符可以有数种使用方法,如下所示:
log udp any any -> 192.168.1.0/24 1:1024
记录来自任何端口的,目标端口范围在1到1024的udp流
log tcp any any -> 192.168.1.0/24 :6000
记录来自任何端口,目标端口小于等于6000的tcp流
log tcp any :1024 -> 192.168.1.0/24 500:
记录来自任何小于等于1024的特权端口,目标端口大于等于500的tcp流
方向操作符:
方向操作符"->"表示规则所施加的流的方向。方向操作符左边的ip地址和端口号被认为是流来自的源主机,方向操作符右边的ip地址和端口信息是目标主机,还有一个双向操作符"<>"。
- 规则选项:
规则选项组成了snort入侵检测引擎的核心,既易用又强大还灵活。所有的snort规则选项用分号";"隔开。规则选项关键字和它们的参数用冒号":"分开。例如:
msg - 在报警和包日志中打印一个消息。
flags -检查tcp flags的值。
content - 在包的净荷中搜索指定的样式。
Content关键字的选项数据比较复杂;它可以包含混合的文本和二进制数据。二进制数据一般包含在管道符号中("|"),表示为字节码(bytecode)。字节码把二进制数据表示为16进制数字,是描述复杂二进制数据的好方法。例如:content: "|90C8 C0FF FFFF|/bin/sh";
字符 : ; \ "在content选项内容中出现时必须被转义(有两个方法:1.用前导“\”字符 2. 使用字节的二进制表示方式,比如用“|3A|”表示“:”):
内容匹配项的默认是区分大小写的;
offset - content选项的修饰符,设定开始搜索的位置 。
depth - content选项的修饰符,设定搜索的最大深度。
nocase - 指定对content字符串大小写不敏感。
distance - content选项的修饰符,设定模式匹配间的最小间距;
distance关键字是content关键字的一个修饰词,确信在使用content时模式匹配间至少有N个字节存在。它被设计成在规则选项中和其他选项联合使用。
格式:distance: ;
例子:
alert tcp any any -> any any (content: "2 Patterns"; content: "ABCDE"; content: "EFGH"; distance: 1;)
within - content选项的修饰符,设定模式匹配间的最大间距;
within关键字是content关键字的一个修饰词,确保在使用content时模式匹配间至多有N个字节存在。它被设计成在规则选项中和distance选项联合使用。
格式:within: ;
例子:
alert tcp any any -> any any (content: "2 Patterns"; content: "ABCDE"; content: "EFGH"; within: 10;)
byte_test - 数字模式匹配。
把数据包净载中特定位置的字串转换为数值类型与指定的值进行比较。
格式:byte_test: , , , [[relative],[big],[little],[string],[hex],[dec],[oct]]
bytes_to_convert 从数据包取得的字节数。
operator 对检测执行的操作 (<,>,=,!)。
value 和转换后的值相测试的值。
offset 开始处理的字节在负载中的偏移量。
relative 使用一个相对于上次模式匹配的相对的偏移量。
big 以网络字节顺序处理数据(缺省)。
little 以主机字节顺序处理数据。
string 数据包中的数据以字符串形式存储。
hex 把字符串数据转换成十六进制数形式。
dec 把字符串数据转换成十进制数形式。
oct 把字符串数据转换成八进制数形式。
例子:
alert udp $EXTERNAL_NET any -> $HOME_NET any (msg:"AMD procedure 7 plog overflow "; content: "|00 04 93 F3|"; content: "|00 00 00 07|"; distance: 4; within: 4; byte_test: 4,>, 1000, 20, relative;)
uricontent - 用于匹配正规化处理后URI字段。
这个关键字允许只在一个请求的URI(URL)部分进行搜索匹配。它允许一条规则只搜索请求部分的攻击,这样将避免服务数据流的错误报警。关于这个关键字的参数的描述可以参考content关键字部分。这个选项将和HTTP解析器一起工作。(只能搜索第一个“/”后面的内容)。
例如:uricontent:".emf";
Flow
这个选项要和TCP流重建联合使用。它允许规则只应用到流量流的某个方向上。这将允许规则只应用到客户端或者服务器端。这将能把内网客户端流览web页面的数据包和内网服务器所发送的数据包区分开来。这个确定的关键字能够代替标志:A+ 这个标志在显示已建立的TCP连接时都将被使用。
选项:
to_client 触发上服务器从A到B的响应。
to_server 触发客户端上从A到B的请求。
from_client 触发客户端上从A到B的请求。
from_server 触发服务器上从A到B的响应。
established 只触发已经建立的TCP连接。
stateless 不管流处理器的状态都触发(这对处理那些能引起机器崩溃的数据包很有用。
no_stream 不在重建的流数据包上触发。
only_stream 只在重建的流数据包上触发。
格式:flow:[to_client|to_server|from_client|from_server|established|stateless|no_stream|only_stream]
reference - 外部攻击参考ids。
这个关键字允许规则包含一个外面的攻击识别系统。这个插件目前支持几种特定的系统,它和支持唯一的URL一样好。这些插件被输出插件用来提供一个关于产生报警的额外信息的连接。
sid - snort规则id。
这个关键字被用来识别snort规则的唯一性。这个信息允许输出插件很容易的识别规则的ID号。
sid 的范围是如下分配的:
<100 保留做将来使用
100-1000,000 包含在snort发布包中
1000,000 作为本地规则使用
rev - 规则版本号。
这个关键字是被用来识别规则修改的。修改,随同snort规则ID,允许签名和描述被较新的信息替换。
classtype - 规则类别标识。
这个关键字把报警分成不同的攻击类。通过使用这个关键字和使用优先级,用户可以指定规则类中每个类型所具有的优先级。
pcre:
pcre选项允许用户使用与PERL语言相兼容的正则表达式。相关正则表达式的具体细节参看PCRE的Web站点:http://www.pcre.org
pcre:[!]"(/<regex>/|m<delim><regex><delim>)[ismxAEGRUB]";
在表达式后的修饰符设置编译正则表达式的一些标志。
Perl兼容的修饰符:
|i| 对大小不敏感
|s| 在点转义符号中包含换行符, 一般情况下被匹配的缓冲区是作为一个大字符串
|m| 的,和$分别匹配串头和串尾。当设置了m修饰符,和$匹配跟紧跟换行符和紧先导于换行符的情况
|x| 要匹配的模式中的空格符被忽略,除非是被转义过的或在一个字符集中。
PCRE兼容的修饰符:
|A| 模式必须在缓冲区的开头匹配到(同^) 设置指定的$必须匹配到缓冲区末尾。如果不用E |
|E| 修饰符,$则可能只匹配到串尾之前换行符。
|G| 在默认情况下不使用“贪婪”模式,只有在模式后面跟了“?”字符的情况下贪婪。
Snort特定的修饰符:
|R| 此匹配相对于前一个匹配成功串尾开始(类似于distance:0)
|U| 匹配解码后的URI缓冲区(类似于uricontent
|B| 不使用解码后的缓冲区(类似于rawbytes)
修饰符R和B不能同时使用。
例如: alert ip any any -> any any (pcre:"/BLAH/i";)
例子:
alert tcp $EXTERNAL_NET $HTTP_PORTS -> $HOME_NET any (msg:"WEB-CLIENT PNG large colour depth download attempt"; flow:from_server,established; content:"|89|PNG|0D 0A 1A 0A|"; content:"IHDR"; within:8; byte_test:1,>,16,8,relative;classtype:attempted-user; sid:3134; rev:3;reference:url,www.microsoft.com/technet/security/bulletin/MS05-009.mspx; )
alert tcp $EXTERNAL_NET any -> $HOME_NET 139 (msg:"NETBIOS SMB Trans Max Param/Count DOS attempt"; flow:established,to_server; content:"|00|"; depth:1; content:"|FF|SMB%"; within:5; distance:3; byte_test:1,!&,128,6,relative; pcre:"/^.{27}/sR"; content:"|00 00 00 00|"; within:4; distance:5;reference:url,www.corest.com/common/showdoc.php?idx=262;classtype:protocol-command-decode; sid:2101; rev:15;)
alert tcp $HOME_NET any -> $EXTERNAL_NET $HTTP_PORTS (msg:"SPYWARE-PUT Hijacker shop at home select installation in progress"; flow:to_server,established; uricontent:"GRInstallCL.asp"; nocase; uricontent:"E="; nocase; uricontent:"MID="; nocase; uricontent:"Refer="; nocase; uricontent:"WGR="; nocase; uricontent:"Prev="; nocase; uricontent:"sGUID="; nocase; classtype:misc-activity; sid:5810; rev:1;)
正则表达式元字符的解释:
\: 转移字符,将后一个字符标记为一个特殊字符
^:匹配输入字串的开始位置
$:匹配输入字串的结束位置
*:匹配前面的子表达式0次或多次
+:匹配前面的子表达式1次或多次
?:匹配前面的子表达式0次或1次
{n,m}:匹配至少n次,至多m次
.:匹配到除"\n"之外的所有单个字符
[]:表示一个字符集,可以单个列出,如[amk$];也可以加一个"-"表示一个字符范围,如[a-z];匹配任意一个字符即可;也可以用补集来匹配不在区间范围内的字符。其做法是把""作为类别的首个字符;其它地方的""只会简单匹配 ""字符本身,例如[5] 将匹配除 "5" 之外的任意字符。
例如:
pcre:"/X-Mailer\x3A[\r\n]*mPOP\s+Web-Mail/smi";
pcre:"/Host\x3A[\r\n]*e2give.com/smi";
pcre:"/User-Agent\x3A[\r\n]*NSISDL/smi";
pcre:"/Host\x3A[\r\n]*push\x2Ecom/smi";
...
注:\x 后为十六进制转义值
\r 匹配一个回车符
\n 匹配一个换行符
\s 匹配任何空白字符
\d 匹配任何十进制数;它相当于类 [0-9]。
\D 匹配任何非数字字符;它相当于类 [^0-9]。
\s 匹配任何空白字符;它相当于类 [ \t\n\r\f\v]。
\S 匹配任何非空白字符;它相当于类 [^ \t\n\r\f\v]。
\w 匹配任何字母数字字符;它相当于类 [a-zA-Z0-9_]。
\W 匹配任何非字母数字字符;它相当于类 [^a-zA-Z0-9_]。
版权归原作者 晓目 所有, 如有侵权,请联系我们删除。